In this series of articles, we are going to learn about the basics of the MySQL database server. In this article, I am going to explain how we can query the data from the MySQFL server using the SELECT statement.
Read more »
In this series of articles, we are going to learn about the basics of the MySQL database server. In this article, I am going to explain how we can query the data from the MySQFL server using the SELECT statement.
Read more »

In this article, we will discuss several points that should be considered when planning to migrate the on-premises SQL workload to Microsoft Azure cloud services. This article is the first step in a series of articles that discuss how to perform the SQL and No-SQL workload migration smoothly to the cloud.
Read more »
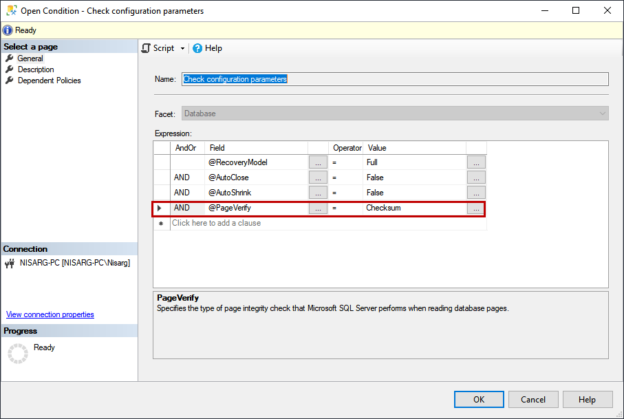
In this article, I am going to explain how we can enforce the SQL database best practices using Policy-Based Management. The policy-based management feature of SQL Server was introduced in SQL Server 2005. This feature was useful because it helps database administrators to define and enforce the database policies based on the organizations’ requirements.
Read more »
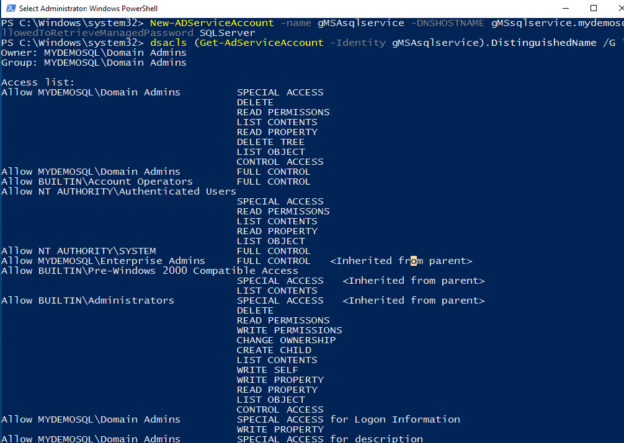
This article is a 6th article in the series for SQL Server Always On Availability Groups. It covers the configuration of the group managed service account (gMSA) for SQL Services.
Read more »
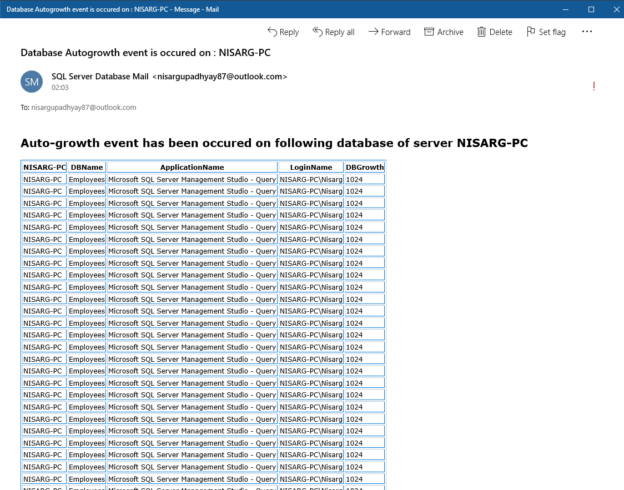
Monitoring the growth of the SQL Database is one of the essential tasks of the SQL Server DBA. In this article, I am going to explain how we can monitor the growth of the SQL database using the default trace. First, let me explain the default trace in SQL Server.
Read more »
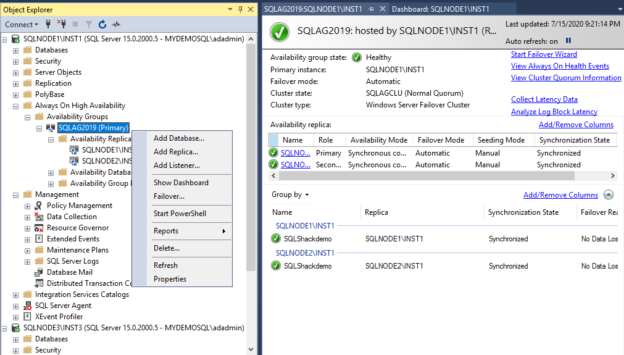
This is the 5th article in the series of a comprehensive guide to SQL Server Always On Availability Groups.
Read more »
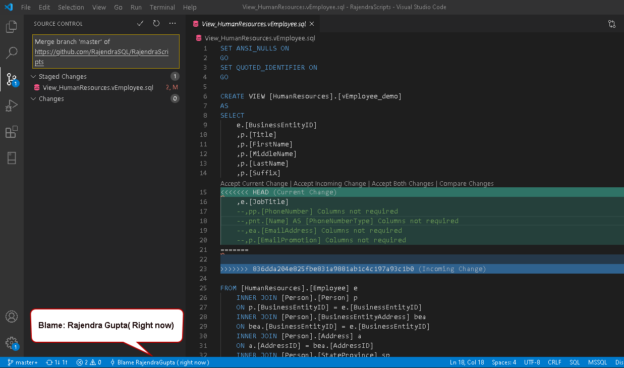
This article explores Visual Studio Code integration with Git Source Control.
Read more »
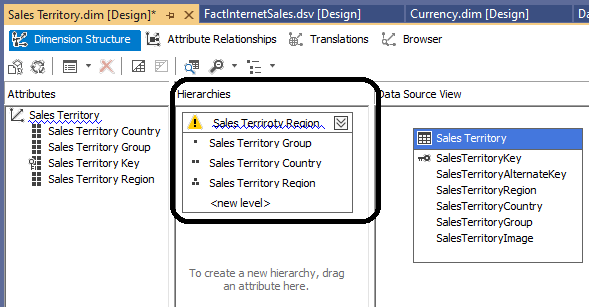
This article will discuss how SSAS Dimension Hierarchies can be used to analyze data much efficiently. If you are a data analyst, you want to start the analysis with a higher hierarchy. Then navigate the narrow attributes when required. For example, it will be better to start with analyzing revenue by year. If you need to analyze further into the data, you can choose the needed year and expand the Quarter -> Month, respectively. Let us see how we can create SSAS Dimension Hierarchies in OLAP Cubes to suit different requirements.
Read more »
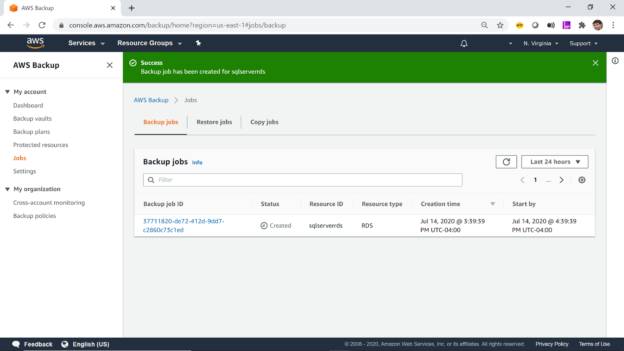
This article gives you an overview of creating backups of AWS RDS SQL Server database instances using AWS Backup service.
Read more »
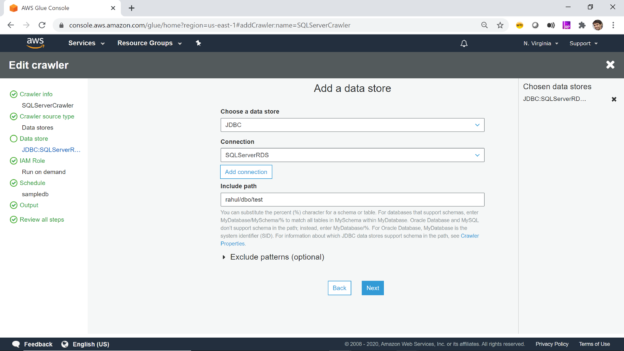
This article gives you an overview of cataloging AWS RDS SQL Server database objects like tables and views, using AWS Glue service.
Read more »
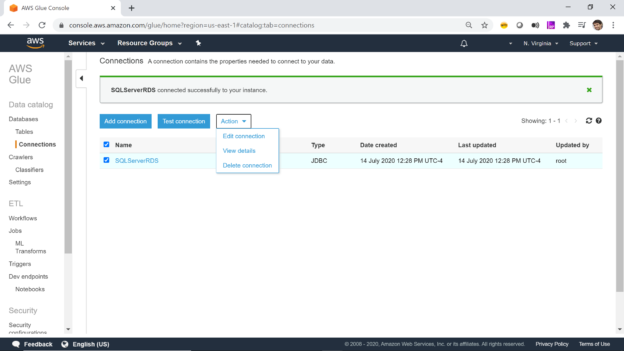
This article gives you an overview of configuring AWS RDS SQL Server with AWS Glue service that is used in AWS for cataloging and ETL operations.
Read more »
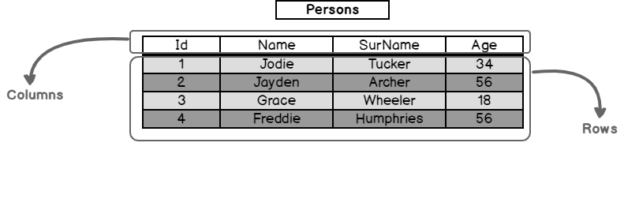
In this article, we will learn the concept of SQL tables and then work on how we can create tables with different techniques in SQL Server.
Read more »
This article gives you an overview of configuring the AWS Redshift cluster to use it from a locally installed IDE or tools.
Read more »
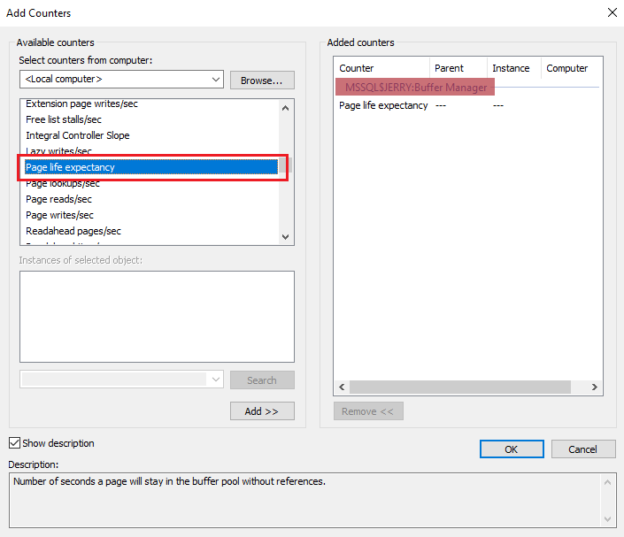
Page Life Expectancy (PLE) is an age of a data page in seconds in the buffer cache or buffer memory after querying the tables with the loading data page into the buffer memory. Page Life Expectancy value indicates the memory pressure in allocated memory to the SQL Server instance. In most of the cases, a page will be dropped from buffer periodically.
Read more »
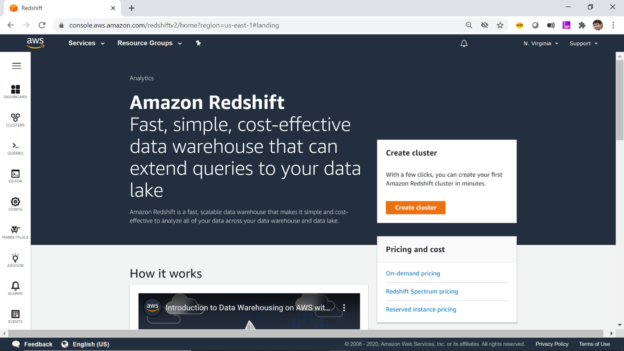
This article gives you an overview of AWS Redshift and describes the method of creating a Redshift Cluster step-by-step.
Read more »
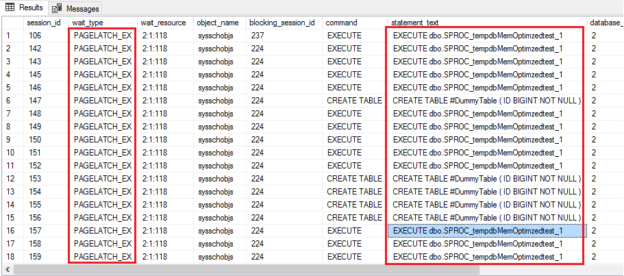
In this article, I will walk you through the new feature in SQL Server 2019, memory-optimized TempDB metadata. The most commonly faced performance problems in SQL Server world is known to be TempDB resource contention. Don’t you agree? Let us find the answer in this article.
Read more »
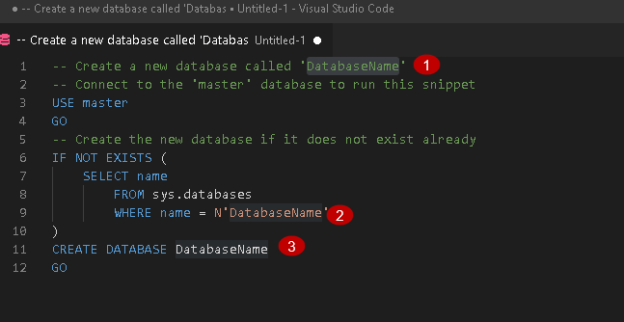
In the previous article, Getting started with Visual Studio Code (VS Code), we took a detailed overview of the popular code editor. It supports various programming languages t-SQL, Python, PHP, AWS CLI, PowerShell, etc. We need to use extensions in the VS code to work with these languages. For example, if we open the T-SQL script, it recommends you for the below extension.
Read more »
After discussing the basic features of Azure Machine Learning and how to clean the data from Azure Machine Learning, let us look at how to perform prediction in Azure Machine Learning. Prediction is one of the important aspects of Machine Learning as it will help to make strategic decisions.
Read more »
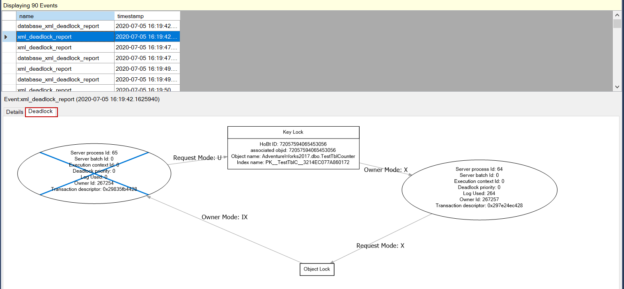
In this article, we will talk about the deadlocks in SQL Server, and then we will analyze a real deadlock scenario and discover the troubleshooting steps.
Read more »
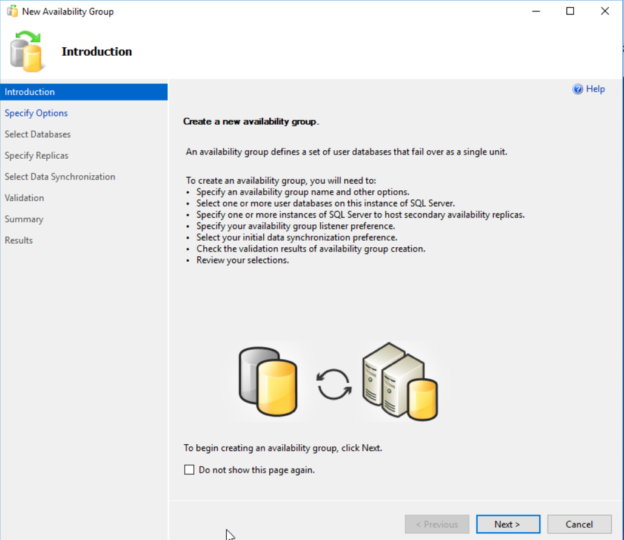
In this article, we will proceed with configuring a SQL Server Always On Availability Groups and perform failover validations.
Read more »

This article explores the AWS S3 bucket to configure a static website.
Read more »
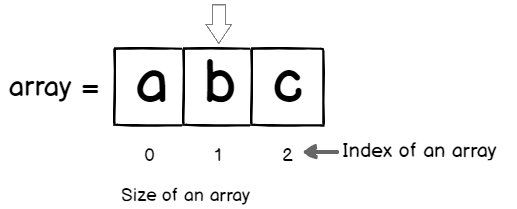
In this article, I am going to walk you through the concepts of the common Data Structures that every student, colleague working with computers should be aware of. Data Structure forms an integral part of any system or database design. It is a very interesting and intuitive concept that you can apply anywhere. Through this article, I aim to introduce the beginners to the concepts of Data Structures and brush up the same for colleagues who have already been associated with the industry for years. This will also help you understand some database concepts more easily once you have a grasp over these concepts.
Read more »
This article explores the configuration of Windows failover clusters, storage controllers, and quorum configurations for SQL Server Always On Availability Groups.
Read more »
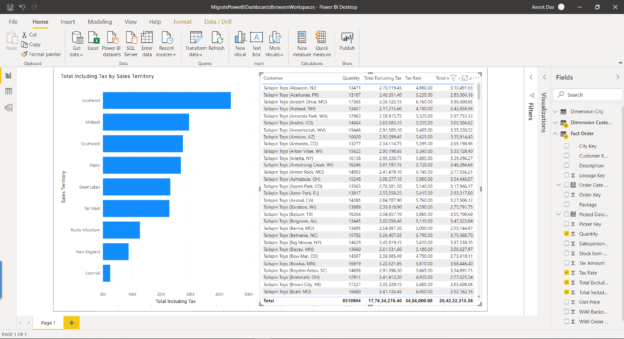
In this article, I am going to explain how we can create a Power BI Report using the Power BI Desktop and then publish it to the Power BI service workspace. Once the report is published to a workspace, we can also consider migrating the same report across several workspaces and all this can be done programmatically by using the Power BI REST APIs. This article is specially targeted towards Power BI admins or DevOps team whose task is to migrate dashboards between various environments like Development, QA, Production, etc. without any manual intervention of the reports.
Read more »

In this article, I am going to explain how we can automate the index and statistics maintenance of Azure SQL Database using an Elastic Job Agent.
Read more »© Quest Software Inc. ALL RIGHTS RESERVED. | GDPR | Terms of Use | Privacy