

In the article, Deploy your AWS RDS Aurora database clusters for MySQL, we explored the Amazon Aurora concept and deployment. In this article, we will understand about the global database feature and its implementations.
Overview of Global Database for Amazon Aurora
Aurora is an AWS managed database offering with compatibility to MySQL and PostgreSQL. In the previous article, we deployed an Amazon Aurora cluster with a writer and multiple readers. All Aurora replicas share the cluster storage and span across multiple availability zones.
In the below image, we have an Aurora cluster named [myamazonaurora] in the us-east region.
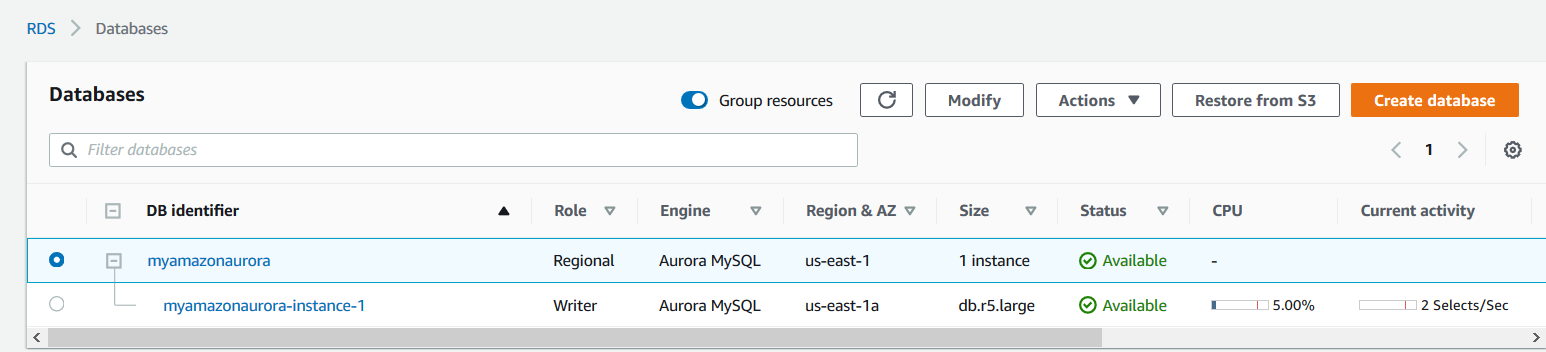
It displays the role of Regional for our cluster configuration. By default, the aurora cluster is situated in a region that we specify during its configuration.
Amazon offers a global database feature for globally distributed transactions. In this global database architecture, we have the following.
- We have one primary AWS region with read-write master and read-only replicas
- Up to 5 Secondary AWS regions for read-only workloads
- Data replicates from the primary region to the secondary region with a very low latency of under a second. It uses storage level replication for transferring the data. AWS manages this low latency due to dedicated network infrastructure for Amazon Aurora
- You can promote the secondary AWS region for read-write workloads in case of an outage or disaster
In the below image, we can look at the global database architecture.
- The primary AWS regions consist of primary Aurora instance for read-write purpose and multiple secondary instances for read-only workloads
- The Secondary replica has only read-only Aurora replicas. You cannot perform any read-write operations here
- In the secondary region, we can have up to 16 read replicas in comparison to the primary replica where 1 primary read-write and 15 read replicas are allowed
- You can use the secondary region for offloading read-only workloads and disaster recovery purposes
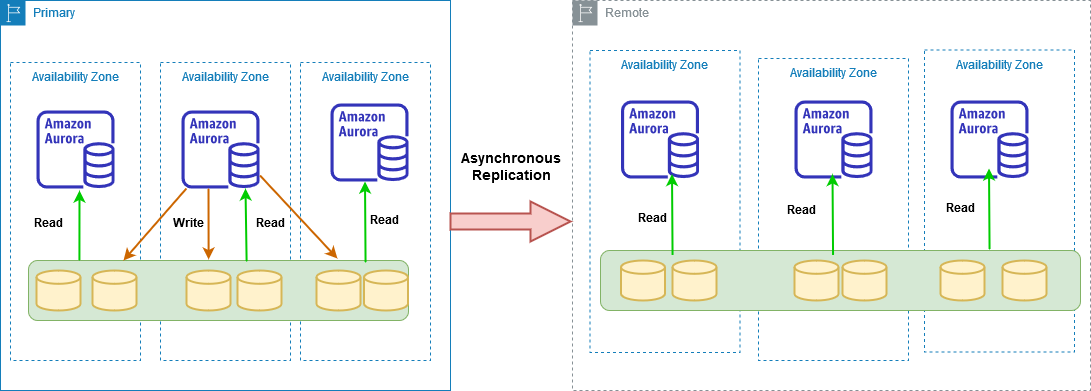
Global database deployment for Aurora
To deploy the global database, you should verify the following:
-
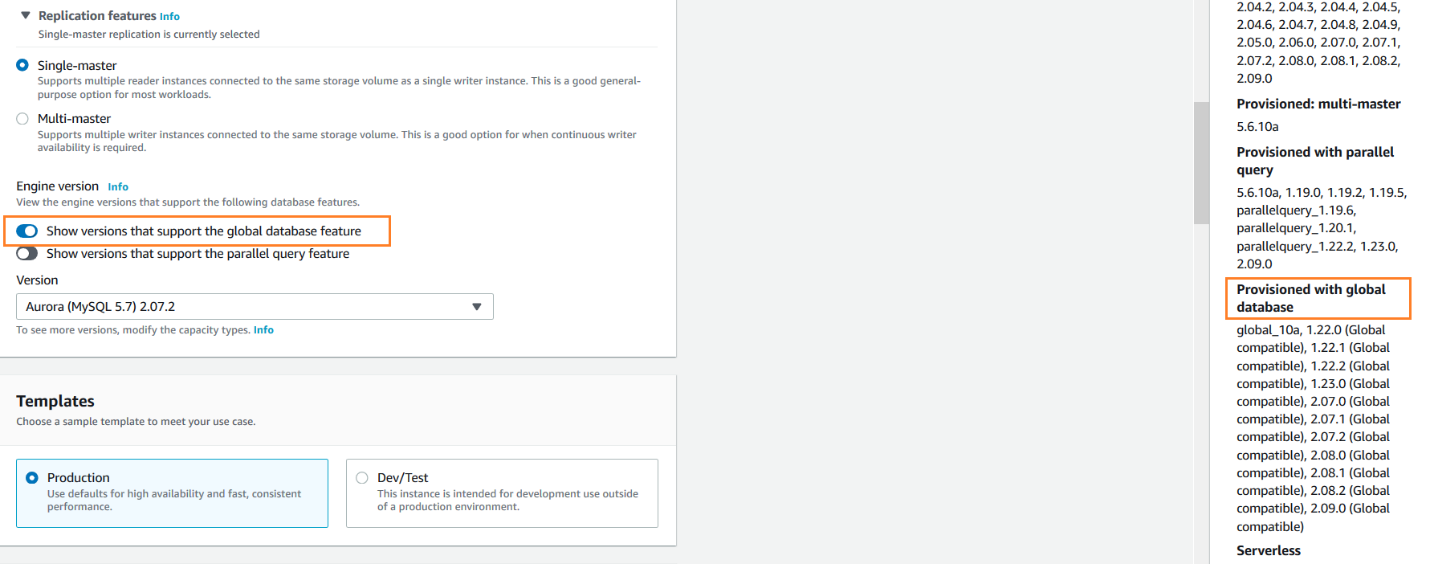
Check for the supported Amazon Aurora version for the global database. Each version of Aurora does not support the global database feature. You can check the supported version in the aurora console by enabling the option – Show versions that support the global database feature

- You cannot use the db.t2 or db.t3 instance classes with Amazon Aurora. The global database feature is available with memory-optimized classes (r and x classes)
- You should also check the AWS regions supporting the global database functionality
- You cannot deploy the global database secondary region cluster in the primary cluster region
To add a global database in the Amazon Aurora, select the region cluster in the AWS console, and click on Actions.
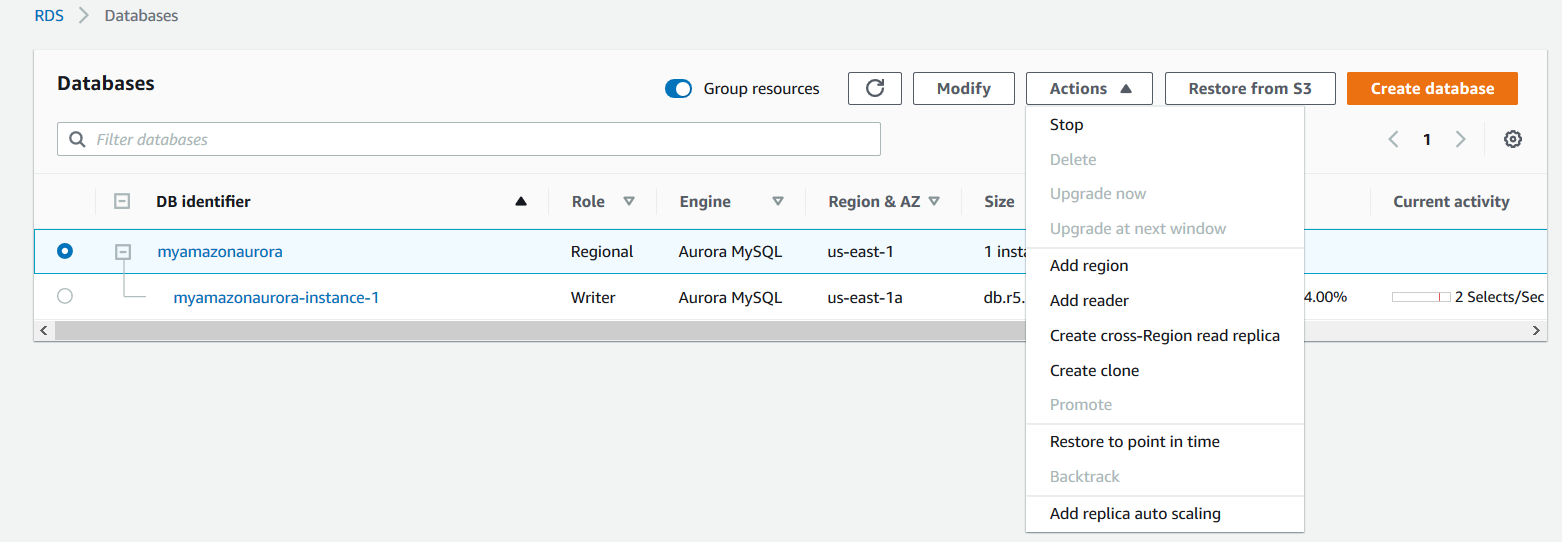
In the actions menu, click on Add Region. It opens the following page for Global database settings.
Global database identifier
Specify a unique name for the global database in your AWS account. It is case-insensitive however AWS stores the name in lowercase.
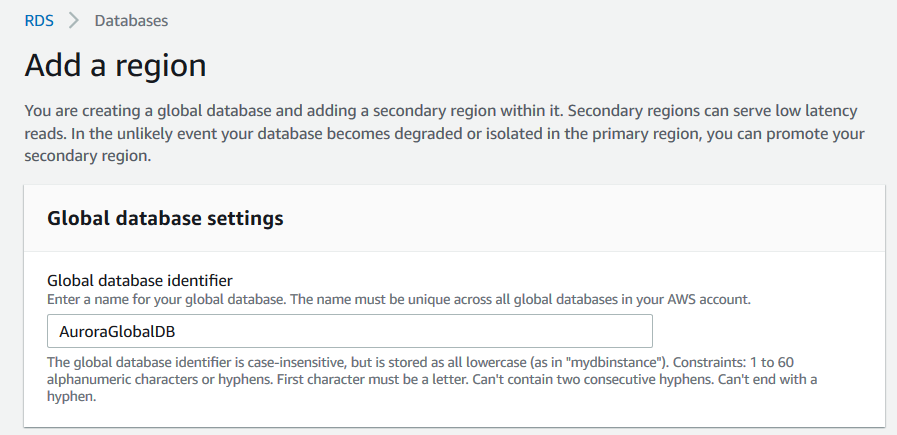
Region
Select the secondary Aurora cluster region from the drop-down list.
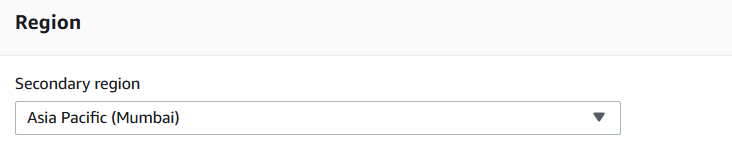
DB instance size
Select the DB instance class that meets your CPU and RAM requirements. As highlighted earlier, you can choose the burst class (db.t2 or db.t3) instances for Amazon Aurora with a global database feature. You get an option for memory-optimized classes only on the list.
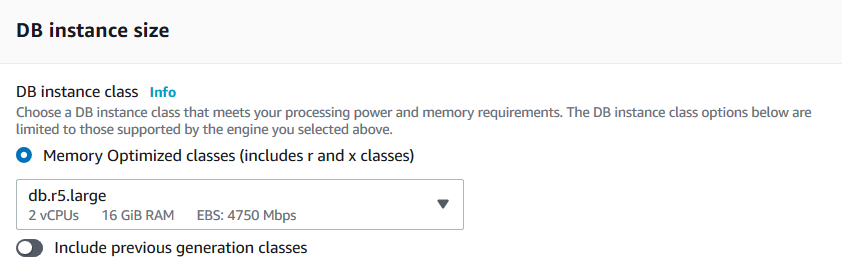
Availability & durability
In this section, you choose the Multi availability zone deployments. You can choose to create the Aurora replica for read-only workloads.
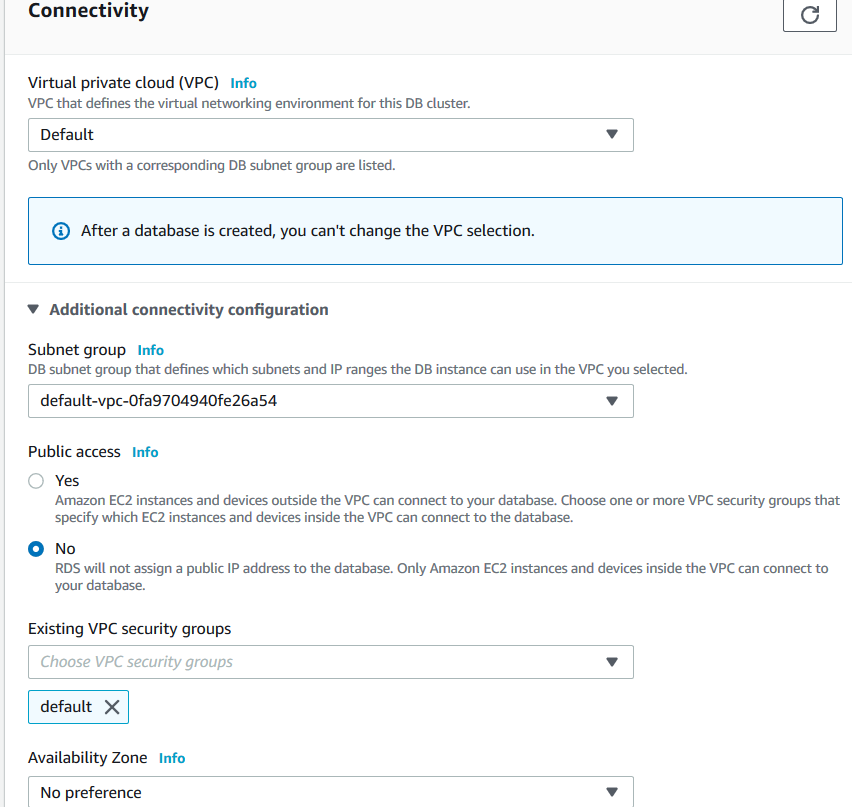
Connectivity and additional configuration
Select the VPC and subnet for the secondary AWS region for the global database. You can also choose to make the resources publicly accessible or not.
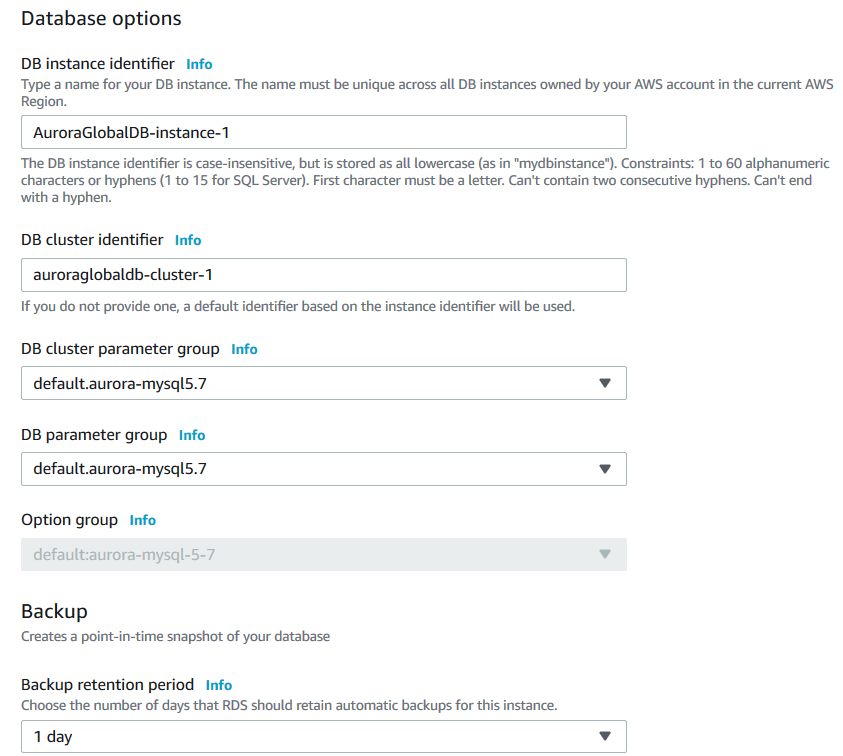
Database options
In the database options, specify the DB instance identifier for your secondary region Aurora database. It prefills the DB instance identifier, DB cluster identifier, DB cluster parameter group and DB parameter group.
Select the backup retention period with a value of up to 35 days of maximum retention.
You can configure other options similar to a regular Amazon Aurora cluster.
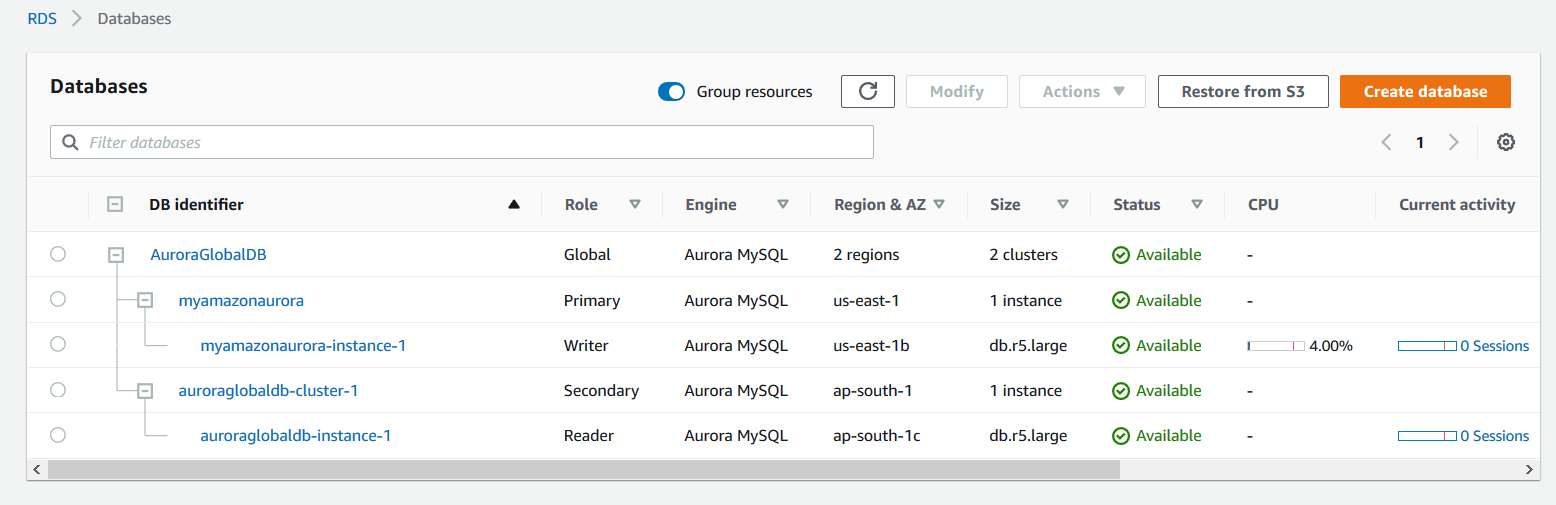
Click on the Add region, and it starts configuring the global database for Amazon Aurora. In the below screenshot, note the following.
- The global database shows 2 regions and 2 clusters
- The primary cluster is in the us-east-1 region and its servers for all read-write requests
- The secondary cluster is in ap-south-1. It is the secondary region in which it is creating a read-only replica
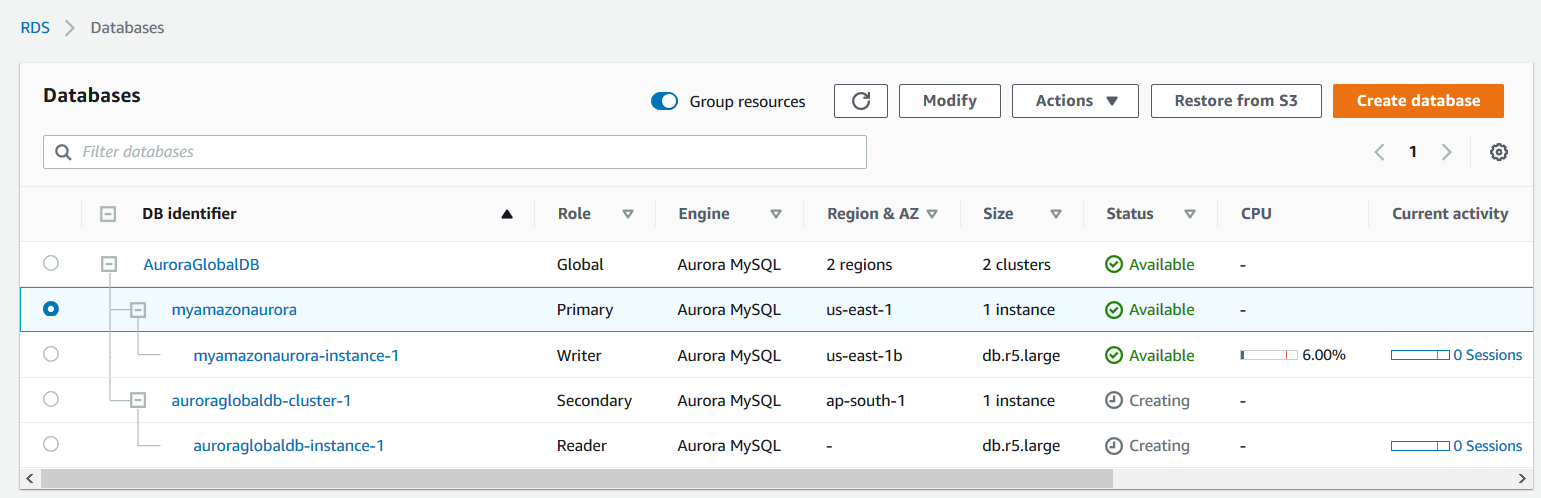
It takes approximately 15-20 minutes for promoting a regional database to a global database. As shown below, all aurora instances are in the available state.
Failover in the Amazon Aurora global database
Suppose you need to failover the primary region replica to the remote region due to an unexpected infrastructure issue. You can failover to the secondary region, and it gets promoted to serve the read-write requests. Therefore, your application and database continue to serve the business and later, you can set the global database again for the old region.
To failover, first, switch to the secondary region of your Aurora clusters. For example, in the case of my case, I have set up the secondary region in Mumbai. Therefore the AWS console is not pointing to Mumbai as shown in the top bar of the AWS console.
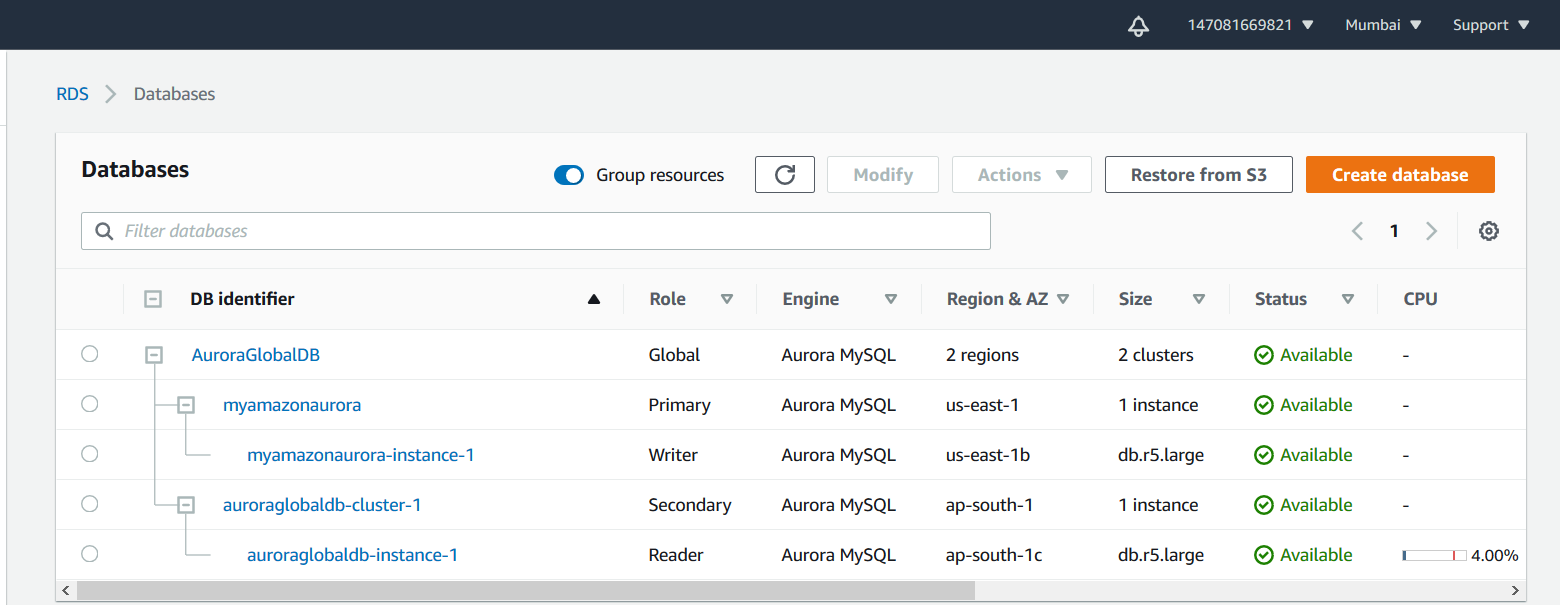
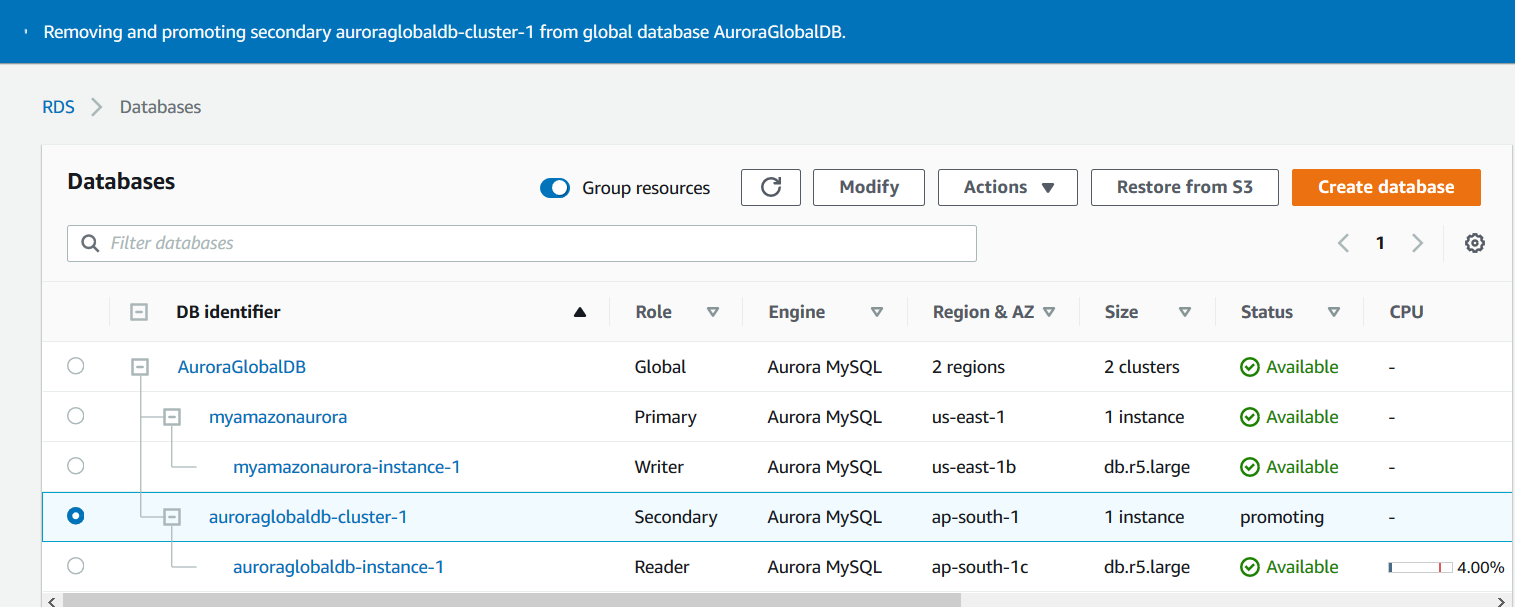
Select the secondary cluster, click on Actions and Remove from Global.
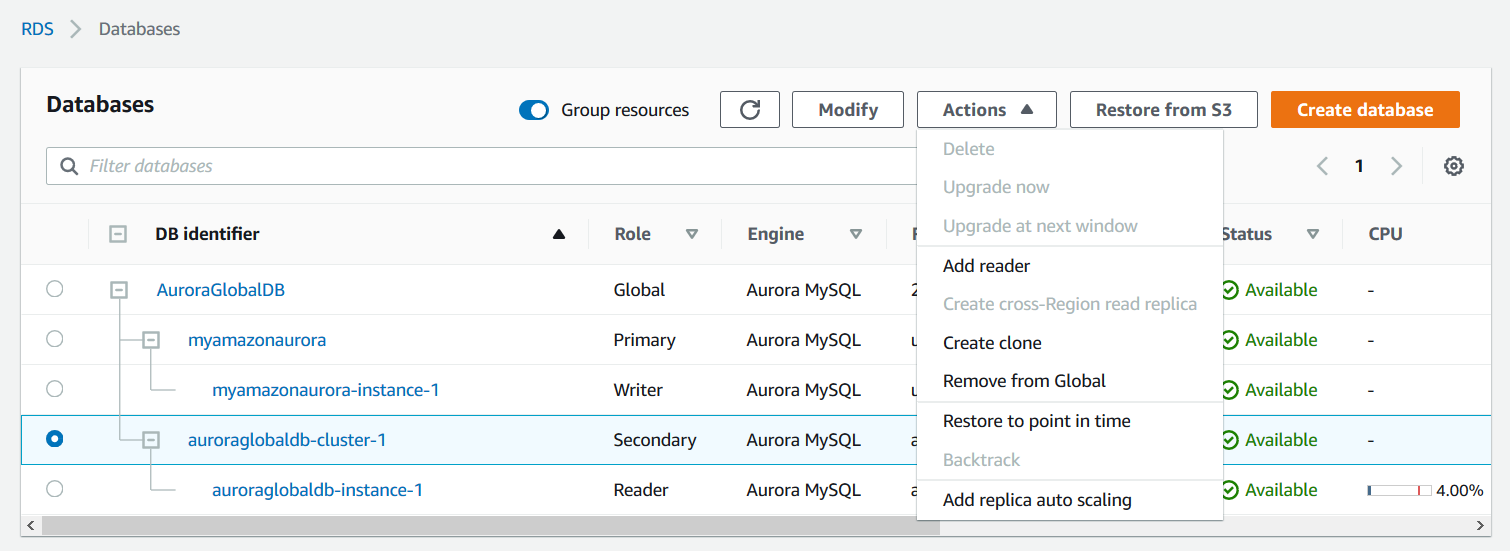
It gives a confirmation message that by removing it from the global, will stop the replication from the current primary to the secondary region. It will convert the secondary region cluster as a standalone cluster.
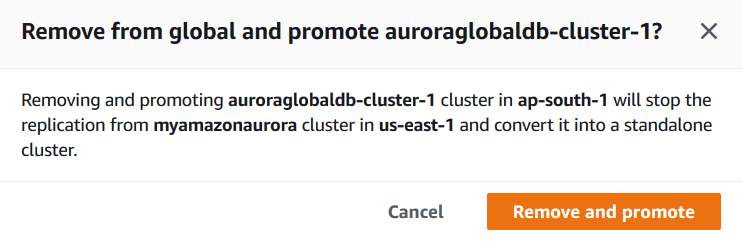
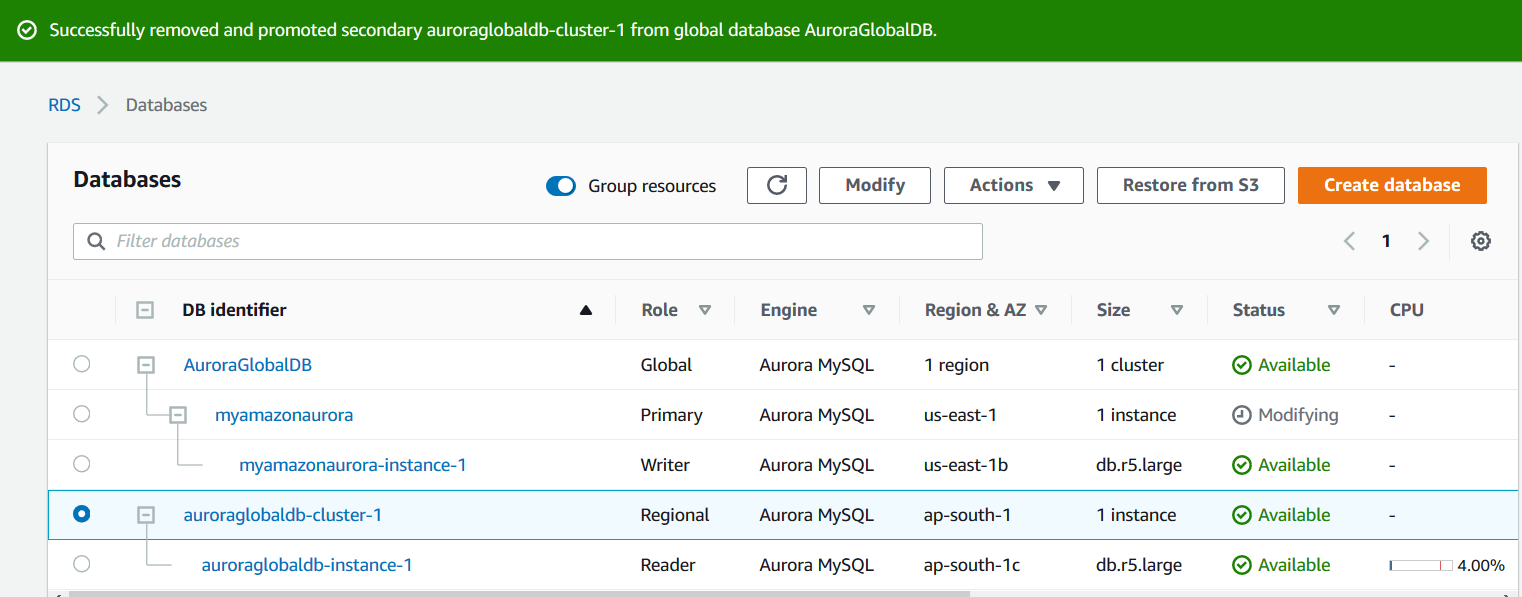
Click on Remove and Promote. As shown below, the status of the secondary cluster changes to Promoting.
Once the process gets complete, notice that the second cluster is showing the role of Regional. It is not a member of the global cluster.
Monitoring the latency between primary and secondary cluster for the global database Amazon Aurora
As stated earlier, the global database consists of latency of less than 1 second between the multiple regions. In the above steps, we configured the global database with the following regions.
- Primary: Us-east-1
- Secondary: ap-south-1
Let’s see do we have latency less than a second between these regions. For this purpose, go to services and open CloudWatch. In the CloudWatch, check the dashboard. We do not have any dashboard.

Click on Create Dashboard. Specify a name for the CloudWatch dashboard.
Once the dashboard is created, add a widget to the dashboard. For this purpose, select the Number widget and click Next.
It shows you the available metrics. You should be in the secondary cluster region. For example, my secondary cluster is in Mumbai; therefore, in the below image, you can see the selected Mumbai region.

Click on RDS for Aurora monitoring. It gives you a list of groups for RDS metrics.

Click on the DBClusterIdentifier, SourceRegion metrics. In these metrics, select the AuroraGlobalDBReplicationLag metric.
- AuroraGlobalDBReplicationLag: It gives you the lag between the primary and secondary global database clusters
You can visit AWS documentation for other Aurora DB metrics.
It shows you the latency is 114ms for my Aurora clusters primary (us-east-1) and secondary (ap-south-1) region.
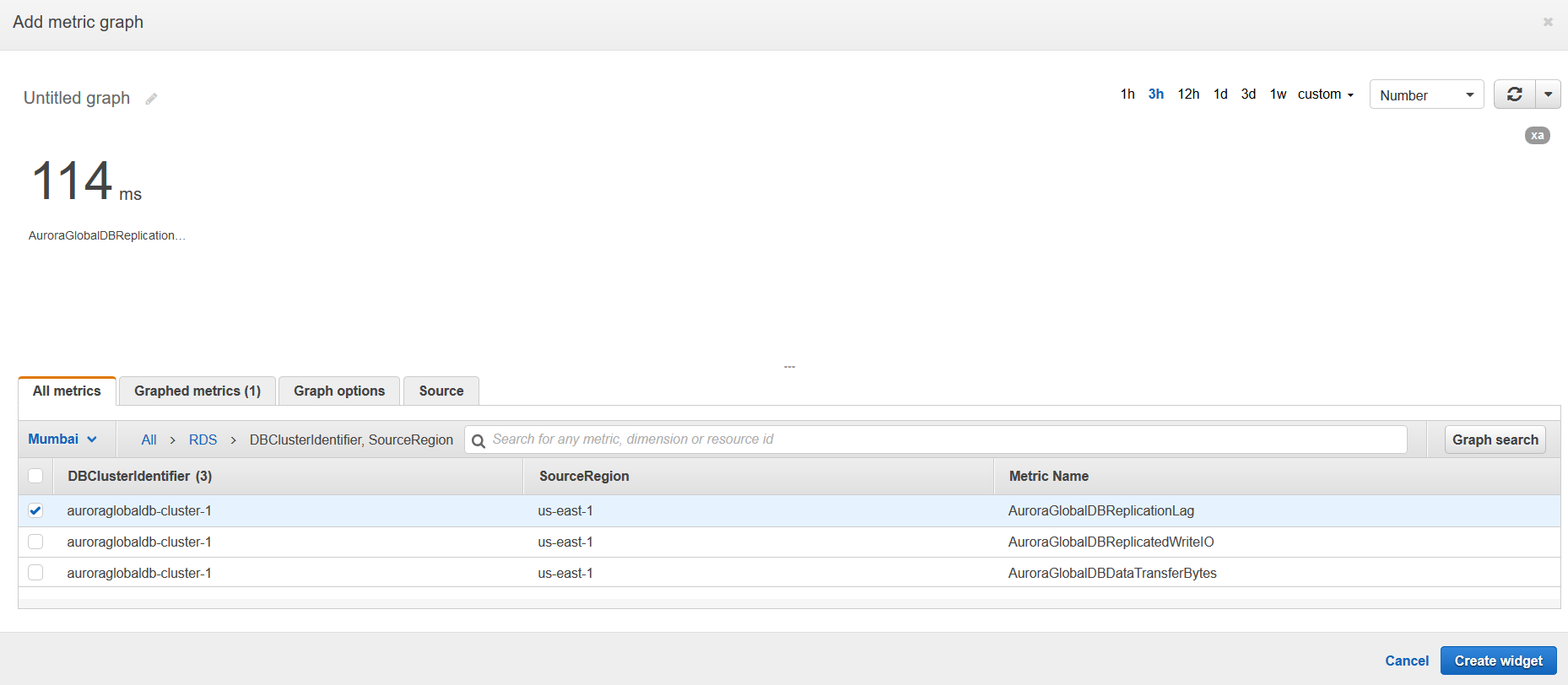
Click on Create Widget, and you get the Aurora region latency as shown below.
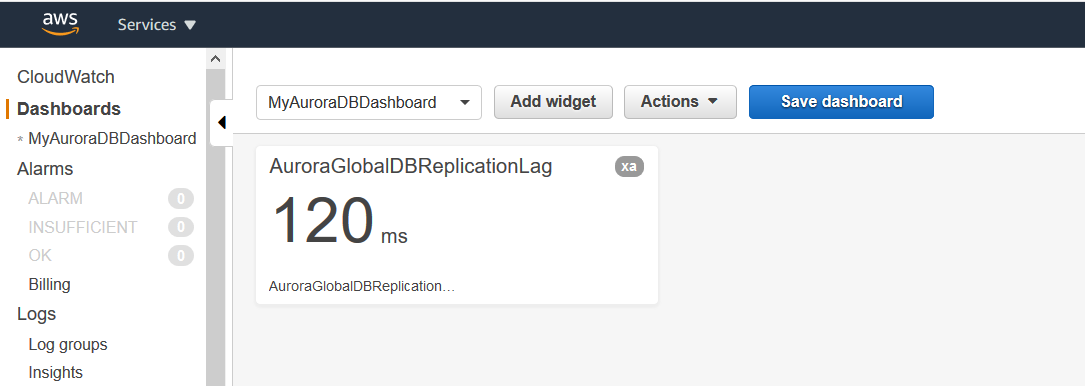
By default, the CloudWatch dashboard refreshes every 1 minute. You can set it Auto-refresh or refresh every 10 seconds or 1-15 Minutes.

Conclusion
In this article, we learned about the global database feature between different regions in the Amazon Aurora. It is an excellent feature for disaster recovery with very low latency in the primary and secondary regions.
Table of contents

I am the author of the book "DP-300 Administering Relational Database on Microsoft Azure". I published more than 650 technical articles on MSSQLTips, SQLShack, Quest, CodingSight, and SeveralNines.
I am the creator of one of the biggest free online collections of articles on a single topic, with his 50-part series on SQL Server Always On Availability Groups.
Based on my contribution to the SQL Server community, I have been recognized as the prestigious Best Author of the Year continuously in 2019, 2020, and 2021 (2nd Rank) at SQLShack and the MSSQLTIPS champions award in 2020.
Personal Blog: https://www.dbblogger.com
I am always interested in new challenges so if you need consulting help, reach me at rajendra.gupta16@gmail.com
View all posts by Rajendra Gupta
- Understanding PostgreSQL SUBSTRING function - September 21, 2024
- How to install PostgreSQL on Ubuntu - July 13, 2023
- How to use the CROSSTAB function in PostgreSQL - February 17, 2023