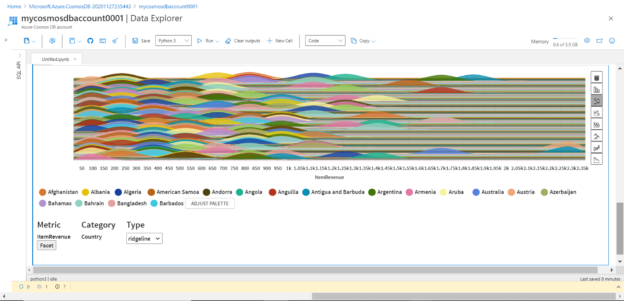
Analyzing data hosted in Azure Cosmos DB with Notebooks
February 10, 2021In this article, we will learn how to analyze data hosted in Azure Cosmos DB using Notebooks.
In this article, we will learn how to analyze data hosted in Azure Cosmos DB using Notebooks.
In this article, I am going to discuss some of the best practices that a programmer must follow while programming in python. Python as a language has evolved to a great extent over the last few decades and has gained popularity amongst a lot of software programmers, data enthusiasts, and system administrators. This is because […]
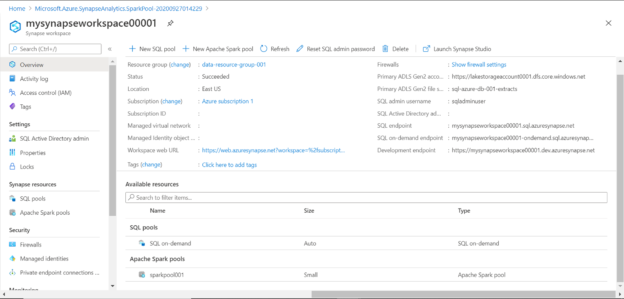
In this article, we will learn how to create a Spark pool in Azure Synapse Analytics and process the data using it.

In this article, we will discuss how to read the SQL Server execution plan (query plan) with all aspects through an example, so we will gain some practical experience that helps to solve query performance issues. Interpreting query plans correctly is the first and major principle to troubleshoot query performance issues. When we try to […]
In this article, we will look at the configuration of the AWS RDS PostgreSQL instances.
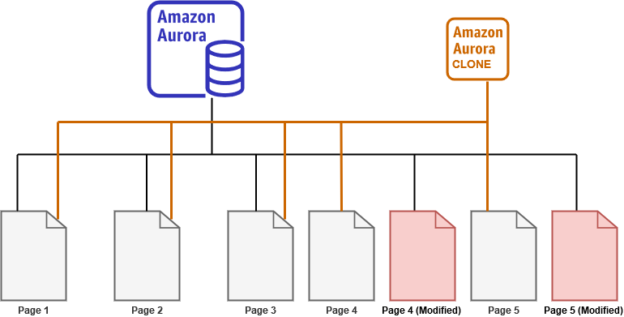
Amazon Aurora provides a MySQL and PostgreSQL compatible relation database with performance and feature enhancements over the existing databases. In the previous articles, we discussed the following features. You can refer to ToC at the bottom. Backtrack Global Database Amazon Aurora Serverless In this article, we will cover fast database cloning and its usage for […]
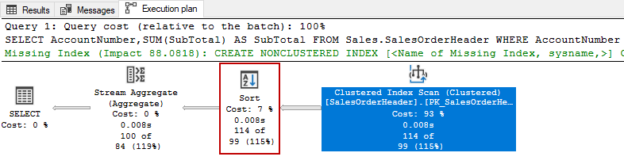
In this article, we will explore how the ORDER BY statement affects the query performance and we will also learn some performance tips related to sorting operations in SQL Server.
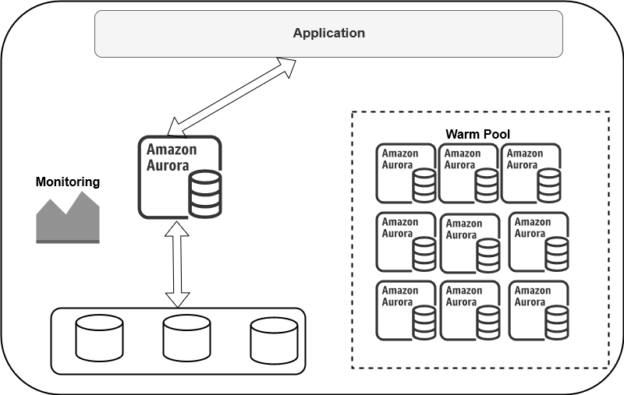
In this 4th article for the Amazon Aurora series, we will discuss and implement an Amazon Aurora Serverless cluster.
Introduction You might be thinking why do you want to create Azure SQL Database and what are the best configurations. This article will provide you with the basic configurations of the Azure SQL Database.

In the article, Deploy your AWS RDS Aurora database clusters for MySQL, we explored the Amazon Aurora concept and deployment. In this article, we will understand about the global database feature and its implementations.
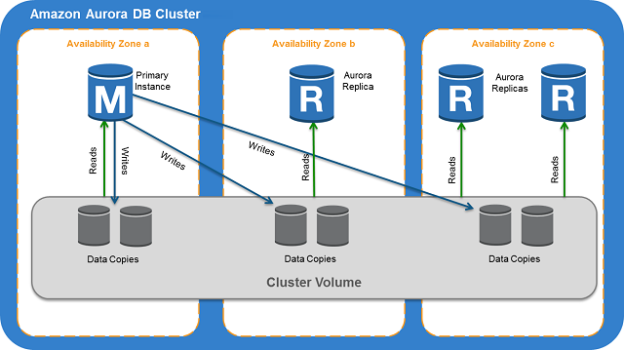
Introduction Amazon offers managed database service for various database products such as Microsoft SQL Server, MySQL, PostgreSQL, Oracle. In these relational database services (RDS), AWS manages the operating system, networking components, backups, monitoring solutions. In the previous articles, we explored many useful RDS features under the AWS RDS category on SQLShack.
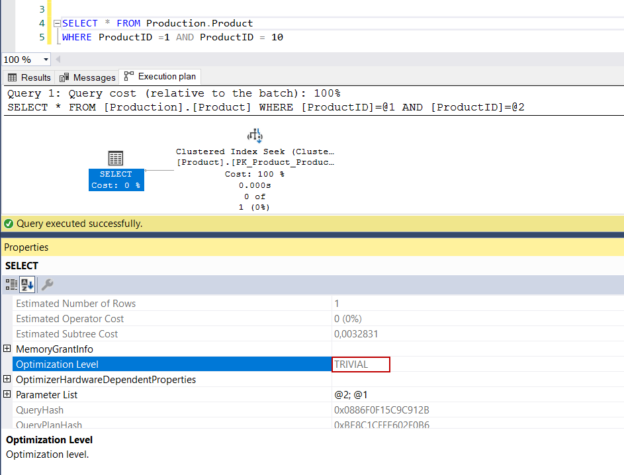
The SQL Server execution plan (query plan) is a set of instructions that describes which process steps are performed while a query is executed by the database engine. The query plans are generated by the query optimizer and its essential goal is to generate the most efficient (optimum) and economical query plan. Some query plans […]

In this article, we will learn to install SQL Server 2019 on the RedHat Linux 18 on a virtual machine.
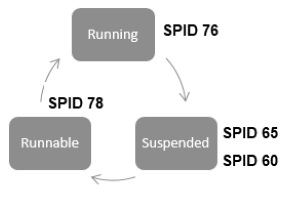
Introduction Troubleshooting using Wait Stats in SQL Server is an important perspective when it comes to managing databases. As a database professional, you might have come across situations, where your end-users are not happy with reports being slower. It will leave you to find the reason for the report slowness.
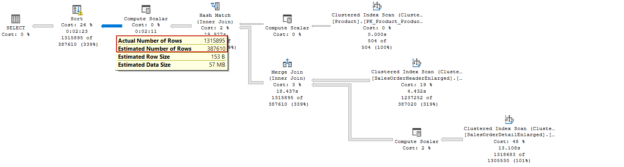
In this article, we will talk about the query tuning features that were announced with SQL Server 2019.
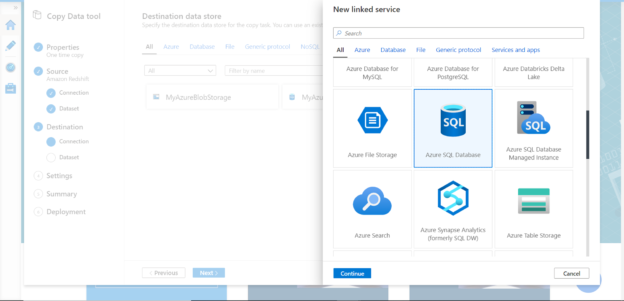
In this article, we will learn an approach to source data from AWS Redshift and populate it in the Azure SQL database, where this data can be used with other data on the SQL Server for desired purposes.
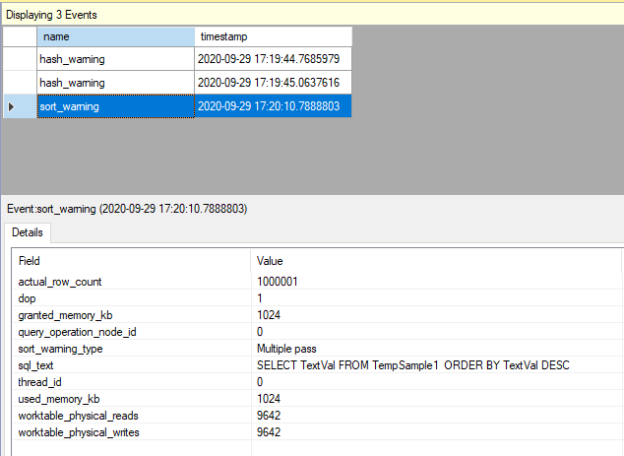
In this article, we will uncover some secrets about the SQL Server tempdb database. Tempdb is a system database and it is used for various internal and user operations. Besides this, the tempdb has many unique characteristics, unlike the other databases. When we take into account all of these features of the tempdb, there is […]
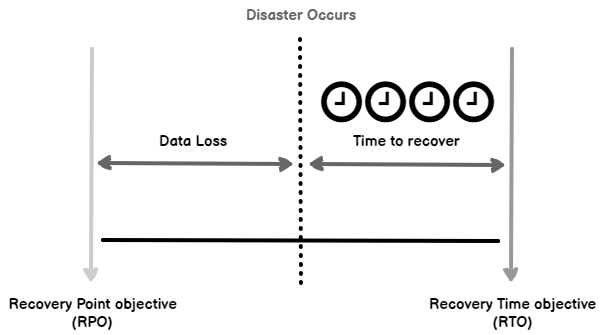
This article discusses useful considerations for SQL Server Disaster Recovery.
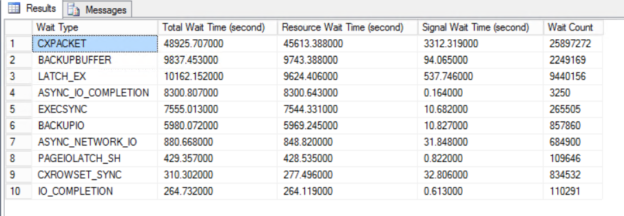
In this article, we will explore, how we can increase SQL Server performance with the help of the wait statistics. Wait statistics are one of the most important indicators to identify performance issues in SQL Server. When we want to troubleshoot any performance issue, at first we need to diagnose the problem correctly because correctly […]
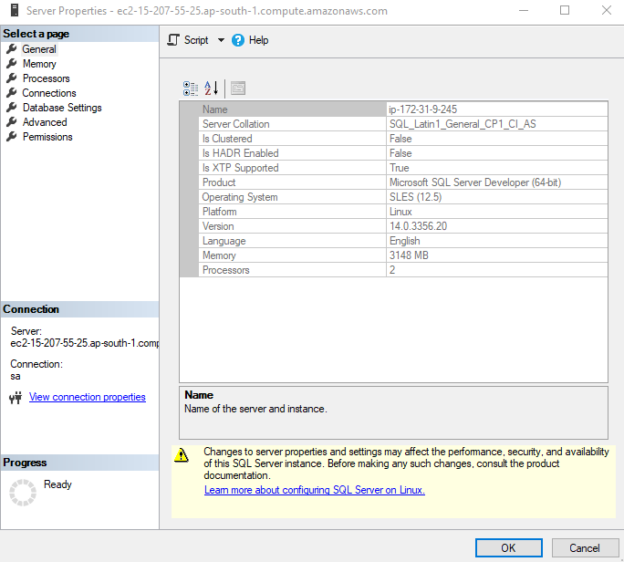
In this article, we will install and configure SQL Server Linux (2017 version) on SUSE Linux in the Amazon EC2 Instance.
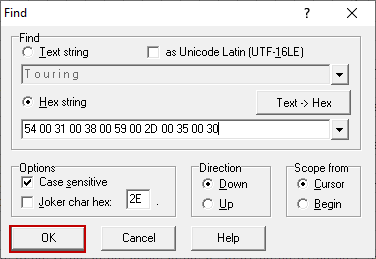
Data consistency errors are the nightmares of database administrators (DBAs) and when we notice “Could not continue scan with NOLOCK due to data movement” explanation in any error message, we are sure of getting in trouble. In this article, we will discuss the details of this data consistency problem.

The recent trend proves that the adoption of the Cloud has much greater significance and importance in modernizing IT. If you are working on migrating the on-premises SQL Server to Microsoft Azure cloud, you need to have a better understanding of the key differences between Azure SQL databases and SQL Server on Azure VMs and […]
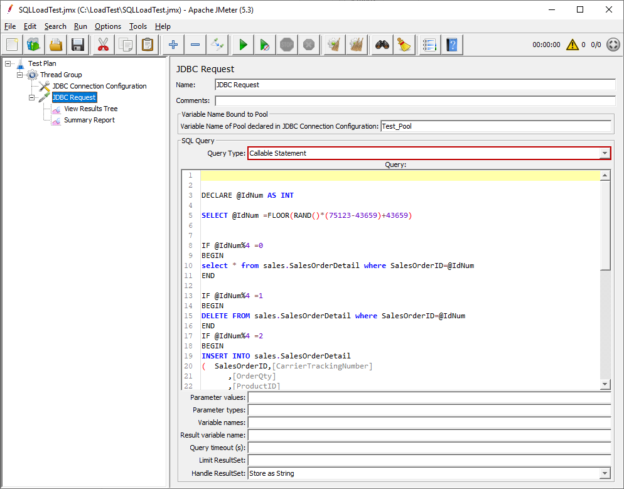
In this article, we will learn how to use Apache JMeter to perform a load test on SQL Server. This test type enables us to measure the application behaviors under specific conditions so that it enables us to observe a variety of resource consumptions (CPU, memory, latency, response times, etc) and it also helps to […]
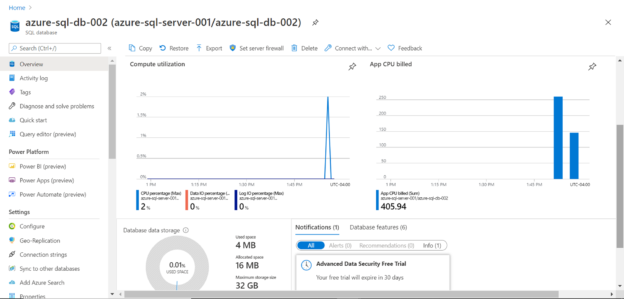
In this article, we will take a look at how to create a serverless Azure SQL database.
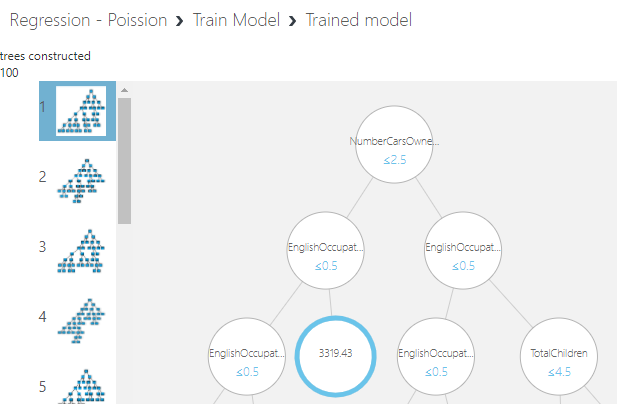
Introduction We will be discussing one of the most common prediction technique that is Regression in Azure Machine Learning in this article. After discussing the basic cleaning techniques, feature selection techniques and principal component analysis in previous articles, now we will be looking at a data regression technique in azure machine learning in this article.
© Quest Software Inc. ALL RIGHTS RESERVED. | GDPR | Terms of Use | Privacy