

Introduction
SQL Server is pretty good at managing disk space. As long as we do our part to set up appropriate storage types and place files and filegroups properly and set reasonable AUTOGROW settings, it’s almost a set-it-and-forget-it operation. Mind you, I said, “almost!” Sometimes, things do go BUMP! in the night and we need to act. Here’s what happened to me not too long ago:
I look after a fairly large database (about 10TB at the moment, and growing). Using table partitioning and switching and archiving, we can manage in the space we have, assuming other things don’t change. One day though, I noticed our free space was reaching a critical level: just 5%. Upon investigation, I discovered that the Windows drive my database was on was shared with another database that didn’t really belong there and it was growing with no end in sight. That got my attention!
Applying compression
The first thing I did to this rogue database was compress it. I have another SQLShack article, How to use SQL Server Data Compression to Save Space, that discusses compression, if you haven’t used it before. Simply put, SQL Server can achieve 40%, 50%, 60% and sometimes even more compression, depending on the data. After compressing all the tables and indexes in this particular database, I had a 1 TB database with more than 60% free space. But in case you’re thinking, “Problem solved!” that is only half the story. You see, the database had stopped growing but was still occupying that 1 TB on the file system. It’s just that now that file had tons of free space in it. I really wanted to reclaim that free space to give my main database some more headroom.
Seeing the shrink
You might be aware that databases can be configured with an AUTOSHRINK setting. A little googling will turn up any number of articles on why this is usually not a good thing to enable. In a nutshell, shrinking is expensive. CPU, I/O, logging, blocking – all of these things increase during a shrink operation. If you need to shrink your database, you want to control it. I needed to shrink my rogue database but no way was I going to enable AUTOSHRINK! For reasons why not, see Auto-shrink – turn it OFF!
What’s the alternative, you might ask? DBCC! The Database Console Commands is a set of commands to perform various types of maintenance and metadata activities. You probably already know the command CHECKDB. I needed to use another command SHRINKFILE.
DBCC SHRINKFILE, as the name implies, shrinks files not databases. Of course, from a file system standpoint, a database is nothing more than a set of files, so that makes sense. Shrink all the files in a database and you’ve shrunk the database. Simple, except…
Those warnings about CPU, I/O, logging and blocking are real. For my first try, I just ran the command:
DBCC SHRINKFILE (N’MyDataFile’, 0);
(Note: 0 is the target size of the file in megabytes, but the command always leaves enough space for the data in the file.)
Which simply says, “Rearrange all the pages in the file until all the free space is at the end, then truncate the file at that point.” Sounds like just what I needed! However, on my 1TB database with 60% free space, this was still running after…drum roll…two days, and less than 30% done! I had to cancel it to let some production jobs run (remember the warning about blocking?) Now, perhaps you’re thinking, “But still, your file is 30% smaller now.” Sigh! The file size hadn’t changed at all! You see, SHRINKFILE doesn’t truncate the file until the desired size is reached or there is no more free space to squeeze out.
Checkpoints?
Wouldn’t it be nice if SHRINKFILE would checkpoint itself every so often, truncate the file to commit the free space it had recovered, then continue? Well, it doesn’t work that way but we can get it to do that if we are clever. You see, there is no reason to try to shrink the file in one operation. You can do it in two operations, or four, or four hundred. Also, you can pause between each shrink step to let other processes work with the database. Doing it this way, you minimize blocking and logging, and the CPU and I/O can be hidden in the noise of other work.
Here’s a simple script that can do this:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
USE SQLShack GO DECLARE @FileName sysname = N'SQLShack'; DECLARE @TargetSize INT = (SELECT 1 + size*8./1024 FROM sys.database_files WHERE name = @FileName); DECLARE @Factor FLOAT = .999; WHILE @TargetSize > 0 BEGIN SET @TargetSize *= @Factor; DBCC SHRINKFILE(@FileName, @TargetSize); DECLARE @msg VARCHAR(200) = CONCAT('Shrink file completed. Target Size: ', @TargetSize, ' MB. Timestamp: ', CURRENT_TIMESTAMP); RAISERROR(@msg, 1, 1) WITH NOWAIT; WAITFOR DELAY '00:00:01'; END; |
Let me walk you through this script to see what’s going on. First, I declare three variables:
- @FileName is the name of the file to be shrunk. I’ll show you where to find the name in a moment.
- @TargetSize is the desired size of the file, after shrinking. The query returns the current size in megabytes, + 1 to account for rounding.
- @Factor is a factor to be applied to the target size for every time DBCC SHRINKFILE is called.
The system view sys.database_files shows all the files for the database context you are currently in. In my case, this query:
|
1 2 |
SELECT TYPE_DESC, NAME, size, max_size, growth, is_percent_growth FROM sys.database_files; |
Returns:

There are two files in this little database. The first one contains data rows – tables and indexes and other objects; the second one is for the log. The name column is what I need for the @FileName parameter, above. The size column is the size of the file in SQL Server pages. Recall that a page is 8K = 8192 bytes. The other columns show the max size (-1 means no limit) and growth factor, in pages, unless the column is_percent_growth = 1, in which case the growth is in percent.
I need to convert size in pages to megabytes. That is just:
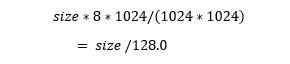
In the body of the loop, I first reduce the target size by the factor. In this case that is .999 or 1/1000th. That seems small but it makes sense for my 1 TB database. That is 1GB per shrink operation. Now, I execute the DBCC SHRINKFILE command then issue a message, reporting on my process. DBCC will also produce a result set for each call. It looks like this:

It shows the current size (after shrinking), the minimum size this database could be, the current number of used pages and the estimated minimum size after shrinking. Why are there 8 more pages in the current size than the actual used pages? That’s partially because SQL Server allocates space in extents which are 64KB in size, or 8, 8KB pages. SQL Server has also reserved one extent for housekeeping.
I added a WAITFOR statement to pause between each operation. In my case, that’s only one second, but I set it up to run after hours when the database was otherwise idle. A larger value (and perhaps a smaller factor) would allow this to be run along with other work, although running it in the wee hours is preferred.
Summary
Sometimes, shrinking a database is unavoidable. This happened to me after I applied table and index compression to a large database. However, shrinking a database is an expensive operation. I’ve shown how you can do that in small increments and keep the overhead to a minimum, even if it takes a little longer to reach the minimum size for a database.

Gerald specializes in solving SQL Server query performance problems especially as they relate to Business Intelligence solutions. He is also a co-author of the eBook "Getting Started With Python" and an avid Python developer, Teacher, and Pluralsight author.
You can find him on LinkedIn, on Twitter at twitter.com/GeraldBritton or @GeraldBritton, and on Pluralsight
View all posts by Gerald Britton
- Snapshot Isolation in SQL Server - August 5, 2019
- Shrinking your database using DBCC SHRINKFILE - August 16, 2018
- Partial stored procedures in SQL Server - June 8, 2018