In this article, I’ll be exploring another new feature with SQL Server 2019, row mode memory grant feedback, along with a retrospective on adaptive query processing, examples and more.
Read more »
In this article, I’ll be exploring another new feature with SQL Server 2019, row mode memory grant feedback, along with a retrospective on adaptive query processing, examples and more.
Read more »
SQL Server Agent is a Microsoft Windows service which helps to execute, schedule and automatize T-SQL queries, Integration Service Package, SQL Server Analysis Service queries, executable programs, operating system, and PowerShell commands. These actions which are performed by SQL Server can be called by the SQL Server Agent. Maybe, we can liken SQL Server Agent to an alarm clock because the agent will execute the scheduled task when the time comes
Read more »
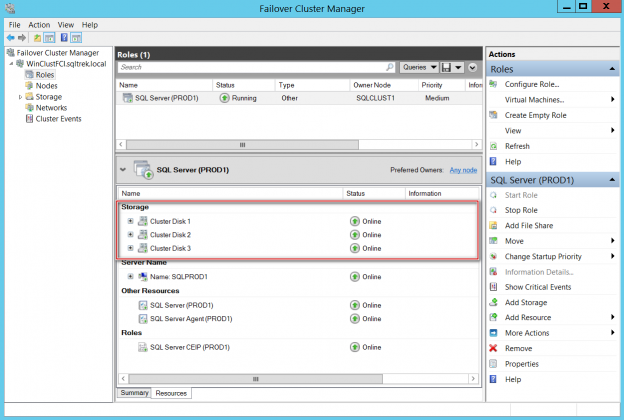
In the other article in this series: Deploy SQL Server for failover clustering with Cluster Shared Volumes – part 1 we have seen what a cluster shared volume is and what are the advantages and other considerations to keep in mind when deploying CSVs for SQL Server workloads. In this article, I will walk though actual installation of a failover cluster Instance leveraging CSVs.
Read more »
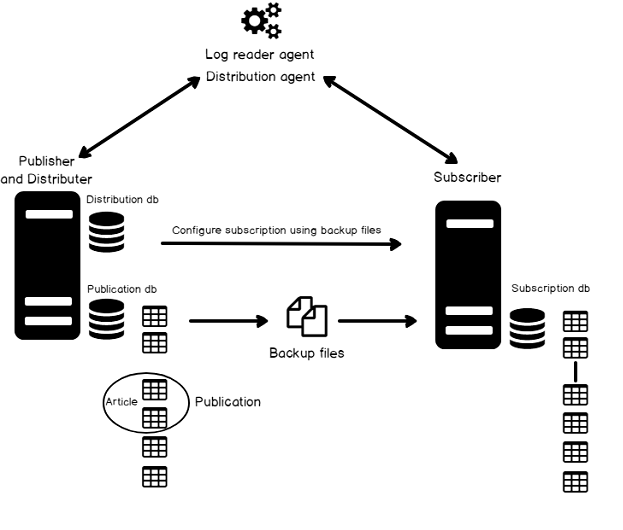
A workload management is considered as a critical aspect of SQL Server transactional replication. Replication is the oldest of the high availability technologies in SQL Server and it is available since the inception of SQL Server. As a very mature technology, SQL Server transactional replication is also very robust and, in most cases, very straightforward to set up and manage.
Read more »
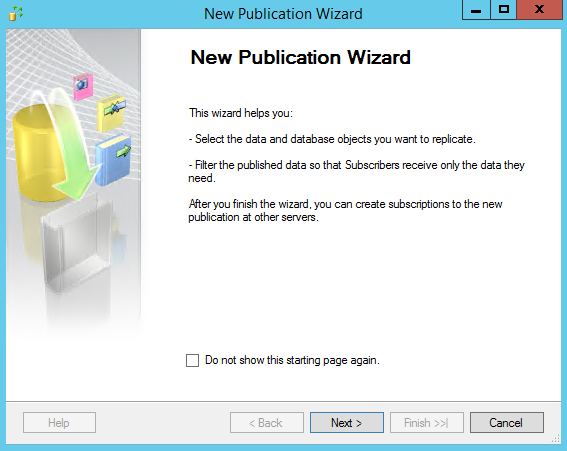
This is article is a continuation of the previous: SQL Server replication: Overview of components and topography.
By now, you’re familiar with the components of replication. So far, we’ve seen a lot of theory about replication. It’s a time for practical walkthrough of setting up a basic transactional SQL Replication system. The best way to get a feel for how SQL Replication is implemented and how it works is to see it in action.
Read more »
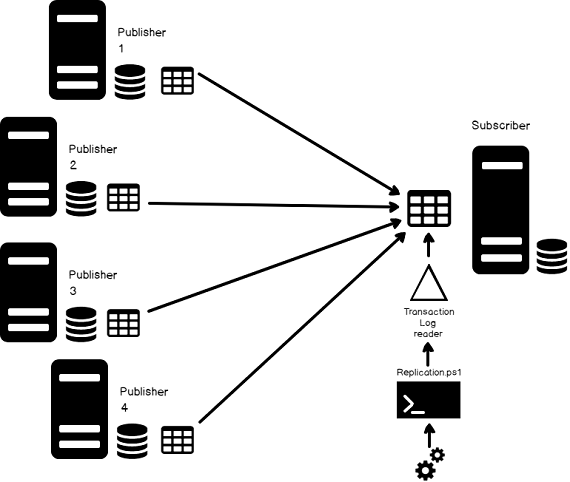
In this data-driven era, replication is often a critical requirement for achieving a modern, agile database management environment. It is believed designing an enterprise-grade dataset is the to achieving this requirement but building datamarts from datasets always presents certain challenges
In this article, we’ll discuss what it takes to setup “central subscriber with multiple publishers” replication model, to create an aggregate dataset from multiple sources, and you’ll also see how to scale with the data.
Read more »
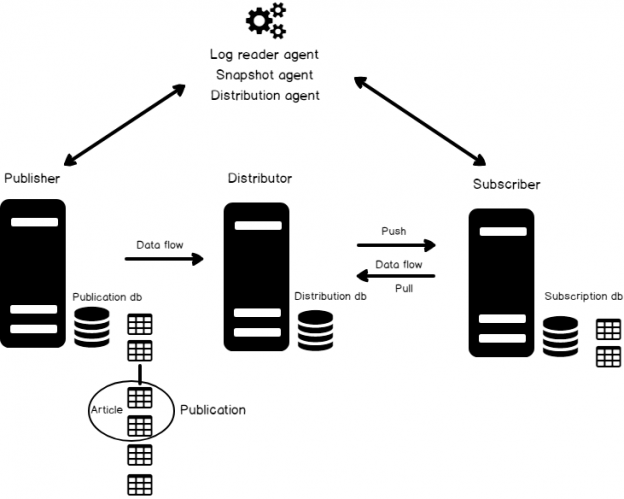
The volume of data retained, managed, and accessed today is unprecedented. Businesses expect the IT department to keep data online and accessible indefinitely, putting intense pressure on the databases required to store and manage it. To meet today’s needs; we need to replace outdated and inefficient legacy processes with new, more agile techniques. SQL Server Replication is one of the techniques to accommodate such demands.
Read more »
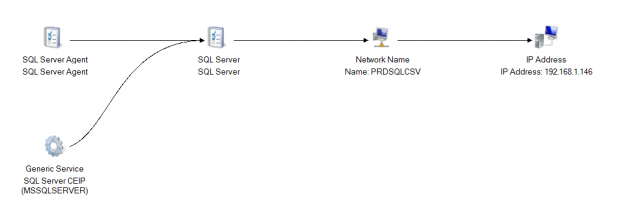
Microsoft SQL Server provides us with a wide variety of solutions to architect High availability (HA) and Disaster Recovery (DR) solutions for mission-critical workloads. In this article, let’s just focus on HA, specifically Failover Clustering. Failover clustering is probably the most mature, robust and stable high availability solution which Windows Server Operating system offers. It’s been there around for few decades now and did evolve over time along with SQL Server. In this article Let’s see a hidden feature of windows server failover cluster which helps in making our already highly available SQL Server Failover clustered instances even more highly available. The new feature which we are going to talk about is Cluster Shared Volumes, AKA CSVs. Considering windows server 2019 is around the corner, I say CSVs are not a new concept in clustering, it’s been there for almost a decade now. Microsoft introduced CSVs in windows server 2008R2, but at that time SQL Server was not supported on CSVs. Well, CSVs were originally designed for Hyper-V workloads and later on enhanced for File servers and eventually landed into SQL Server beginning version 2014.
Read more »
In most cases, an organization can either use the existing out-of-the-box database replication features offered by their database software provider or invest in custom solutions to execute and manage database replication processes. The latter option sometimes allows greater flexibility to create data replicas across multiple types on multiple platforms.
Read more »
Database mail is widely used by DBAs and companies around the world and is one of the features of SQL Server that can be very important for startups. That is because it is a cheap solution for getting alerts from your SQL Server for potential hardware issues, early warning signs of corruption, along with potential resource constraints. However, it can be misused or pose potential security issues. Before we start, to my myself clear I am in favor of configuring Database mail for the DBA team when done properly. In the rest of the article, we will touch on some of the common mistakes people make with database mail and their SQL Servers. We will not discuss the setup of this feature as it was well documented by Bojan Petrovic on SQLShack.
Read more »
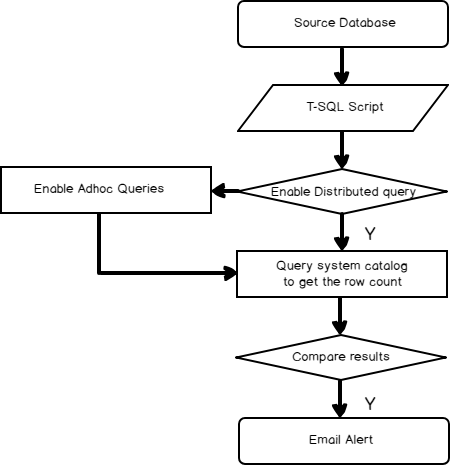
Bringing impactful analysis into a data always comes with challenges. In many cases, we rely on automated tools and techniques to overcome many of these challenges.
Read more »
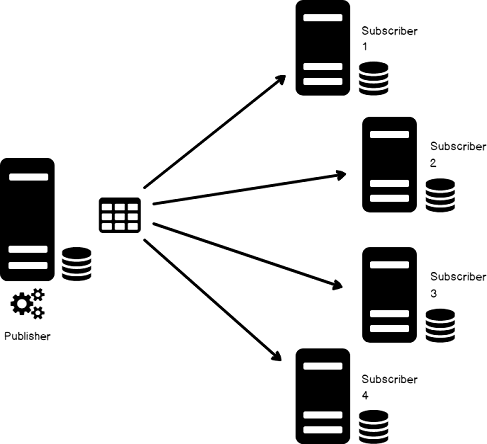
In this article, you’ll learn how to setup a simple, custom distributed database replication system.
In general, a typical setup of transactional replication model of a central publisher with multiple subscribers includes the creation of a replica database(s) which may serve multiple purposes including:
Read more »
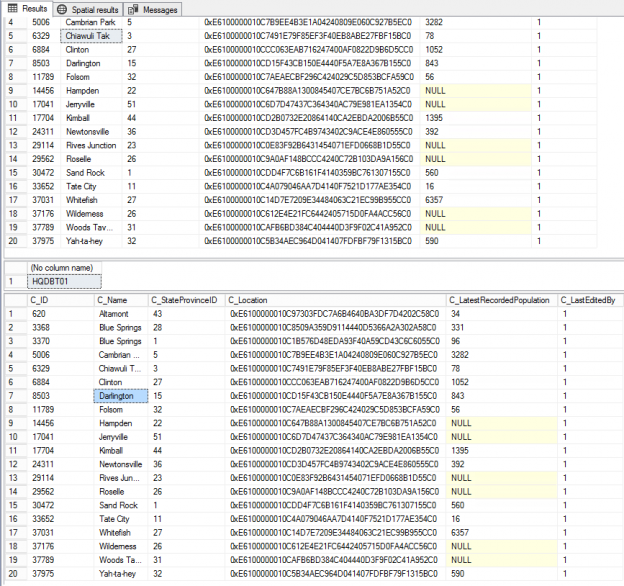
This article discusses the challenges of meeting the availability, and performance requirements of high ended transactional replication environments. In addition, you’ll learn a new innovative approach that can be used to add/drop articles from an existing replication environment while maintaining replication system up and running.
Read more »
Business transformation requires solid tools to automate complex integration to seamless deployments. In today’s modern data-rich world, nothing is more important than data management, making it critical to know how to safeguard and meet compliance requirement is very critical and the key to the business success.
Read more »
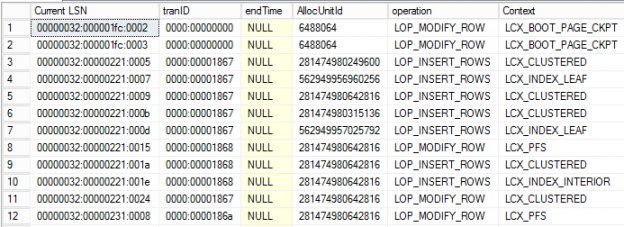
In this article, we’ll discuss how to read SQL Server transaction logs. This article should provide and insight into how the workload is being captured in the transaction log files. We are going to see how to get the transaction meta-data details and the history of the data will give us a clear idea of how the system is working and helps to decide peak usage hours, also helps to log information about who is doing what?
Read more »
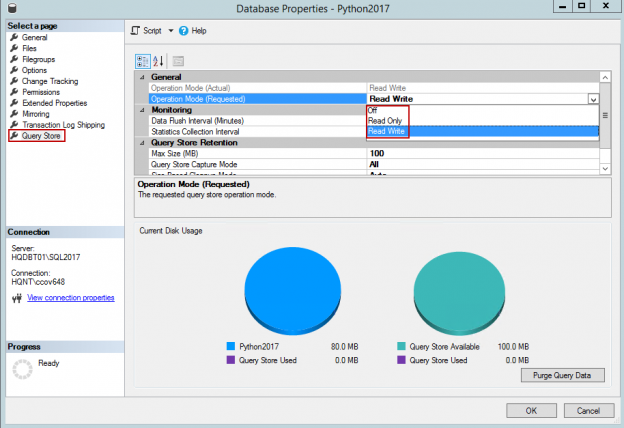
Monitoring databases for optimal query performance, creating and maintaining required indexes, and dropping rarely-used, unused or expensive indexes is a common database administration task. As administrators, we’ve all wished, at some point, that these tasks were simpler to handle.
Read more »
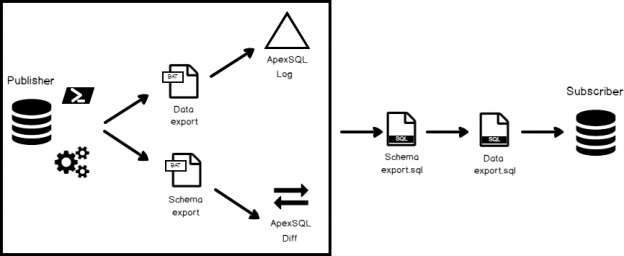
In the article How to setup SQL Server database replication for reporting Server we discussed all about setting up a simple SQL Server transactional replication environment. In this article, we’ll simulate a more robust system that replicates faster and includes both DDL and DML statements. We’ll walk-through the steps to setup a dynamic transactional replication.
Read more »

SQL Server is pretty good at managing disk space. As long as we do our part to set up appropriate storage types and place files and filegroups properly and set reasonable AUTOGROW settings, it’s almost a set-it-and-forget-it operation. Mind you, I said, “almost!” Sometimes, things do go BUMP! in the night and we need to act. Here’s what happened to me not too long ago:
Read more »
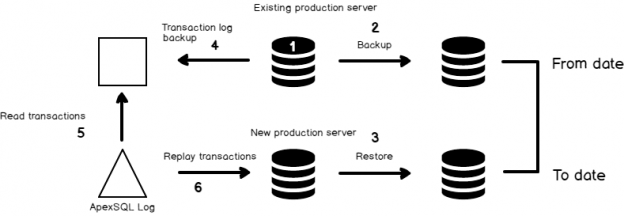
The growing importance and complexity of data migration, in an era of exploding data volumes and ever-changing business requirements, means that old approaches will no longer get the job done. We are in a world where everything needs to run instantly. Every Database Administrator or Developer would have definitely heard about database migrations with zero downtime and with zero data loss.
Read more »
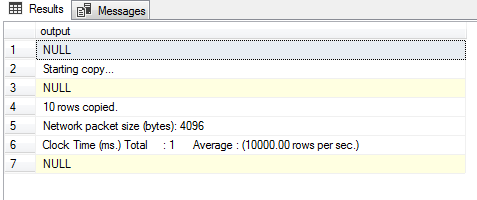
There are various methods available for bulk data operations.
The BCP (Bulk Copy Program) utility is a command line that program that bulk-copies data between a SQL instance and a data file using a special format file. The BCP utility can be used to import large numbers of rows into SQL Server or export SQL Server data into files. The BCP data files don’t include any schema details or format information. Hence, it is recommended to create a format file to record the data format so in case of any failures, you can refer to the format file and better understand the data format to determine what may have gone wrong..
We’ve been using the BCP tool for a long time, the reason being that it has a very low overhead, and works great for bulk exporting and importing of data. It is one of the most efficient ways to handle bulk import and export of data.
Read more »
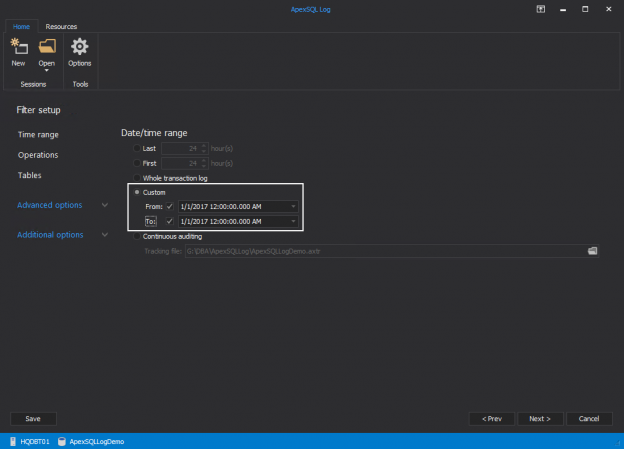
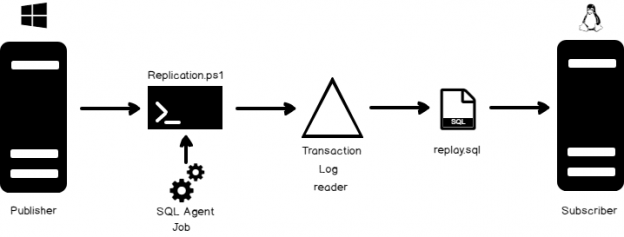
In this article, you’ll see how to simulate production loads on a test server with a “record and replay” type situation using the transaction log, batch scripting, PowerShell and a SQL Server agent job.
We’ll be walking through the scenario in the following steps
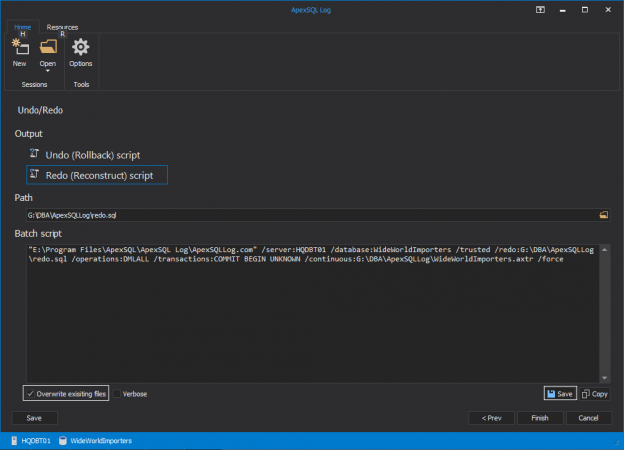
In this article, we’ll discuss the purpose of database replication and show how you can implement Replication using ApexSQL Log, a SQL Server transaction log reader.
Read more »
So, your manager wants you to figure out how to encrypt sensitive Data? Well, Microsoft has introduced a fairly easy way to configure feature called Always Encrypted. Read more »

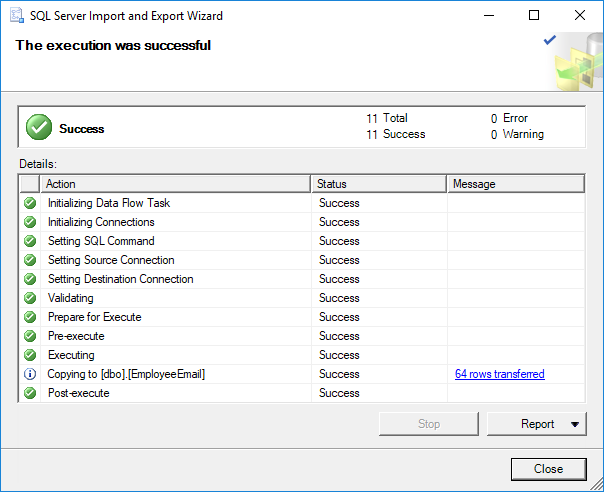
The process of importing or exporting large amounts of data into a SQL Server database, is referred to as bulk import and export respectively. Fortunately, we are provided with a plethora of native tools for managing these tasks incluing
Read more »
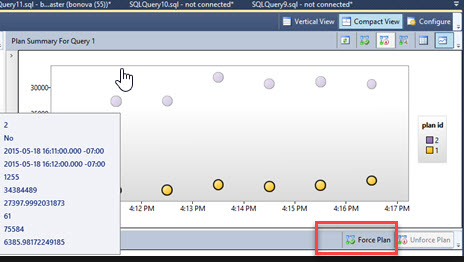
Query store was introduced in SQL Server 2016. It is often referred to as a “flight data recorder” for SQL Server. Its main function is that it captures the history of executed queries as well as certain statistics and execution plans. Furthermore, the data is persistent, unlike the plan cache in which the information is cleared upon a server restart or reboot. You can customize, within Query Store, how much and how long the query store can hold the data.
Read more »© Quest Software Inc. ALL RIGHTS RESERVED. | GDPR | Terms of Use | Privacy