Introduction
This article describes how to improve the ETL Process in SQL Server by using the native replication technique in SQL Server.
Read more »
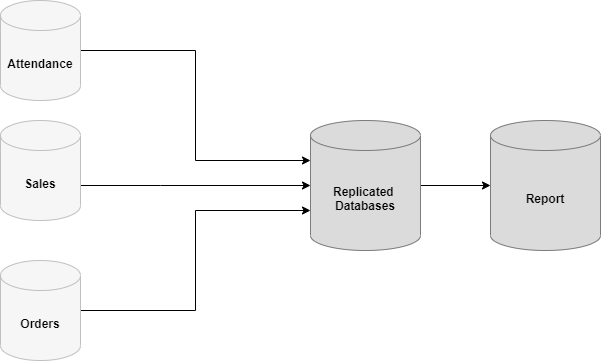
This article describes how to improve the ETL Process in SQL Server by using the native replication technique in SQL Server.
Read more »
In this article, we will learn how to create and manage read replicas in Azure Database for PostgreSQL.
Read more »
In this article, we will implement a SQL Server Replication between AWS RDS SQL Server and On-premises SQL Server instance.
Read more »
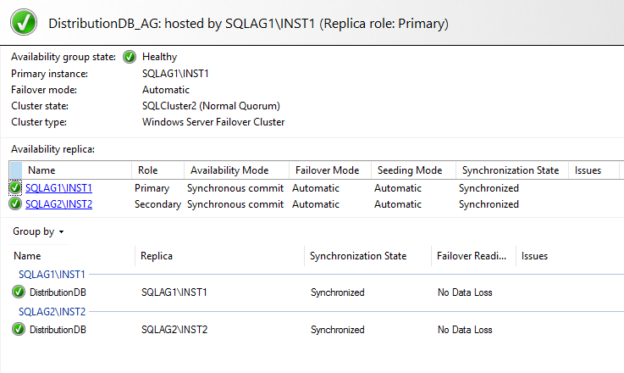
In this 17h article of the SQL Server Always On Availability Group series, we are going to explore the SQL Server replication for the distribution database in the availability group.
Read more »

In this article, we will discuss a number of interview questions that cover the SQL Server Replication concept, components, types, and troubleshooting scenarios.
Read more »
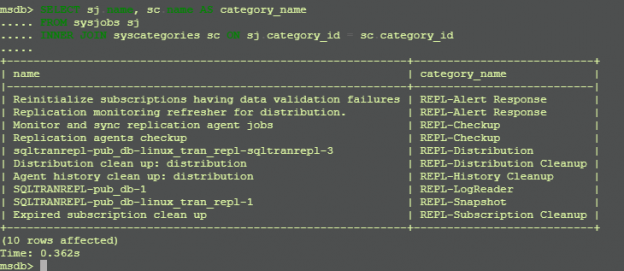
In this article, we will talk about how to send the SQL Server Transactional Replication on Linux Environment.
Read more »
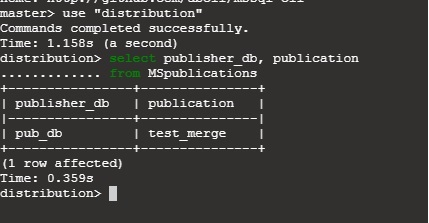
Replication is a process to manage multiple copies of the same data at a different node. Microsoft SQL Server supports Merge Replication, Transaction Replication, Peer to Peer Replication and Snapshot Replication.
Read more »
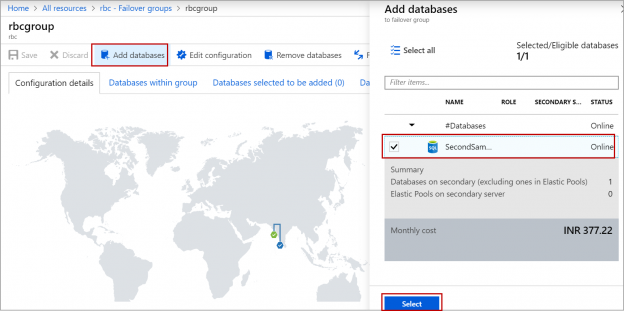
In this article, we will review how to set up auto-failover groups in Azure SQL Server and how failover group is different from active geo-replication in Azure. Auto-failover group is an Azure SQL database feature that replicates one or a group of databases to the secondary Azure SQL server in the cross-region. We cannot have a secondary server in the same region. This feature is used to failover all the databases in the failover group in case of disaster and the failover is automatic.
Read more »
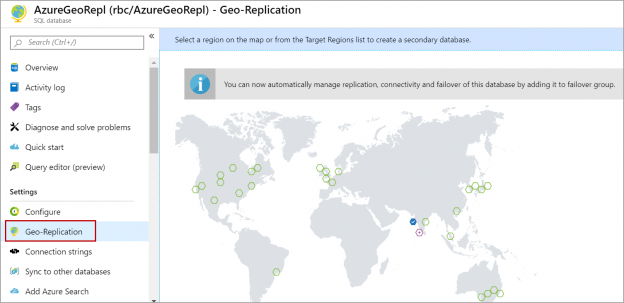
In this article, we will review how to set up Geo-Replication on Azure SQL databases. Geo-Replication is an Azure SQL database feature that allows you to create a readable secondary database in the same region or cross-region. We can failover to the secondary database in case of an outage for a long time on the primary database server. We can also use this feature to migrate a database from one server to another server in the same or cross region with minimal downtime. Geo-replication uses the Always-on feature to replicate committed transactions to the secondary database asynchronously.
Read more »
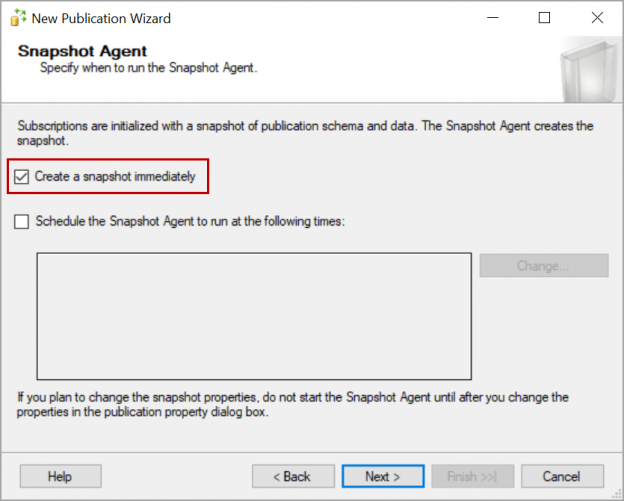
In this article, we will review how to setup SQL replication with publisher database in Always On availability groups so that replication continuous to sync even after failover to the secondary server in the availability group.
Read more »
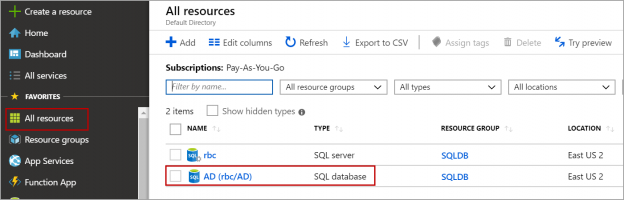
In this article, we will review how to configure the sync group to replicate data between Azure SQL databases using Azure SQL Data Sync.
Read more »
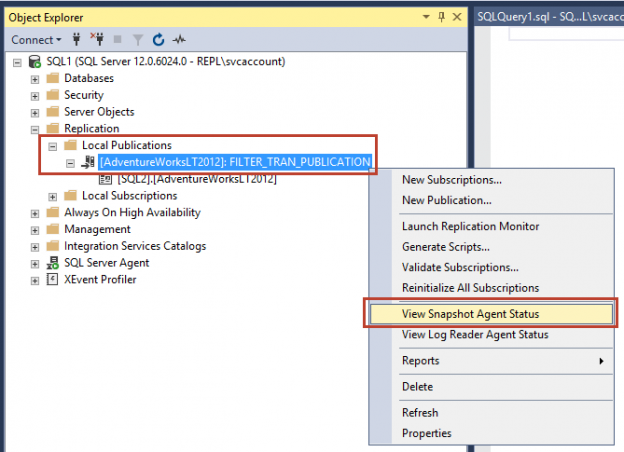
In the last articles, we have learned Configuring Snapshot and Transactional SQL Server replication and Configuring Peer to Peer and Merge SQL replication. Now, once we configured SQL Server replication, there will be some instances where we need to modify the SQL Server replication configuration as per the project updates. In this article, we will learn a few modifications in the existing SQL Replication such as Add new article, drop an article and change the Snapshot folder path and data filter in the current SQL Server replication.
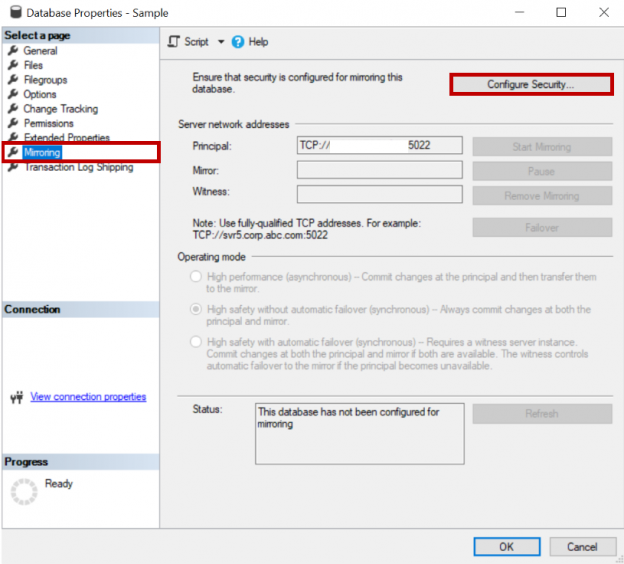
Both log shipping and mirroring are high availability and disaster recovery options available in SQL Server. This article will review on how to configure log shipping on a mirrored database.
Read more »
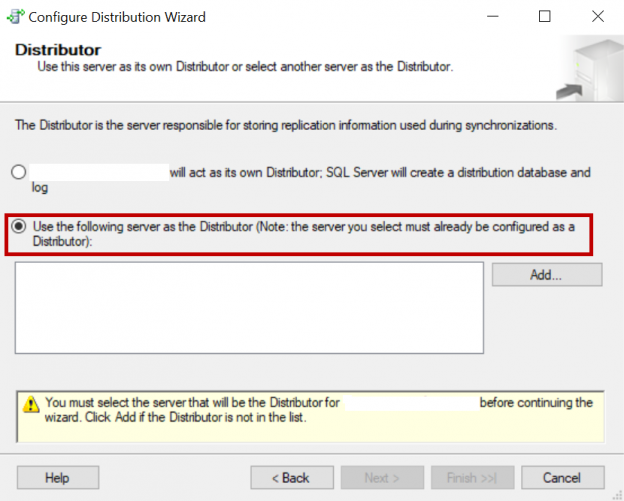
This article will review on how to configure SQL Server Replication along with mirroring on a database.

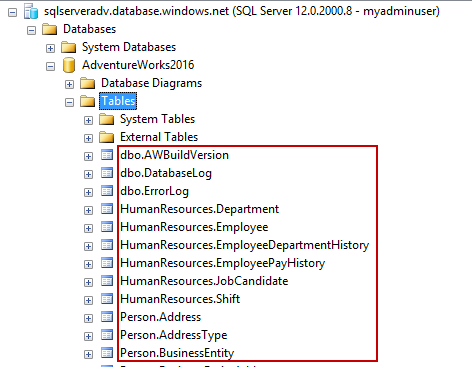
In this guide, we’ll discuss more about migrating a SQL Server database to Azure SQL Database using SQL Server Transactional Replication.
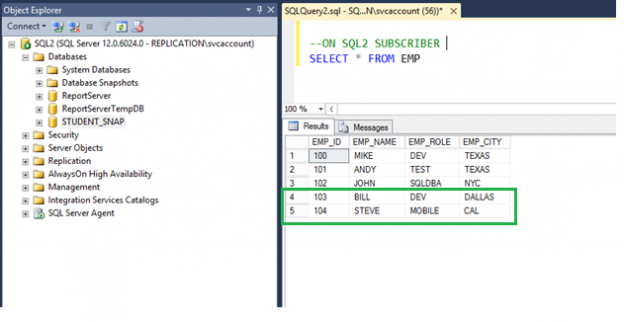
In this article of the series on SQL Server replication, we will explore ways to configure SQL Server Snapshot replication and Transactional replication step by step.
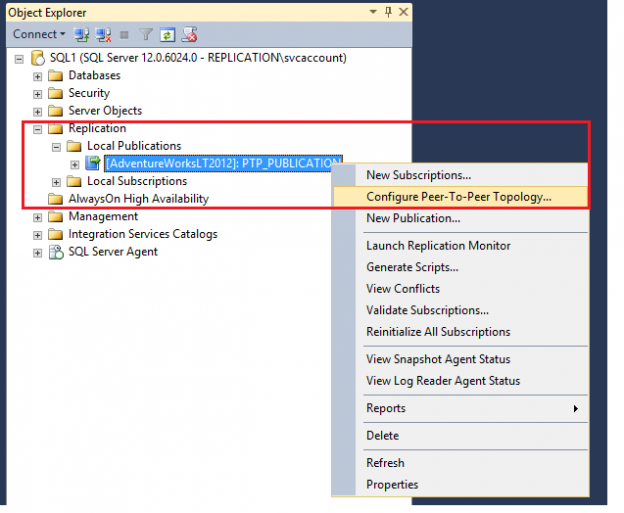
This article will cover SQL Server replication configuration including Peer to peer replication and merge replication, initial configuration, adding nodes and data verification.
Read more »
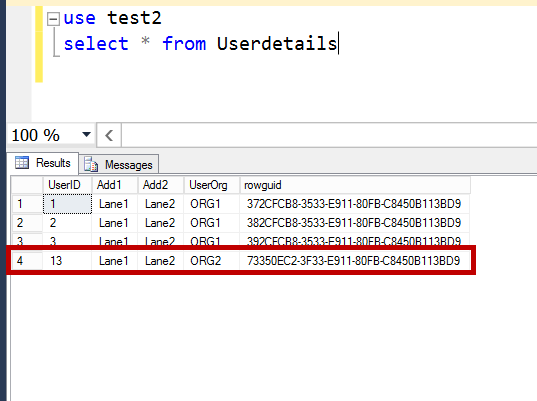
In this article we will discuss about SQL Server Merge Replication Parameterized row filter issues while replicating incremental data changes post initial snapshot.
Read more »
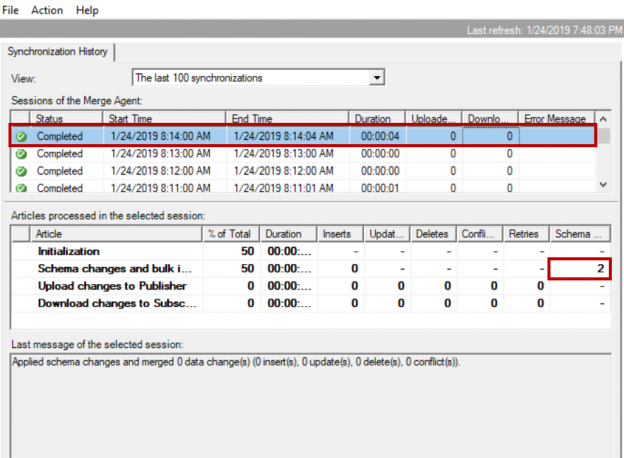
This article will review performance issues in replicating schema changes on tables involved in SQL Server Replication (Merge).
Read more »
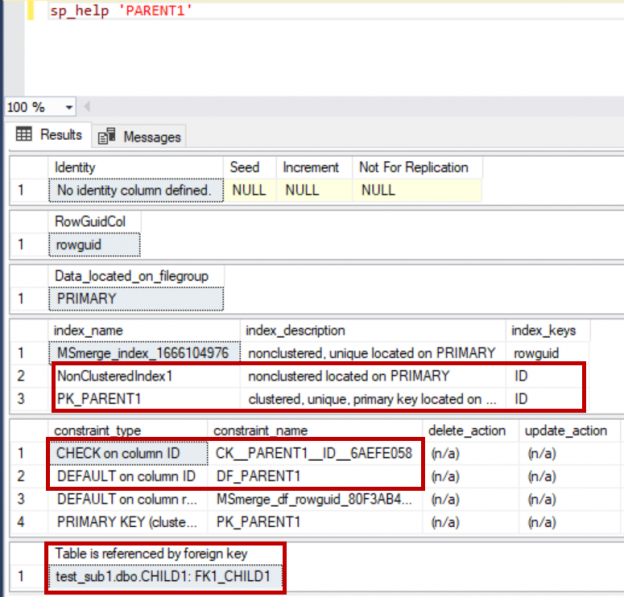
This article will show how triggers, indexes, constraints and foreign keys will replicate in snapshot and after snapshot in SQL Server replication.
Read more »
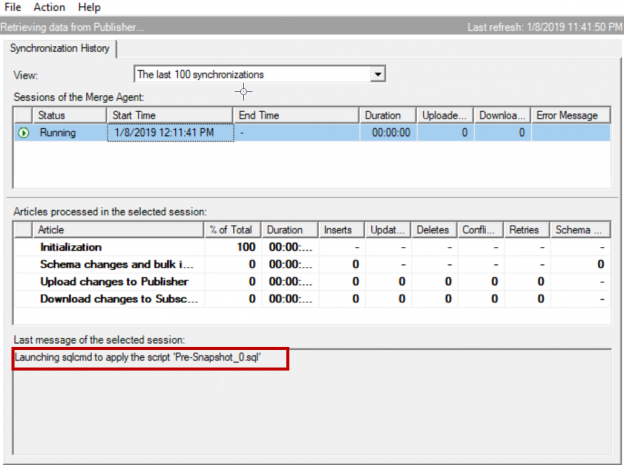
This article will review specific SQL Server merge replication issues related to foreign keys and schema snapshots
In our environment we use SQL Server merge replication to replicate data to multiple subscribers. We had a situation where a table needs to be part of merge replication and the table has more than 246 columns. Merge replication supports tables with maximum of 246 columns. In this article let us see how to replicate a table with more than 246 columns.
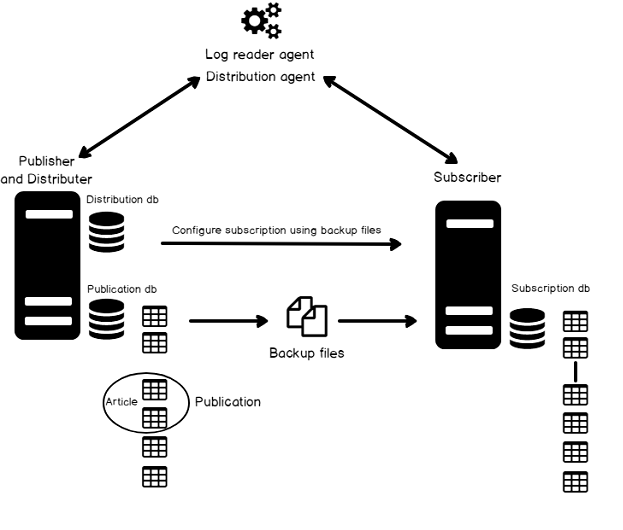
A workload management is considered as a critical aspect of SQL Server transactional replication. Replication is the oldest of the high availability technologies in SQL Server and it is available since the inception of SQL Server. As a very mature technology, SQL Server transactional replication is also very robust and, in most cases, very straightforward to set up and manage.
Read more »
This is article is a continuation of the previous: SQL Server replication: Overview of components and topography.
By now, you’re familiar with the components of replication. So far, we’ve seen a lot of theory about replication. It’s a time for practical walkthrough of setting up a basic transactional SQL Replication system. The best way to get a feel for how SQL Replication is implemented and how it works is to see it in action.
Read more »
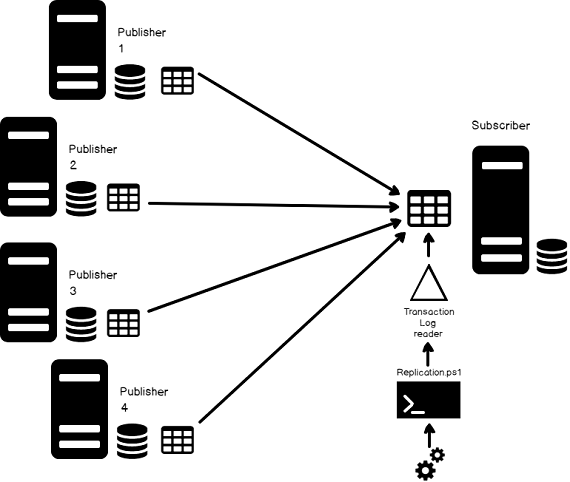
In this data-driven era, replication is often a critical requirement for achieving a modern, agile database management environment. It is believed designing an enterprise-grade dataset is the to achieving this requirement but building datamarts from datasets always presents certain challenges
In this article, we’ll discuss what it takes to setup “central subscriber with multiple publishers” replication model, to create an aggregate dataset from multiple sources, and you’ll also see how to scale with the data.
Read more »© Quest Software Inc. ALL RIGHTS RESERVED. | GDPR | Terms of Use | Privacy