
This article explains both the SSIS term extraction and term lookup components. Besides, it illustrates the use cases of each one of them.
This article is the eighteenth of the SSIS features face-to-face series that aims to compare similar SSIS components in order to remove any confusion for the data integration developers that use this technology.
Introduction
While structured data is essential, unstructured data such as plain texts, tweets, and social media posts are even more valuable to businesses if analyzed correctly. It can provide a wealth of insights that statistics and numbers just can’t explain. One of the most popular analyzing techniques is “Text mining” or “Text Analytics”.
Text mining transforms unstructured text into a structured format to identify meaningful patterns and new insights. Nowadays, text analytics is still a hot topic where intelligent algorithms and natural language processing models are being involved and improved continuously.
In SQL Server Integration Services (SSIS), two components are developed to help users extract useful information from texts: SSIS term extraction and SSIS term lookup components.
To illustrate those components, we will be analyzing the About section in the Stack Overflow users’ profiles. We will be using the Stack overflow 2013 database.
Figure 1 – The “About me” section in the Stack Overflow user profile
- Side Note: All examples in this article are made using SQL Server 2019, Visual Studio 2019, SQL Server Integration Services projects extension version 3.4.
SSIS term extraction
As described in the SSIS toolbox, the term extraction component extracts frequently used English-only terms from an input data flow. Terms and their corresponding score are written to output data columns.
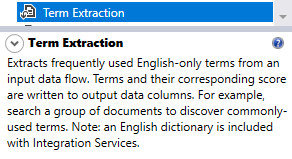
Figure 2 – SSIS term extraction description in the Visual Studio toolbox
As mentioned in the official documentation, the term extraction process is done :
- Words identification: Removing unnecessary characters and symbols from words
- Tagging words: Separating nouns, verbs, numbers, adjectives…
- Words Stemming: The SSIS Term Extraction transformation stems from nouns to extract only a noun’s singular form
- Normalization: The Term Extraction transformation normalizes terms that are capitalized only because of their position in a sentence and uses their non-capitalized form instead
- Case-Sensitive Normalization: The Term Extraction transformation can be configured to consider lowercase and uppercase words as distinct terms or variants of the same term
- Sentence and Word Boundaries: Separating text into sentences
The SSIS Text Extraction transformation uses internal algorithms and statistical models to generate its results.
To demonstrate how to use this component, we created an SSIS package. We defined two OLE DB connection managers; one for the Stack Overflow database and the other for the destination database. Then, we added a data flow task. In the data flow task, we added an OLE DB source, a term extraction component, and an OLE DB Destination.
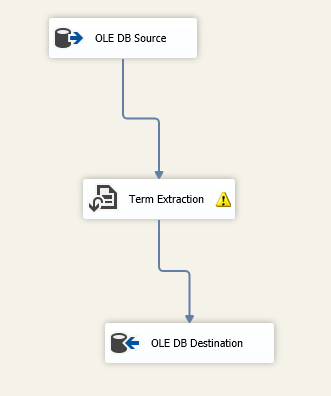
Figure 3 – Data flow task
The SSIS term extraction editor contains three configuration tabs: Term extraction, Exclusion, and Advanced.
In the term extraction tab page, we should select the column that contains the text to be analyzed. In addition, we should specify the names of the two output columns generated by the SSIS term extraction component:
- Term: The extracted terms column
- Score: The term score (Method is selected in the advanced tab page)
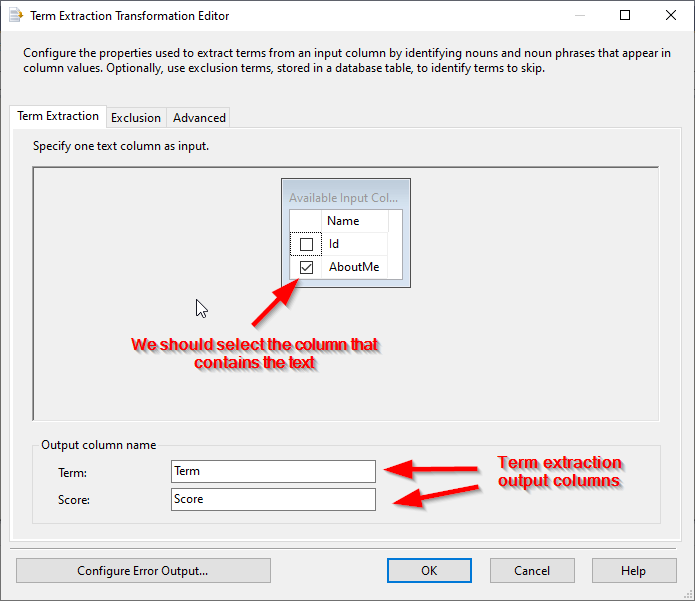
Figure 4 – Term extraction tab page
In the Exclusion tab page, we can select a table that contains a list of terms to be excluded in the component output. The SSIS term extraction component only supports OLE DB connection managers for exclusion tables.
Figure 5 – Exclusion tab page
The Advanced tab page contains several configurations:
- Term Type:
- Noun: Specify that the transformation extracts individual nouns only
- Noun phrase: Specify that the transformation extracts noun phrases only
- Noun and noun phrase: Specify that the transformation extracts both nouns and noun phrases
- Score Type:
- Frequency: Specify that the score is the frequency of the term
TFIDF: Specify that the score is the TF*IDF value of the term
The TFIDF score is the product of Term Frequency and Inverse Document Frequency. It is a numerical statistic intended to reflect how important a word is to a document in a collection
TFIDF of a Term T = (frequency of T) * log( (#rows in Input) / (#rows having T))
- Parameters:
- Frequency threshold: Specify the number of times a word or phrase must occur before extracting it
- Maximum length of term: Specify the maximum length of a phrase in words
- Options:
- Use case-sensitive term extraction: Specify whether to make the extraction case-sensitive
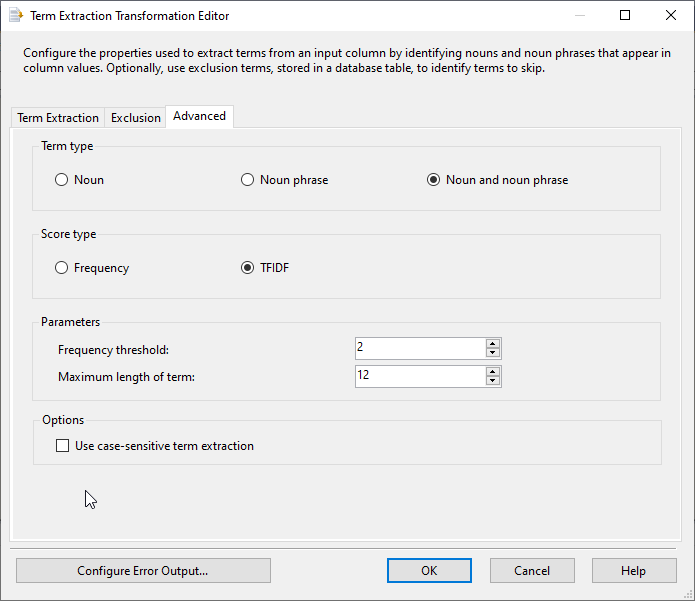
Figure 6 – Advanced tab page
After executing the package, we can check that 130345 terms were extracted from 2465713 users in the Stack Overflow 2013.
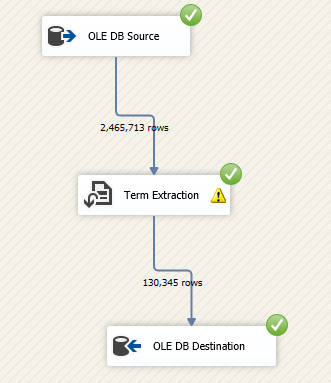
Figure 7 – Executed data flow task
Let us check what the frequency of some of the Job Titles is. We can do that using a simple SQL query:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
SELECT [Id] ,[Term] ,[Score] FROM [Test].[dbo].[Terms] WHERE [Term] IN ('Software Developer' ,'Data Engineer' ,'Data Scientist' ,'Software Tester' ,'Business Intelligence Developer' ,'BI Developer' ,'Data Architect') ORDER BY [Score] DESC |
For instance, we can check that 11917 users mentioned the word “Software Developer” term while Data Scientist is mentioned “624” time.
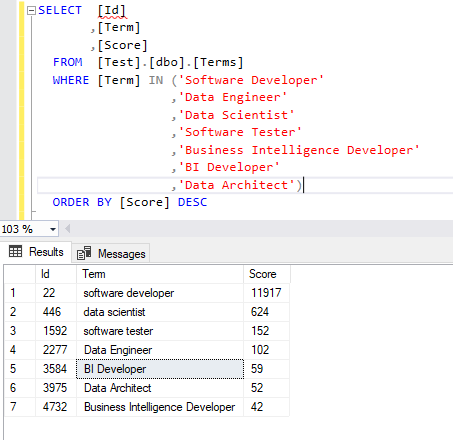
Figure 8 – Querying job titles in the destination table
For more information about the term extraction transformation, you can refer to the following SQL Shack article: Term Extraction Transformation in SSIS.
SSIS term lookup
As described in the SSIS toolbox, the term lookup determines how frequently specific terms occur in a data flow. This component is similar to the SSIS term extraction. The main difference is that the term lookup looks for the frequency of terms that matches a reference table within each text instead of extracting all terms from all texts provided.
Figure 9 – SSIS term lookup description in the SSIS toolbox
To demonstrate the SSIS term lookup, we created a reference table named “JobTitles”, where we inserted few job titles. In the data flow task, we replace the SSIS term extraction component with a term lookup.
There are also three configuration tab pages in the SSIS term lookup editor: Reference table, term lookup, and Advanced.
In the reference table tab page, we should specify the SQL table that contains the list of terms we are looking to use as a reference in our extraction process.
Figure 10 – Reference table tab page
In the term lookup tab page, we should select the columns we need to pass-through this transformation (keep them in the data pipeline). Besides, we should link the input columns with the lookup column (the one that contains the reference terms).
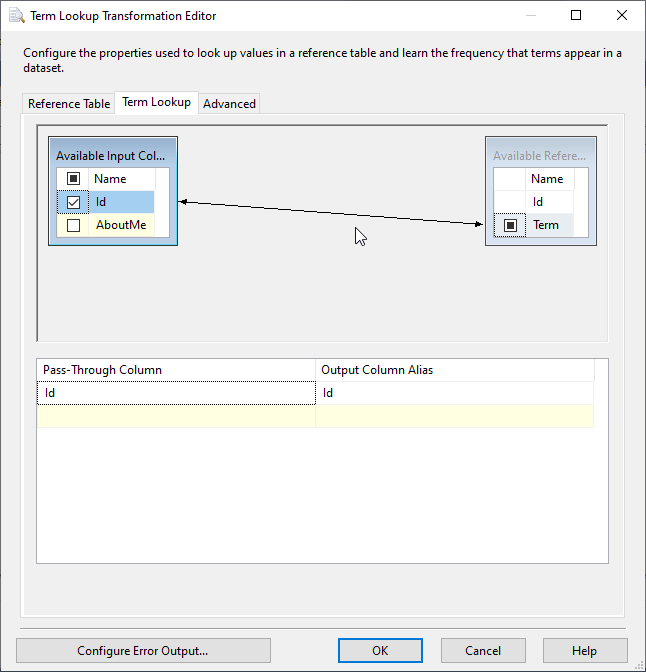
Figure 11 – Term lookup tab page
In the “Advanced” tab page, only enabling case-sensitive term extraction option is available.
Figure 12 – Advanced tab page
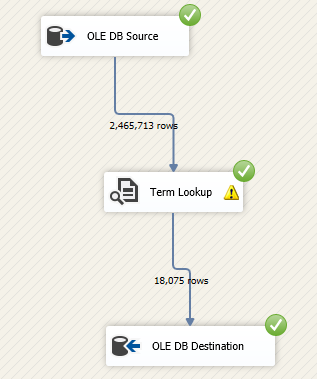
After configuring the SSIS term lookup transformation and setting up the destination component, let us execute the package. As we can see in the image below, 18075 rows were generated as output. The number of rows is smaller than the SSIS term extraction output since only the terms in the reference table are valid.
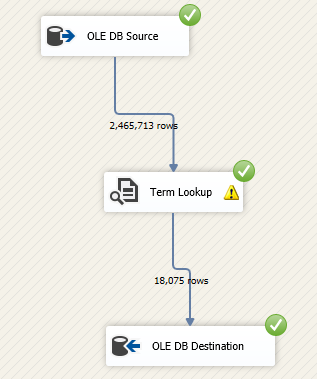
Figure 13 – Executed data flow
If we check the generated data, we can see that the score generated is per user. This means it shows how many times a specific term is found in each user’s “about me” section.
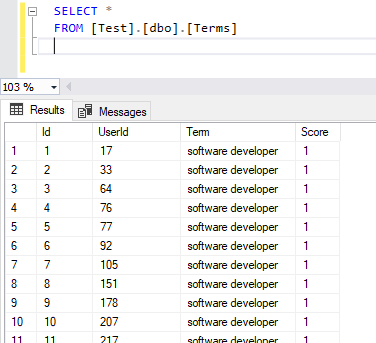
Figure 14 – Term lookup generated data
For example, if we check the highest score of a term, we can find that the term “Software developer” is mentioned 45 times by the user 2427022.
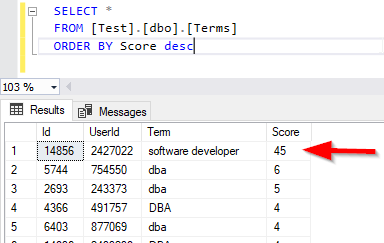
Figure 15 – Highest term score
It is not normal that we have a similar number of occurrences in a single about me section. Let us check what the original text stored by querying the “users” table is.
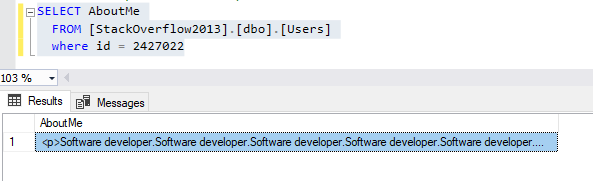
Figure 16 – Retrieving the “about me” column
As shown in the images, the user repeated the software developer term 45 times in his about me section. This means that if using the term extraction component, the frequency of the term may be affected by those strange cases, while the SSIS term lookup gives more insights.

Figure 17 – “About me” column content
Summary
In this article, we illustrated the difference between the SSIS term extraction and term lookup transformations.
At the end of this article, it is worth mentioning that we may have to run the term extraction transformation several times and examine the results to configure the component to generate the type of results that works for our text mining solution. Besides, term lookup may give us a much-detailed output in several cases, especially when having unexpected issues, as we mentioned in the article.
Table of contents

Besides working with SQL Server, he worked with different data technologies such as NoSQL databases, Hadoop, Apache Spark. He is a MongoDB, Neo4j, and ArangoDB certified professional.
On the academic level, Hadi holds two master's degrees in computer science and business computing. Currently, he is a Ph.D. candidate in data science focusing on Big Data quality assessment techniques.
Hadi really enjoys learning new things everyday and sharing his knowledge. You can reach him on his personal website.
View all posts by Hadi Fadlallah
- An overview of SQL Server monitoring tools - December 12, 2023
- Different methods for monitoring MongoDB databases - June 14, 2023
- Learn SQL: Insert multiple rows commands - March 6, 2023