
Continuing my blog post series after 24HOP Russia “Query Processor Internals – Joins”. In this (and the next one) blog post, we will talk about the Nested Loop Post Optimization Rewrite optimizations.
Some of you may know that a Nested Loop join algorithm preserves order of the outer table.
Here is Craig’s Freedman (from the Query Optimizer Team, Microsoft) post:
Let’s first setup some test data.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
create database nldb; go use nldb; go create table dbo.SalesOrder(SalesOrderID int identity primary key, CustomerID int not null, SomeData char(30) not null); go with nums as ( select top(1000000) rn = row_number() over(order by (select null)) from master..spt_values v1, master..spt_values v2, master..spt_values v3 ) insert dbo.SalesOrder(CustomerID, SomeData) select rn%500000, str(rn,30) from nums; go create index ix_CustomerID on dbo.Salesorder(CustomerID); go |
Now we will issue two queries. I use an index hint for demonstration purposes only, there might be no hint needed in real life for such a situation.
|
1 2 |
select * from dbo.SalesOrder with(index(ix_CustomerID)) where CustomerID < 500; select * from dbo.SalesOrder with(index(ix_CustomerID)) where CustomerID < 1000; |
The plans are almost the same:
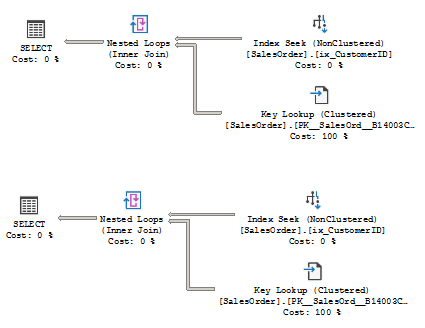
But the results:
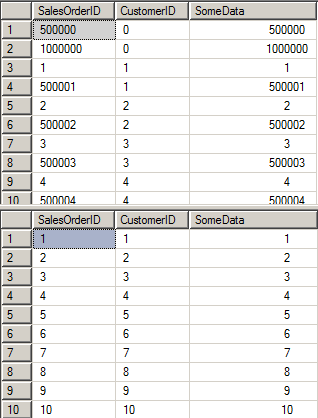
Obviously, the sort order is different. That is one of the examples showing, that you should never rely on the “default” sort order, as there is no such thing. The only way to get a desired sort order is to add an explicit outer order by in your query.
Ok, but still, why the sort order is different.
Implicit Batch Sort and Nested Loop operator
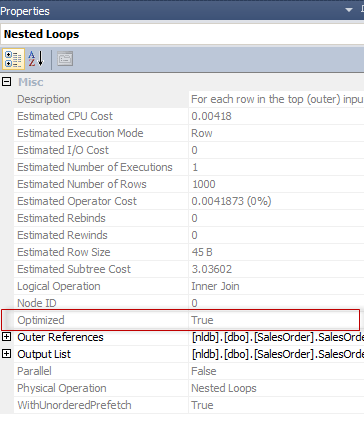
Let’s examine the Nested Loop operator details.
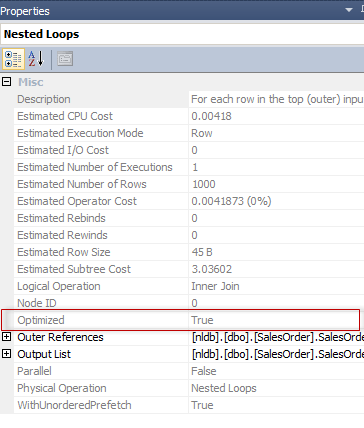
You may notice the Optimized property set to true. That is not very informative, what does it mean – “optimized”. Luckily, we have an explanation in the Craig Freedman’s blog for Nested Loop:

What I love in Craig’s posts, that every insignificant (from the first glance) word has a solid meaning.
The catch, even for an experienced users, is that both plans has an “Optimized=true” keyword in the Nested Loop Join plan operator, but only in the second query, the reordering is done.
Why do the reordering?
The purpose is to minimize random access impact. If we perform an Index Seek (with a partial scan, probably) we read the entries in the index order, in our case, in the order of CustomerID, which is clearly seen on the first result set. The index on CustomerID does not cover our query, so we have to ask the clustered index for the column SomeData, and actually, we perform one another seek, seeking by the SalesOrderID column. This is a random seek, so what if, before searching by the SalesOrderID we will sort by that key, and then issue an ordered sequence of Index Seeks, turning the random acces into the sequential one, wouldn’t it be more effective?
Yes, it would in some cases, and that is what “optimized” property tells us about. However, we remember, that it is not necessarily leads to the real reordering. As for comparing the real impact, I will refer you to the actual Craig’s post or leave it as a homework.
How it is implemented inside SQL Server?
Let’s issue the query with some extra trace flags, showing the output physical tree (the tree of the physical operators) and the converted tree (the tree of the physical operators converted to a plan tree and ready to be compiled into the executable plan by the Query Executor component).
|
1 2 3 4 5 6 7 |
select * from dbo.SalesOrder with(index(ix_CustomerID)) where CustomerID < 1000 option( recompile , querytraceon 3604 , querytraceon 8607 , querytraceon 7352 ); |
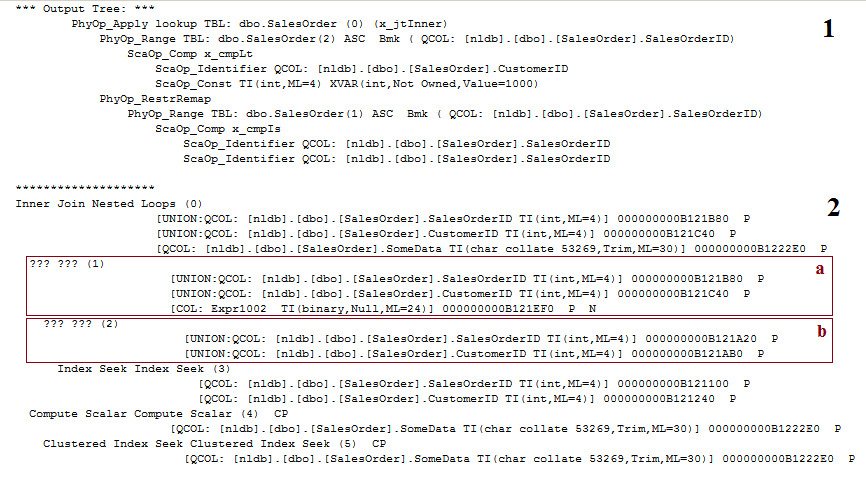
The first one (1) is the output tree of the physical operators, the result of the optimization. The second one (2) is the converted tree ready to become a plan, for the execution compilation.
Notice the in the first one we have no mysterious nodes, like “??? ???”. But we have two of them in the second one. That is the result of Post Optimization Rewrites phase introducing some extra optimizations for the Nested Loops.
The node (a) is for the optimization – called “Prefetching” and displayed as “WithUnorderedPrefetch = true” in the plan properties. This is not the topic of this post, but you may refer to the useful links later in this post to read more about it.
The second one (b) is for the Batch Sort – our case.
You may be interested to know if there is a special iterator for that mysterious node in the executable plan, and there is one. It is called CQScanBatchSortNew. Here how it looks like in the WinDbg call stack.
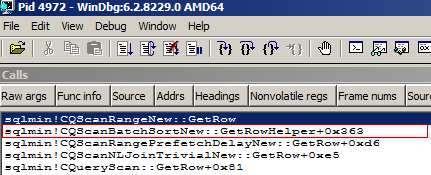
The marked area represents a call to the iterator CQScanBatchSortNew which is responsible for the “OPTIMIZED” property and sorting optimization.
Below you may also see the Prefetch iterator (CQScanRangePrefetchDelay), mentioned above.
Not pretending to the any drawing skills, but to be clear, the artificial plan, with those artificially drawn operators might look like this.
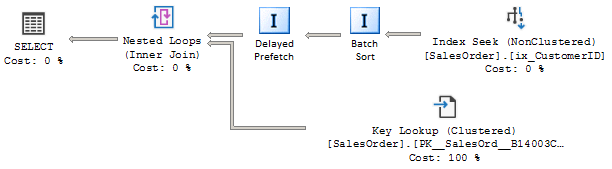
Explicit Batch Sort and Nested Loop
The implicit batch sort optimization is a lightweight optimization, which is done on the Post Optimization Rewrite phase; however, that kind of optimization might be done before, by explicitly introducing the Sort operator. The decision to do one or another is a cost based decision.
First, let’s fool the optimizer to pretend there is much more rows (just to not create a huge test database):
|
1 |
update statistics dbo.SalesOrder with rowcount = 10000000, pagecount = 400000 |
Now consider this example:
|
1 2 3 4 5 6 7 |
select * from dbo.SalesOrder with(index(ix_CustomerID)) where CustomerID < 10000 option( recompile , maxdop 1 , querytraceon 3604 , querytraceon 8607 ); |
I’m using the hints again only for the easy demonstration, it is not necessary in the real life.
The plan is now:
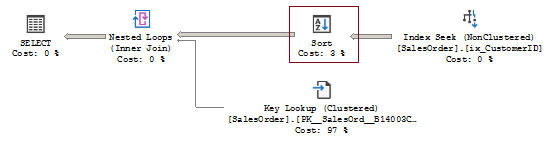
The sort operator properties clearly show that the order is a clustered index order.
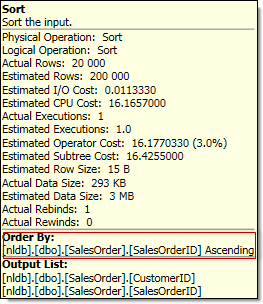
Unlikely the OPTIMZED property and implicit Batch Sort, this kind of decision is done before the Post Optimization Rewrite, and we may see the explicit sort operator in the output physical tree.
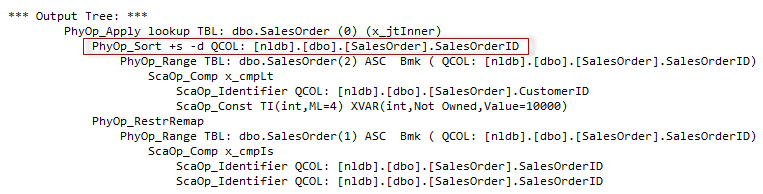
Though they are doing the similar function and serve similar goals, they are slightly different
- The implicit sort is done before the Post Optimization Rewrite
- The implicit batch sort may not spill to disk and is net compromise between the explicit sort and not sorted requests
- Different TF to manage them =)
Magical TFs
There are three of them. All are well known but probably needs some clarification.
TF 2340 – Disable Nested Loop Implicit Batch Sort on the Post Optimization Rewrite Phase
TF 8744 – Disable Nested Loop Prefetching on the Post Optimization Rewrite Phase
TF 9115 – Disable both, and not only on the Post Optimization but the explicit Sort also
All of them, except 2340 are undocumented, so not should be used in production, be careful.
That is all for that post.
There are some other batch sort optimization applications, but not to do the re-write, I’d rather provide the links to further reading and some additional relevant and interesting material.
Previous article in this series:

Currently he works as a database developer lead, responsible for the development of production databases in a media research company. He is also an occasional speaker at various community events and tech conferences. His favorite topic to present is about the Query Processor and anything related to it. Dmitry is a Microsoft MVP for Data Platform since 2014.
View all posts by Dmitry Piliugin
- SQL Server 2017: Adaptive Join Internals - April 30, 2018
- SQL Server 2017: How to Get a Parallel Plan - April 28, 2018
- SQL Server 2017: Statistics to Compile a Query Plan - April 28, 2018