
In this blog post, we will look at one more Nested Loops (NL) Join Post Optimization Rewrite. This time we will talk about parallel NL and Few Outer Rows Optimization.
For the demonstration purposes, I will use the enlarged version of AdventureWorks2014. In the sample query, I will also use the trace flag (TF) 8649 – this TF forces parallel plan when possible and is very convenient here, as we need one for the demo. There are also a few other undocumented TFs: TF 3604 – direct diagnostic output to console, TF 8607 – get a physical operator tree, before Post Optimization Rewrite, TF 7352 – get a tree after Post Optimization Rewrite phase.
The sample query is asking for some data based on the period’s table.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
use AdventureWorks2014; go -- create and fill sample periods if object_id('tempdb..#Periods') is not null drop table #Periods; create table #Periods(DateStart datetime, DateEnd datetime); insert #Periods values ('20110101','20110201'),('20120101','20120201'),('20130101','20130201'),('20140101','20140201'); go -- get all the orders in the periods set showplan_xml on; go select soh.SalesOrderID, soh.Comment from Sales.SalesOrderHeaderEnlarged soh join #Periods p on soh.OrderDate >= p.DateStart and soh.OrderDate < p.DateEnd option ( querytraceon 8649 -- Demand parallel plan ,querytraceon 3604 -- Output to console ,querytraceon 8607 -- Before Post Optimization Rewrite ,querytraceon 7352 -- After Post Optimization Rewrite ); go set showplan_xml off; |
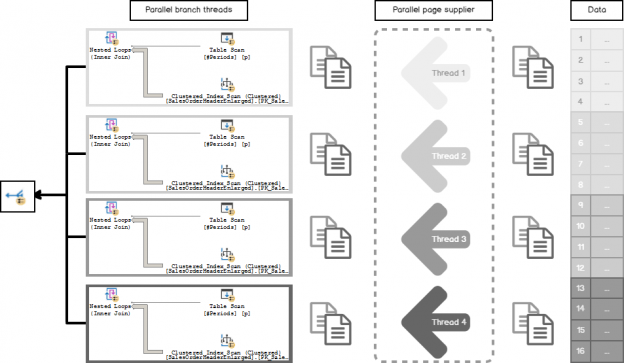
On the following picture, I combined two kinds of operator’s tree produced before the Post Optimization Rewrite and after with the Query Plan, colored and shortened output a little bit for better illustration.
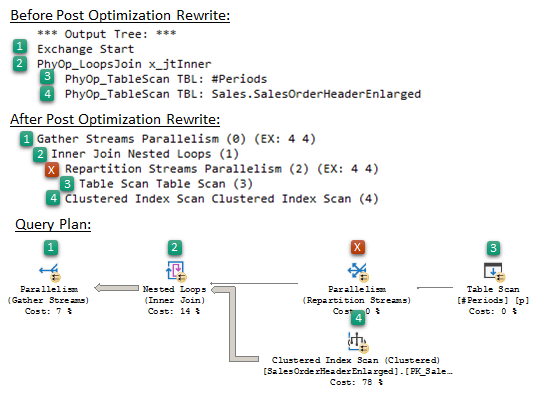
You may notice the node [X], missing in the first tree, that is a result of the cost-based optimization but presenting in the second tree and the query plan. That is the optimization introduced for the Parallel NL Join during the Post Optimization Rewrite and called Few Outer Rows Optimization.
Without this optimization, the plan would be the following.
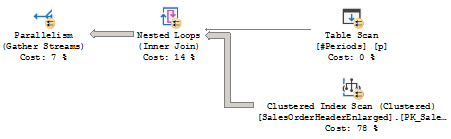
Why do we need this extra [Parallelism (Repartition Streams)] operator?
Few Outer Rows Optimization
When the Parallel Scan process begins, threads demand rows dynamically, as soon, as they need them. The Parallel Scan thread asks the so-called parallel page supplier to give it a bunch of pages for processing. Then Parallel Scan gets rows from those pages and working with them in a corresponding parallel plan branch. After it has done the processing, it sends the results to the parallel exchange buffers and demands the next portion of the pages.
It may look like this.
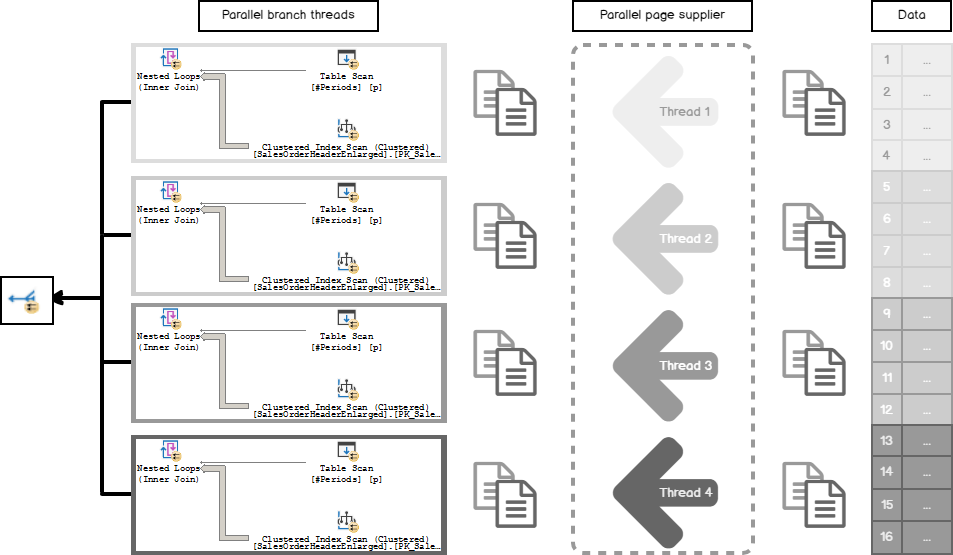
Each thread is given the demanded amount of pages to work with and processing them inside the parallel plan branch, then passing to the Gather Streams Exchange operator that combines results together. Each thread is doing its part of the work.
What if there are very few rows on the outer side of the NL and they fit only a few pages (let’s say a small table like the one we have in our example)? Then the thread that comes first will grab all of them leaving all other threads idle and doing all the work by itself.
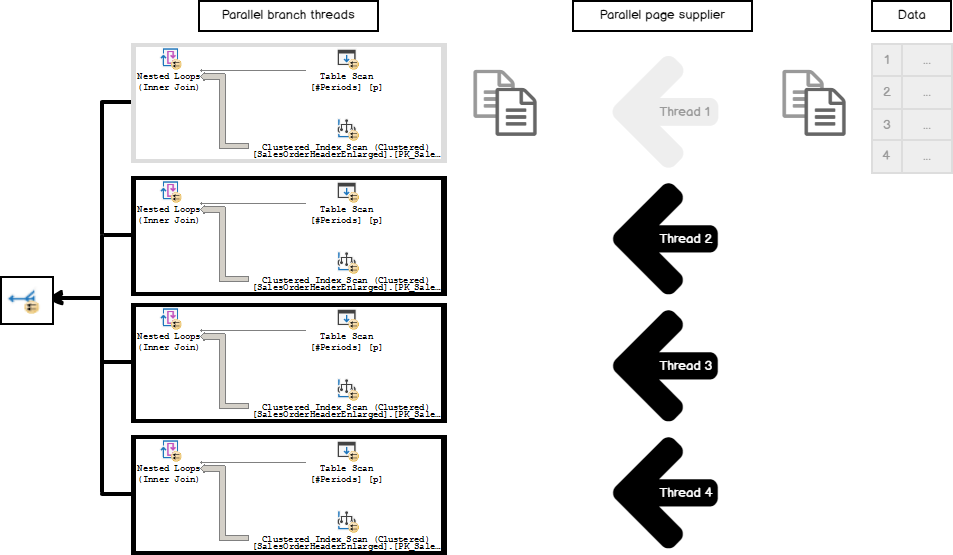
In that case, we will execute a parallel plan in one thread and that is not effective. This is an extreme case, nevertheless, in a real-life query, that kind of imbalance may significantly reduce the productivity of the query execution, but probably not at so high degree.
To prevent this situation, SQL Server introduces the Repartition Streams operator between the scan and the branch of work. It has a partitioning type Round Robin, which means that it sends each subsequent packet of rows to the next subsequent consumer thread, redistributing the rows in that manner.
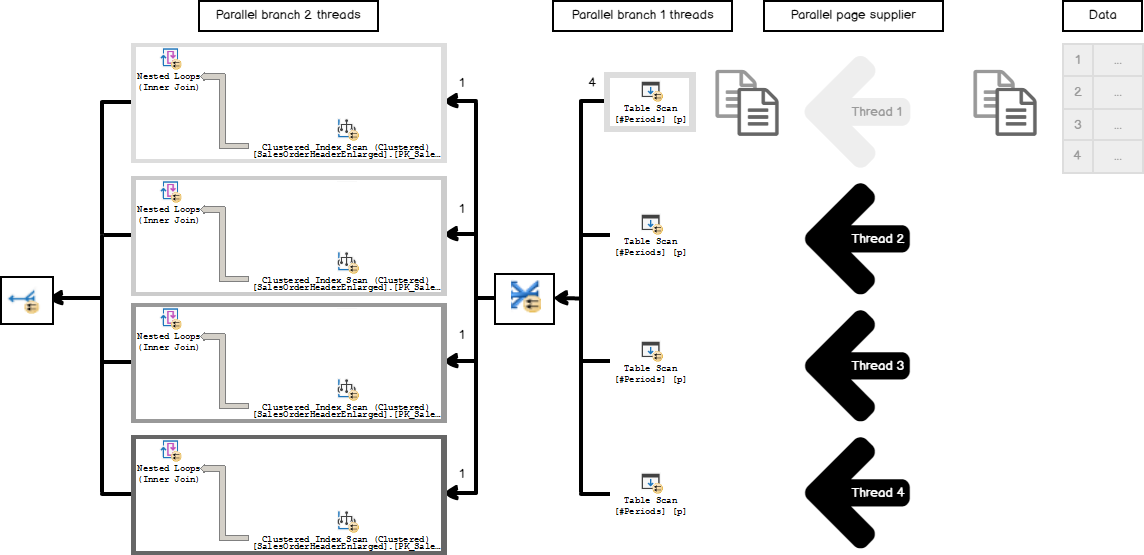
After that redistributing, the entire join related work is balanced between 4 threads.
TF 2329
Now let’s compare the plans and time with that optimization and without it. To disable Few Outer Rows optimizations we will use the TF 2329. I have 4 cores on my machine, so there will be 4 threads per branch, you may have different results.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
set statistics time, xml on; declare @SalesOrderID int, @Comment nvarchar(256); select @SalesOrderID = soh.SalesOrderID, @Comment = soh.Comment from Sales.SalesOrderHeaderEnlarged soh join #Periods p on soh.OrderDate >= p.DateStart and soh.OrderDate < p.DateEnd option(querytraceon 8649); select @SalesOrderID = soh.SalesOrderID, @Comment = soh.Comment from Sales.SalesOrderHeaderEnlarged soh join #Periods p on soh.OrderDate >= p.DateStart and soh.OrderDate < p.DateEnd option(querytraceon 8649, querytraceon 2329); set statistics time, xml off; |
The first plan is:
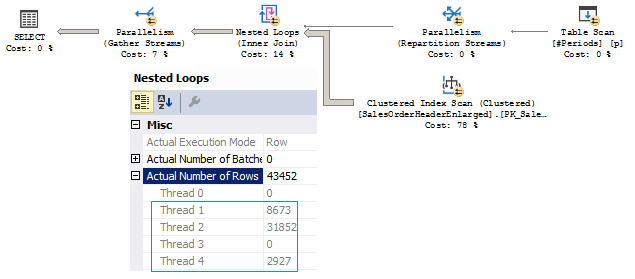
We may see that parallel page supplier passed all the four rows to one thread, however, Parallelism (Repartition Streams) operator redistributed rows between the threads and almost each of the threads did its piece of work scanning and joining the inner side of NL. That is much quite even work distribution (your results may vary depending on the SQL Server and Hardware configuration and workload).
The second plan:
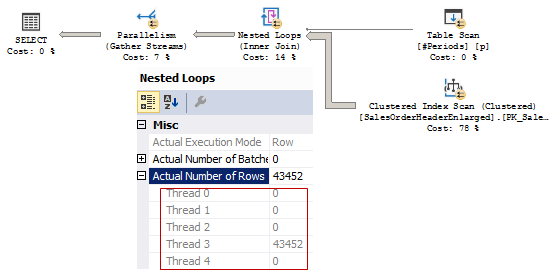
All the rows came to the Thread 3 this time, but it has no Parallelism (Repartition Streams), so all the work was done by a single thread. In fact, we have a serial execution of the parallel plan.
Now let’s look at the execution time.
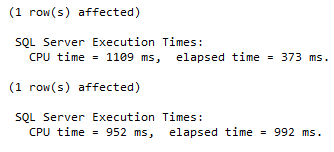
The CPU time in the first case is slightly bigger: 1109 ms vs 952 ms – because real parallel work was done, however, the elapsed time is almost 2-3 time less than in the second query: 373 ms vs 992 ms. Of course, the 2-3 time speedup is an extreme case, but It is (or even more) still possible.
Few Outer Rows Optimization is designed mostly for Data Warehouse workloads; however, it might happen anywhere if this pattern is recognized.
Previous article in this series:

Currently he works as a database developer lead, responsible for the development of production databases in a media research company. He is also an occasional speaker at various community events and tech conferences. His favorite topic to present is about the Query Processor and anything related to it. Dmitry is a Microsoft MVP for Data Platform since 2014.
View all posts by Dmitry Piliugin
- SQL Server 2017: Adaptive Join Internals - April 30, 2018
- SQL Server 2017: How to Get a Parallel Plan - April 28, 2018
- SQL Server 2017: Statistics to Compile a Query Plan - April 28, 2018