
Microsoft SQL Server provides us with a wide variety of solutions to architect High availability (HA) and Disaster Recovery (DR) solutions for mission-critical workloads. In this article, let’s just focus on HA, specifically Failover Clustering. Failover clustering is probably the most mature, robust and stable high availability solution which Windows Server Operating system offers. It’s been there around for few decades now and did evolve over time along with SQL Server. In this article Let’s see a hidden feature of windows server failover cluster which helps in making our already highly available SQL Server Failover clustered instances even more highly available. The new feature which we are going to talk about is Cluster Shared Volumes, AKA CSVs. Considering windows server 2019 is around the corner, I say CSVs are not a new concept in clustering, it’s been there for almost a decade now. Microsoft introduced CSVs in windows server 2008R2, but at that time SQL Server was not supported on CSVs. Well, CSVs were originally designed for Hyper-V workloads and later on enhanced for File servers and eventually landed into SQL Server beginning version 2014.
Fair enough, but why should we care about Cluster shared volumes?
Well, the idea behind introducing CSVs is to provide truly shared disks to a failover cluster which are available to all the nodes for reading and write operations. Let’s talk about a traditional Failover clustered Instance setup for a moment. During Failover, to bring SQL Server resource online, the drives should be unmounted on the previous owner and remounted on the node which will act as the primary after failover. Should your IO subsystem become bottleneck for whatever reason, Unmounting and mounting process takes longer time thus impacting the availability of the system. Whereas with CSVs, there is no unmounting and mounting of disks since they are already made available for reading and write operations across all the nodes. In other words, it reduces downtime since SQL Server resource is no longer dependent on disks to come online. Let’s talk about one more scenario where CSVs outperform traditional shared storage. Let’s assume disk(s) loses connectivity from the node which is currently running SQL Server in middle of the day, under these circumstances the cluster can leverage another path (s) available to the shared disk without having to failover the resource group to another node. This will save us from potential unplanned downtime during business hours.
How CSVs work
Under the covers, CSVs still use the same idea of shared disk but with an abstraction layer above NTFS stack. In a traditional shared storage solution, a shared disk is accessible to only one node (Whoever the owner is) at any given point of time, whereas in CSVs all the nodes participating in WSFC will have their own logical paths to the disk(s) leveraging SMB (Server Message Block) protocol. Even though all the nodes within the cluster have both logical and physical paths to shared disk (Let’s say $SQLDATA for example), only the node which owns SQL Server resource can own that disk ($SQLData in our example), where the owner node sends I/O commands either directly using its own access path or using cluster heartbeat network. Basically, one node will be designated as coordinator node (This is the one which NTFS volume is mounted at that given point of time) which talks to all other nodes within the cluster using SMB 3.0 protocol for orchestrating Metadata. So, what is Metadata from SQL Server standpoint? Initial provisioning of Database files during database creation, Extending Database files are considered the most common Metadata events which we can see in SQL Server deployments.
Note: Metadata orchestration is done in parallel and is non-disruptive for SQL Workload.
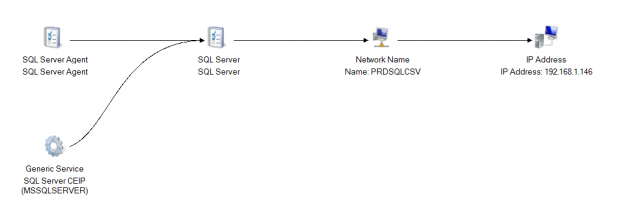
Now let’s see how the cluster dependency looks like when using Cluster shared volumes for SQL Server workloads.
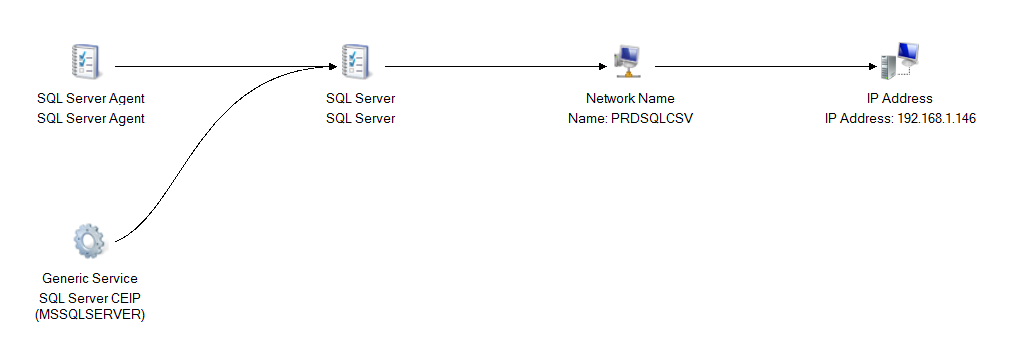
In the above screenshot, you can see the dependency report doesn’t display our shared disks at all. In other words, it thinks SQL Server is not directly dependent on shared disks but behind the scenes, SQL Databases still reside on that CSV disk(s). The important thing to understand with CSV deployments is our SQL Server Instance availability still depends on CSV disk (After all that’s where our Databases are residing), but it’s getting abstracted. Compare the above screenshot with the dependency report from a traditional failover cluster Instance setup.
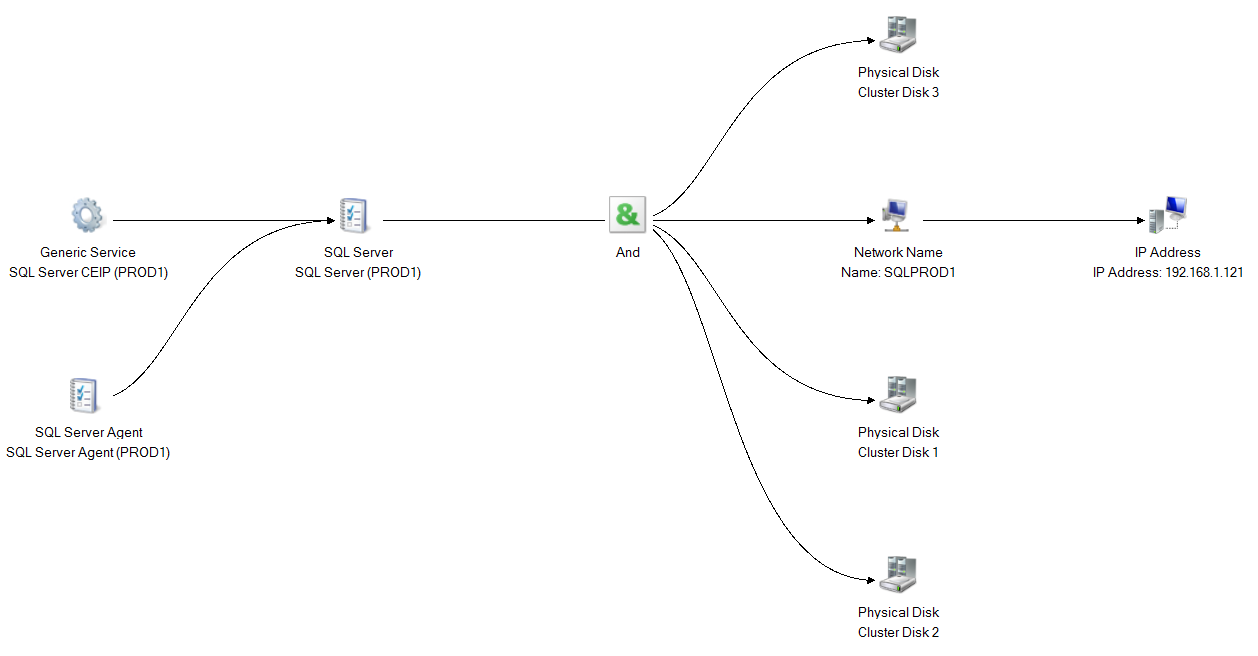
Here you can see the dependency report showing SQL Server resource is directly dependent on the shared disks along with (AND Dependency) the Network name.
What are the benefits of using CSVs for SQL Server workloads?
-
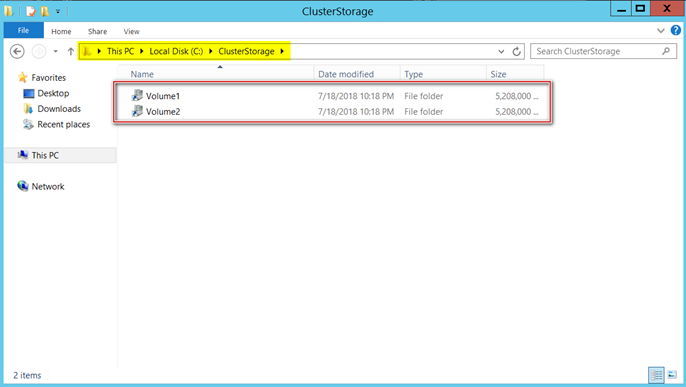
It provides us with a very highly scalable solution where we can have virtually unlimited disk drives with no dependency on the drive letters. You can see in the below screenshot how CSVs get created when deployed. Basically, a folder named ‘ClusterStorage’ gets created under C$ on every node within the windows server failover cluster under which CSVs are placed. You can log in to any node of the cluster to access these disk drives.

- Time it takes to failover gets considerably improved (As discussed earlier, there is no concept of unmounting/mounting of the disk drives during failover). Also, CSVs are resilient to certain types of storage failures.
- CHKDSK operation is integrated, In CSVs scanning (Is an online operation) and repair operations are separated. This could potentially bring down the time it takes to perform certain file system corrections to seconds/minutes as opposed to hours.
- Ease of management. As we have an abstraction to which node within the Failover Cluster owns the disk, we can manage them from any node irrespective of which node the drive is mapped under the covers.
Note: AlwaysON Availability Groups are not supported by cluster shared volumes, Only FCIs are supported. If you have plans to deploy AGs, sorry CSVs are not for you.
One important consideration when deploying CSVs for production SQL Server workloads is to disable iSCSI networks for the cluster use to prevent CSV traffic on those networks. Also, it is recommended to have multiple cluster networks (or teamed NICs) to carry CSV traffic.
In the next part of this short series, I will show you step by step process, how to install SQL Server Failover Clustered Instance leveraging Cluster Shared Volumes.
FAQs
What are the Main advantages of using CSVs?
Manageability, Scalability and High Availability.
Will there be any performance impact using CSVs?
Not really. These disks should be considered as a traditional shared disks w.r.t monitoring.
Can I use CSVs for deploying Availability Groups?
No, AGs are not supported with Cluster Shared volumes.

View all posts by Sreekanth Bandarla
- SQL Server with a Docker container on Windows Server 2016 - April 15, 2019
- Simulating a Multi Subnet cluster for setting up SQL Server Always On Availability Groups – lab setup - March 14, 2019
- Deploy SQL Server with Cluster Shared Volumes – part 2 - September 19, 2018