
This article gives you an overview of configuring AWS RDS SQL Server with AWS Glue service that is used in AWS for cataloging and ETL operations.
Introduction
AWS Cloud offers a variety of data repositories like AWS RDS, AWS DynamoDB, AWS Redshift and many others. AWS RDS supports six different types of databases namely Aurora, MariaDB, SQL Server, Postgres, MySQL and Oracle. With a variety of data repositories on the cloud, there is often a need to hold inventory of all the data repositories and database objects held in those repositories in a central location. This central inventory is also known as the data catalog. AWS Glue is a serverless managed service that supports metadata cataloging and ETL (Extract Transform Load) on the AWS cloud. To perform these operations on AWS RDS for SQL Server, one needs to integrate AWS Glue with AWS RDS for SQL Server instance. We will learn how to enable this integration in this article.
AWS RDS SQL Server Instance
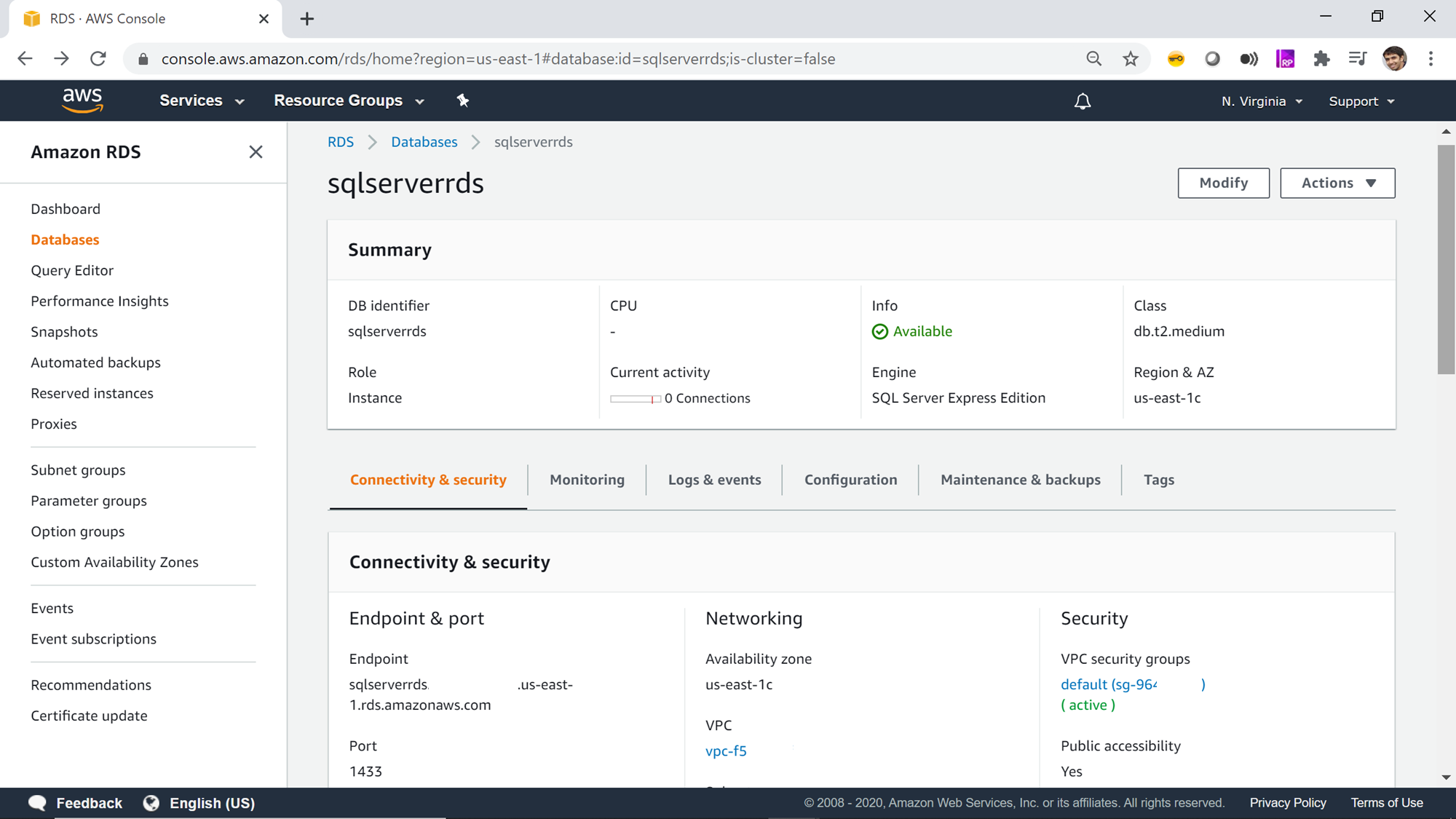
The first thing we need to have in place to perform this exercise is a working Amazon RDS for SQL Server instance. For those who are new to AWS RDS for SQL Server, they can read this article, Getting started with AWS RDS SQL Server, to create a new instance. Once you have a working instance, it would look as shown below. You can create the AWS RDS SQL Server instance using any edition of SQL Server supported by the RDS service. Ensure that you have the required privileges to connect and access data from the instance.
Introduction to AWS Glue
AWS Glue is a serverless service offering from AWS for metadata crawling, metadata cataloging, ETL, data workflows and other related operations. AWS Glue can be used to connect to different types of data repositories, crawl the database objects to create a metadata catalog, which can be used as a source and targets for transporting and transforming data from one point to another. AWS Glue supports workflows to enable complex data load operations. Usually, the first step for any operation is connecting to the data source of interest by creating a new connection. To learn the required configurations for creating a new connection, navigate to the AWS Glue home page from the AWS Search console by searching for the Glue service as shown below.
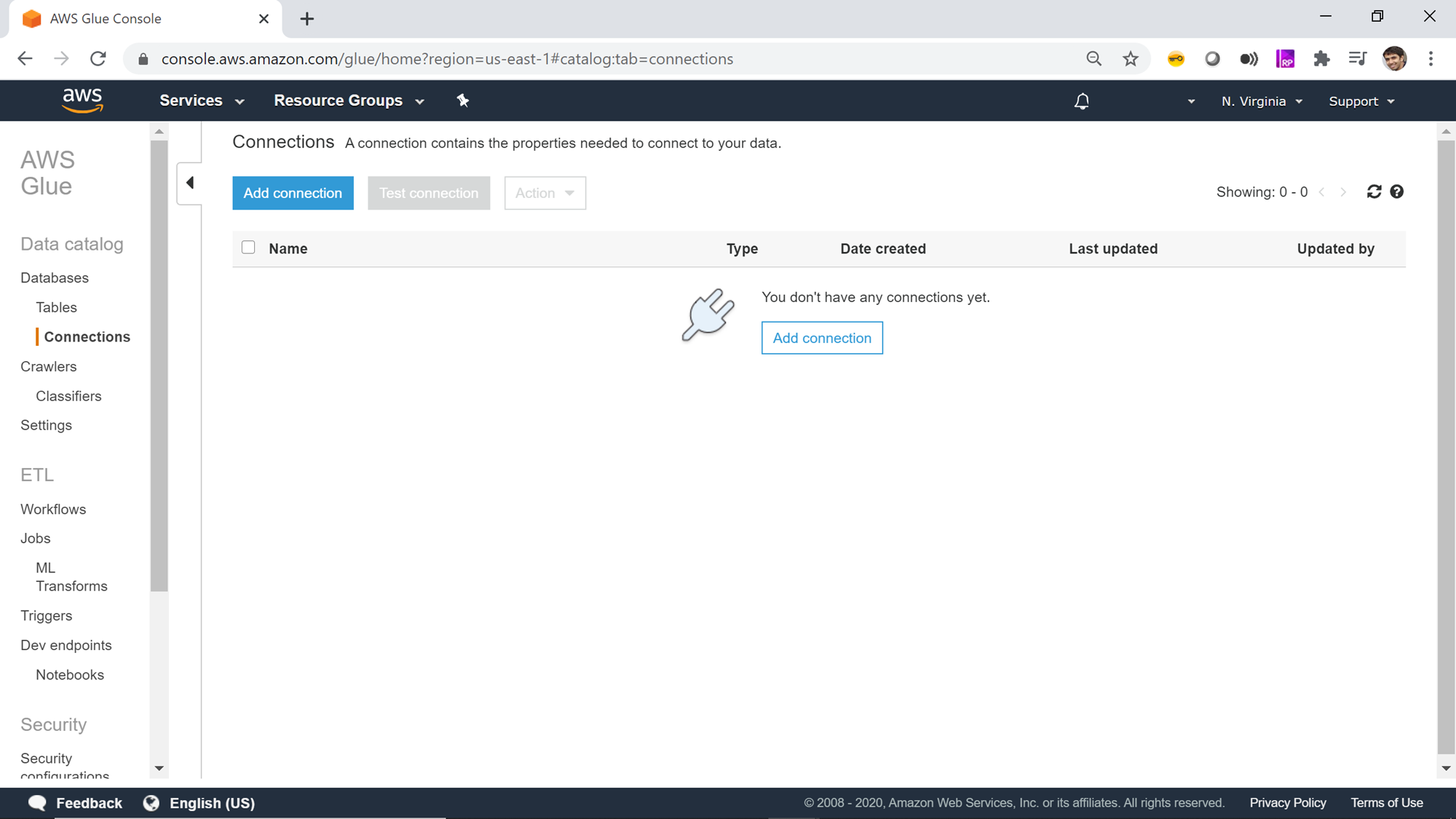
The left pane contains different options which are categorized majorly into Data catalog, ETL and Security. Once you are on the home page of AWS Glue service, click on the Connection tab on the left pane and you would be presented with a screen as shown below.
Now it’s time to create a new connection to our AWS RDS SQL Server instance. Click on the Add connection button to start creating a new connection. A new wizard screen would appear which will have multiple steps to collect details regarding the data source to which we intend to create a connection. The first step is to provide a connection name. Provide a relevant name for the connection.
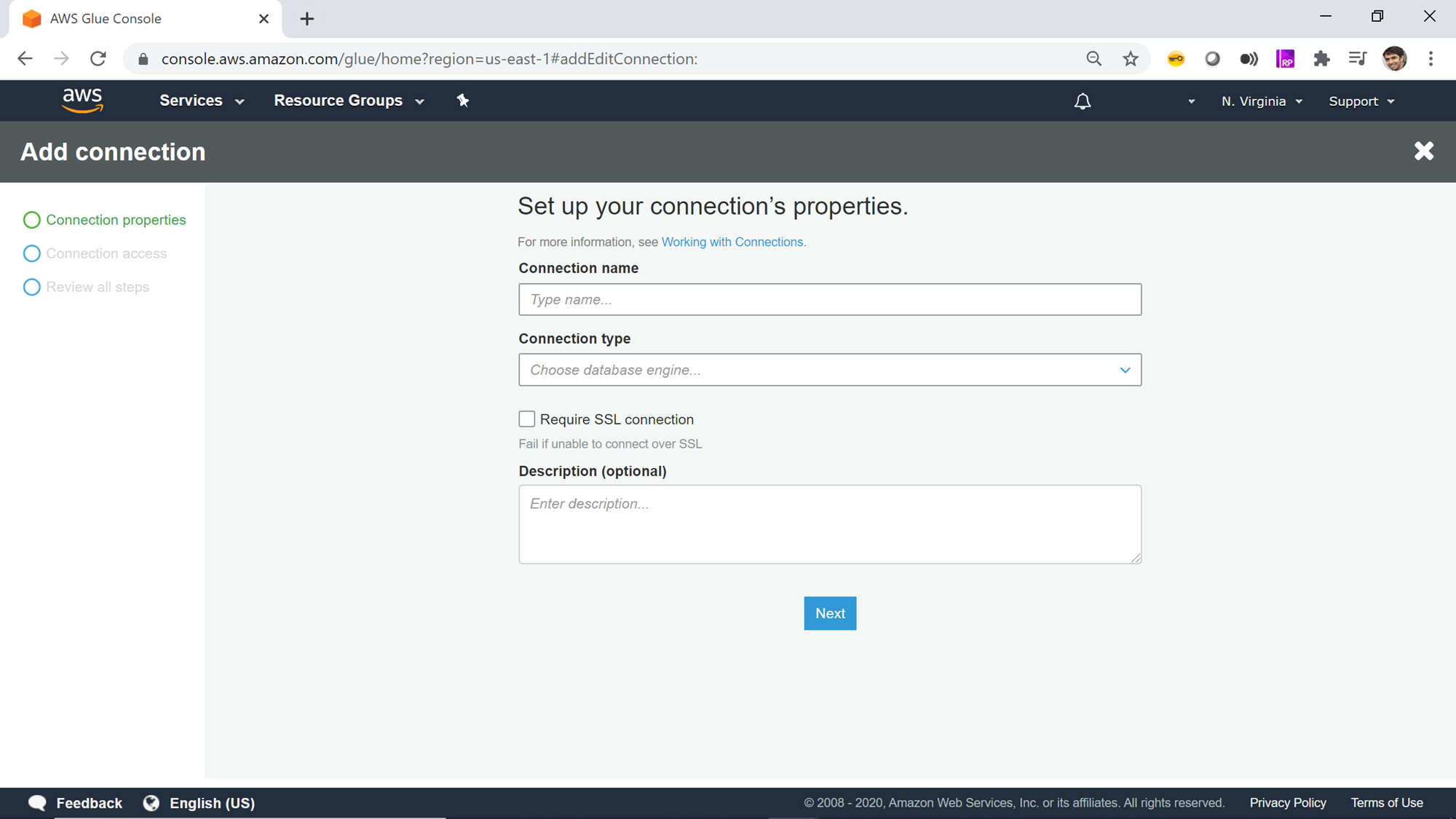
Next, we must select the type of connection. In the Connection type dropdown, you can find the options as shown below. Of all the supported options, we need to select Amazon RDS as it’s the service that holds our AWS RDS SQL Server instance.
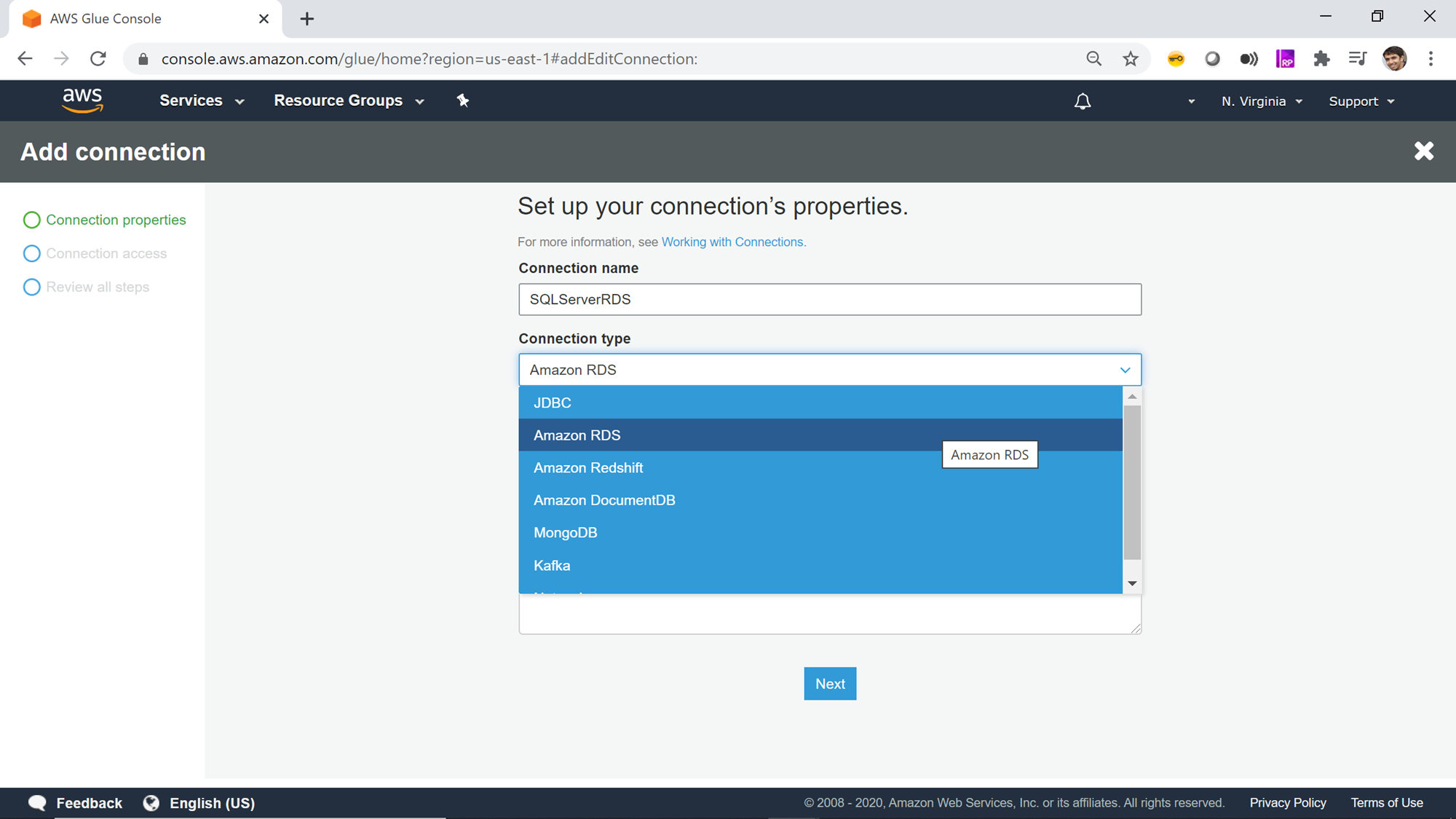
Once you select it, the next option of Database engine type would appear, as AWS RDS supports six different types of database mentioned above. Of all the supported databases, we need to select SQL Server. If the AWS RDS SQL Server instance is configured to allow only SSL enabled connections, then select the checkbox titled “Requires SSL Connection”, and then click on Next.
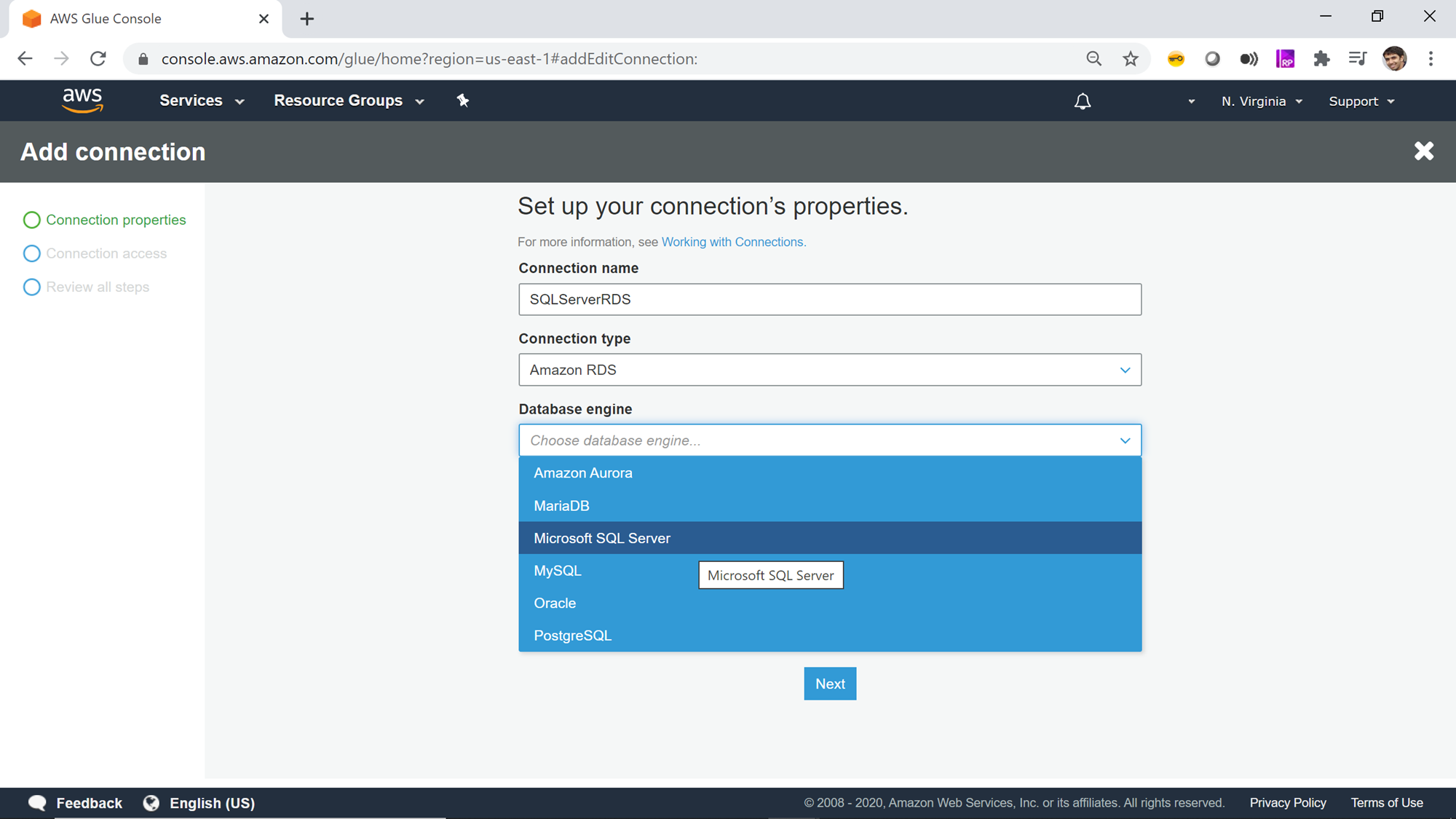
Provided the AWS RDS SQL Server instance is configured with public accessibility or with the network configuration such that the instance is visible to other services, you would be able to find the instance name listed in the instance dropdown. If the instance is not visible, it’s highly probable that either you do not have sufficient privileges to access the instance or the network configuration is blocking AWS Glue to access the instance. Assuming that you can access the instance, select this instance name from the instance list.
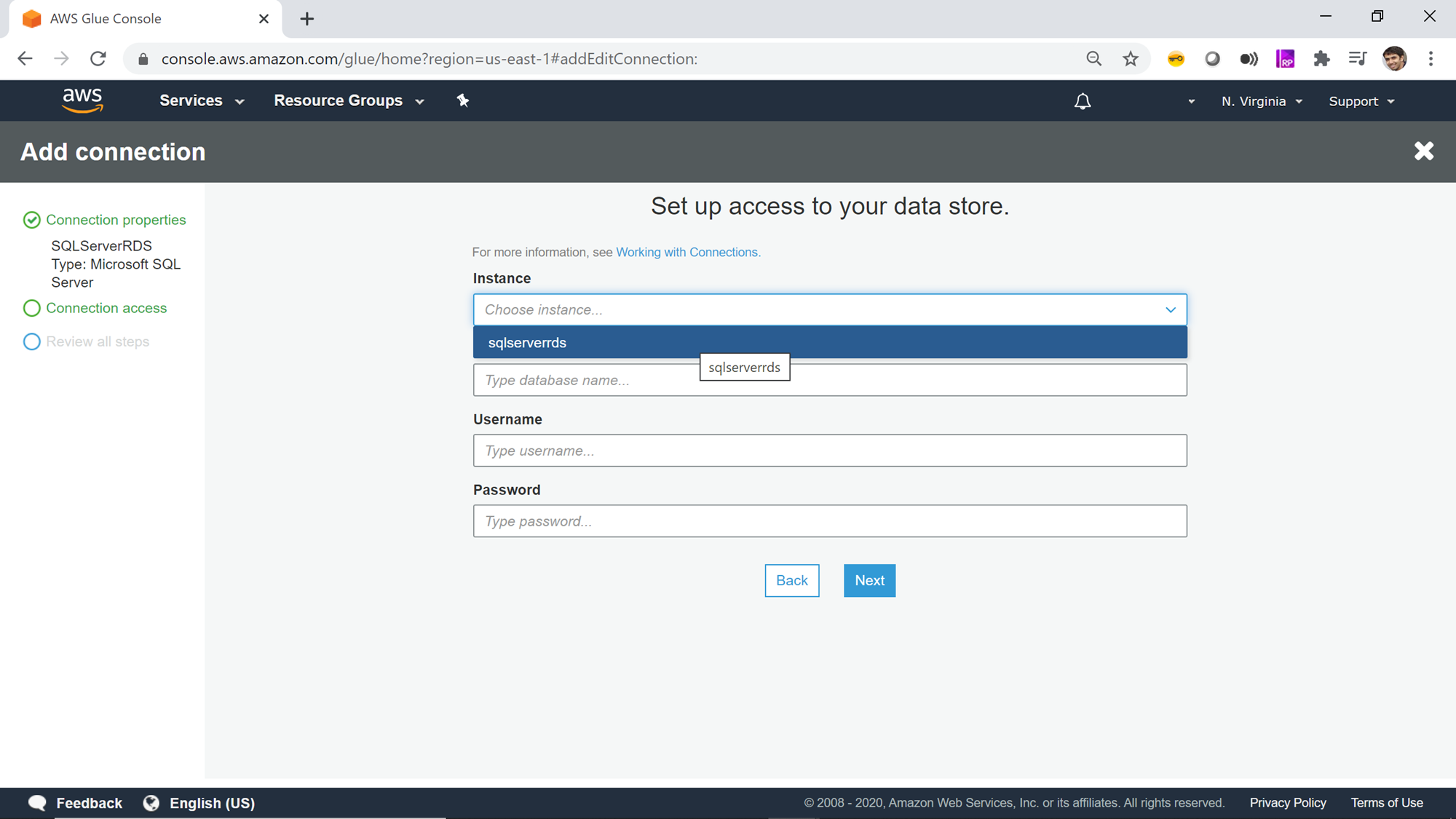
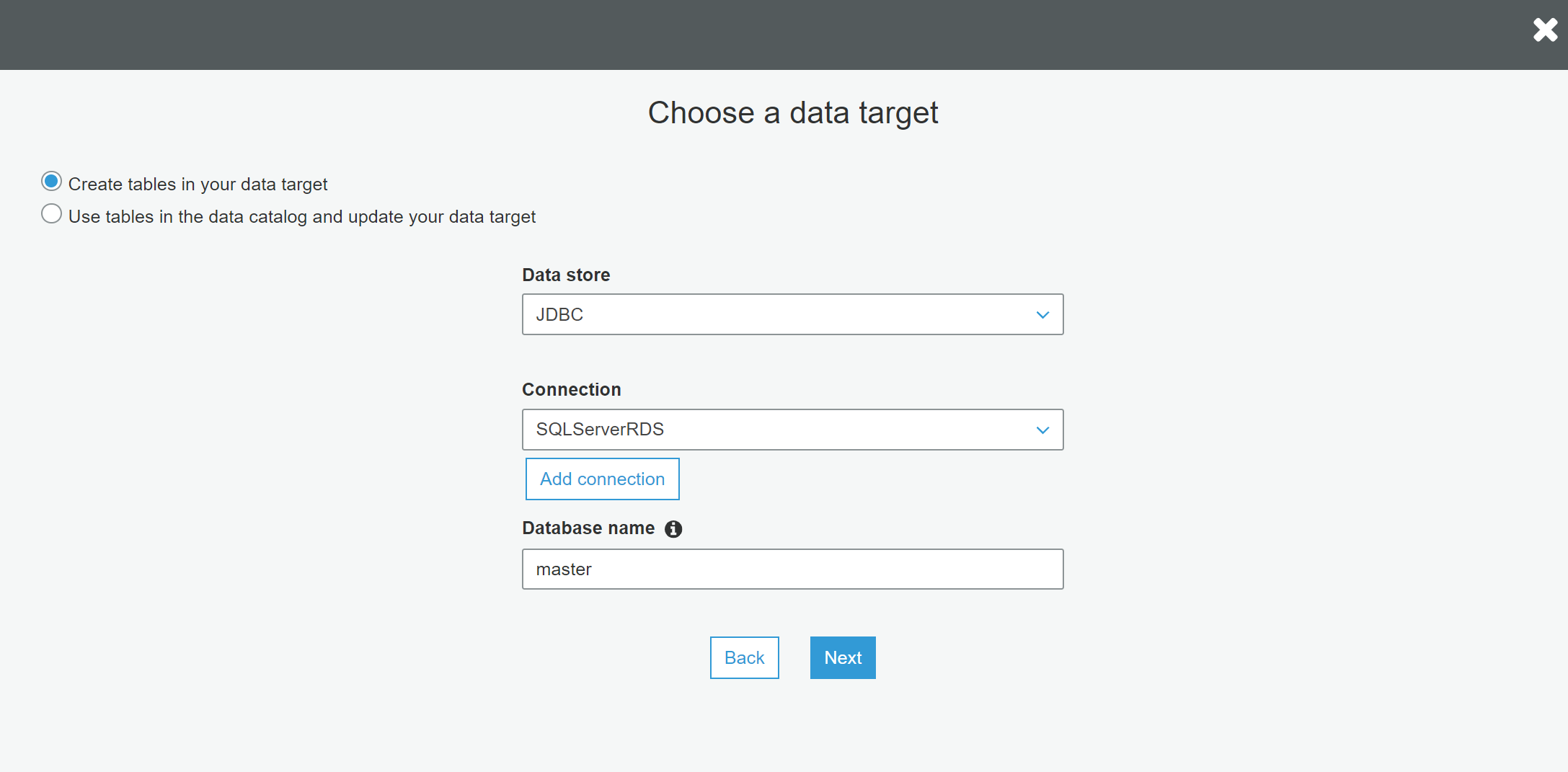
After selecting the instance name, provide the database name and database connection credentials (user id and password). In a brand-new AWS RDS SQL Server instance, you may not have new databases created. But every SQL Server database would have some system databases, which is sufficient to just create a connection and test the connectivity. Once you have custom or user databases created in the instance, you can edit this connection and point the connection to the desired database. For the purpose of this exercise, we can mention the database name as master, and provide the user name and password that allows access to the Amazon RDS for SQL Server instance as well as database as shown below and click Next.
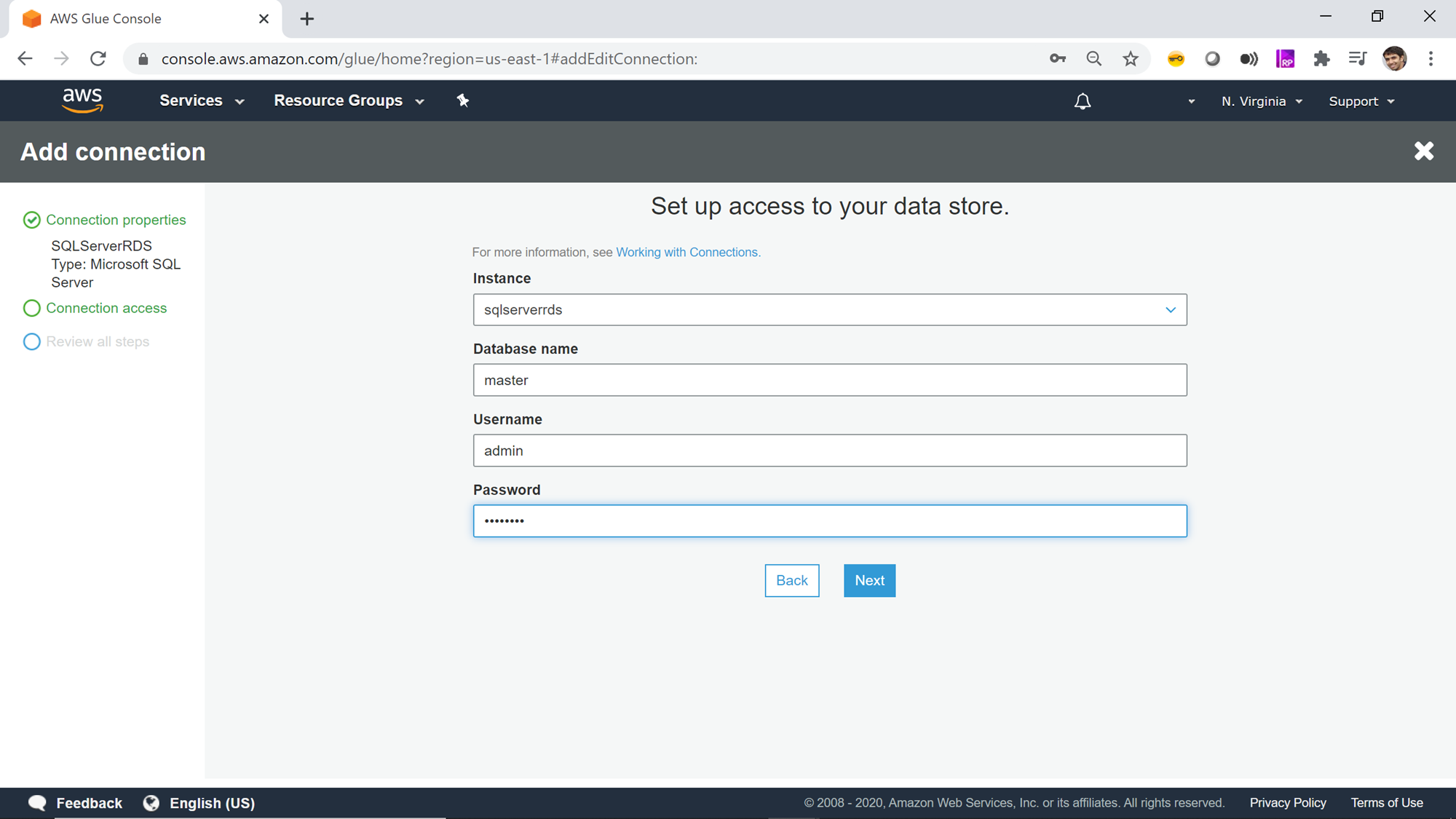
The next step just requires reviewing the details that we have provided in these two steps and confirm the creating of a new connection. Review the details and create a new connection. Once the connection is created, it would appear in the connections list as shown below.
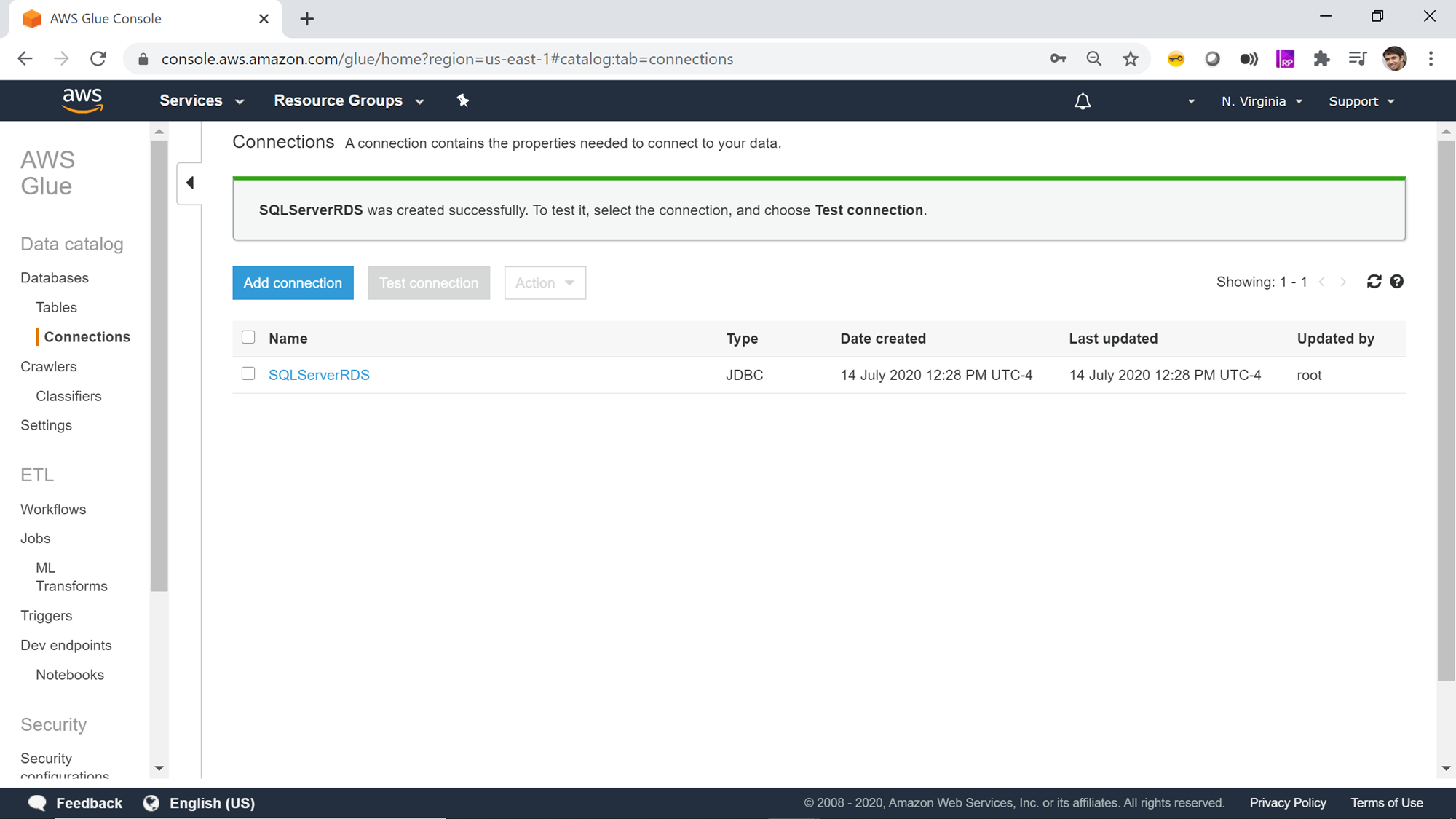
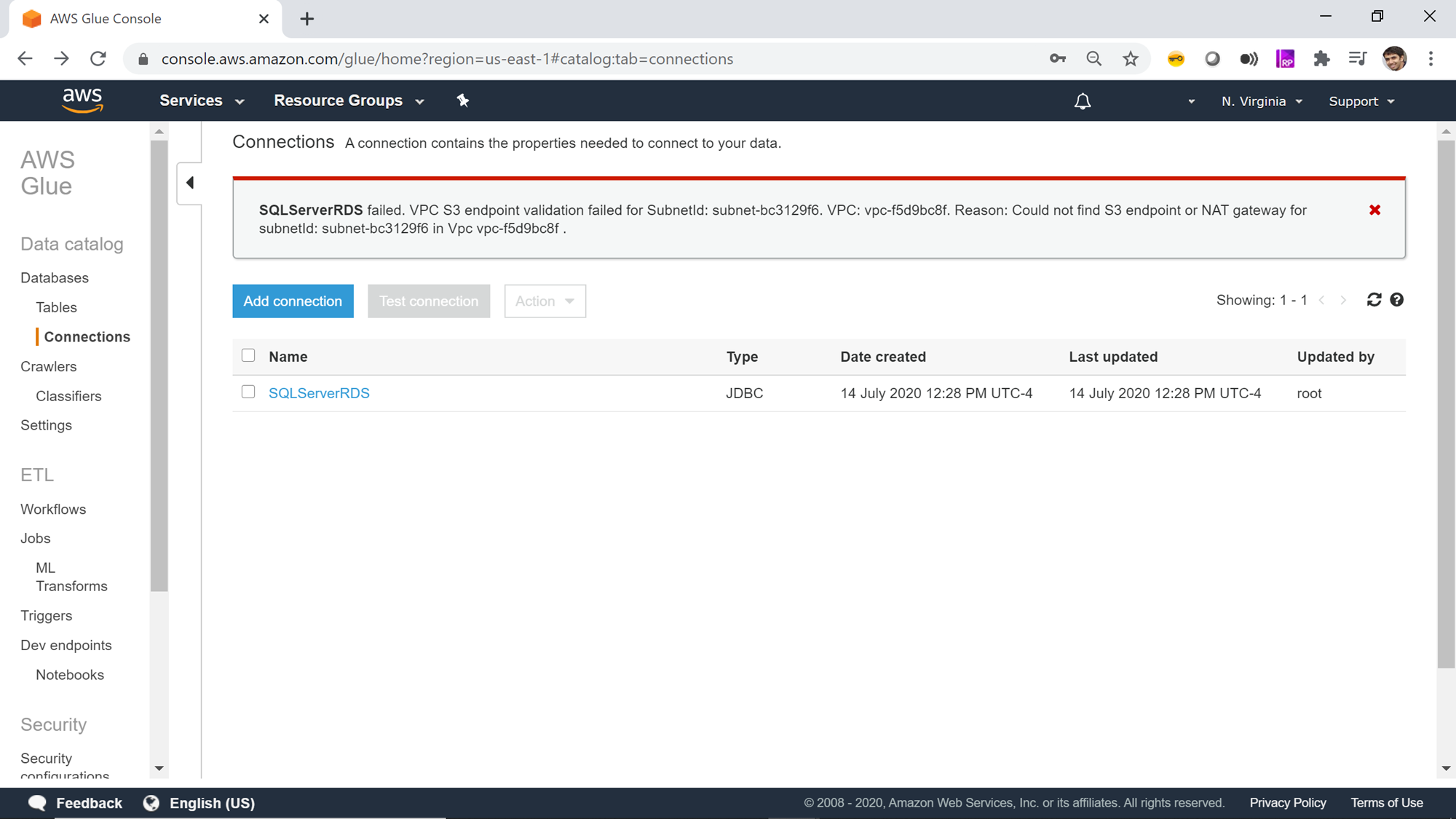
Now that the connection is created, it’s time to test the connection. Select the newly created connection and you would find that the Test connection button gets activated. Click on the Test Connection button and it would start opening an active connection to the AWS RDS SQL Server instance. You may find an error message as shown below and the connection would fail. The reason for the same can be network configuration that blocks AWS Glue from accessing JDBC enables data repositories or a missing VPC endpoint if the service is configured to access AWS S3 as well. You can read more about these configuration requirements from here.
Assuming the correct network configuration is in place, when you test the connection, it would succeed as shown below.
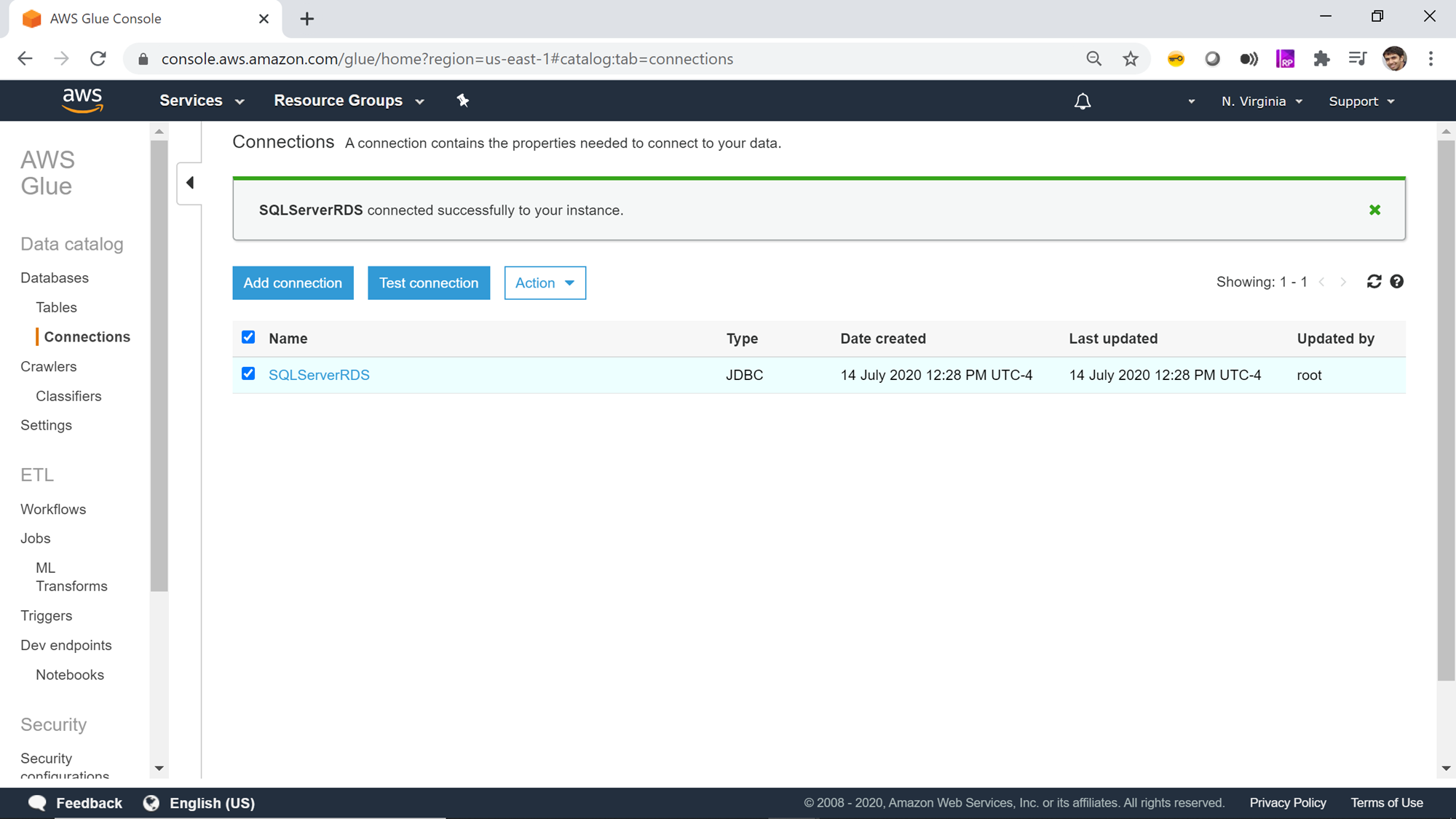
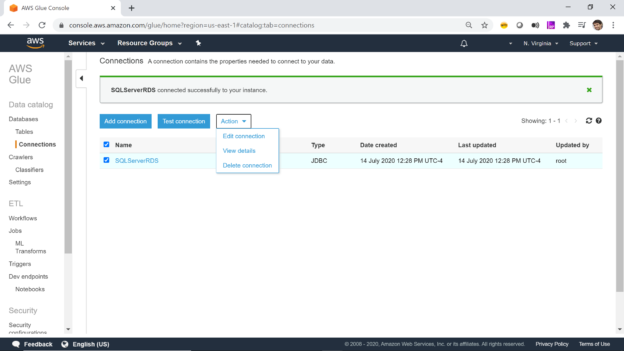
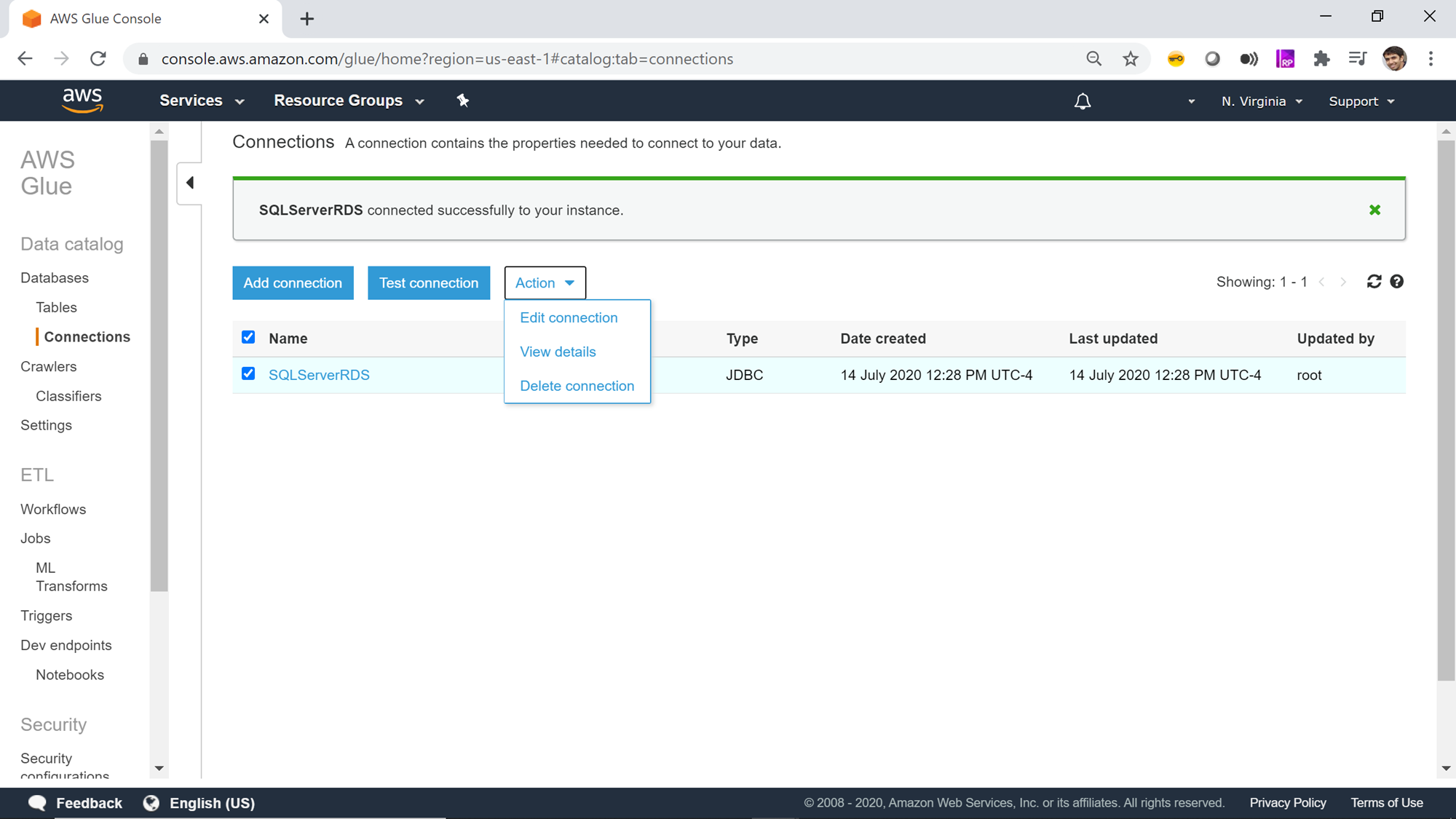
Once the connection is created and tested, you can click on the Actions menu to edit the connection, delete the connection, or view the details of the connection. It should be noted that connections in AWS Glue do not support tags which allows adding metadata to the objects. So, the name of the connection is the only mechanism to identify the purpose of the connection. Hence it is important to follow a naming convention that clearly identifies the purpose or repository of the connection, which would reduce or eliminate the need of viewing the details of each connection every time to know the target of the connection.
AWS Glue connection properties and details differ for each type of connection and data source selected in the connection. Consider reading this article to understand more details regarding AWS Glue connection properties.
Once the connection is in place, the same can be used in ETL Jobs and Workflows. An excerpt of how the connection would get listed when defining ETL Jobs is as shown above. There can be numerous ETL jobs that share the same connection. The benefit of this centralized connection approach is that just by changing the connection detail, all the ETL jobs start pointing dynamically to the updated target location, which eliminates the need to edit each ETL job individually.
Conclusion
In this article, we learned how to use the AWS Glue service to create connections to AWS RDS SQL Server instance. We configured the details required to connect to the instance and successfully tested the connection to the AWS RDS SQL Server instance and learned about the configuration we may need as well as errors we may face while establishing a new connection.
Table of contents

He has worked internationally with Fortune 500 clients in various sectors and is a passionate author.
View all posts by Rahul Mehta
- Finding Duplicates in SQL - February 7, 2024
- MySQL substring uses with examples - October 14, 2023
- MySQL group_concat() function overview - March 28, 2023