
This article explains the SSIS pivot transformation and how it differs from the unpivot transformation.
This article is the thirteenth article in the SSIS feature face-to-face series, which aims to remove confusion and to illustrate some of the differences between similar features provided by SQL Server Integration Services (SSIS).
Introduction
In general, the word “Pivot” means a shaft or a pin on which something turns. In the world of data, pivoting data is a data processing technique that is used to reshape tabular data by converting rows into columns. Pivoting is generally used for data analysis and visualization. Unpivot is the reverse operation of pivot where the columns are converted to rows.
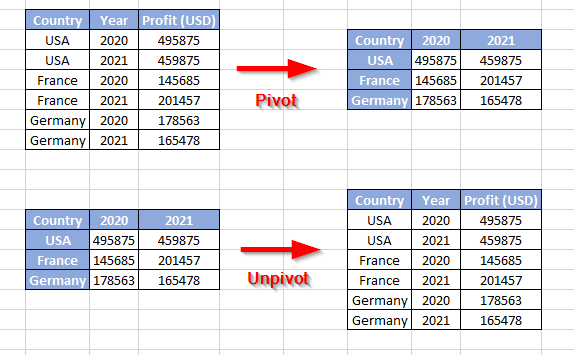
Figure 1 – Pivot vs. Unpivot operations
In SQL Server, there are two built-in relational operators called Pivot and Unpivot that can be used to perform the pivoting and unpivoting operations over relational data. Since these two operations are needed sometimes in the data import phase, two transformations are developed in the SQL Server Integration Services. The following sections will explain the SSIS pivot transformation and the SSIS unpivot transformation and how to use them during the data import phase.
- Side Note: All examples in this article are made using the Stack overflow 2013 database, SQL Server 2019, Visual Studio 2019, SQL Server Integration Services projects extension version 3.4.
SSIS pivot transformation
As described in the Visual Studio toolbox, the SSIS pivot transformation “Compacts an input data flow by pivoting it on a column value, making it less normalized.” Besides, two essential requirements are mentioned:
- “The input data should be sorted by the pivot column because a pivot happens each time data in the pivot column changes.” This note means that if the data is not sorted, this may cause meaningless changes in the component output metadata, leading it to failure
- “Duplicate Rows will cause this transformation to fail.” Since duplicate columns’ will be generated in the component output
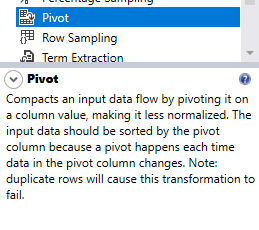
Figure 2 – Pivot transformation description in the SSIS toolbox
Let us consider the following query that returns the number of earned badges per year:
|
1 2 3 4 5 6 |
SELECT [Name] ,YEAR([Date]) as Earned_year ,COUNT([UserId]) as Time_Earned FROM [StackOverflow2013].[dbo].[Badges] GROUP BY [Name],YEAR([Date]) ORDER BY [Name], Earned_year |
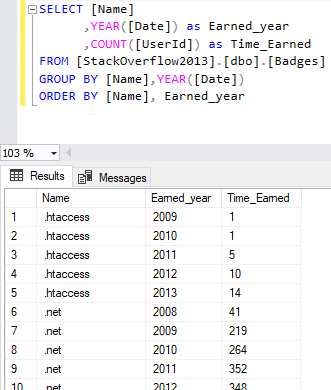
Figure 3 – Earned badges per year
To explain the SSIS pivot transformation, we (1) create an Integration Services project, (2) added a package, (3) created an OLE DB connection manager to configure the connection to the Stack Overflow 2013 database.
Within the package control flow, we add a Data Flow Task. As shown in the image below, we added an OLE DB Source and configured it to read from the SQL command mentioned above.
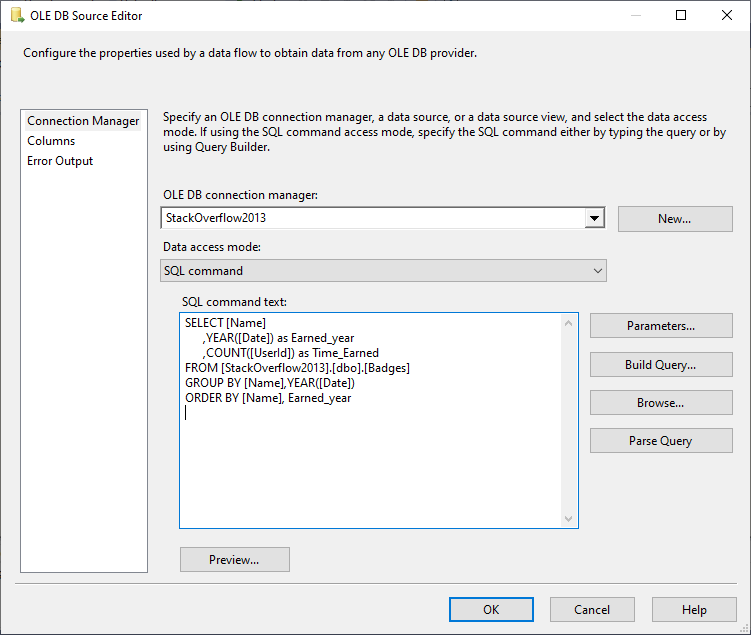
Figure 4 – OLE DB Source configuration
Now, let us add a pivot transformation that takes the OLE DB Source output as an input. In the SSIS Pivot transformation editor, we need to select the following columns:
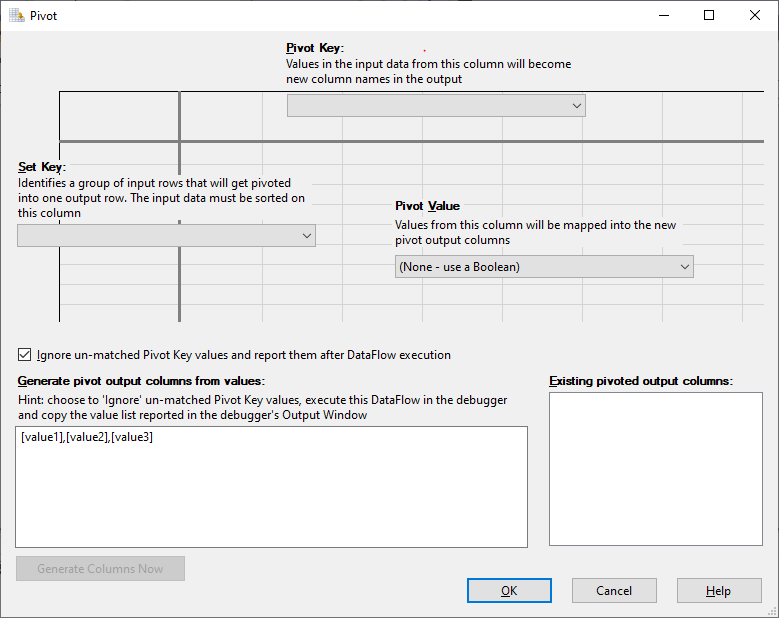
Figure 5 – Pivot transformation editor
- Pivot Key: Values in the input data from this column will become the new column names in the output. In this example, we should select the “Earned_Year” column
- Set Key: Identifies a group of input rows that will get pivoted into one output row
- Pivot Value: Values from this column will be mapped into the new pivot output columns
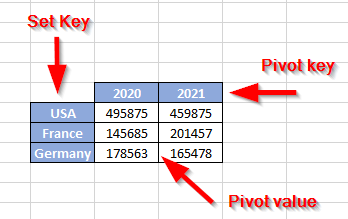
Figure 6 – Pivot columns explanation
Since SSIS component metadata needs to be defined before execution, the pivot key columns should be defined. If we already know the values in the data, we should write them within the values textbox and click on the “Generate columns now” button as shown below.
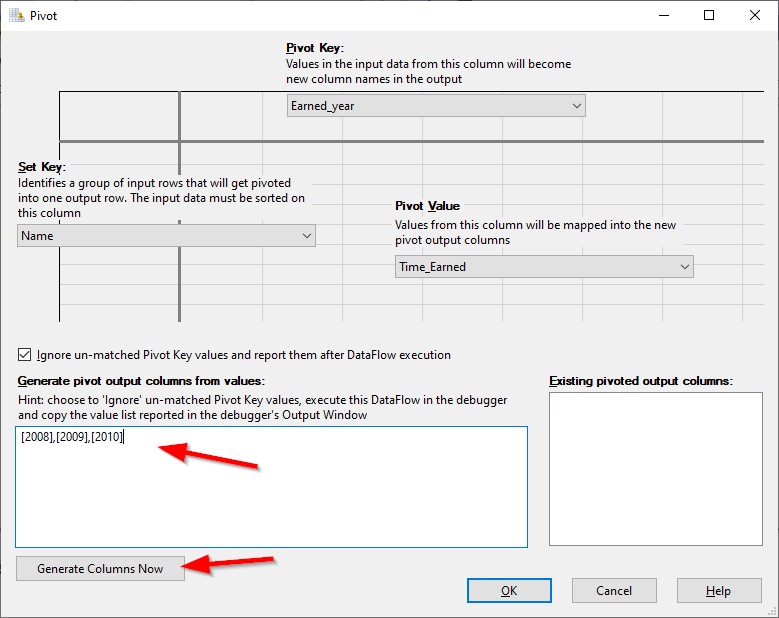
Figure 7 – Generate output columns
If we don’t know all values found in the data, we should check the “Ignore un-matched Pivot Key values and report them after DataFlow execution” option. Execute the DataFlow in the debugger, and copy the value list reported in the debugger’s output Window (this is mentioned as a hint in the SSIS pivot transformation editor).
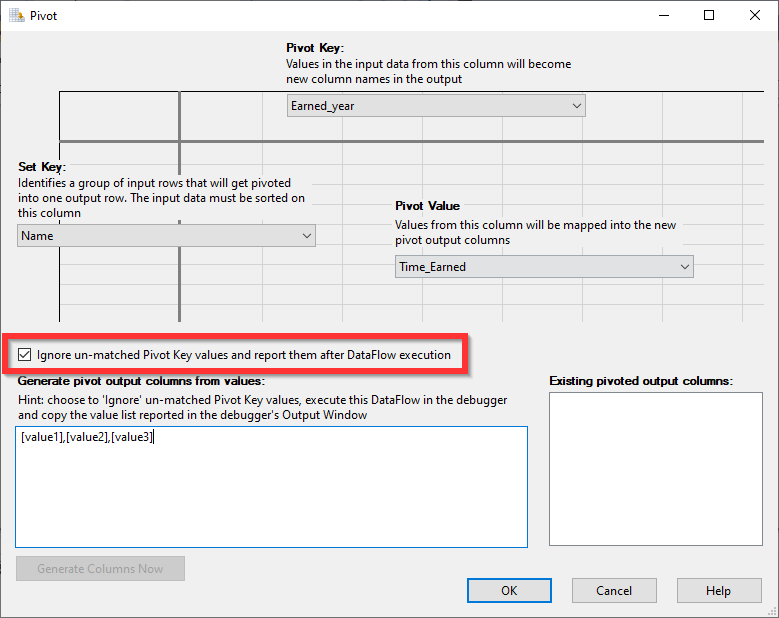
Figure 8 – Ignore un-matched Pivot key option
To execute the Data Flow task, go to the package control flow, press right-click on the Data Flow task, and click on “Execute Task”.
Figure 9 – Executing the Data Flow Task
After execution is finished, go to the Progress tab and check the SSIS pivot transformation output as shown in the image below.
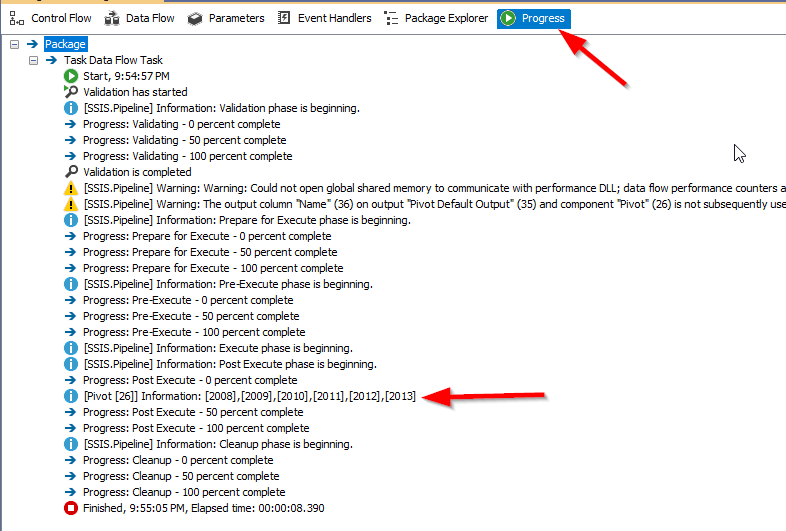
Figure 10 – Reading the pivot transformation output
You can copy this output by pressing right-click on the message and click on “Copy message text”.

Figure 11 – Copy the pivot transformation output
We should paste only the column names into the output column text box and click on “Generate columns now”. We can check the added columns in the “Existing pivoted output columns” text box.
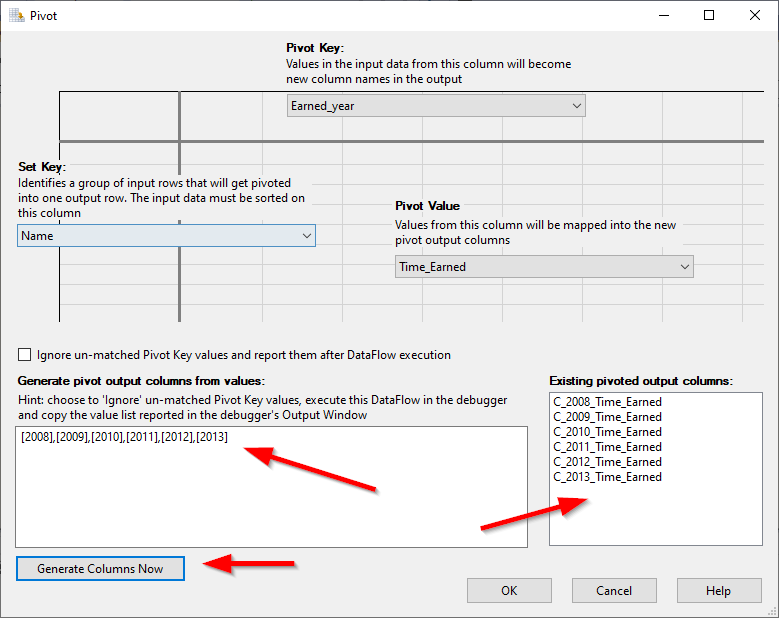
Figure 12 – Generating output columns
After configuring the SSIS pivot transformation, we will export the result into a Flat file (CSV). As shown in the image below, the number of rows is reduced to the number of distinct values found in the “Set Key” columns.
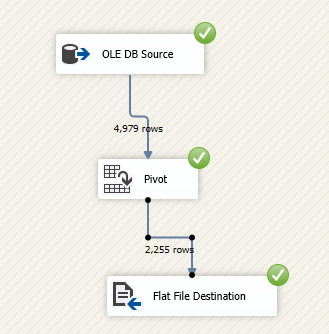
Figure 13 – Executed data flow task
If we open the created CSV file, we can check how the data is transformed to a pivot table.
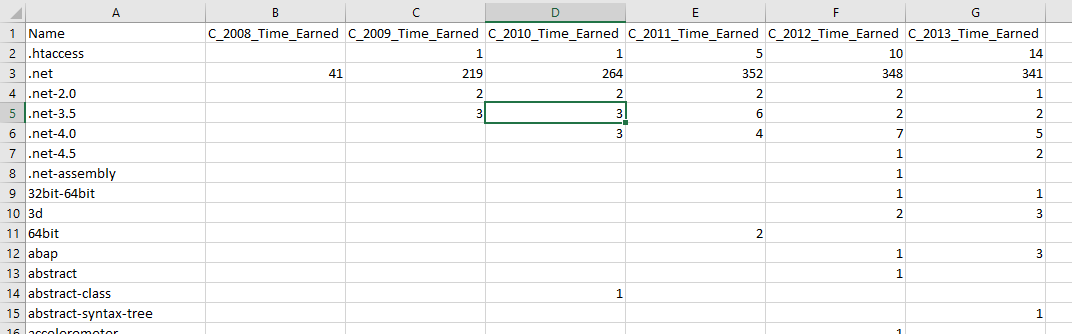
Figure 14 – Data sample from the exported csv file
SSIS unpivot transformation
As mentioned in the SSIS toolbox, the unpivot transformation “expands an un-normalized data flow into a more normalized version (Values from multiple columns of a single record expand to multiple records in a single column)”.
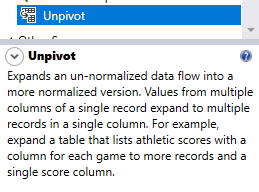
Figure 15 – Unpivot transformation description in the SSIS toolbox
To explain the SSIS unpivot transformation, we will add a new Data Flow task with a Flat File source that reads from the CSV file we created in the previous example. Then we will add an SSIS unpivot transformation component that takes the flat file source’s output as an input.
Now, let us open the SSIS unpivot transformation editor. As shown in the image below, we should configure this transformation as follows:
- We should check the “Pass through” option for the columns that do not need to be unpivoted
- We should check all columns that we need to unpivot
- In the columns grid, we should specify an output column name for each input column. In this example, we used “Times_Earned” as a column name since it was used in the initial SQL query we used
- We should specify the pivot value output column name where the values will be stored. In this example, we used “Earned_Year” as a column name since it was initially used in this article
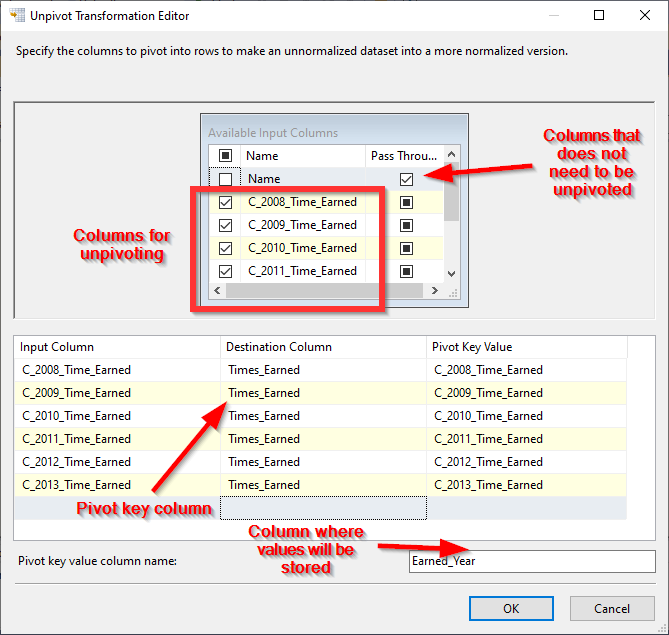
Figure 16 – SSIS unpivot transformation editor
After configuring the unpivot transformation, we add a Flat file destination to export the unpivoted data to another flat file (CSV). After executing the package, we should note that the unpivot transformation output rows count is higher than the input rows.
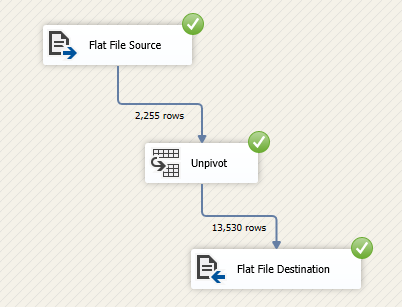
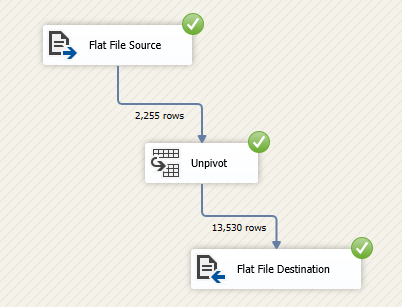
Figure 17 – Unpivot input and output rows count
If we open the created CSV file, we can check how pivoted data is transformed back to a normalized table.
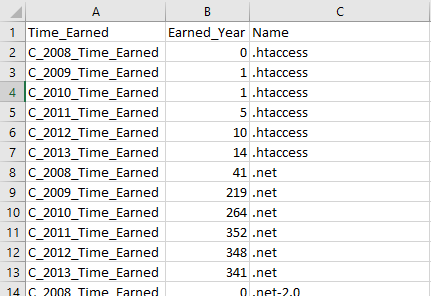
Figure 18 – Unpivoted data sample
- Important note: The output of the unpivot transformation is 13530 rows, while the SSIS pivot transformation input was 4979 rows. The reason for this difference is that the unpivot transformation generates a row for each pivot key, set key combination, while it may not exists in the initial data. For example, in the initial data, the “.htaccess” name does not have a row for the 2008 year while it has in the unpivot output while a value equal to 0. The unpivot transformation output rows count = the number of set key values x the number of pivot columns. In this example: 13530 (output rows) = 2255 (Name distinct values) x 6 (Earned year values)
- An overview of SQL Server monitoring tools - December 12, 2023
- Different methods for monitoring MongoDB databases - June 14, 2023
- Learn SQL: Insert multiple rows commands - March 6, 2023
Summary
In this article, we briefly explained the pivot and the unpivot operations and why developers use them. Then, we explained the SSIS pivot transformation and how to configure it to convert normalized data into a pivot table. Finally, we explained the SSIS unpivot transformation and how to transform pivoted data into normalized data.
Table of contents

Besides working with SQL Server, he worked with different data technologies such as NoSQL databases, Hadoop, Apache Spark. He is a MongoDB, Neo4j, and ArangoDB certified professional.
On the academic level, Hadi holds two master's degrees in computer science and business computing. Currently, he is a Ph.D. candidate in data science focusing on Big Data quality assessment techniques.
Hadi really enjoys learning new things everyday and sharing his knowledge. You can reach him on his personal website.
View all posts by Hadi Fadlallah