
Database design and Logical Asseveration play a vital role in database performance and SQL Query optimization. Both have different parameters to make your database and the query accurate.
Database Design
Database design plays an essential role in the database performance side. If the table structure is not in proper terms of data distribution and normalized way, then it could raise the significant challenge to change the structure as and when a problem comes in the picture. We will discuss a few parameters below to keep in mind when we design the database.
Normalization
Normalization is a technique to structure relational data in the form of schema and table to reduce the data redundancy and avoid the data anomaly. Data relation can be designed in 1NF, 2NF, 3NF as required with the nature of the information. Performance side, Normalization reduces IO operations with avoiding Insert/Update/Delete anomaly. Normalization of the database structure causes less amount of storage compared to unstructured data in the SQL Server database. You can understand it more over here, What is Database Normalization in SQL Server?
For example:
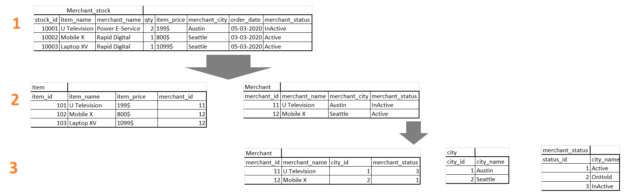
We have a table with Merchant_stock with details of Item, Merchant, Available Quantity, Price. We normalized it to end the level with the lookup table references in the last normalized form.
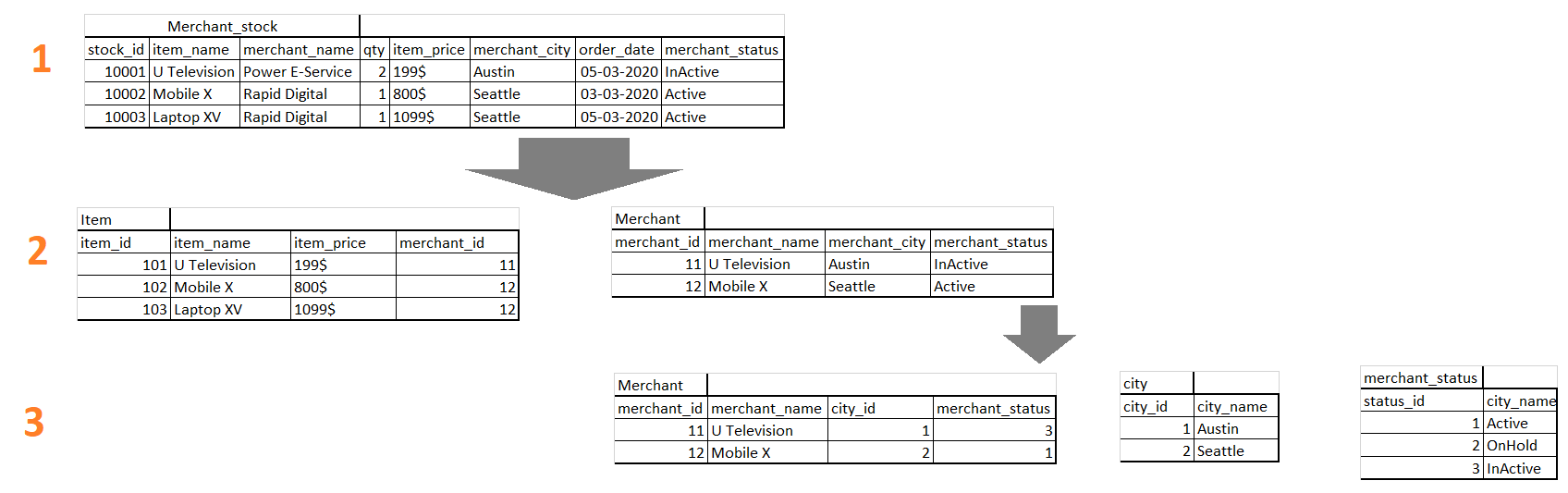
When a user wants details of Merchant, Merchant City, and Merchant status with the stock item, then the user can join multiple tables with the clause of Primary Key of the lookup tables.
|
1 2 3 4 5 |
SELECT * --(Required Columns) FROM Item AS I INNER JOIN Merchant AS M ON I.merchant_id = M.merchant_id INNER JOIN city AS C ON C.city_id = M.city_id INNER JOIN merchant_status AS MS ON M.merchant_status = MS.status_id |
End level normalization reduces the redundancy of the table. For example: a user wants to change the city or status for the merchant, (n) numbers of rows will be affected in the update statement with the first case of the above example table(merchant_stock). And in the second case, just one row will be affected in the Merchant table. Again status name change will update (n) rows in the second case. Therefore, in the third case, Integer reference is used for the merchant staus to avoid the update (n) rows in the table.
Static kinds of fields should be store in the lookup table always, and use the integer reference in the detail table is the best practice for the database design with the normalization.
Indexes
Indexes are a reference to a quick search on the information. An index is a powerful tool to directly locate the target data rather than scanning the entire table and find the required row/s from the table. The use of a Clustered or Non-Clustered index is to make quick data matching patterns. The index improves the overall query performance with the wise use of it. SQL Server allows us to create an index with the number of options as below, and each one has a significant role in the Query performance.
Index Options:
- ALLOW_PAGE_LOCKS
- ALLOW_ROW_LOCKS
- DATA_COMPRESSION
- DROP_EXISTING
- FILLFACTOR
- IGNORE_DUP_KEY
- MAX_DURATION
- MAXDOP (max_degree_of_parallelism)
- ONLINE
- OPTIMIZE_FOR_SEQUENTIAL_KEY
- PAD_INDEX
- RESUMABLE
- SORT_IN_TEMPDB
- STATISTICS_INCREMENTAL
- STATISTICS_NORECOMPUTE
Table Partition
SQL Server Table Partition is a way of distributing the data across the file system with the set of user-defined rules. When we are working on a large-sized table, the row filter option is also available; however, it is comparatively slower compared to Table Partition option. When we have used the Table Partition on the table, the Query filter will target the required portion of the table and return the result-set relatively quickly. A query filter will decide to focus on a particular piece or partition of the table by the partition schema. Proper use of the Table Partition and table design make excellent query performance on the large table.
Users can add the File Group and Files with the database to use partition with the table. For example:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
--Adding File Group for a Database ALTER DATABASE [Database Name] ADD FILEGROUP [File Group name] GO --Adding File to File Group ALTER DATABASE [Database Name] ADD FILE ( NAME = [PartJan], FILENAME = '\C:\\...\DATA\File.ndf', SIZE = 2048 KB, MAXSIZE = UNLIMITED, FILEGROWTH = 1024 KB ) TO FILEGROUP [File Group name] GO |
Row balancing
Keeping rows in a single table for all clients is not the only solution in a product-based database solution. For the different geographic client base, data needs to be stored in the database according to the client geography to meet the latency issues and better SQL Query optimization. An application can be deployed on multiple locations to perform different activities; however, the database insert location will be single. Therefore, we can have a database set up with the same tables on multiple sites, and according to the client, geography requests can be served to the target database.
Constraints
SQL Server Query Optimizer always checks for the foreign key and check constraints to prepare an efficient query execution plan, and each execution runs on the execution plan. SQL Server optimizer is too reliable and smart; if any constraint exists on the column, then the execution plan will skip the unnecessary part of data manipulation checks.
Logical Asseveration
Logical Asseveration is a part of the query process and related performance parameters. Different query strategies with the most efficient way are the right solutions for SQL Query Optimization. Here we will discuss a few parameters below to keep in mind when we write a query, Procedure, Function, or Trigger.
JOIN Structure
JOIN structure with improper order of the table affects the query performance when several tables are present in joins with multiple conditions in the ‘Where’ clause. Query optimizer always refers to the table order in joins and changes it accordingly to prepare the execution plan. However, the optimizer will not follow all the possible orders with the query statement. Therefore, the developers have to try to order the table in the prepared query with one to one mapping. Improper order of tables in the join query consumes more resources in the server, and it affects other queries as well in the SQL Server.
Relation Expression
Relational Expression in the WHERE clause is significant for SQL Query optimization. IF EXISTS, IF NOT EXISTS, NOT IN, IN, CASE WHEN, and many more conditions can be used in the WHERE clause. Sightless use of conditions makes a surprising execution time and execution plan too. Even NOT IN can be replaced by the LEFT JOIN with IS NULL condition as well, which is not known to many developers. What kind of Expression can be used, and when that depends on the nature and types of data? To make your query fast and optimized, it depends on the logic which is being written by the developer.
For example:
|
1 2 3 |
SELECT * FROM TableA WHERE COL1 NOT IN (SELECT COL1 FROM TableB) |
Or
|
1 2 3 4 |
SELECT A.* FROM TableA AS A LEFT JOIN TableB AS B ON A.COL1 = B.COL1 WHERE B.COL1 IS NULL |
3. Data Sorting
Data Sorting is an expensive part of the query execution in SQL Server. Users can avoid using unnecessary sorting in the SQL Server program because it stores the query result set into the buffer to sort it in particular order reference. Even a SQL Server index option provides an option to store data with the sorting, yet again it is the job of the query optimizer to make perfect query execution plan.
For example: an Index is defined with the sorting column option, and rows returns from the table will be in order as well; however, SQL statement can have multiple fields in the ORDER BY clause. So, it could cause various issues to process the data to sort into the order of columns in the ORDER BY term. User needs to use required fields only to having data sorting in a particular result set only to avoid unnecessary data sorting in the procedure.
SET Options
When we are working on large-sized database or having good experience in SQL Query Optimization then definitely we could face issues like: Multiple execution plan for the single procedure in the SQL Server, Query or procedure will turn the execution faster in SSMS but not with the application, errors can be returned by the application for the procedure (Nested Procedure), but it works fine using SSMS, and many more issues can be resolved with the help of SET Options declaration in the SQL Server.
When we execute a query using SSMS, it uses SSMS default configured SET Options. Whether application uses SET Options, which are defined in the procedure or defined in the SQL Connection, therefore, there could be different ways of execution for the same procedure by the SQL Server query optimizer and to make multiple execution plans with a set of SET Options.
For example:
SET ARITHABORT ON statement is needed with the query statement or procedure 0when arithmetic operation is being used in the query.
ISOLATION LEVEL
SQL Server ISOLATION LEVEL stands for the transaction Concurrency control and ACID (Atomicity, Consistency, Isolation, and Durability). ISOLATION LEVEL for each transaction determines the integration of data with the row-level locking for the users with different level and how long the transaction must hold locks to protect data against these changes. User can define the ISOLATION LEVEL in the database connections, and requests with the command of SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED / READ COMMITTED / REPEATABLE READ / SERIALIZABLE. Even the user can change the ISOLATION LEVEL on the same command in between execution for the different purposes to data visibility and SQL Query optimization.
For example:
Users can use WITH(NOLOCK) with the table name in the query to fetch read uncommitted data. For the procedure, the SET statement can be written with ISOLATION LEVEL to get applied with all tables of the procedure.
|
1 |
SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED |
Remote Call
Remote call a is cross SQL Server Query or procedure to requests or perform operation on the remote site. Users can perform any of INSERT / UPDATE or DELETE operations using remote queries with the help of Linked Server. Even user can JOIN the remote table on the local server database table as well. A remote query is not considered as a bad thing in the SQL Server; however, if we filter or manipulate the remote data into the local server that affects the query performance, for better query performance, a user can execute the remote procedure in the local server.
The remote procedure is a good option for the SQL Query optimization, write your logic in the procedure at the remote server end and execute that procedure with the Linked Server on the local SQL Server.
Conclusion
SQL Server Query optimization can be a difficult task, especially when dealing with a large database where even the minor change can have a negative impact on the existing query and database performance.
The parameters discussed above are relevant to the database design and query writing. The product and database will be reliable and better as the above parameters are accurately defined and used in your database.

View all posts by Jignesh Raiyani
- Page Life Expectancy (PLE) in SQL Server - July 17, 2020
- How to automate Table Partitioning in SQL Server - July 7, 2020
- Configuring SQL Server Always On Availability Groups on AWS EC2 - July 6, 2020