
Amazon Aurora provides a MySQL and PostgreSQL compatible relation database with performance and feature enhancements over the existing databases. In the previous articles, we discussed the following features. You can refer to ToC at the bottom.
- Backtrack
- Global Database
- Amazon Aurora Serverless
In this article, we will cover fast database cloning and its usage for aurora databases.
Overview of Amazon Aurora Clone Database
Suppose you want to test the application code, run analytical queries, performance testing. You require the production database in the development environment. Usually, we restore the production database backup into development and give it to users to perform their operations. Aurora clone is a quick and cost-effective way to create a duplicate aurora cluster volume, data. The aurora clusters use shared cluster volumes, and it maintains 6 copies of data in three availability zones.
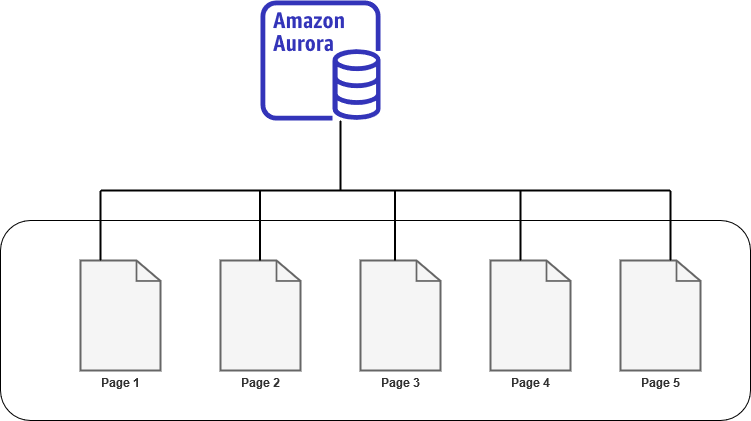
Suppose your database has the following 5 pages in the cluster volume. Currently, your production instance reads data from these pages for any users’ queries.
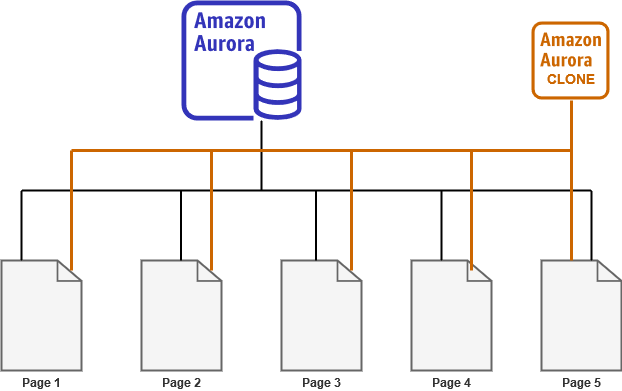
Let’s say the database is idle, i.e. there are no active transactions (data modification) on your aurora database. At this point, you clone the aurora cluster. In this case, initially, the cloned cluster also uses the existing source volume. It does not copy any pages until no data (page) modifies. In this scenario, it does not require any additional storage.
As shown below, both the source and Clone cluster point to the same data pages in shared storage.
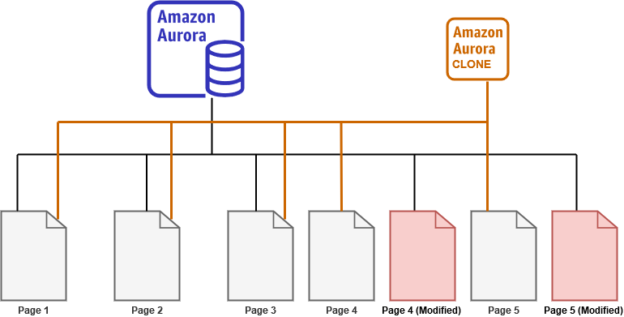
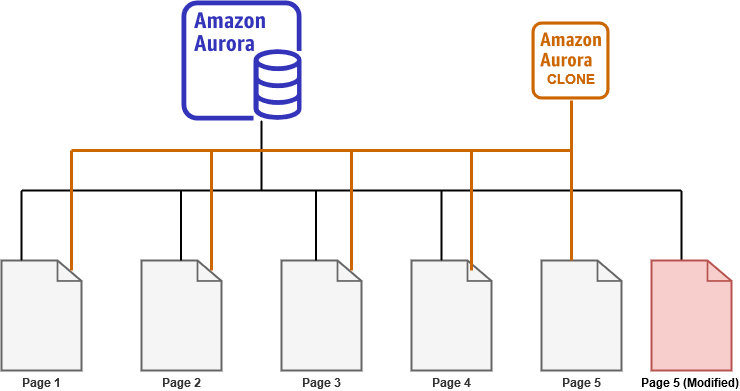
Now, the user connects with the writer endpoint on the source (production) cluster, and it modifies page 5. In this case, the source aurora cluster points to the modified page 5. It does not make changes to an existing page; instead, it writes a new page with the modified data. Therefore, you require additional storage for the modified page.
The cloned copy of the aurora cluster still points to the old page 5. It does not get the updated copy of the page.
Similarly, if page 4 also modifies on a production cluster, the source aurora stores the content on a new page. The clone cluster still points to old page 4, as shown below:
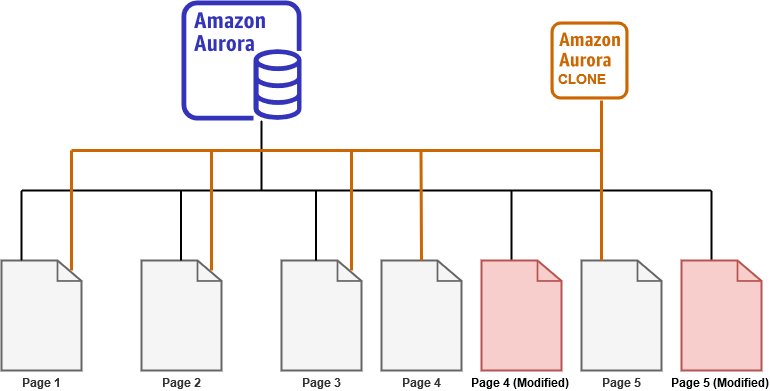
Usually, the clone database is considered to be a read-only database. In aurora, we can modify data for the clone database as well. For example, let’s say, you connect to the aurora clone writer endpoint, execute the query, and it modifies page 1.
In this case, the cloned cluster points to the newly modified page while the source still points to the original page. Here, we require the additional space for the clone cluster volume. Any changes in the clone database do not impact the source aurora instance. It makes it suitable for testing your queries, performance benchmarking, load testing.
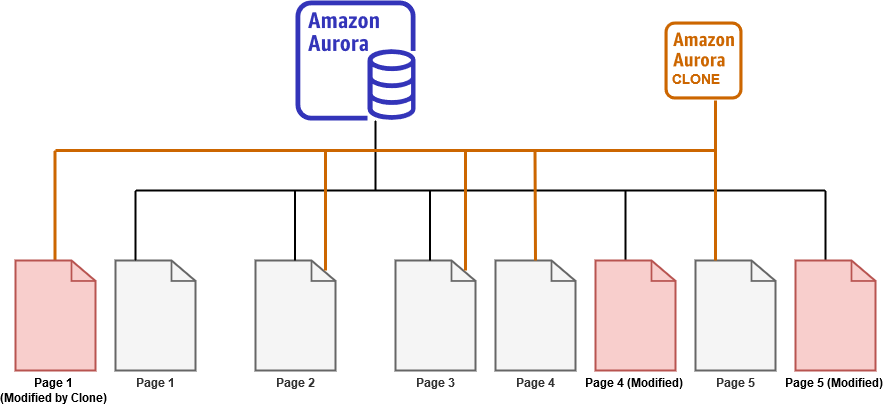
The storage requirement depends on data modifications. If you have too many data page changes, it will require additional space for each copy of the source page. You only pay for the changed page. Aurora uses the copy-on-write protocol to create a new page copy, update the pointers when any changes occur in either source or clone database. Aurora allows you to create multiple clones for your data.
Aurora Clone limitations
Aurora clone features come with few limitations. It is essential to know those limitations before we proceed with the implementation.
- Aurora clone database is not supported on Serverless architecture or cluster with parallel query feature.
- You should have at least one database instance in the Aurora cluster.
- Both Source and clone aurora clusters should be in the same region.
- You can create a maximum of 15 clones for a cluster. Further, each clone copy also supports a maximum of 15 clones.
Create a database clone for Amazon Aurora
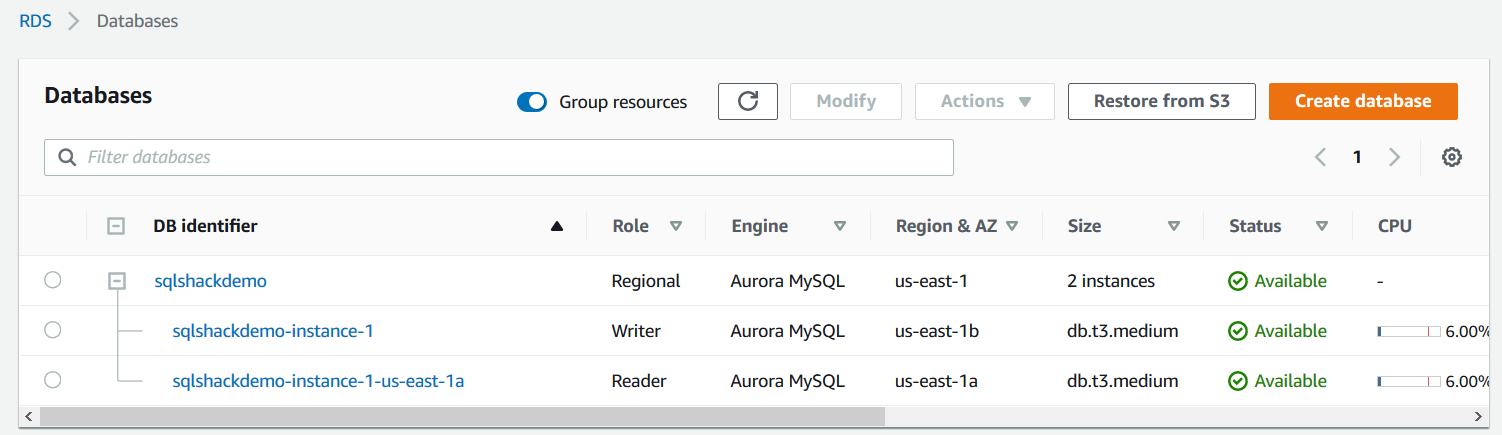
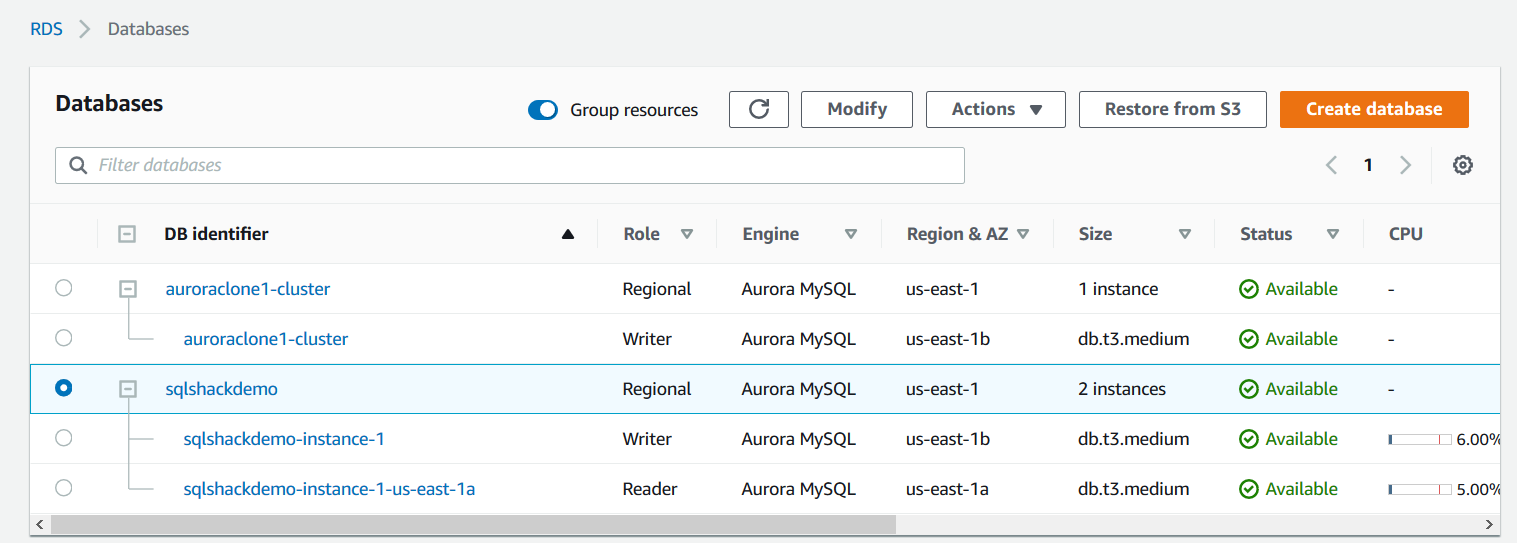
In this article, I have the following aurora cluster before we create a clone.
-
Aurora cluster name: sqlshackdemo
- Writer: sqlshackdemo-instance-1
- Reader:sqlshackdemo-instance-1-us-east-1a
- An AWS EC2 Linux instance that connects with the Aurora MySQL cluster
- Install MySQL client tools for connecting with aurora instance

To connect with the aurora MySQL instance, click on the aurora cluster name in the database terminal and note down the writer endpoint.
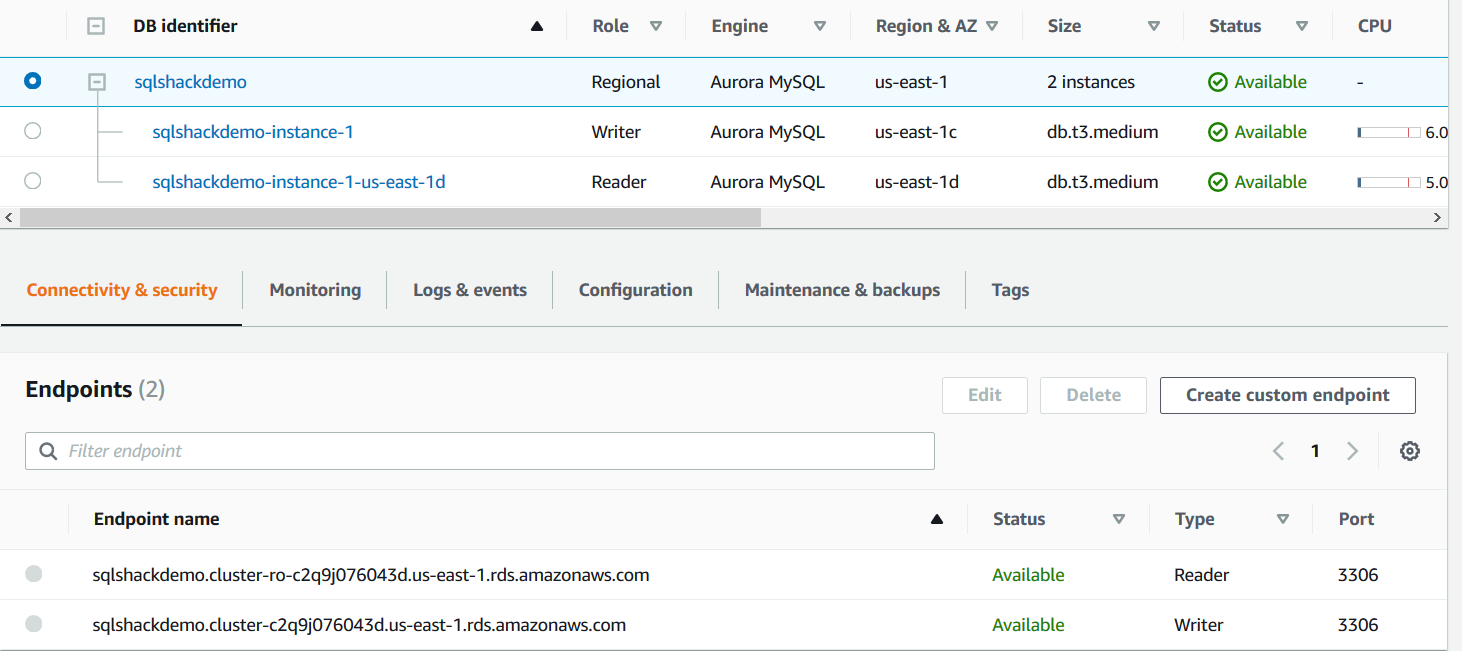
In the EC2 terminal, connect with the aurora endpoint using the writer endpoint:
$ mysql -h sqlshackdemo.cluster-c2q9j076043d.us-east-1.rds.amazonaws.com -P 3306 -u admin -p
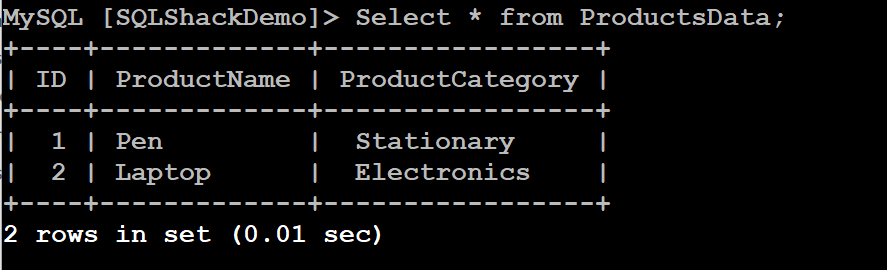
On the source cluster, we have a [ProductData] table in the [SQLShackDemo] database. It has two records, as shown below:
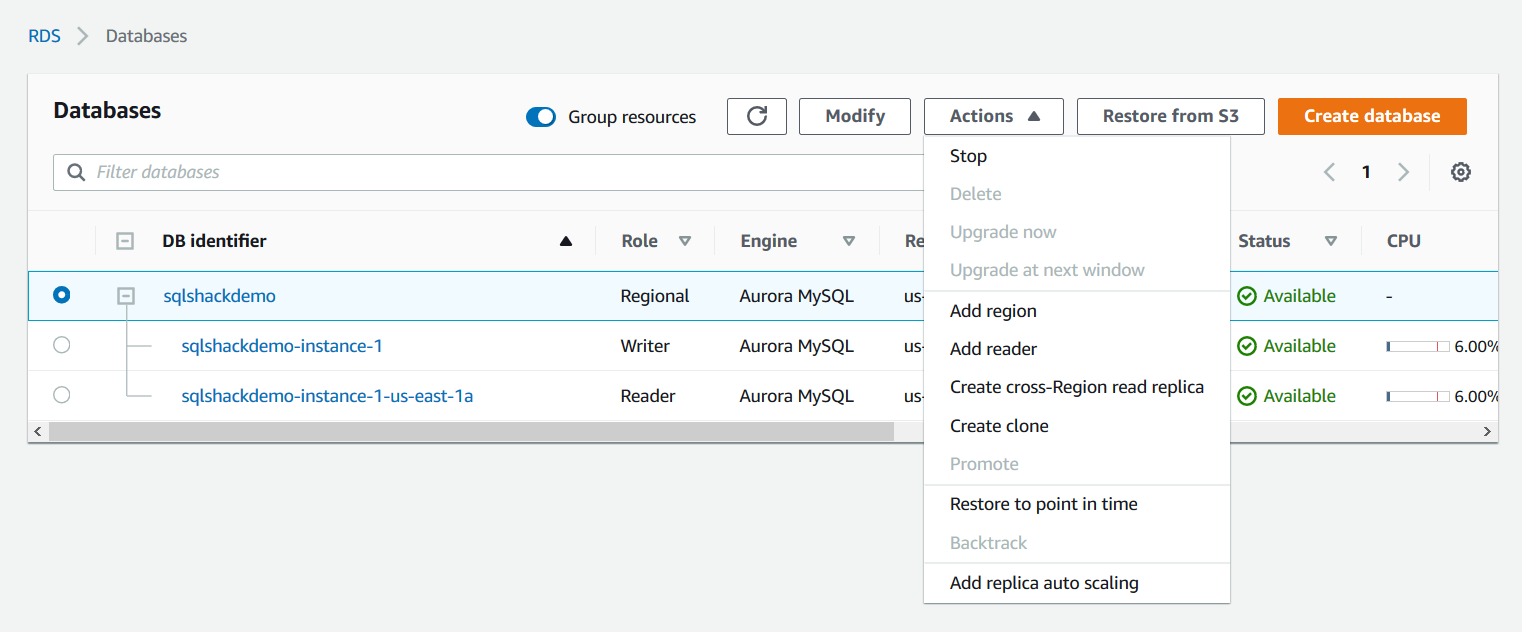
Now, to create the Clone, select the aurora cluster, go to Actions-> Create Clone.
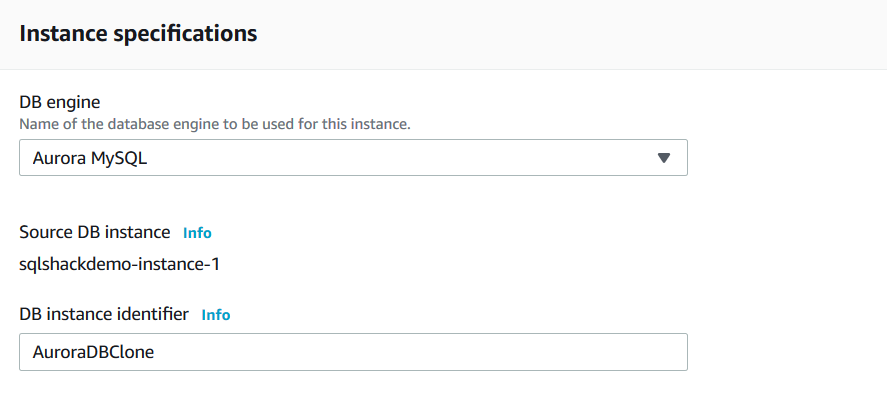
It launches the clone configuration page. It has almost the same configurations for your source cluster. However, you can give inputs such as DB instance identifier, DB instance size, VPC, Subnet, Public accessibility. In this demo, I specify the aurora cluster clone as [AuroraDBClone].
Select the desired clone instance size. You can use both burstable and memory-optimized classes for the clone instance.
Click on Create Clone after specifying the cluster configuration parameters.
It starts creating the cloned cluster and instance, as shown below:

It takes quite a few minutes to create the aurora clone cluster. The clone creation time depends upon the database size, instance class.
As we can see below, both the source and clone cluster is in available status. The clone and source instance both are in the same region us-east-1b.
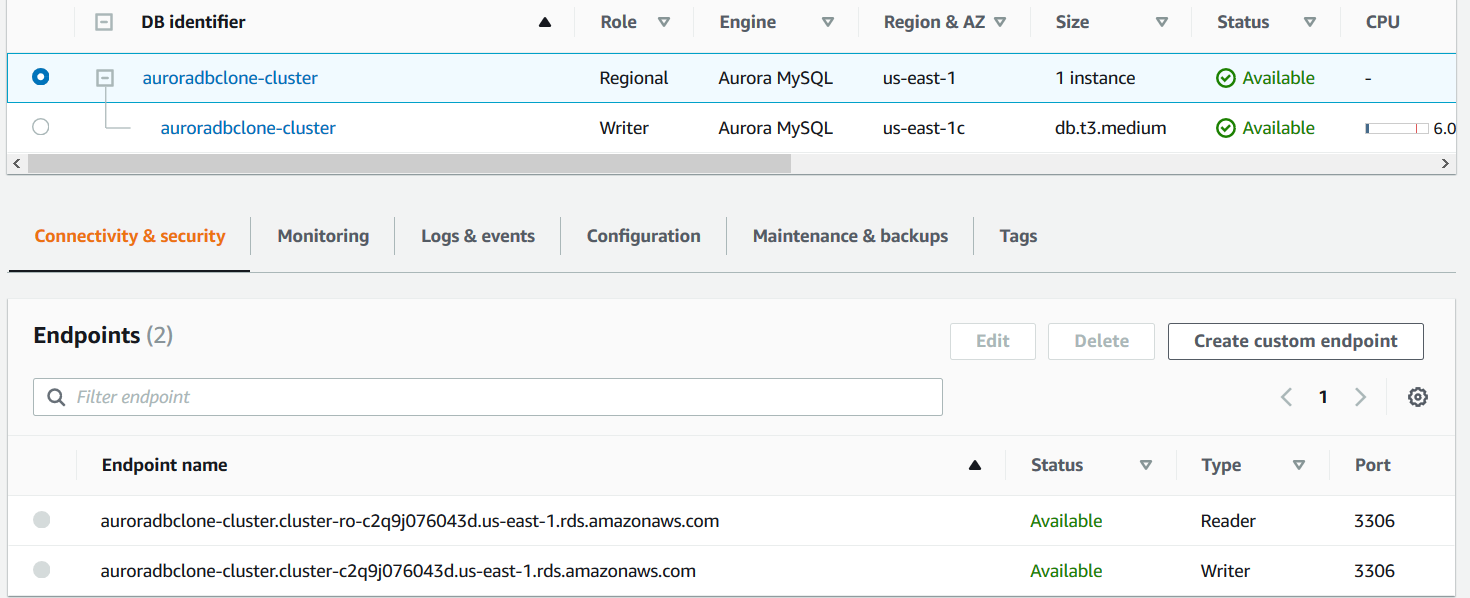
Now, the application can connect with the cloned cluster using its endpoint. As shown below, the aurora clone cluster also has a reader and writer endpoint. It also uses port 3306 for its communication purpose.
Verify table checksum in source and Clone Aurora cluster
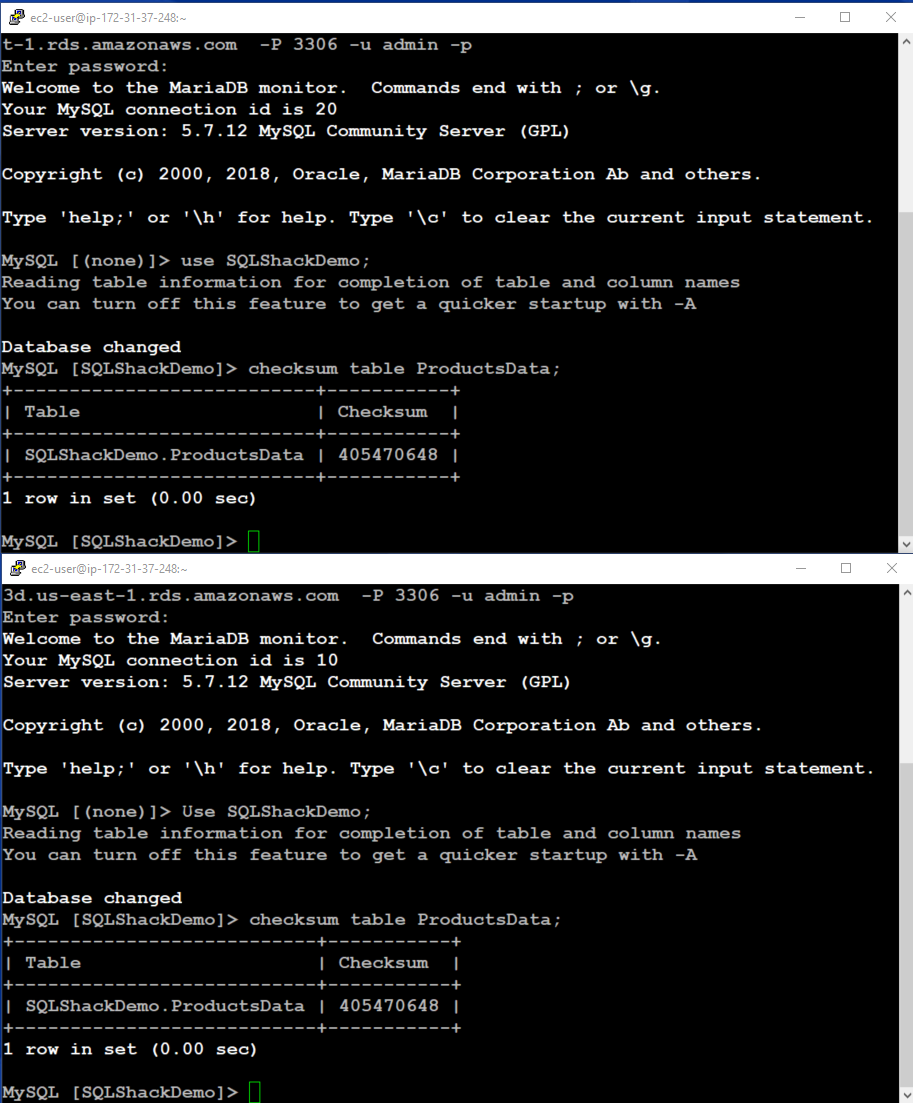
As stated earlier, the cloned cluster refers to the same database pages in the shared storage in an idle cluster. To verify it, let’s perform a CHECKSUM for the table [ProductsData] contents. If the table checksum is different, that means both source and clone instance tables are different in some way. The checksum should be similar for both tables in an idle (No Data modification) instance.
In the following screenshot, we can see that the table checksum is the same for both the Source and Clone aurora cluster. It shows that our table is identical in both clusters.
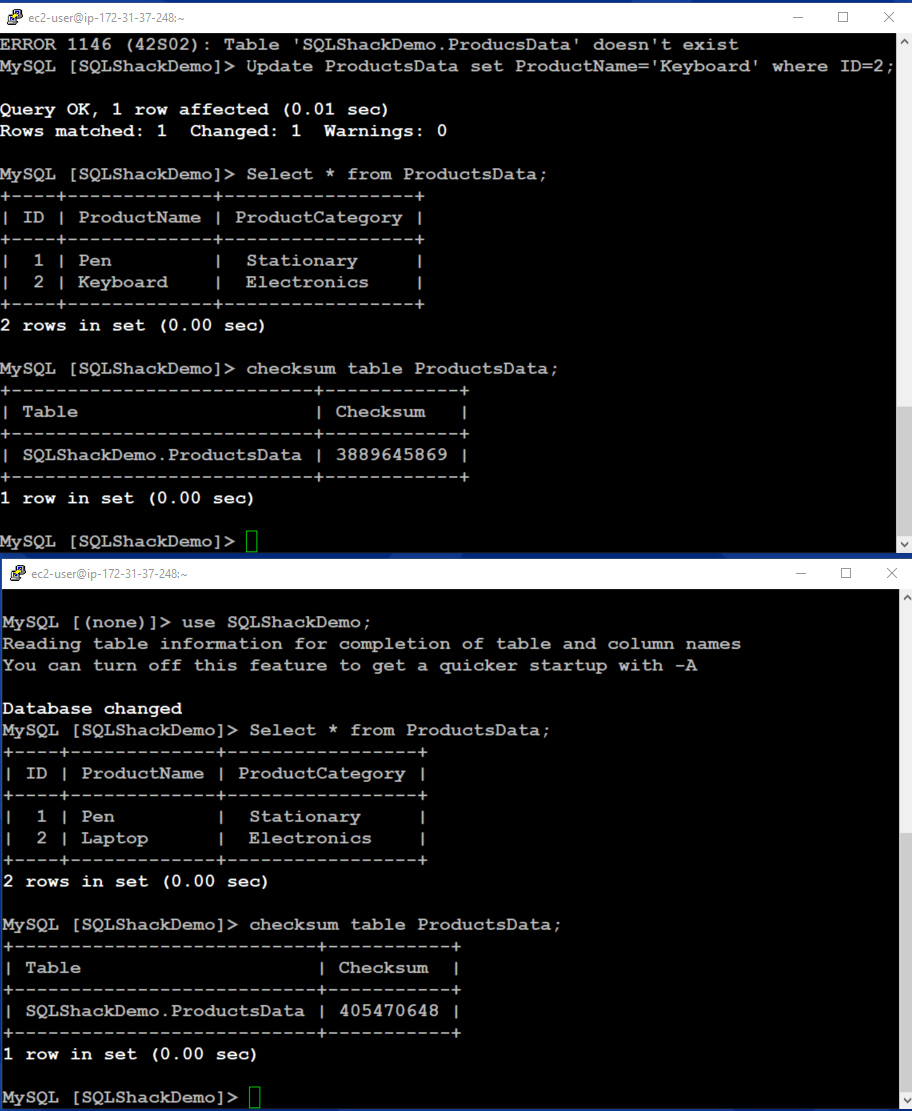
Modify data on Source Aurora cluster
We can perform DML on both Source and Clone Aurora clusters. In the below image, we update the [productname] in the source instance.

Now, we check the records as well as their checksum in both clusters. As we can see here, on the source cluster, record and checksum are updated. However, our clone instance stills give us old records and their checksum. It proves our point that Aurora uses a copy-on-write protocol and creates a new page for any data modifications.
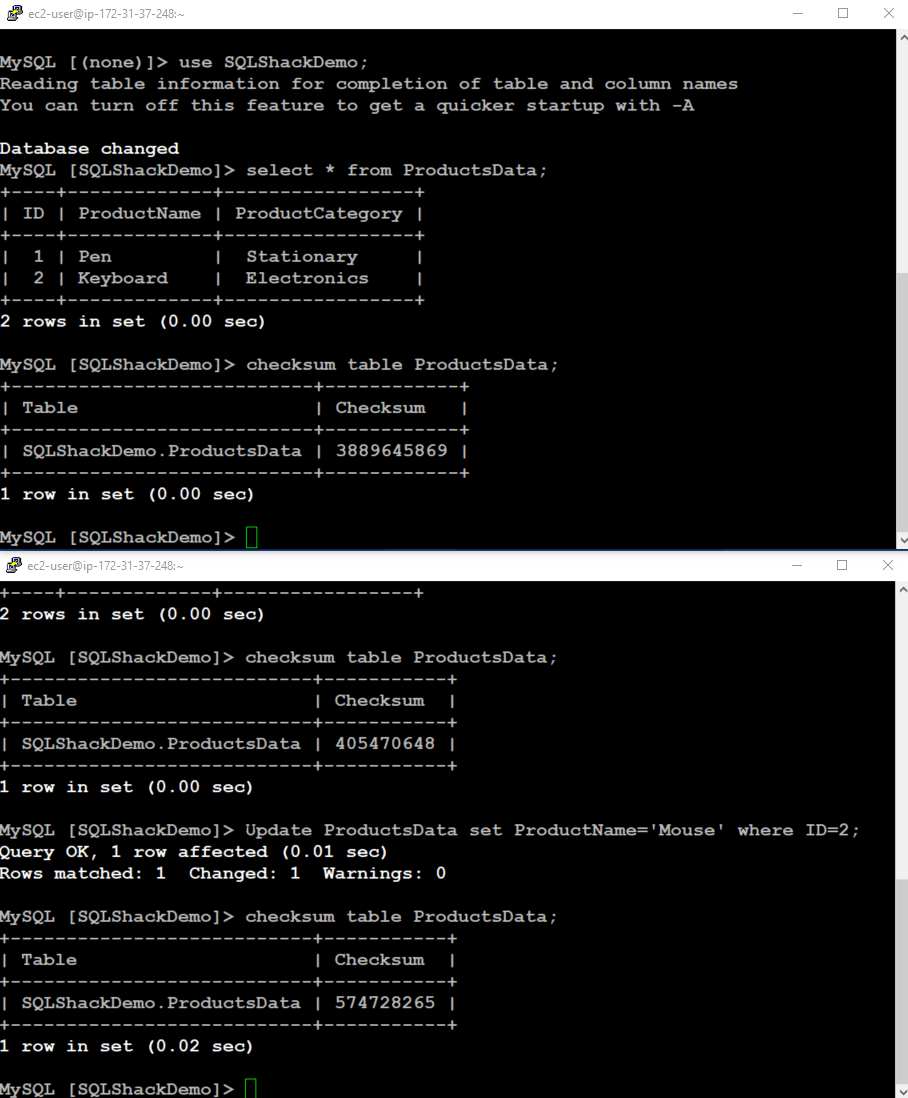
Modify data on Clone Aurora cluster
In this part, we connect to the aurora cluster using the writer endpoint and perform a DML operation. It should not impact our source aurora cluster data and table checksum.
Note the following in the below screenshot:
- Source data and its checksum remain intact
- The clone instance record is updated as per our DML, and it has a modified table checksum as well
Cross-account cloning
Amazon Aurora allows you to share the Clone with another AWS account. Usually, in an organization, we have separate accounts for production and non-production environment. Similarly, you might want to share the Clone with an external vendor for resolving specific issues, performance problems. In this case, you need to provide permissions for other AWS accounts so that they can access your clone cluster. You can explore more about cross-account cloning, its implementations and restrictions in AWS blogs.
Conclusion
Amazon Aurora clone feature allows creating the database copy for performing testing quickly and efficiently. It does not cost you much because it consumes space for pages that requires modification. It also allows you to create multiple clones and even clone from a cloned database.
Table of contents

I am the author of the book "DP-300 Administering Relational Database on Microsoft Azure". I published more than 650 technical articles on MSSQLTips, SQLShack, Quest, CodingSight, and SeveralNines.
I am the creator of one of the biggest free online collections of articles on a single topic, with his 50-part series on SQL Server Always On Availability Groups.
Based on my contribution to the SQL Server community, I have been recognized as the prestigious Best Author of the Year continuously in 2019, 2020, and 2021 (2nd Rank) at SQLShack and the MSSQLTIPS champions award in 2020.
Personal Blog: https://www.dbblogger.com
I am always interested in new challenges so if you need consulting help, reach me at rajendra.gupta16@gmail.com
View all posts by Rajendra Gupta
- Understanding PostgreSQL SUBSTRING function - September 21, 2024
- How to install PostgreSQL on Ubuntu - July 13, 2023
- How to use the CROSSTAB function in PostgreSQL - February 17, 2023