
Introduction
This article describes how to improve the ETL Process in SQL Server by using the native replication technique in SQL Server.
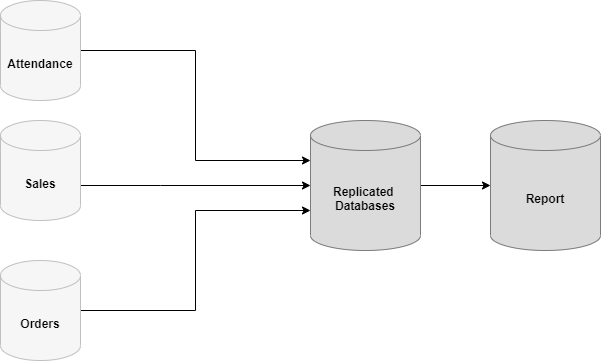
In an enterprise environment, typically you will have multiple databases that span across multiple servers depending on the operational situations. For example, operations can be divided into databases such as Order, Sales and Attendance. Since operational data is distributed in these databases, for reporting purposes we may have to bring this data to a single database with many transformations as shown in the below figure.
Challenges
As we know, reporting database has structural changes from the operational databases. Reporting database may follow the de-normalized structure to improve read performance as the Report database may not have many writes. Apart from the de-normalized structures, the Report database may have aggregated data to improve the performance of the report database. This means that transformation cannot be avoided in the Report database.
Typically, this transform is done using Extract-Transform-Load or ETL. However, if the ETL is directly performed on the operational system, there can be performance issues on the operational databases. Since ETL is applied on the large volume of data in a batch, row and tables locks will be placed and that will create performance issues to the operational databases.
If the report database is directly dependent on the operational databases, if there are any changes to the operational databases, reporting databases should be changed. For example, there can be instances where the database may need to move to new database servers or existing database servers.
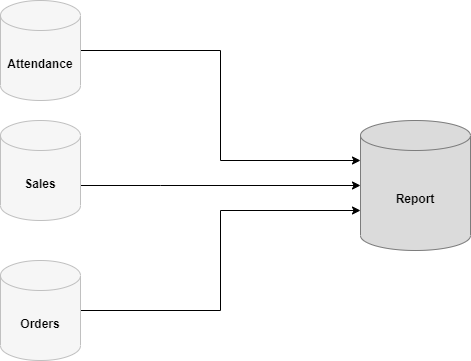
In order to avoid these issues, Replication is used to Improve the ETL process in SQL Server as shown in the following figure.
However, this replication has to be configured with special configurations to improve the ETL Process in SQL Server.
Replication Configuration
First of all, the replication tends to have a large load and will increase the load in the future. To facilitate the large scale, it is recommended to keep the separate distributor for the replication.
As you are aware, there are three types of replication types in SQL Server that are snapshot replication, transactional replication, and merge replication. Out of these replication configurations, snapshot replication is out. Merge replication will add triggers and GUID columns to the tables and will not be a popular choice to improve the ETL process in SQL Server. However, transactional replication needs a primary key for the table. In case you have tables without a primary key, you will not be able to use those tables. It is important to note that though transactional replication is using the database log, you do not need to configure the database to a full recovery model. However, if there are any issues with the replication, the database log will grow. Therefore, special monitoring should be done replication and should be fixed any issue in the replication to stop the growth of the database log.
Configuring Publications
As you know, SQL Server replication follows the publisher-subscriber method. You need to publish the articles (Tables) from the operational databases while there will be a subscription to the created publications from the replication database.
Let us create the publication from operational databases. As we know, replication is created database wise. Therefore, we need a minimum of one replication per database. This publication is simple as shown in the below screen.
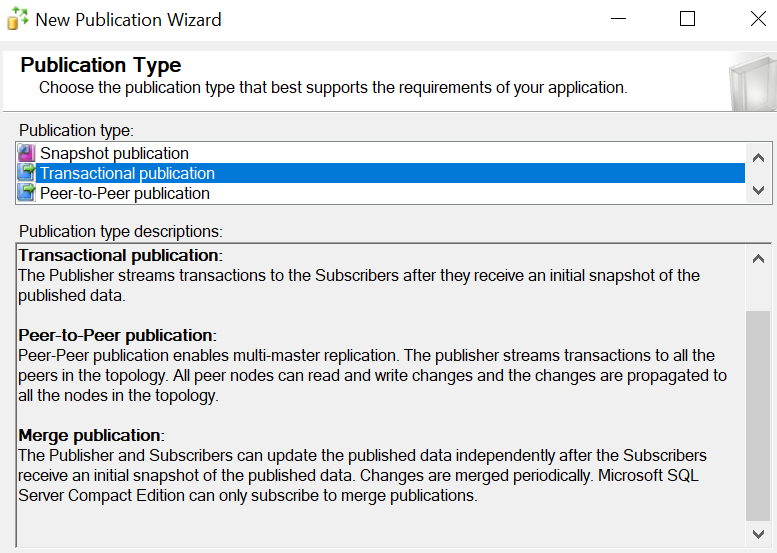
In this publication, we will select the tables that are required to publish to improve the ETL process in SQL Server.
After the standard publication is created, we need to change a few properties of the published articles from the following screen after choosing the properties of the publication.
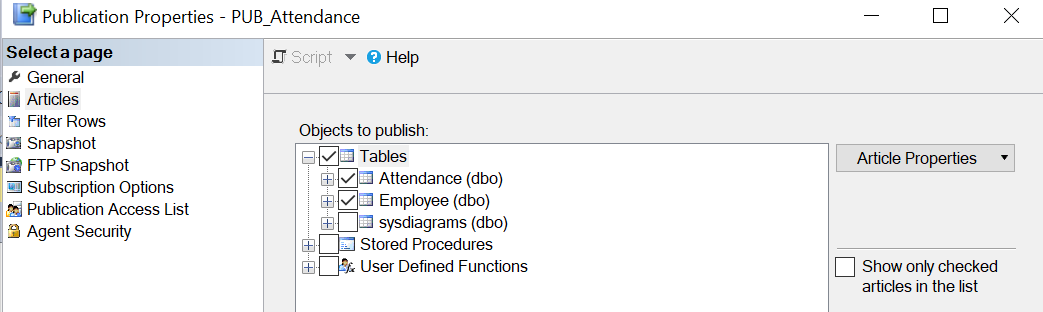
Important two configurations that have to be changed are shown in the following screen.
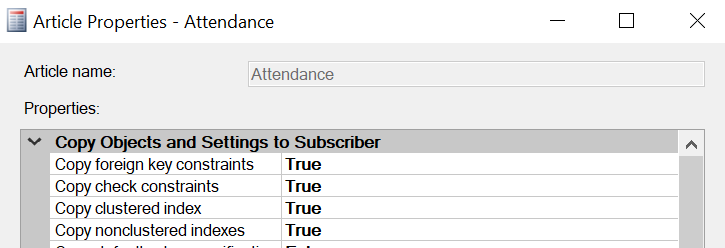
We need to apply the same indexes to the replication databases. If the same indexes were not applied to the replication database, during the data replication there will be performance issues. This configuration is not only relevant to this case but also general to all the replication configurations.
Next is an important configuration that is relevant to this configuration. As we are replicating tables in multiple databases to one database, there can be a situation where the same table name may exist in multiple databases. For example, the Employee table may consist of all three databases, Attendance, Sales and Orders. Since table names cannot be duplicated, we need to make the table name unique. One of the easiest options is to add the database name to the destination table. For example, the Employee table in the Orders table can be configured as Orders_Employee while the Employee table in the Attendance table can be configured to Attendance_Employee as the destination. This configuration is shown below.
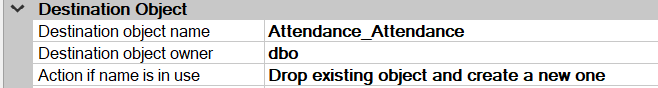
This configuration needs to be carried out for all the articles in all the publications individually to improve the ETL process in SQL Server.
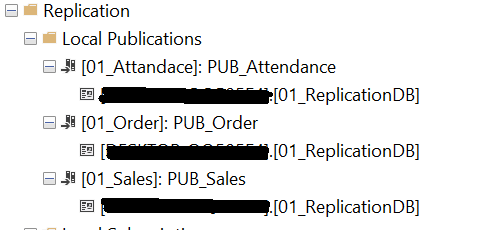
After the publications are configured, you will see the publications are below.

In case you have operational databases in multiple database servers, you will see the publications in the relevant database server.
Subscription
Next is to create a subscription that will replicate data to the replication database to improve the ETL process in SQL Server. This is a standard subscription creation as you will see in the typical replication setup.
After the subscriptions are created you will see your configuration as below. Please note that the SQL Server name is hidden for security reasons.
Further, since you are using this configuration for ETL, the subscription schedule may be defined for different time schedules. In the case of a typical subscription, we would like to have continuous replication which can be modified in this scenario.
Once the replications are in place you will see that the following tables are created in the Publication Database.

You can see that the tables are created with the prefix of the database name so that the unique name of the table name is maintained.
Let us look at how indexes are created for the Employee table. In every database, there is an Employee table, and each has the Primary Key named PK_Employee for the EmployeeID column and two databases have a Unique index for NIC number.
Let us see how they were created in the replicated table.
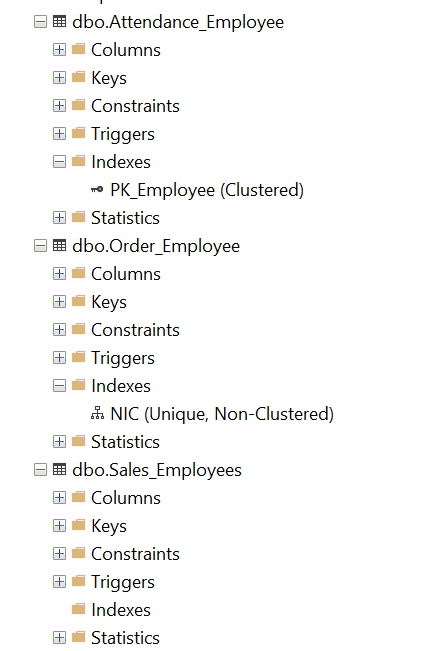
You can see that only one instance of primary key and unique index is created in the replicated database. As you know, Primary Key and Unique Key are constraints, and they should have a unique name. This means PK_Employee can have the only instance and it is the same for Unique constraints.
You have two options. The first option is to let the operational database maintain the unique constraint. However, this is not practical, as operational databases are developed in isolation and they may lack communication between the teams. Therefore, most of the time, this has to be covered from the replication side which will be the second option that we have. After the replication is created, we need to verify whether all constraints are applied and if not, we need to apply these constraints annually to improve ETL Process in SQL Server.
Since all the tables are now in one database, it is much easier to write ETLs from the Replicated database, without impacting any operations of the operational databases.
How the issues were resolved
Now let us look back and see how this has resulted to Improve ETL Process in SQL Server.
- Since replication is an asynchronous process, it will not impact the operational databases. Since for ETL process in SQL Server does not need continuous replication, you can schedule to have minimum impact on the system during the peak time
- When databases are needed to move from one instance to another or a new database server, it is only a matter of changing the publication by the DBA team. No changes need to be done to the ETL
Due to these two reasons, you can see that Replication can be used to improve the ETL process in SQL Server.
Conclusion
We looked at utilizing replication to improve the ETL process in SQL Server. This method has eased the load on the operating system due to the asynchronous nature of the replication method. In this method, we have made the replicated table to be unique and we need to make sure that the constraints in the destination tables are also unique.

View all posts by Dinesh Asanka
- Testing Type 2 Slowly Changing Dimensions in a Data Warehouse - May 30, 2022
- Incremental Data Extraction for ETL using Database Snapshots - January 10, 2022
- Use Replication to improve the ETL process in SQL Server - November 4, 2021