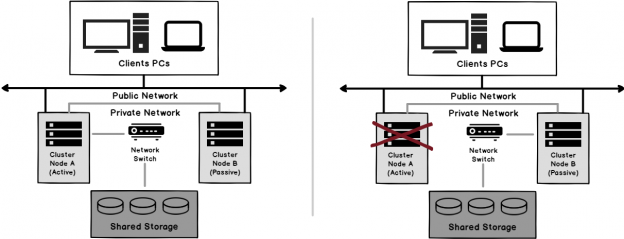
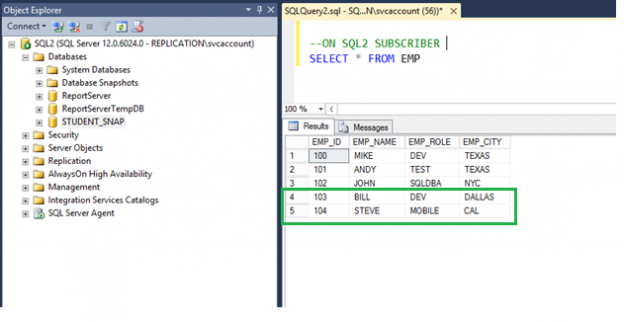
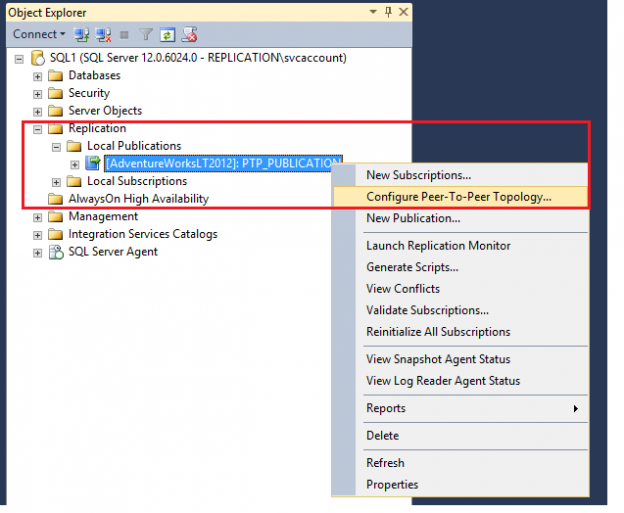
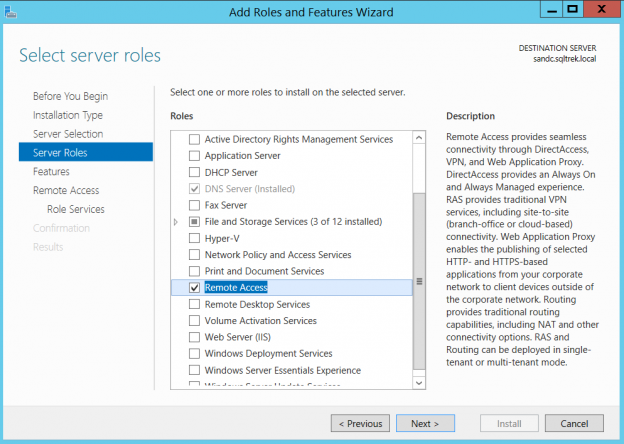
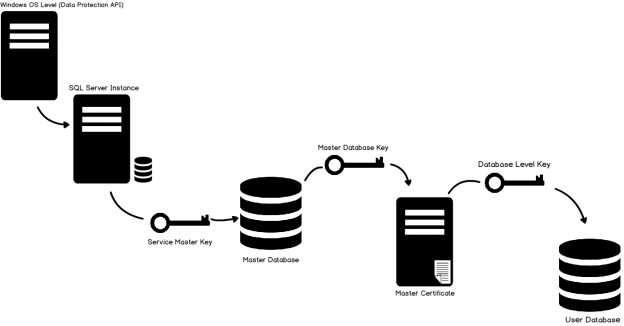
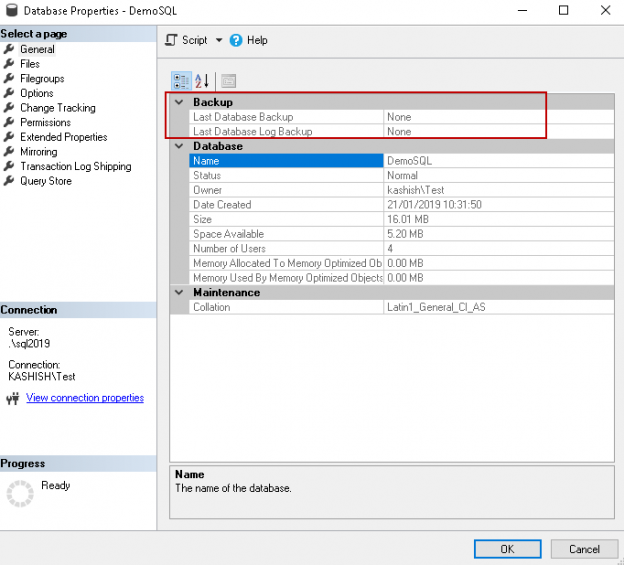
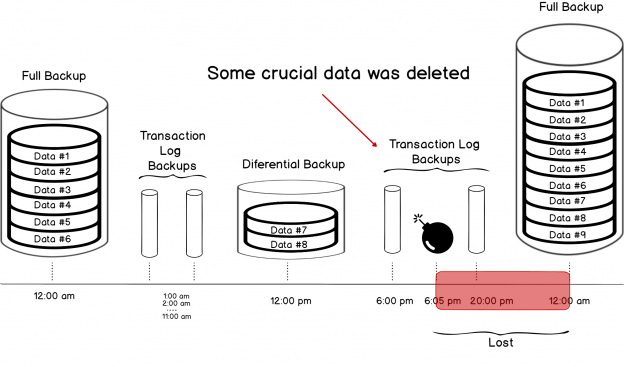
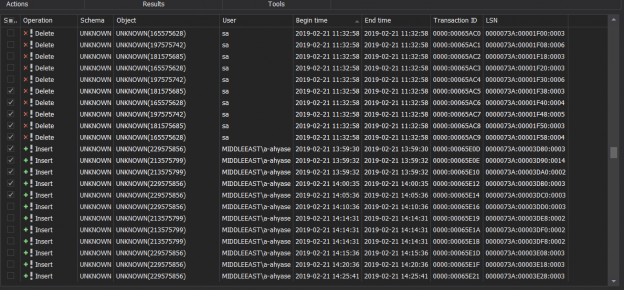
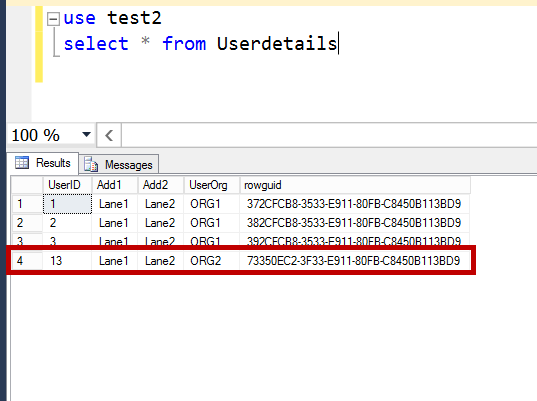
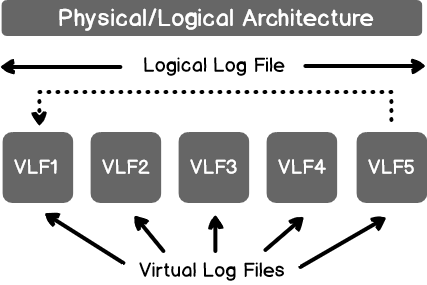
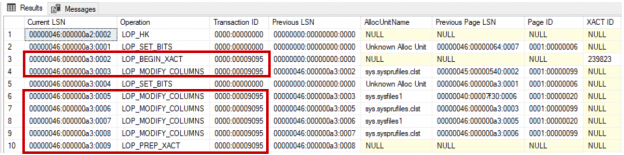
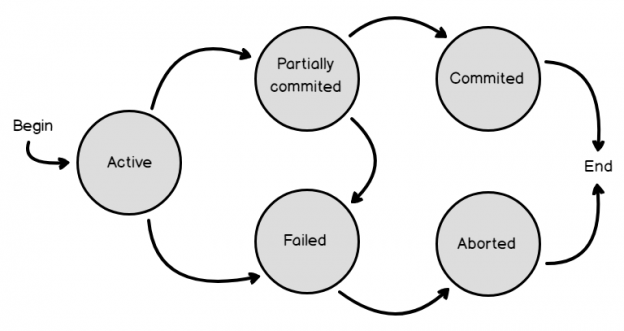
In the previous article of this series on the SQL Server transaction log, we discuss the SQL Server database recovery models, Full, Simple and Bulk-Logged, and the how the recovery model option of the database affects the way the SQL Server Engine works with the transaction logs. In this article, we will discuss the different types of high availability and disaster recovery solutions and the role of the SQL Server transaction log in these technologies.