
This article will cover SQL Server transaction log architecture including file topography, basic overview, review of LSN and MinLSN, and log truncation
Topography
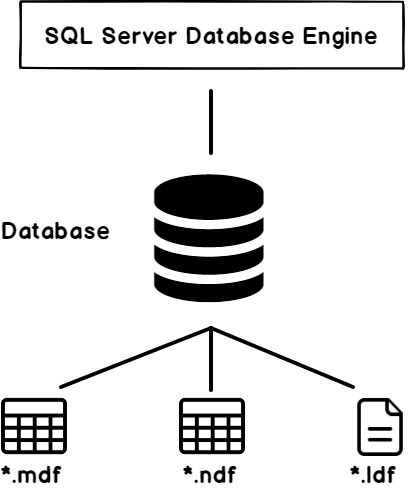
A SQL Server database consists mainly of three files, the primary data file (.mdf), the secondary data file (.ndf) and the transaction log file (.ldf). As the name indicates, the data files are used to store the tables data within the data page. The SQL Server transaction log file is used to write a record for each data modification operation, including an image of the data before and after the modification process.
Overview
In the previous article of this series SQL Server Transaction Overview, we described the concept of the SQL Server transaction. In this article we’ll review the architecture of the transaction log file.
The transaction log is a critical component of a SQL Server database for ACID (Atomicity, Consistency, Isolation and Durability) compliance. When the SQL Server service is restarted, the database enters into the Recovery state, in which the SQL Server Database Engine reads the SQL Server transaction log file to make sure that the database is in a consistent state. It does this by writing the committed transactions data to the data file in a roll-forward process, and undoing all uncommitted transactions in a roll-back process. In addition, the transaction log file is used to restore the database to a specific point of time, in case of a disaster or system failure. It can be also used to return the database to the previous state when a ROLLBACK command is executed after a transaction.
The functionality of the SQL transaction log is achieved by writing a log record to the transaction log file before writing the data pages to the physical data file, in a process called Write-ahead Logging. The SQL Server Database Engine writes a log record for each single operation, such as writing a log at the beginning and at the end of each SQL transaction, after each data modification process, when creating or dropping a database table or index, and after each page allocation or deallocation process. These logs will be written to and read from the transaction log file sequentially.
SQL Server allows us to create multiple SQL Server transaction log files on each database. Each transaction log file is divided internally into multiple Virtual Log Files, also known as VLFs. The size and number of the VLFs on each transaction log file is dynamic, where the SQL Server Database Engine starts with the least possible number of VLFs on the transaction log file and extend it, based on the defined increment, when the file runs out of free space.
The number and the size of the VLFs affect the performance of the database startup, backup and restore operations. To override these performance issues, we should tune both the SQL transaction log file initial size and auto-growth increment properly. We will cover the VLFs subject completely in the next article. It is not always recommended to have multiple transaction log files in your database, as it may impact the performance of your database, due to writing the data sequentially and not in parallel. You can create another transaction log file as a workaround, in case of running the current hosting disk drive out of free space.
Transaction log LSN
Each Transaction log record that is written to the SQL Server transaction log file can be identified by its Log Sequence Number (LSN). When the database is created, the Database Engine starts writing at the beginning of the logical transaction log file, which is the beginning of the actual physical transaction log file, and mark the end of the written log as the end of the logical log file. When a new transaction is performed, the log records will be written serially to the end of the logical transaction log file, with an LSN value higher than the LSN value of the previous log record.
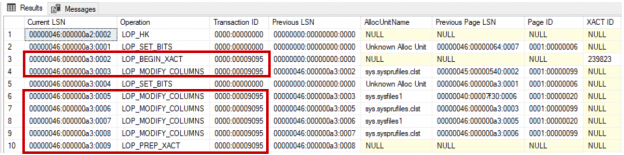
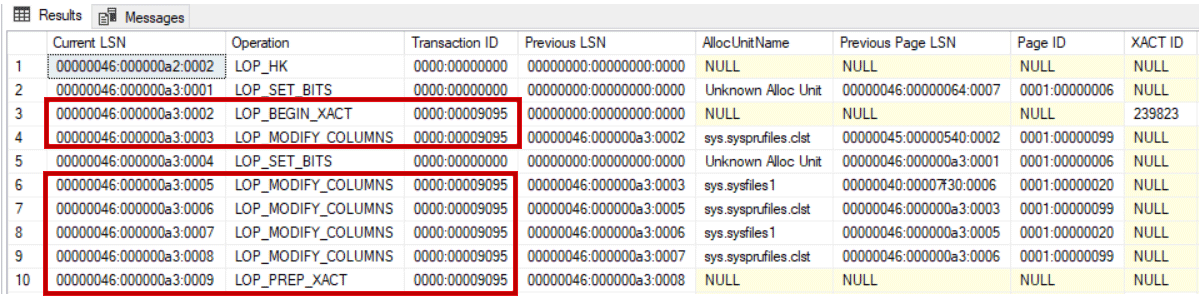
The serially inserted log records contain other useful information, such as the ID of the transaction that this record belongs to. In this case, all log records associated with a specific transaction will be grouped and linked in a chain based on the transaction ID, that speed the rollback process of that transaction. For example, querying the sys.fn_dblog system DMO using the following script shows us number of log records, with different LSNs, that belong to the same transaction, and linked together using the Transaction ID value, as shown clearly below:
|
1 2 3 |
SELECT [Current LSN],[Operation] ,[Transaction ID],[Previous LSN] ,[AllocUnitName],[Previous Page LSN], [Page ID],[XACT ID],[Begin Time],[End Time] FROM sys.fn_dblog (NULL, NULL) |
You can imagine the SQL Server transaction log file as a circular tape. When the end of the logical log reaches the end of the actual physical log, the Database Engine will write the new log by wrapping it around the beginning of the actual log file, in a circular way, or to the next transaction log file, if the database consists of multiple transaction log file, as shown below:
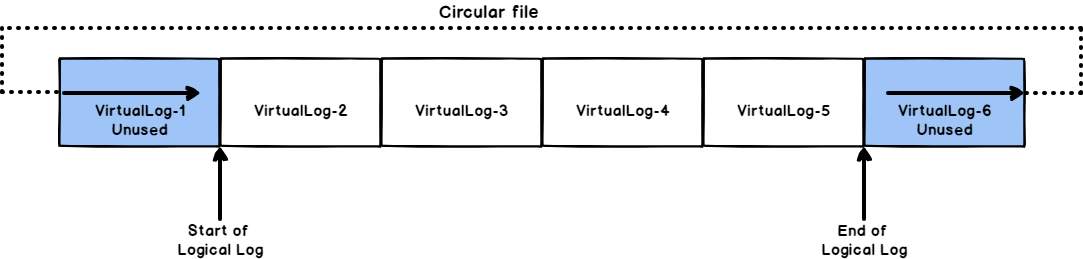
If the end of the logical log reaches the start of the logical log, due to one of the following reasons, the SQL Server Database Engine will return error number 9002, as there is no room available for the new transaction log record to be written in the SQL Server transaction log file:
- No proper truncate process is performed.
- Auto-growth option is not enabled.
- Auto-growth enabled but the disk drive is running out of free space.
MinLSN
The Minimum transaction log Sequence Number, also known as MinLSN, is a special type of LSN, that shows the LSN of the oldest active log record that is required to perform a successful database rollback process. The portion of the SQL Server transaction log file between the MinLSN and the end of the logical log that is required for the full database recovery, is called the Active Log, as shown below:
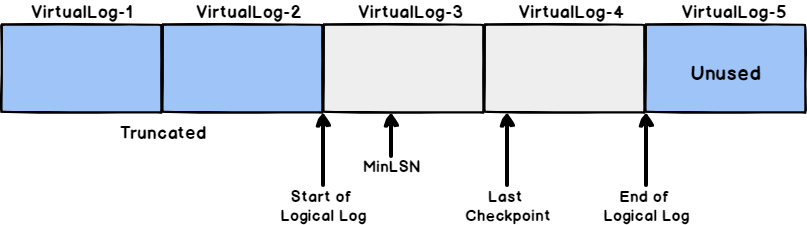
Truncation
Log truncation process deletes all inactive VLFs from the SQL Server transaction log file. No part of the active log can ever be truncated. VLF is the smallest unit of truncation in the transaction log file. If there is one active log record within an VLF, the overall VLF will be considered as part of the active log.
To be able to truncate the SQL Server transaction log:
- The transaction should be committed
- The transaction log is not pending any backup or high availability feature
- A Checkpoint operator should be triggered to mark the inactive portion of the transaction log as reusable
When a data insertion or modification is performed on your database, the Database Engine keeps the performed change in the buffer pool memory, rather than applying it directly to the database files. In this way, it will perform less frequent I/O operations. The data pages that are stored in the buffer pool memory but not reflected yet to the database files are known as Dirty Pages. The process used by the Database Engine to reflect the dirty pages to the database files periodically is called Checkpoints.
- For detailed information about the checkpoints, see Database checkpoints – Enhancements in SQL Server 2016.
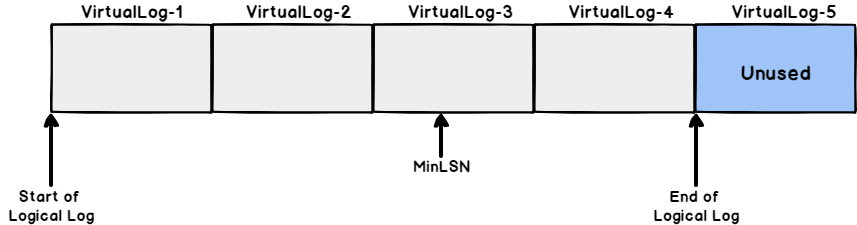
When a log truncation process is performed, the Database Engine will free all the inactive log records, starting from the beginning of the logical log toward the MinLSN, for reuse by the actual physical log. For example, the below SQL Server transaction log file contains:
- Physical log with 5 VLFs
- Logical log, which is the used part of the physical log, occupies the first four VLFs
- The first two VLFs contains inactive logs that cannot be used for now
- The second two VLFs (VLF 3 and VLF 4) contain active log records that cannot be truncated
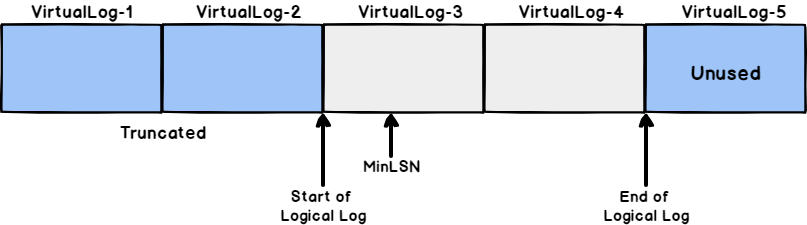
After performing a truncate process on the previous SQL Server transaction log file, you will see that:
- The first two VLFs, that contain inactive log records, are truncated
- VLF1 and VLF2 are available now for reuse again
- VLF1 and VLF2 are no longer part from the logical log
- No change performed on VLF3 and VLF4 that are contain active log records
For now, we are familiar with the internal structure of the SQL transaction log file, its importance and how it works. In the next articles of this series, we will describe deeply the different aspects of the SQL Server transaction log. Stay tuned!
Table of contents

He is a Microsoft Certified Solution Expert in Data Management and Analytics, Microsoft Certified Solution Associate in SQL Database Administration and Development, Azure Developer Associate and Microsoft Certified Trainer.
Also, he is contributing with his SQL tips in many blogs.
View all posts by Ahmad Yaseen
- Azure Data Factory Interview Questions and Answers - February 11, 2021
- How to monitor Azure Data Factory - January 15, 2021
- Using Source Control in Azure Data Factory - January 12, 2021