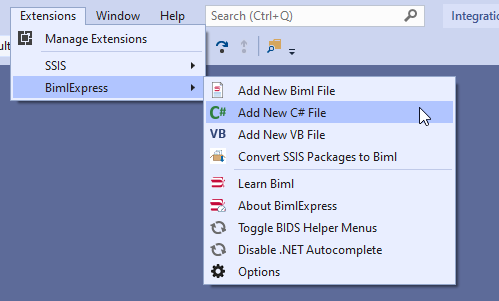
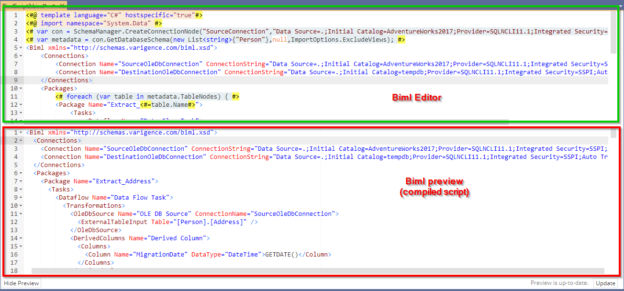
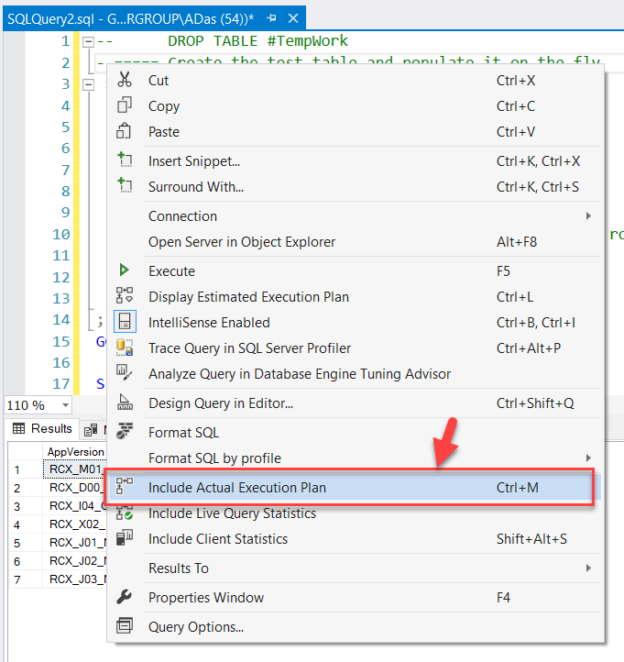
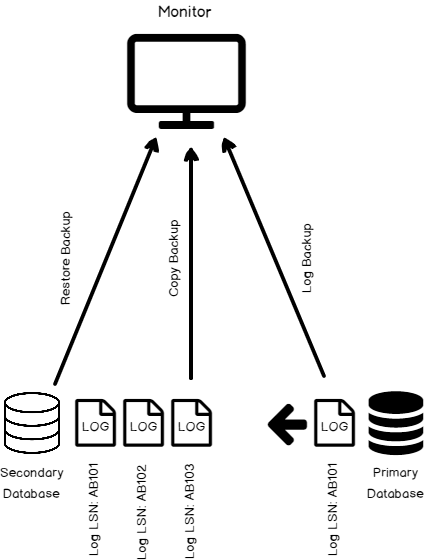
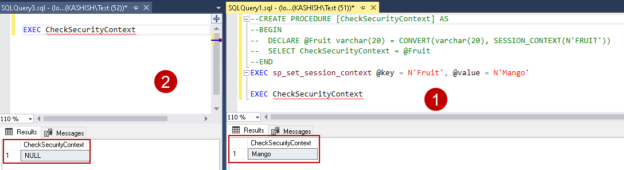
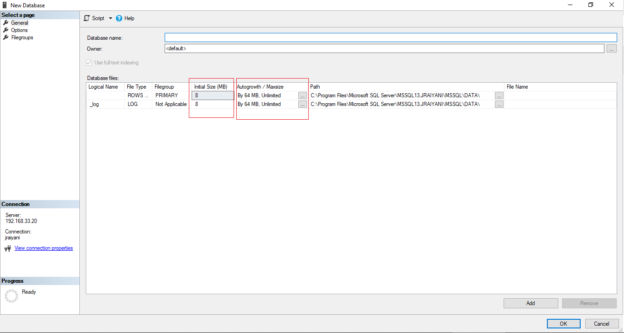
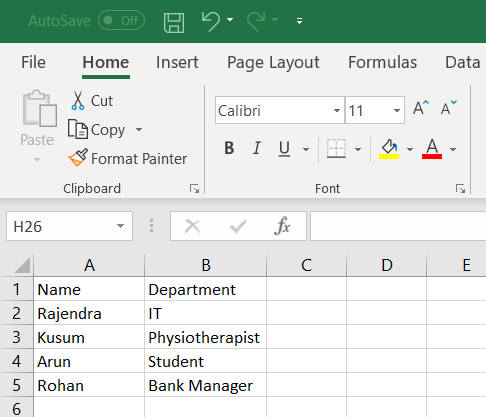
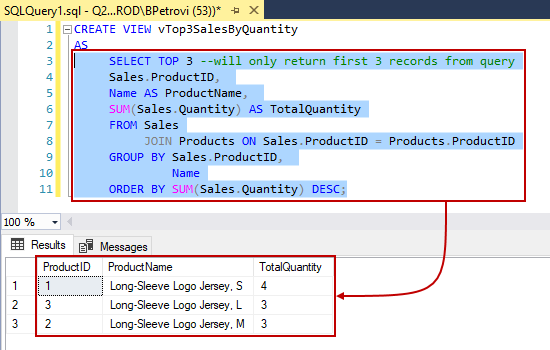
In the previously published article, Extending Biml with C# scripts, we have explained how to use VB or C# scripts within the Biml code to prevent doing repetitive development work. But in this solution, the C# scripts and classes are only available within a single file while we may need to use them in many.
Read more »