
The growing importance and complexity of data migration, in an era of exploding data volumes and ever-changing business requirements, means that old approaches will no longer get the job done. We are in a world where everything needs to run instantly. Every Database Administrator or Developer would have definitely heard about database migrations with zero downtime and with zero data loss.
Objective
Database migrations could lead to downtime. How can we deal with database migrations when we don’t want our end-users to experience downtime but also want to keep data up-to-date, with no missing data?
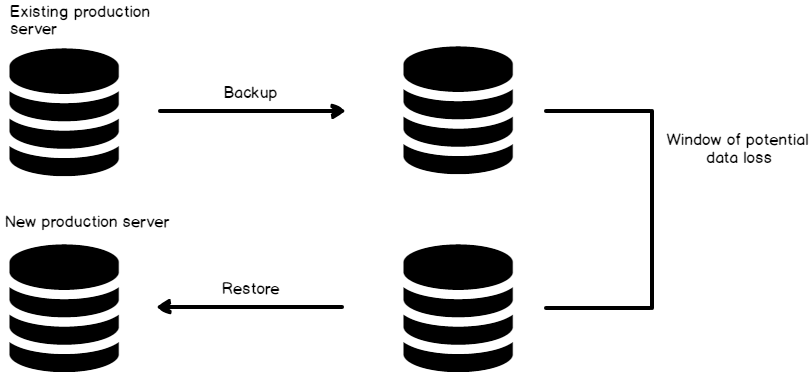
Let us consider a scenario where you’re performing a migration where backing up and restoring the database might take 30 minutes. That means either 30 minutes of downtime or potentially a 30-minute window of lost data. How can we avoid end user downtime and also avoid data loss?
The traditional database migration approaches have several limitations and its near-impossible task to maintain an exact replica of the production without a downtime because transactions that occur during the migration process will be lost or if the database is taken offline during the migration process, you will have downtime
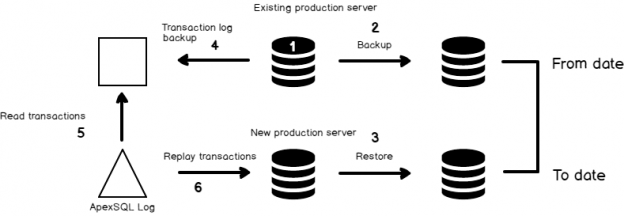
In this article, we’ll show how we can backup a production database and then restore it to a new location, while not taking the production system offline nor losing data during our migration window.
We’ll allow the client application and database to keep running through the entire process. Once we restore the database to production, we’ll capture all of the transactions that were made on the production system, during the migration, and replay them on production to ensure there is zero downtime.
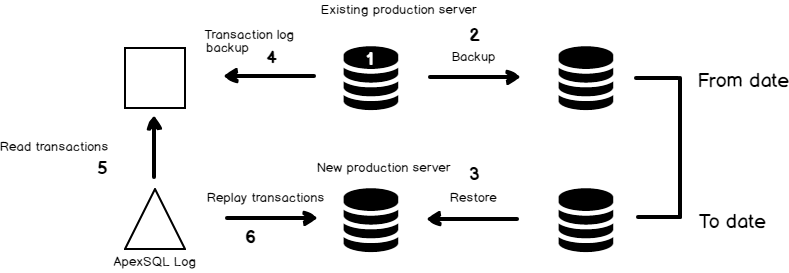
The process
The backup and restore database technique is the core of SQL Server High-Availability technique and also a base for database migration. This process is adopted to reduce the downtime of database migration. As it’s an online process, we can initiate a backup while the users online. But even so, there is a period of time in between the initial backup and the final restore, where transactions will be lost. That is where a transaction log reader comes in handy.
Let us take a look at the 3rd party too, ApexSQL Log. ApexSQL Log helps you to read the SQL Server transaction log quickly and efficiently. We’ll use this to capture the missing transactions and replay them on the new server
- Backup the source database
-
Restore the new database with recovery on—the target database is online and it is ready for use
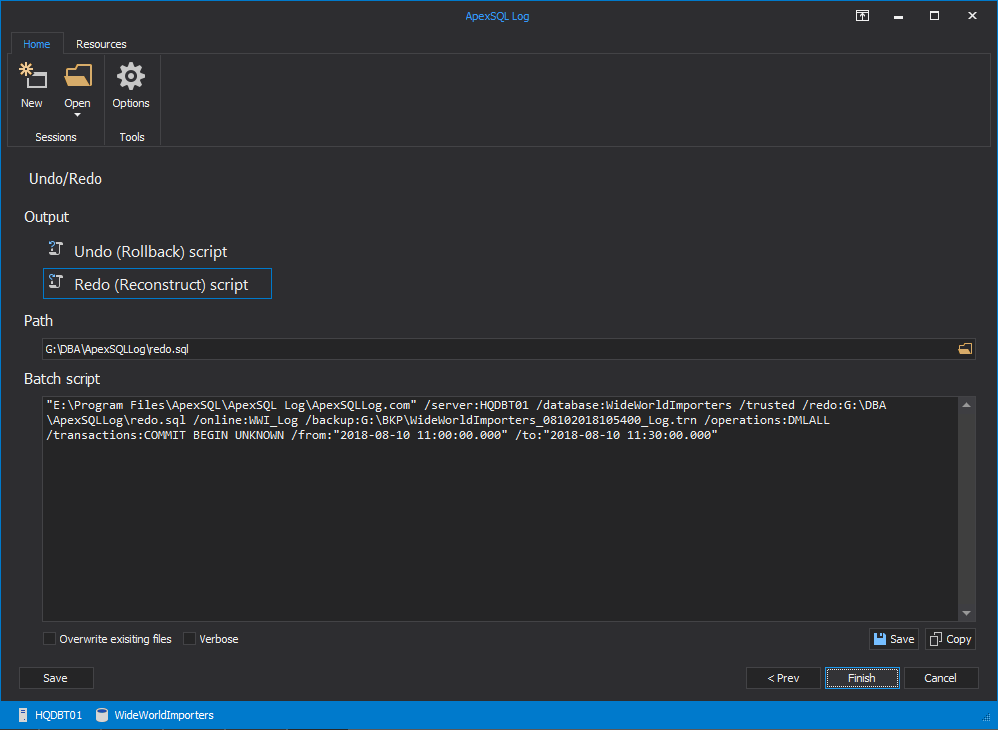
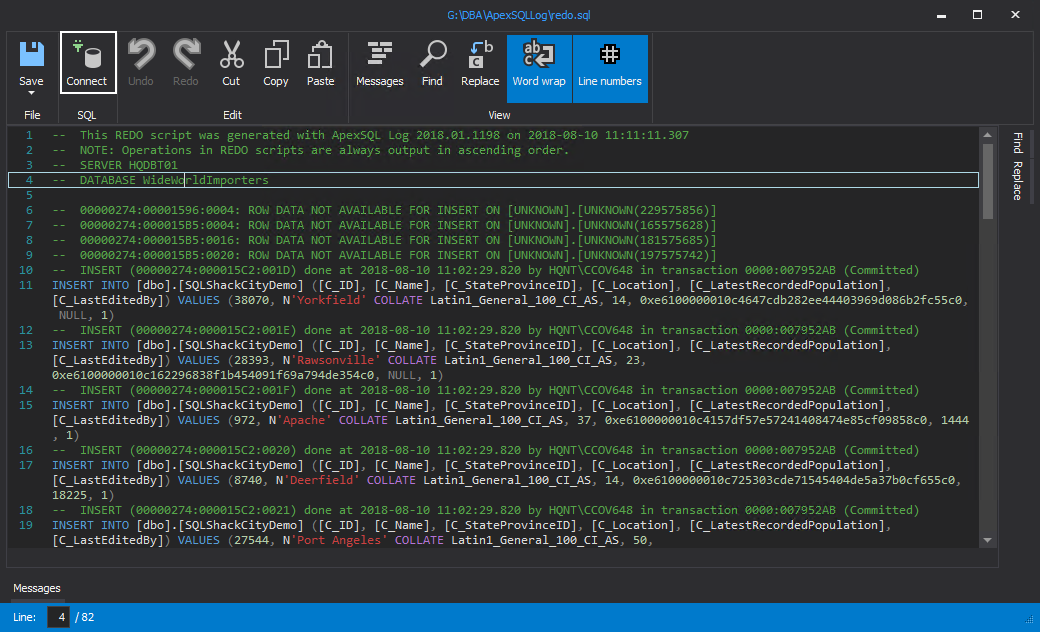
Initiate the transaction log reader at the source database to read all of the transactions that were committed during our migration window. In doing so, you will generate the SQL script of the delta changes since the last FULL backup. The available options and configurations are easy to customize. The process of scripting the committed transactions (redo.sql) is very simple and the generated SQL can be applied to target at a later point in time to synchronize any differences that happened during the backup and restore window.
- Applying transactions is an online operation. In real-time, you just need to change the network configuration (DNS entry to point to a server) and all done. Also, the residual transactions are applied to the new databases online. It means the data loss is “Zero” and migration can be implemented under the concept of “Zero downtime”.
Demo
Let us walk through the entire process using World-wide-importer database.
We will have assumed you’ve backed up your source database and restored it to a new location. When you have restored it, you should take a backup of the transaction log for the original database.
Note the time that you backed up the production database and also the time that you switched over to the new database. These dates and times will be used to create the window by which we capture transactions from the original production system
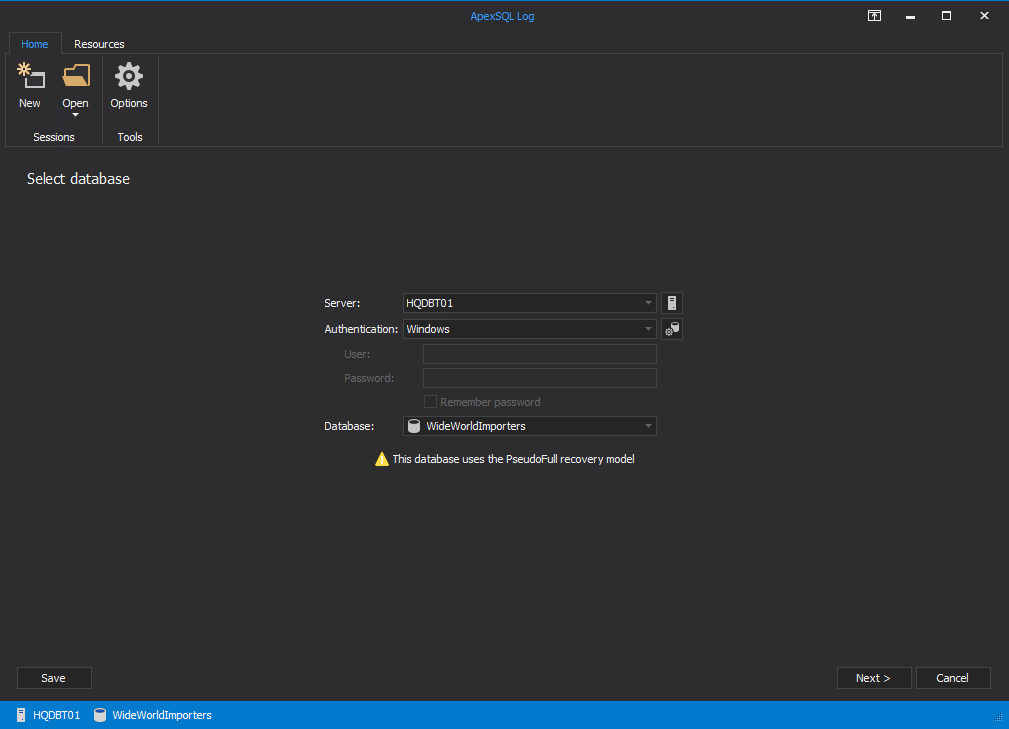
- Open ApexSQL Log
-
Connect to SQL Server instance and choose the WWI database

-
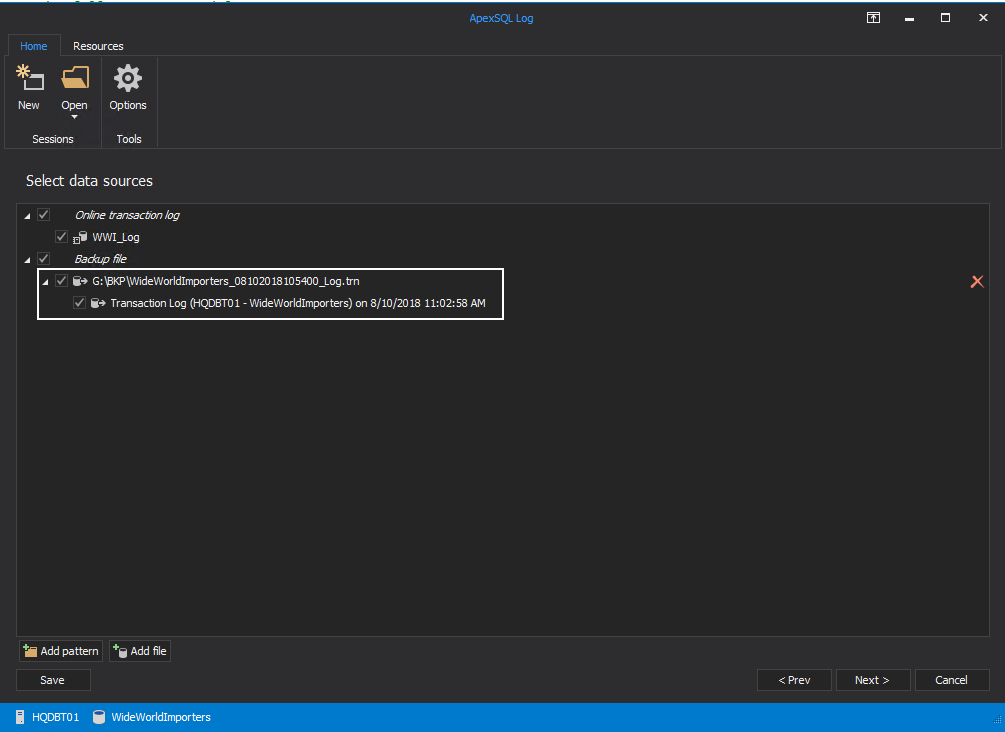
Select transaction log file sources
-
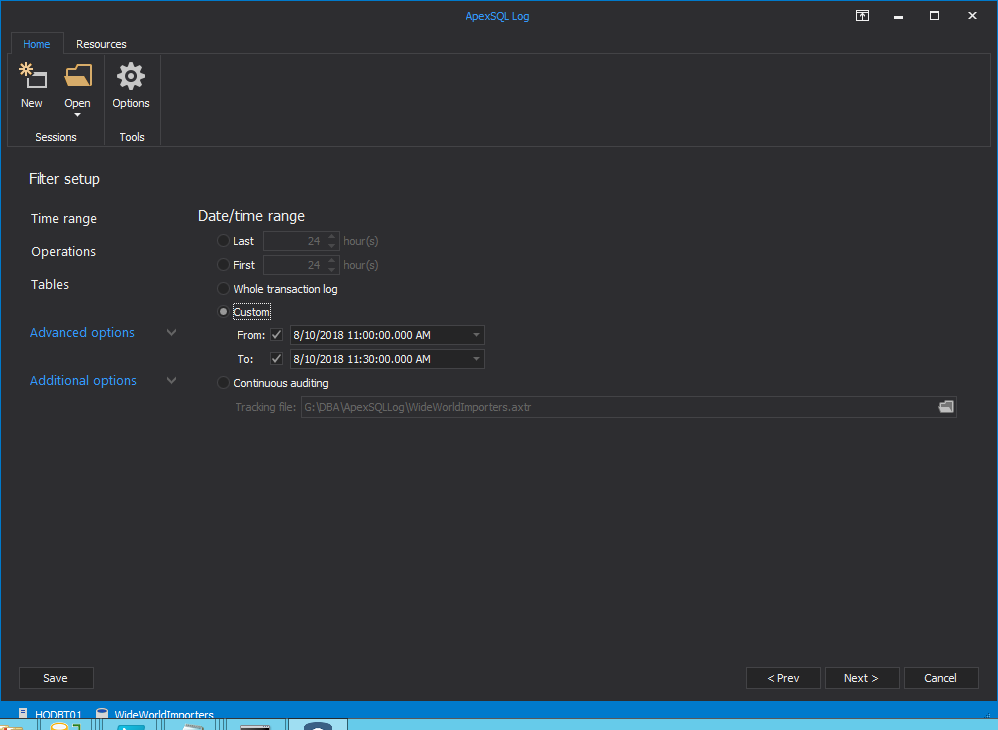
Select Custom and enter in the dates and times From when the original production system was backed up To when the new production system was put online.
-
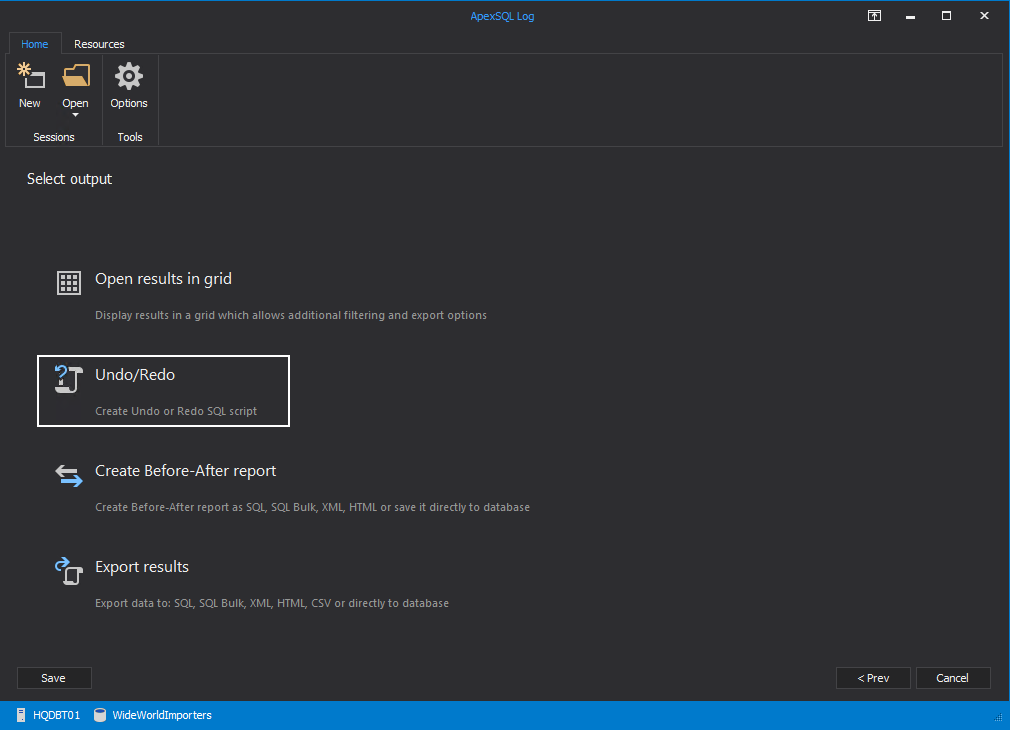
Next, choose Undo/Redo to generate a redo.sql file
-
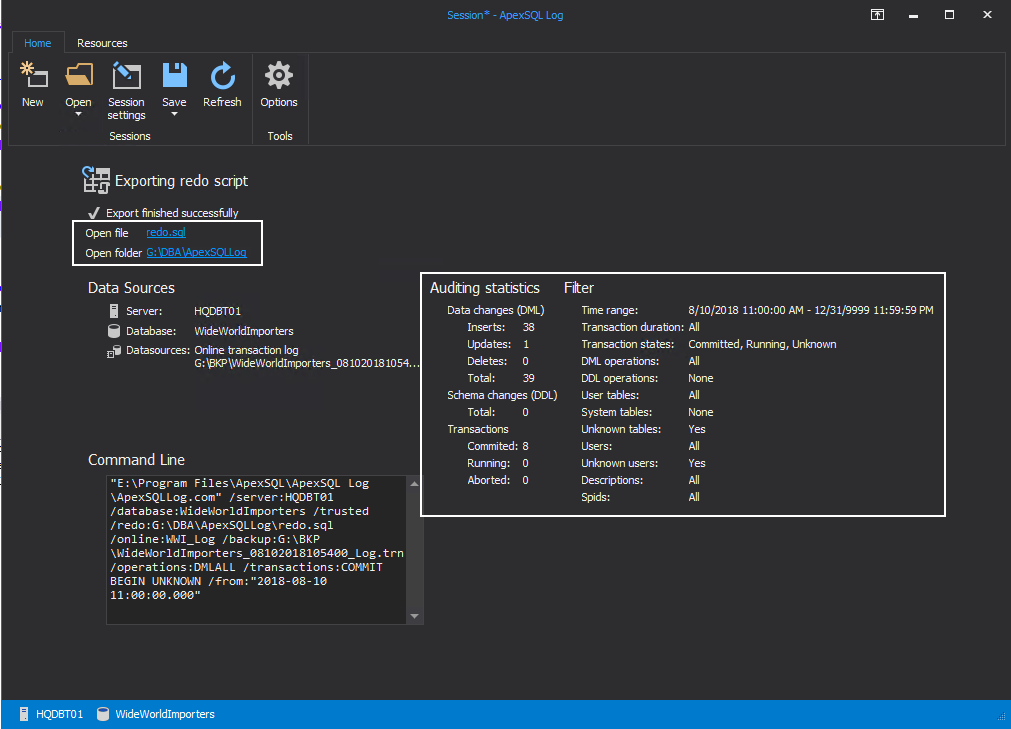
To generate the SQL, Click Finish.
You can see a lot of statistical data about the DML operation that was performed since the last full backup. This represents data that would have been lost or activity that would have been prevented, during a downtime window
-
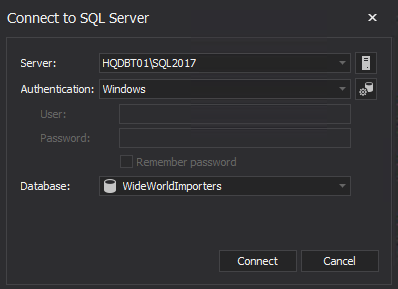
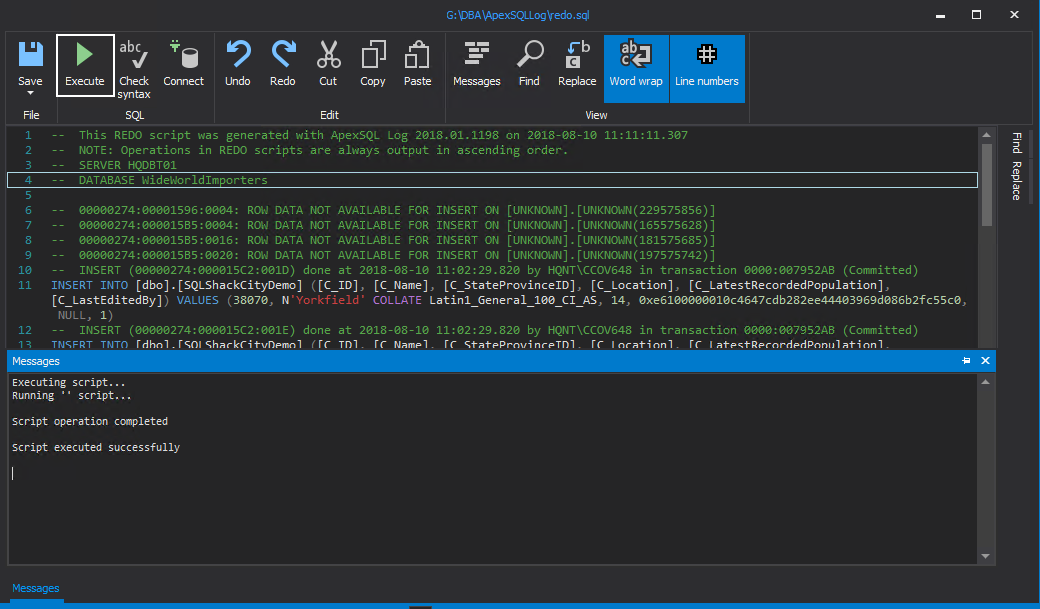
Now, let’s run this script(redo.sql) against our newly restored production database. To run, Click redo.sql. This will open up a query execution window. Click Connect and type in the target instance details. Then, click Execute to run the SQL script.
We’ve successfully moved our database without losing a single row of data!
Wrap Up
In this article, we reviewed how to address the gap in data inherent in many database migrations, due to the fact that new data/transactions that occur since the last backup but before the new system is turned online are lost. The “answer” is often to shut down the production system for a maintenance window and lock out users, but this results in system downtime. By keeping the system up, recording the transactions during the latency period and then replaying them on the new production server, you can both keep the system up 100% and avoid any data loss
Table of contents

My specialty lies in designing & implementing High availability solutions and cross-platform DB Migration. The technologies currently working on are SQL Server, PowerShell, Oracle and MongoDB.
View all posts by Prashanth Jayaram
- Stairway to SQL essentials - April 7, 2021
- A quick overview of database audit in SQL - January 28, 2021
- How to set up Azure Data Sync between Azure SQL databases and on-premises SQL Server - January 20, 2021