
In this article, I am going to explain what Data Lineage in ETL is and how to implement the same. In this modern world, where companies are dealing with a humongous amount of data every day, there also lies a challenge to efficiently manage and monitor this data. There are systems that generate data every second and are being processed to a final reporting or monitoring tool for analysis. In order to process this data, we use a variety of ETL tools, which in turn makes the data transformation possible in a managed way.
While transforming the data in the ETL pipeline, it has to go through multiple steps of transformations in order to achieve the final result. For example, when the ETL receives the raw data from the source, there may be operations applied to it like filtering, sorting, merging, or splitting two columns, etc. There can also be aggregations or other calculations made on this raw data before finally moving into a data warehouse or preparing it for reporting. In order to be able to detect what the source of a particular record is, we need to implement something known as Data Lineage. It is a piece of simple metadata information that helps us detect gaps in the data processing pipeline and enables us to fix issues later.
Understanding Data Lineage
As it goes by the name, Data Lineage is a term that can be used for the following:
- It is used to identify the source of a single record in the data warehouse. This means there should be something unique in the records of the data warehouse, which will tell us about the source of the data and how it was transformed during the processing
- Simplify the process of moving data across multiple systems. When we move data across multiple systems for data processing, it might happen that a specific set of records were being missed out due to unknown reasons. In case we are not able to track down such missed records, it will lead us to incorrect figures being reported in the warehouse
- Makes the data movement process more transparent. Introducing a lineage key in the ETL process makes the documentation of the project a bit easier as we already know how the data has been transformed in order to come to a particular set
How to implement Data Lineage in practical
In my opinion, the process of implementing Data Lineage in an ETL process is very simple. We just have to identify a set of records for the first time, as it enters the ETL pipeline. Once the records are within the ETL pipeline, we can assign a key to those records, which will help us identify the source system and tell us from which data source the records are being imported. Other details can also be included, like batch information that tells us how many times the ETL process was being executed, etc. You can add much complex, detailed information in order to establish a correct lineage for tracking the records back.
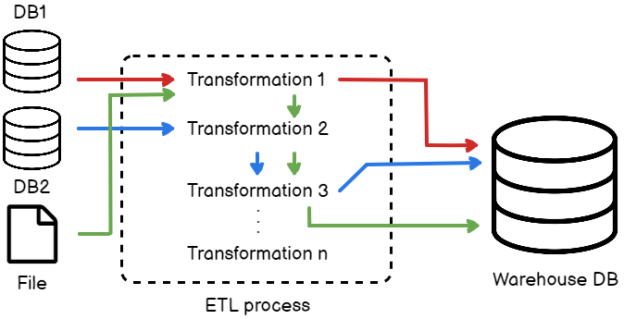
Figure 1 – ETL Process
Let us consider the above simple ETL process. As you can see, there are three sources from where data is generated – two databases and one file. Once the data is loaded into the ETL pipeline, there are a series of transformations that can be applied to the data as it moves. Finally, the data is being stored in the Warehouse database from where further reporting can be carried out.
Now, let us assume that all the data does not need to go through each of the transformations. For example, the data that comes from the DB1 only needs to go through “Transformation 1”; data from DB2 needs to go through “Transformation 2” and “Transformation 3” and data from the file needs to undergo each of the transformations. Finally, all the data from the databases and the file will be pushed into the warehouse for analysis.
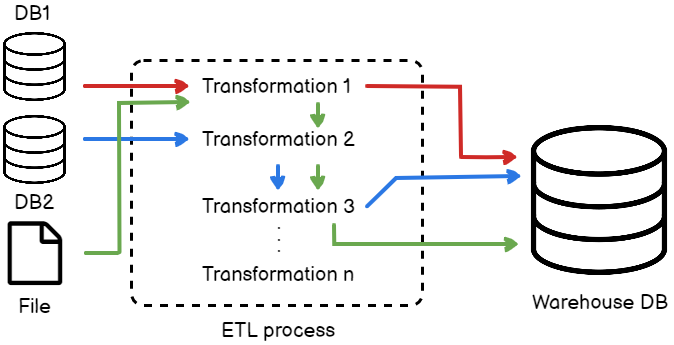
Figure 2 – Transformation flow diagram
If you see in the diagram above, I have marked the data flow from all the sources in separate colors. This flow is implemented, as mentioned in the article above.
In such a system, the data from the sources might be different from each other; however, in the final data warehouse, the format for storing all the data will be identical. In order to know from which source a particular record originated, we need to implement a “SourceSystemID” as the lineage key, which will ultimately enable us to track back to the source database when anything in the warehouse goes wrong. Along with that, we can also log another field, “TransformationID”, which can tell us about the specific transformations that each of the records has undergone in order to be loaded in the data warehouse. Finally, a “BatchID” can be appended to each of the records that will tell us about the execution details such as date and time of execution, duration of the run, etc.
While designing ETL processes, it is not always advised that there should be a key that should identify the lineage. If the ETL is a small process that does not involve many complexities like different data sources or various transformations, then adding the lineage information would be a possible overhead because it might not be very useful at a later point in time.
Implementing a simple Data Lineage example
Now that we have some idea what data lineage all about is, let us understand the same using some practical examples. Let me go ahead and create two files, “Employee1.csv” and “Employee2.csv”. These are simple CSV files that contain information about employees and their departments. The structure of both the files are kept identical; however, this also holds true in case both the files have different structures. In order to keep things simple, I will simply insert the name of the source file name into the database as the SourceSystemID.
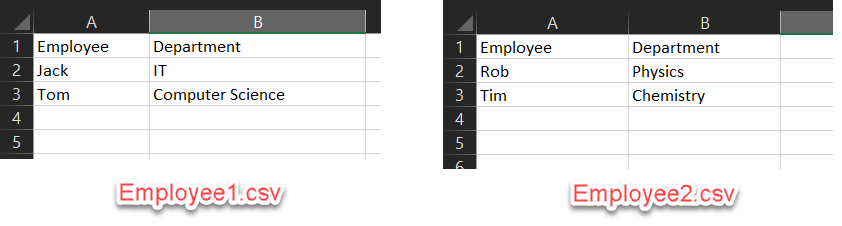
Figure 3 – CSV Files
As you can see in the figure above, I have created two different files and inserted records in those as well. Now let us create a table in the SQL Server database, which will act as the data warehouse. Additionally, we will also add a column “SourceSystemID” in which we are going to populate the name of the file from which the record is being fetched. In place of the filename, it is also possible to assign an integer value, which will insert an ID representing the name of the source of the record.
While designing the ETL process for implementing Data Lineage, you need to add a Derived Column transformation in your Data Flow Task. In this Derived Column, you can add what data you would like to insert for this new SourceSystemID.
This above scenario would like the below on the SSIS package:
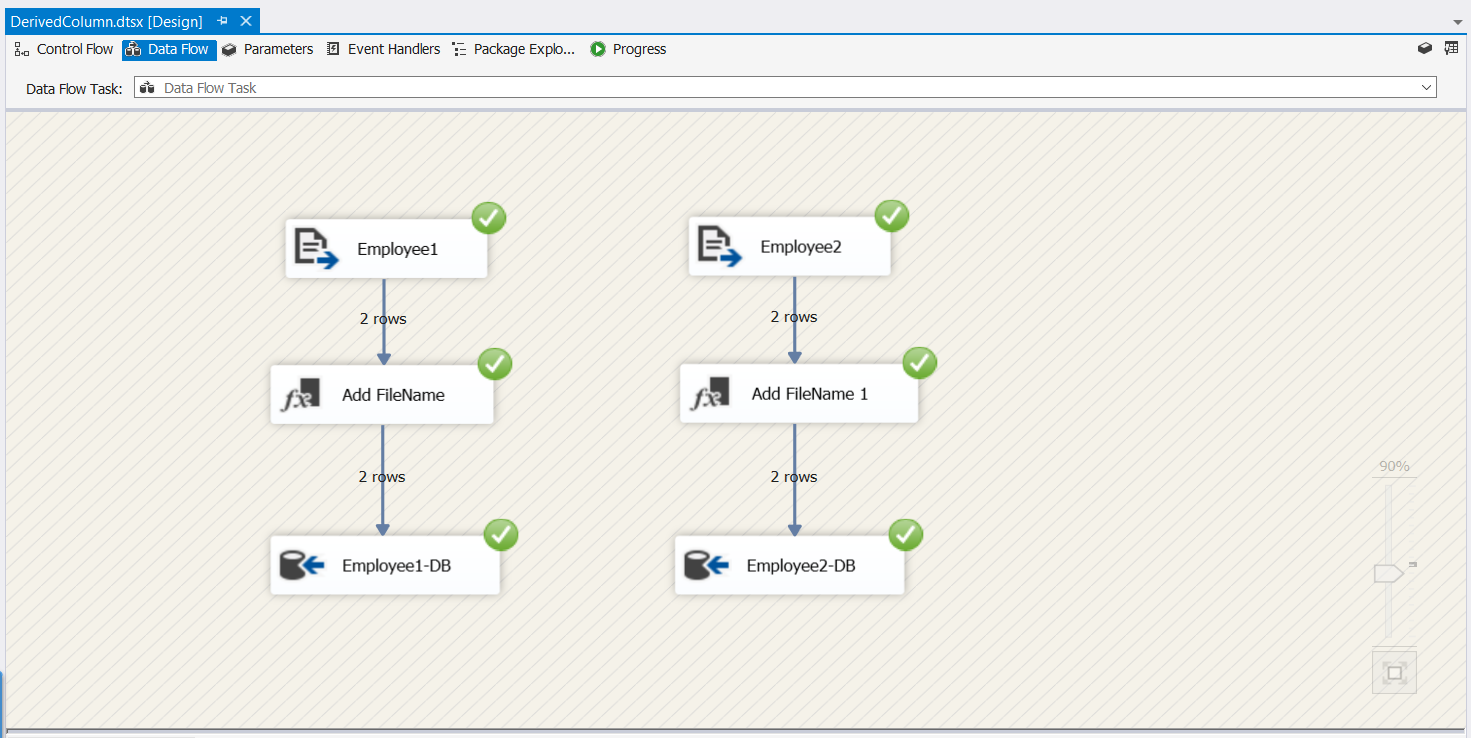
Figure 4 – SSIS Package Data Flow
Since I plan to cover a complex data lineage pipeline in SSIS packages in my next article, designing the SSIS package to show the entire flow is out of scope for this tutorial. You can check out An introduction to SSIS Data Lineage concepts article to know more about this.
You can refer to the following image to have an understanding of how the final dataset will look like in the database.
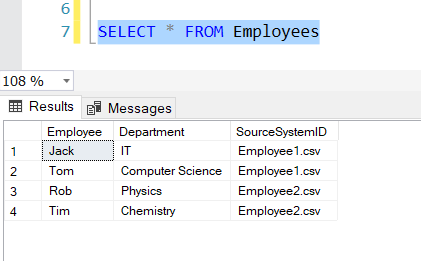
Figure 5 – SourceSystemID added to the database
As you can see in the figure above, by looking at the database table, we now have an idea from which source did the records originate actually, and this is helpful while tracking back with data quality issues. This is how we can implement Data Lineage in our ETL packages.
Conclusion
In this article, we have understood the theory behind implementing data lineage in an ETL process. Usually, the ETL tools do not have any out of the box tool to implement the lineage directly. However, customizations can be made in order to create an automated data pipeline, which includes the lineage right from the beginning while the data is being imported into the process. This lineage information can then be used during the entire session of the data processing as the transformations occur and finally stored in the data warehouse. This lineage information can be useful later if required to track back the sources from the transformed data. In my next article, I will try to explain in more detail how to create an SSIS package and implement a complex Data Lineage pipeline with it.

He is a prolific author, with over 100 articles published on various technical blogs, including his own blog, and a frequent contributor to different technical forums.
In his leisure time, he enjoys amateur photography mostly street imagery and still life. Some glimpses of his work can be found on Instagram. You can also find him on LinkedIn
View all posts by Aveek Das
- Getting started with PostgreSQL on Docker - August 12, 2022
- Getting started with Spatial Data in PostgreSQL - January 13, 2022
- An overview of Power BI Incremental Refresh - December 6, 2021