The purpose of this article is to give newbies some basic advice about SQL performance tuning that helps to improve their query tuning skills in SQL Server.
Read more »
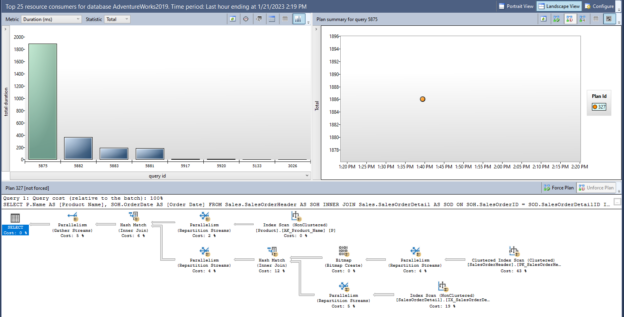
The purpose of this article is to give newbies some basic advice about SQL performance tuning that helps to improve their query tuning skills in SQL Server.
Read more »
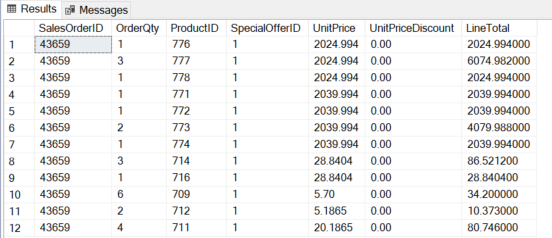
Today we will learn about the SQL IN operator. The RDBMS systems are very popular today in terms of data storage, data security, and data analysis. SQL stands for Structured Query Language which is used to create, update, or retrieve data in RDBMS or Relational Database Management Systems like SQL Server, Oracle, Microsoft Access, MySQL, and PostgreSQL.
Read more »
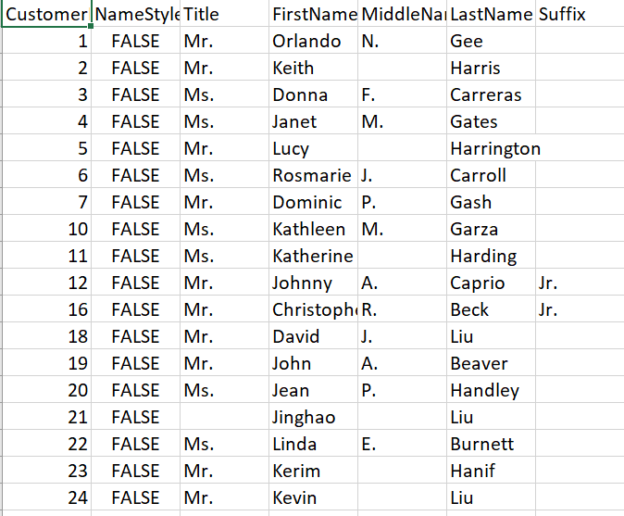
This article will provide an understanding of identifying duplicate values in SQL.
Read more »
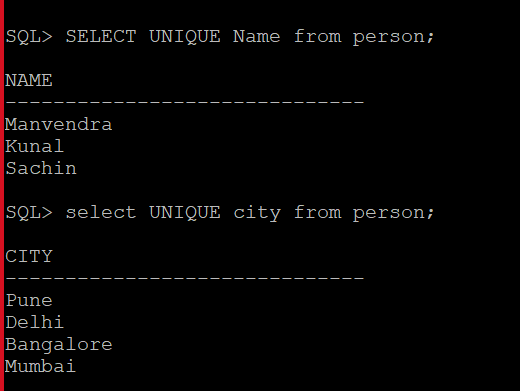
Today, we will learn the difference between SQL SELECT UNIQUE and SELECT DISTINCT in this article. As we all know that SQL is a query language that is used to access, create, delete, and modify data stored in a database system like SQL Server, Oracle, MySQL, etc. All these database systems have their query language like TSQL, PLSQL, etc. These query languages are based on ANSI standard SQL language which can also be used in these database systems to perform any transaction.
Read more »
This article explains some of the popular SQL Server monitoring tools and techniques.
Read more »
In this article, we will show a PostgreSQL tutorial to create a user using PgAdmin and PL/PgSQL.
Read more »
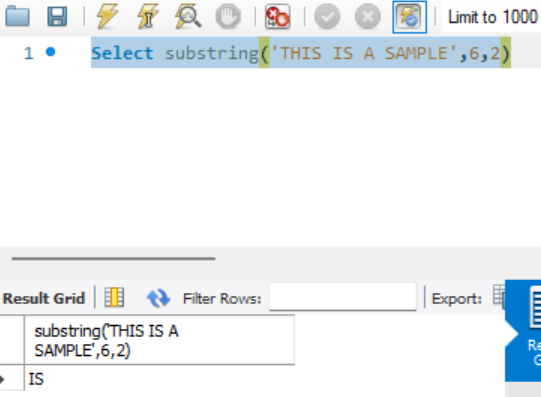
This article will provide an understanding of different ways to use substring in MySQL.
Read more »

This article will show PostgreSQL Data Types with various examples.
Read more »
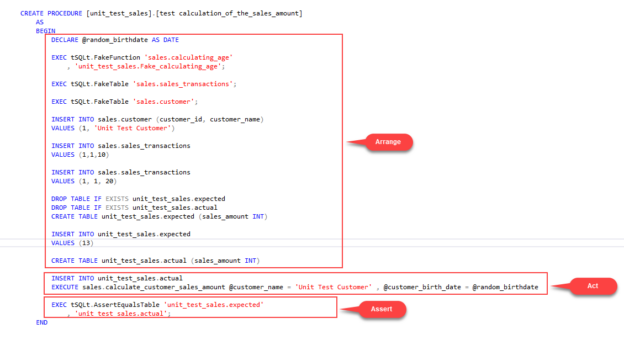
In this article, we are going to learn the basics of SQL unit testing and how to write a SQL unit test through the tSQLt framework.
Read more »
This article covers the different methods to install Postgres on Ubuntu.
Read more »
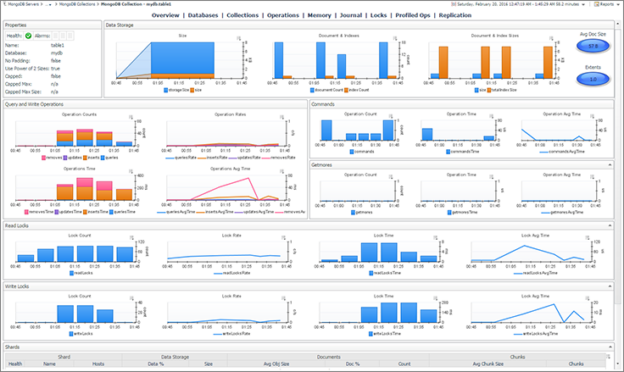
This article explains what database monitoring is and why it is essential. Then, it illustrates the different methods for monitoring MongoDB NoSQL databases.
Read more »
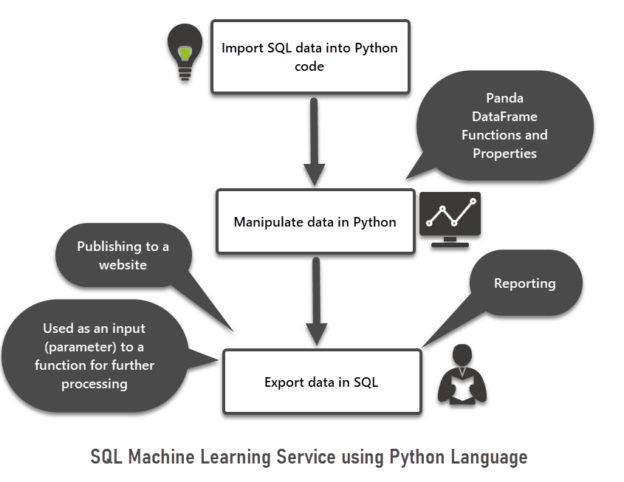
This article is about SQL Machine Learning which is one of the most interesting topics equally attractive to both beginners and professionals of different areas of expertise.
Read more »
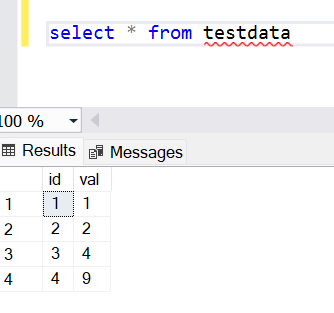
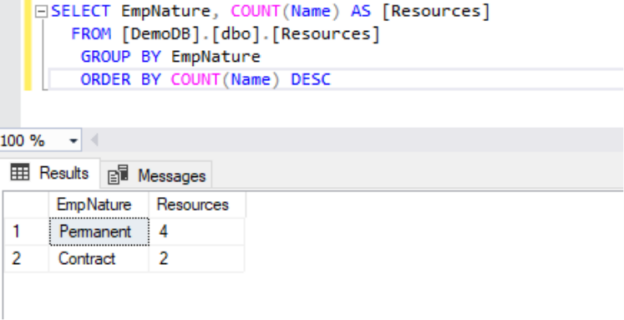
Today, I am going to explain how to do a group by clause in your SQL queries. SQL (Structured Query Language) is a very popular query language that is widely used to access and manipulate records stored in a database. The GROUP BY clause is also a SQL statement that is used to group identical values. Let’s first understand this clause what it does and why we use this clause in SQL queries.
Read more »
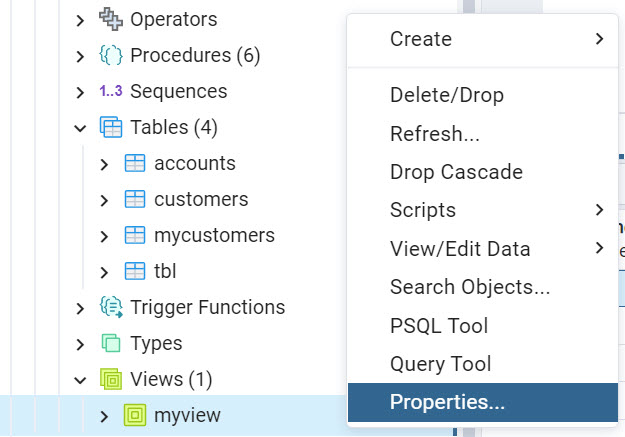
In this article, we will have a tutorial to learn PostgreSQL. According to Statista, PostgreSQL is the 4th most popular database in the world (the other ones are Oracle, SQL Server, and MySQL). That is why we think it is an important DBMS to learn.
Read more »
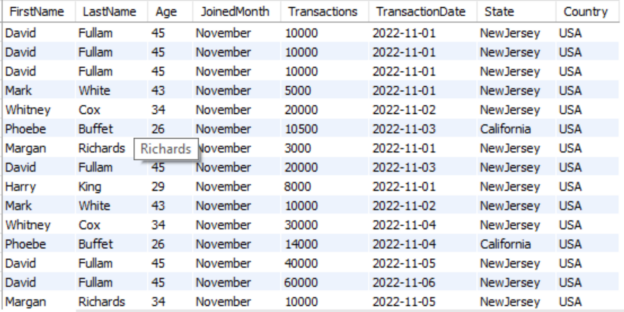
This article will provide an understanding of how to effectively use group concatenation in MySQL.
Read more »
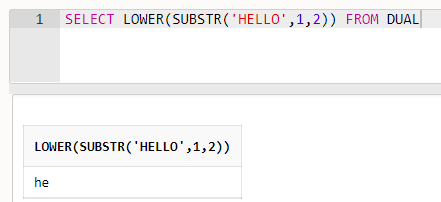
The Oracle SQL database provides many useful functions to use with your query or programming. The SUBSTR function is one of the most used string functions in the Oracle SQL database. I will also discuss a few important string functions TRIM, UPPER, and LOWER which can be used along with substring functions. In this article, we will discuss substring in Oracle SQL.
Read more »

Today, we will compare the two most popular database products PostgreSQL vs MySQL, and explain the differences between them in this article. There are many database systems based on the relations database management system (RDBMS) concept in the market. Some of them are Oracle, SQL Server, MySQL, PostgreSQL, etc. It’s really important to understand the differences between them before selecting any database product for your application. Keeping this in mind, I am writing this article to explain these two database systems i.e., PostgreSQL vs MySQL, and compare them from various aspects so that you can understand them before taking any decision for your requirements.
Read more »
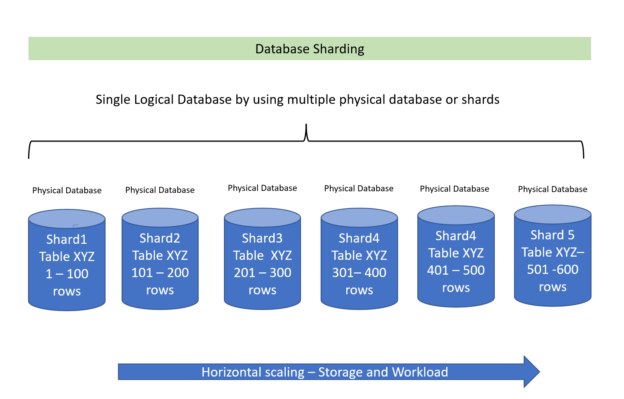
When an application grows the associated database grows automatically. It needs to be scaled to a larger machine or server and overall configuration needs to be increased to handle the application and database performance requirement.
Read more »
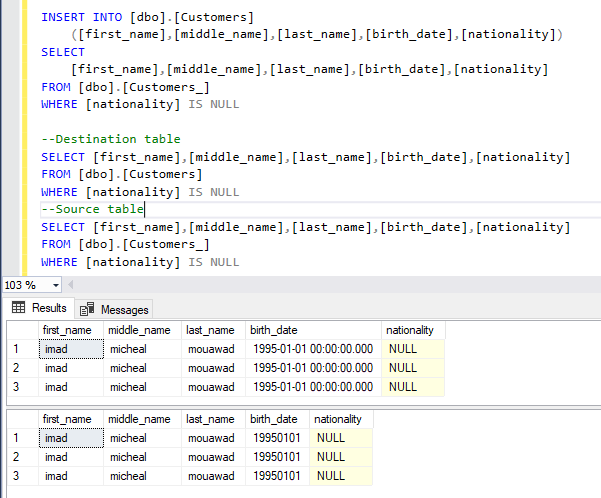
This article explains the different approaches used to insert multiple rows into SQL Server tables.
Read more »
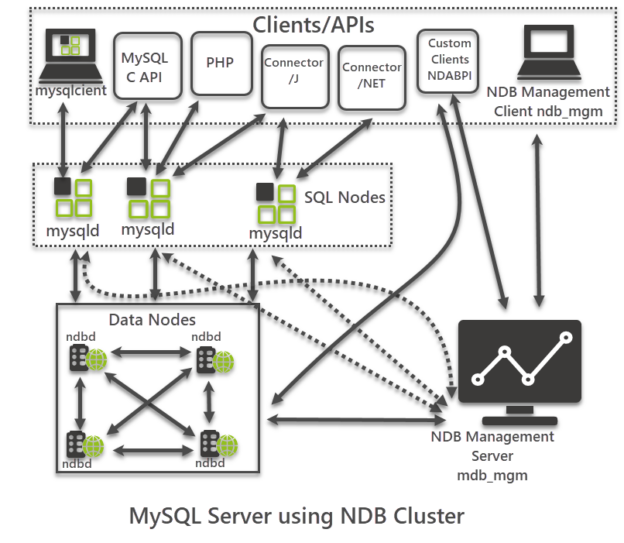
This article provides an overview of MySQL Cluster in a simple understandable manner suitable for both database beginners and professionals.
Read more »
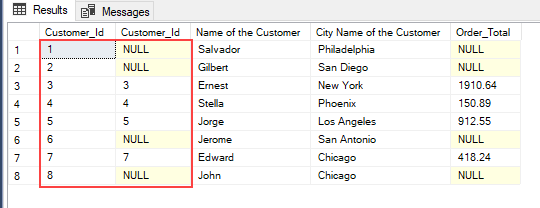
In this SQL cheat sheet, we’ll look at sample SQL queries that can help you learn basic T-SQL queries as quickly as possible.
Read more »
This article will explore the use of the CROSSTAB function in PostgreSQL.
Read more »
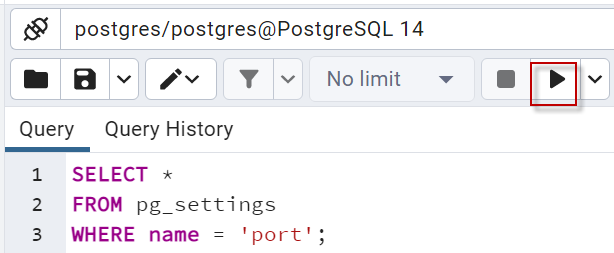
In this article, we will learn how to create PostgreSQL stored procedures using PSQL.
Read more »
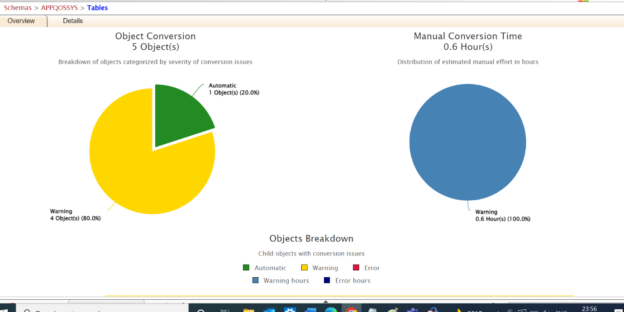
Data Modernization has become important nowadays. Organizations are looking into options to migrate their on-premises database to a cloud and some other heterogeneous databases. In this article, we will see the strategy and options to migrate the Oracle database to the Azure SQL database. We will be leveraging the SSMA tool for migrating the database.
Read more »© Quest Software Inc. ALL RIGHTS RESERVED. | GDPR | Terms of Use | Privacy