
SQL Server 2019 has a rich set of enhancements and new features. In particular, there are many new feature improvements in the database engine for better performance and query tuning.
Some of the important enhancements are:
- Row mode memory grant feedback
- Batch mode over row store
- APPROX_COUNT_DISTINCT
- Compatibility level hints
- Enhancements to columnstore index such as an online rebuild, compression estimates
- Certificate management in the configuration manager
- Database classification improvements
In this article, we are going to talk about the Approx_Count_Distinct function. This function was available in Azure SQL Database previously but has been launched now with SQL Server 2019.
In a day-to-day environment, when we deal with data, there are many tables in the database that have duplicate values. For example, suppose a customer table holds records of all customers who buy a product from a store. As we know, the customer can buy the product multiple times and each time the customer visits the store and purchase goods, an entry is made into the customer table.
Now, suppose we want to know the unique customer’s information from our table so until now with SQL Server 2017, we use Count distinct function to get unique records. The format of count distinct function is as below.
|
1 |
SELECT COUNT (DISTINCT column-name) FROM table-name |
First, let us prepare our sample database and table with millions of rows and then I will introduce you to a new function in SQL Server 2019 Approx_count_distinct.
In this article, we’ll need to generate the millions of rows for test data for which I’ll use ApexSQL Generate
For demo purpose, let us create two tables in the database.
- Employees table:
|
1 2 3 4 |
CREATE Table Employees ( EMPId int identity primary key, EMP_name nvarchar(50) Null ) |
- Insert 2 million rows of random data
- We will insert any Null values in the table.
- EmployeesWithNull:.
|
1 2 3 4 |
CREATE Table EmployeesWithNull ( EMPId int identity primary key, EMP_name nvarchar(50) Null) |
- Insert 2 million records in this table.
- We will insert NULL values in this table
Overview of Approx_Count_Distinct function
SQL Server 2019 introduces the new function Approx_Count_distinct to provide an approximate count of the rows. Count(distinct()) function provides the actual row count. In a practical scenario, if we get approximate a distinct value also works. This new function gives the approximate number of rows and useful for a large number of rows.
This function APPROX_COUNT_DISTINCT is supposed to use less memory and CPU resources so that data result can be obtained without any issues as spilling to disk or CPU spikes. This is useful for a requirement with billions of rows.
As per Microsoft documentation, ‘The function implementation guarantees up to a 2% error rate within a 97% probability.’
Syntax for Approx_Count_distinct is APPROX_COUNT_DISTINCT (expression)
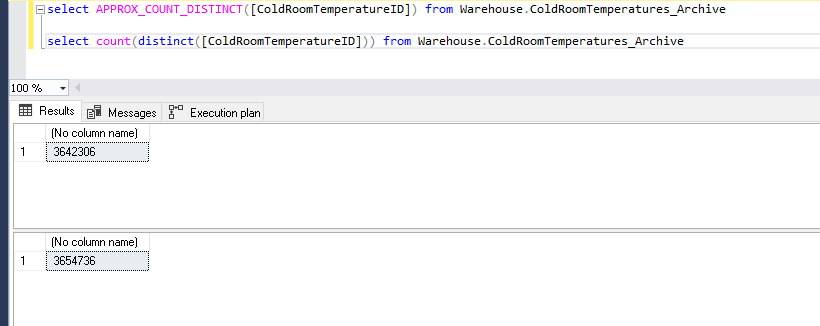
Let us perform some comparison in both the count (distinct).
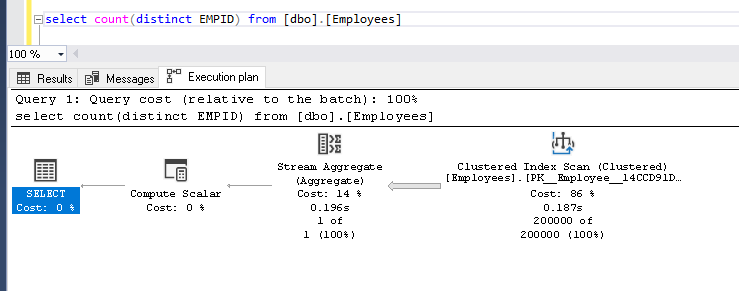
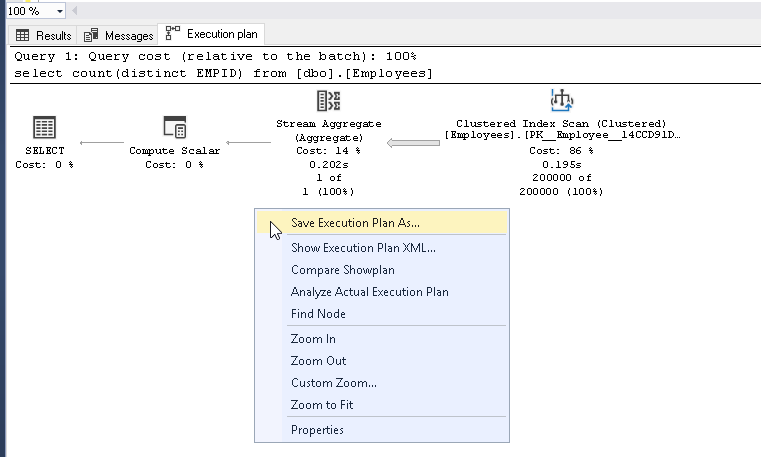
Get the count of distinct records from ‘dbo.employees’ table and view the actual execution plan
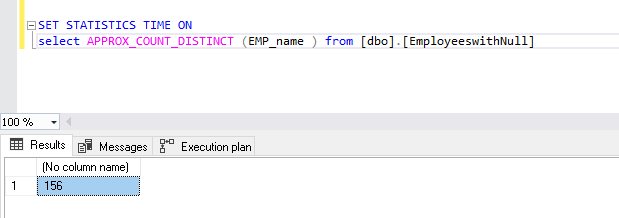
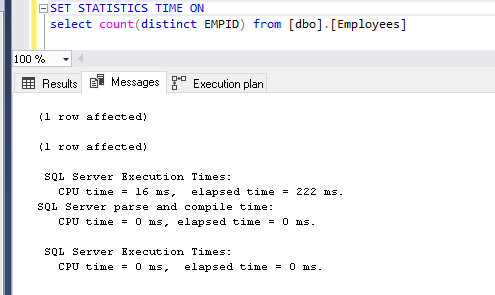
View the stats as well from the count distinct function.
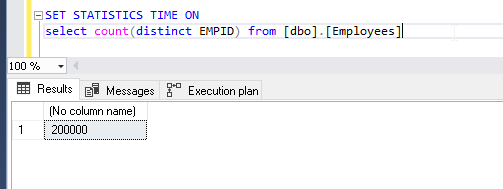
View the output record count. Its shows 2 million of distinct records in the table.
Save the execution plan by right click, ‘Save Execution Plan As’ and provide the location to save it.
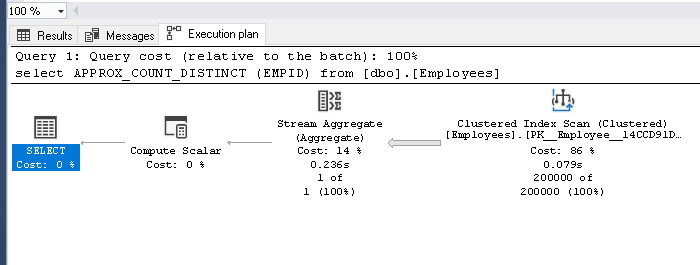
Now run the below query using the SQL Server 2019 function APPROX_COUNT_Distinct.
|
1 2 |
SET STATISTICS TIME ON select APPROX_COUNT_DISTINCT(EMPID) from [dbo].[Employees] |
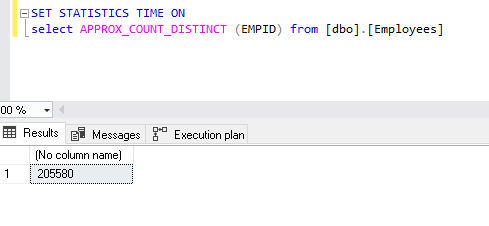
Notice the number of records. It says 205,580 records while our table only contains 2 million rows. It shows that we are not getting the exact count of distinct values, it is approximate.
Right click on execution plan and click ‘Compare Showplan’
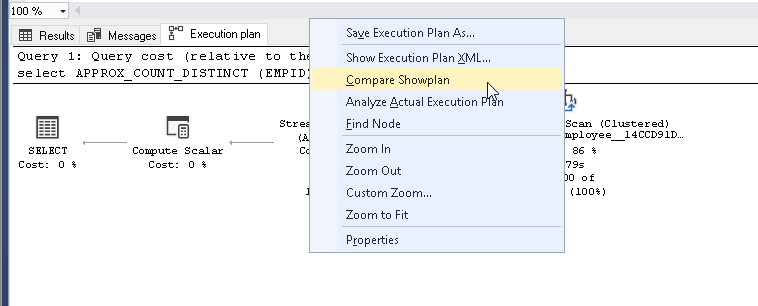
In Compare showplan provide the previously saved execution plan path
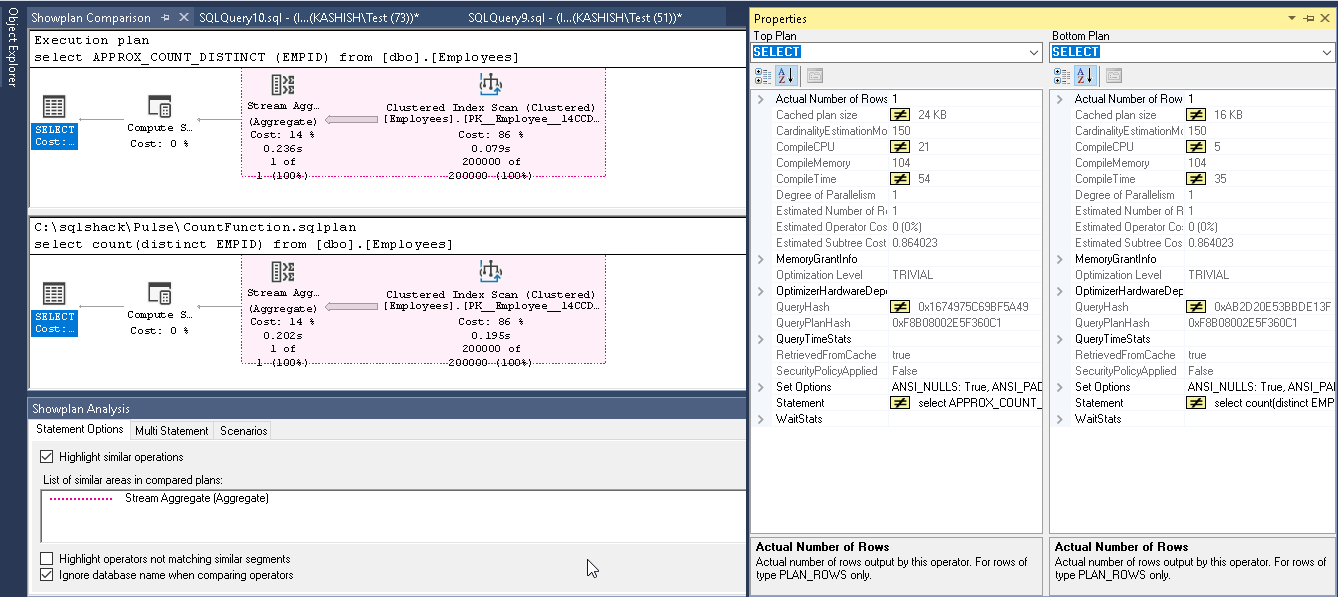
Now we can see a comparison of both Count (Distinct) and Approx_Count_distinct. Both the execution plan looks the same. In Approx_Count_distinct, we can see small improvement of clustered index scan time 0.079 seconds compared with 0.195 seconds using count (distinct)
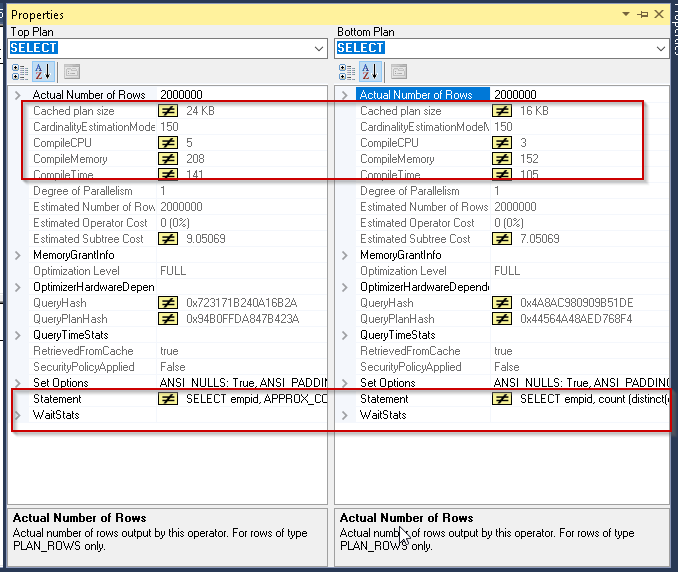
Now, if we compare the select operator in both the execution plan, in my result set below, we see little bit high values in the Approx_count_distinct function. For example, cache plan size, compileCPU, Compilememory, compile-time is high when we use the new function.
Let us perform the same test on our table with Null values.

We can see the below result in execution plan comparison report.
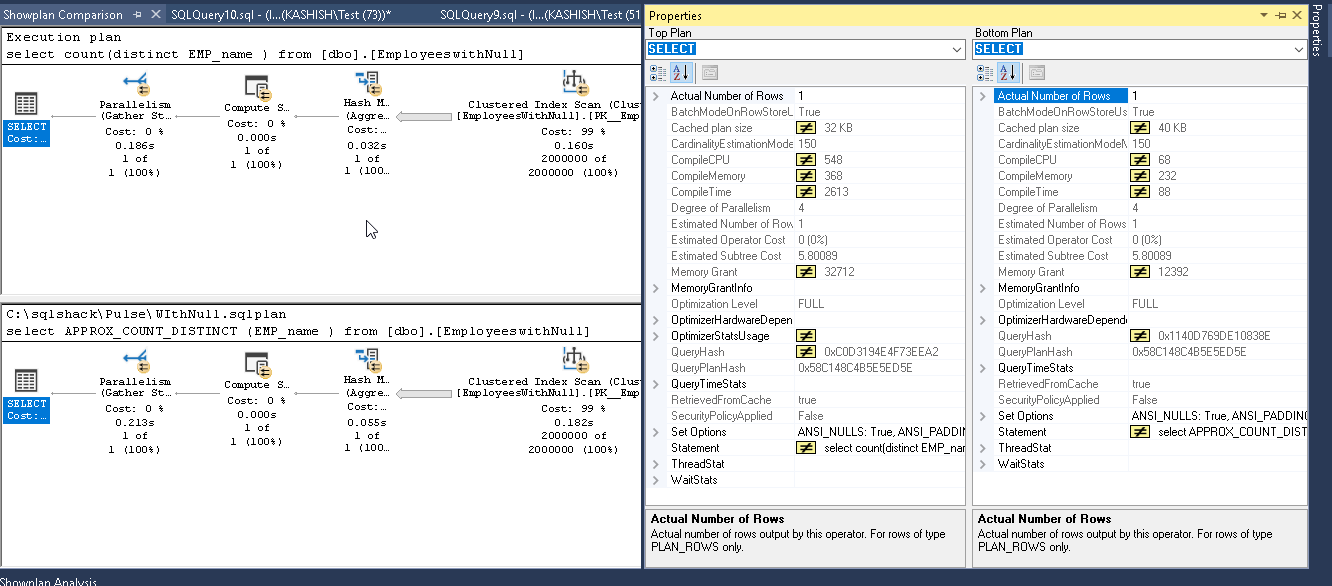
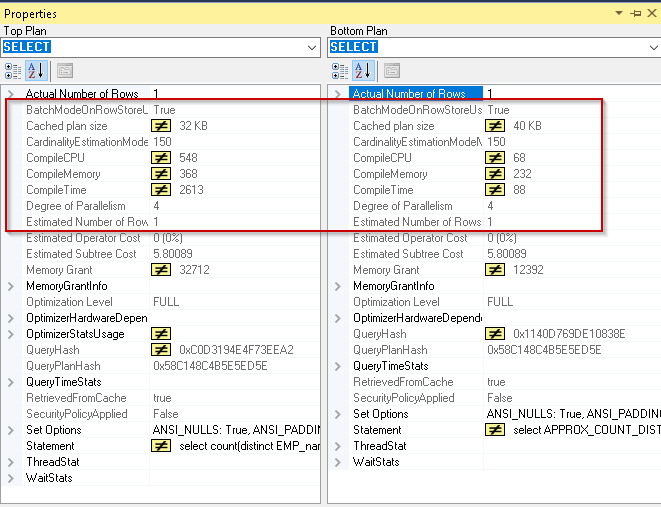
Rows count are again high as compare to the count distinct function.

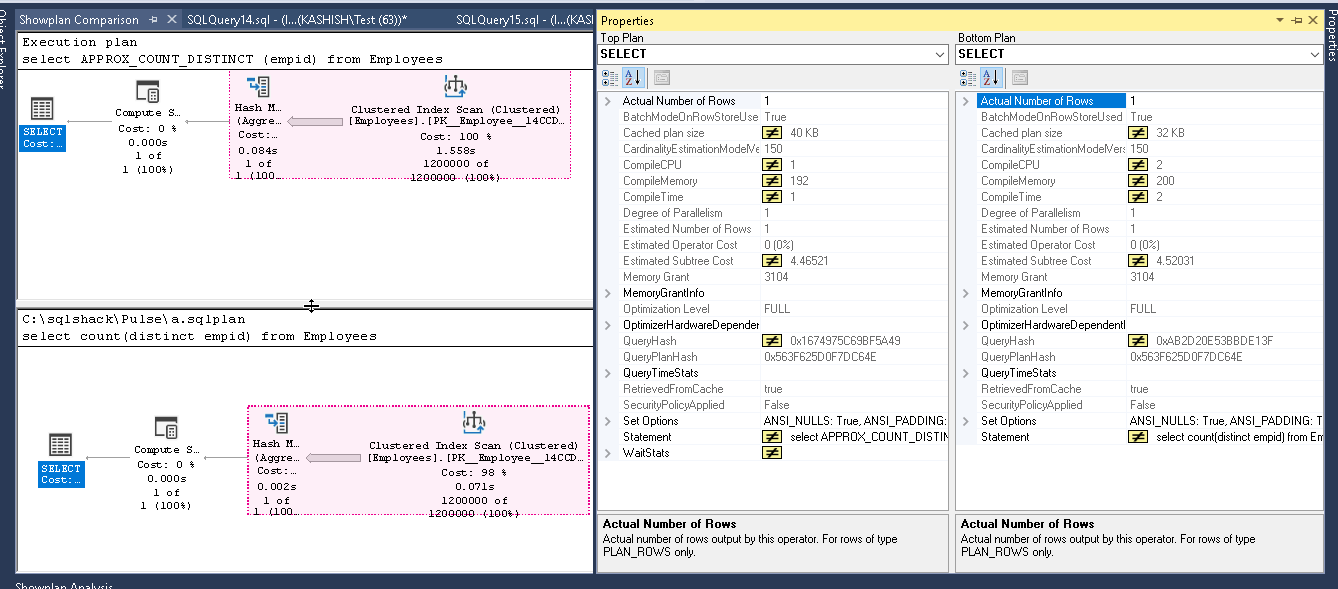
Let us insert more records into both the table and refresh our data.
If we compare both the execution plan now, we can see little performance improvement while using the APPROX_COUNT_DISTINCT function.

Let us do one more test against the sample database WideWorldImporters. Here in the comparison report, we found fewer values for CompileCPU, CompileMemory, and CompileTime while using the Approx_Count_distinct as compared with count distinct.
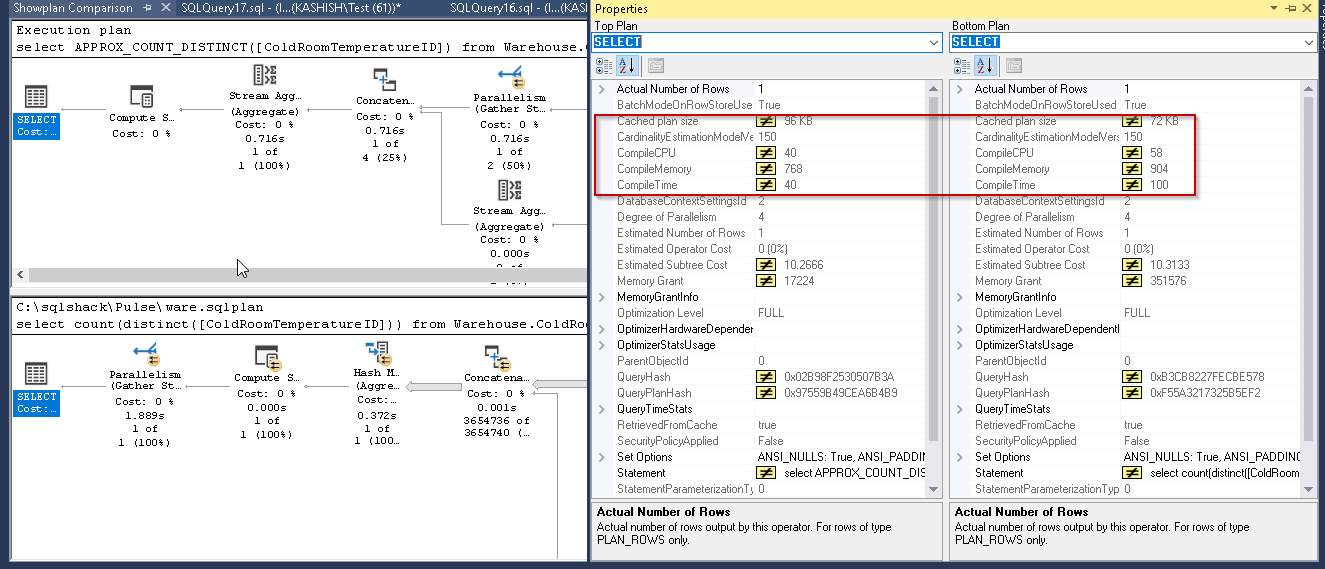
You can see the difference in row count in both the methods. Most of the time in my demo, I saw high row counts with new function however here we can see lower value than the actual but that is 0.34% approximate than the actual.
Let us start the default extended event session ‘standard’ before running both the queries to capture the live trace of performance. Expand the XEvent profiler from SQL Server Management Studio and launch session.
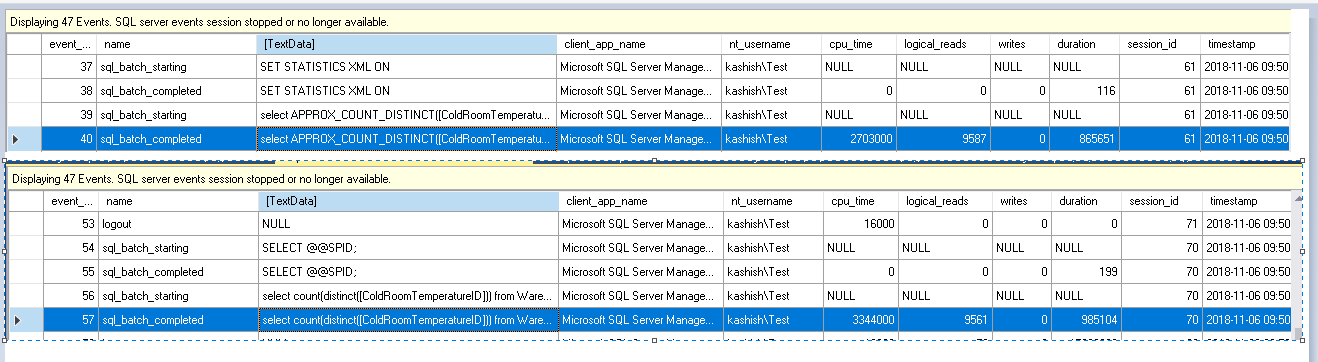
This captures the logical reads, CPU time, writes, duration.
We can notice that values are lower while using the Approx_count_distinct as compare with the count distinct function.
Conclusion
We explore the new functionality of getting an approximate count of distinct nonnull values in SQL Server 2019. During my test, I got mixed results in terms of performance however you can try running in more complex data scenario. Feel free to leave any feedback or questions in the comments below.

I am the author of the book "DP-300 Administering Relational Database on Microsoft Azure". I published more than 650 technical articles on MSSQLTips, SQLShack, Quest, CodingSight, and SeveralNines.
I am the creator of one of the biggest free online collections of articles on a single topic, with his 50-part series on SQL Server Always On Availability Groups.
Based on my contribution to the SQL Server community, I have been recognized as the prestigious Best Author of the Year continuously in 2019, 2020, and 2021 (2nd Rank) at SQLShack and the MSSQLTIPS champions award in 2020.
Personal Blog: https://www.dbblogger.com
I am always interested in new challenges so if you need consulting help, reach me at rajendra.gupta16@gmail.com
View all posts by Rajendra Gupta
- Understanding PostgreSQL SUBSTRING function - September 21, 2024
- How to install PostgreSQL on Ubuntu - July 13, 2023
- How to use the CROSSTAB function in PostgreSQL - February 17, 2023