
This article will explain how to use the SSIS lookup transformation and how it differs from the fuzzy lookup. This is a continuation of the SSIS features face-to-face series that we published previously on this website.
Introduction
Lookups are one of the most popular data integration techniques. They can be considered indexed reference data needed while processing data sets. Besides, these tables are used primarily for data standardization, enrichment, or cleaning operations.
In SQL Server Integration Services (SSIS), two types of lookups transformations can be performed; normal and fuzzy lookups. Both transformations are available within data flow tasks. This article explains both SSIS lookup transformations and when to use each one of them.
Lookup transformations
As defined in the Microsoft Visual Studio SSIS toolbox, the Lookup component is used to “join additional columns to the data flow by looking up values in a table”. This component uses equality join to integrate the main data with the lookup table.
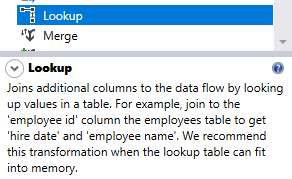
Figure 1 – Lookup transformation description in the SSIS toolbox
In General, lookups are used in the data enrichment process like the example given in the SSIS toolbox description where the “employee id” column is used to join the main data flow with the lookup table in order to get the “hire date” and “employee name” columns. Besides, lookups are also used in the data standardization process, where the data identifier is retrieved based on one or many columns. As an example, while importing an employee list, the “employee name” and “hire date” columns are used to join an input data set with the lookup table to get the “employee id” column.
In SSIS, Lookup is a transformation component, which means that it needs an input data pipeline. To explain this component easily, we will do this using an example.
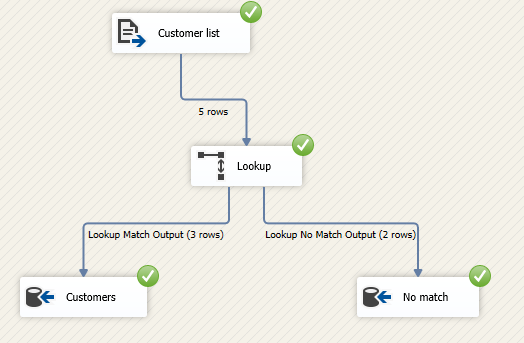
Assuming that we are importing a customer list stored as a CSV file into an SQL Server database. The customer list has the following fields: first_name (text), middle_name (text), last_name (text), dob (number), nationality (text). The customer table in the SQL Server database has the following columns: customer_id (integer – identity), first_name (varchar), middle_name (varchar), last_name (varchar), birth_date (integer), nationality (integer). The nationality column in the destination table is a foreign key with reference to the “countries” table containing the country name and identifier.
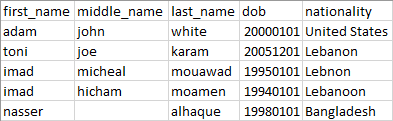
Figure 2 – Customer list
To import the CSV file to the destination SQL table, we need to get the corresponding identifier for each nationality from the “countries” table. In the ETL approach, the SSIS lookup transformation is the most popular method to achieve that. To illustrate how we can use this component, we will create an SSIS package.
First of all, we define a flat file connection manager for the customer list CSV file and an OLE DB connection manager for the destination SQL Server database. Then, we add a data flow task into the package control flow. We add a “Flat File Source” component and an SSIS lookup transformation in the data flow task.
After configuring the “Flat File Source”, we open the SSIS lookup transformation editor to configure it. As shown in the image below, the first page in the editor contains the following options:
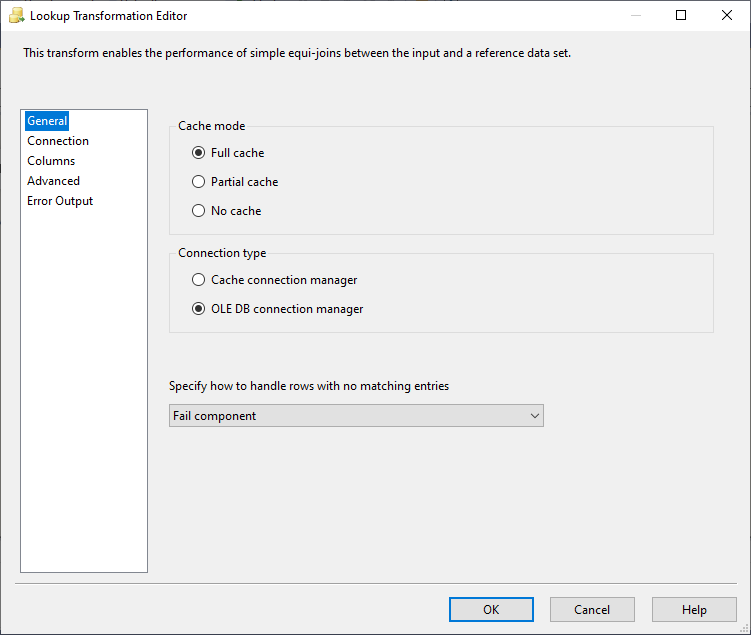
Figure 3 – Lookup transformation editor’s general page
- Cache mode:
- Full cache: The lookup table is loaded into the cache before the transformation runs
- Partial cache: The rows with matching entries in the lookup table and, optionally, the rows without matching entries in the dataset are stored in the cache (configuration in the advanced tab page). When the memory size of the cache is exceeded, the Lookup transformation automatically removes the least frequently used rows from the cache
- No Cache: No data is loaded into the cache memory
- Connection type: There are two available connection managers in the SSIS lookup transformation; OLE DB connection manager and Cache connection manager (only Full cache mode)
- No matching entries handling: This option is used to specify how to handle rows with no matching entries in the lookup table. In this example, we choose the “Redirect rows to no match output” option
In this article, we will explain working with Full Cache mode and OLE DB connection manager. For more details about using Cache connection manager or caching modes, you can refer to the following Microsoft official documentation:
- Lookup Transformation Full Cache Mode – Cache Connection Manager – SQL Server Integration Services (SSIS)
- Implement a Lookup in No Cache or Partial Cache Mode – SQL Server Integration Services (SSIS)
Next, we should go to the Connection to select the lookup table. As shown in the image below, we have to choose the connection manager and the lookup table. Also, we can use a SQL command instead of just selecting a table which allows us to use multiple joint tables as a reference data set.
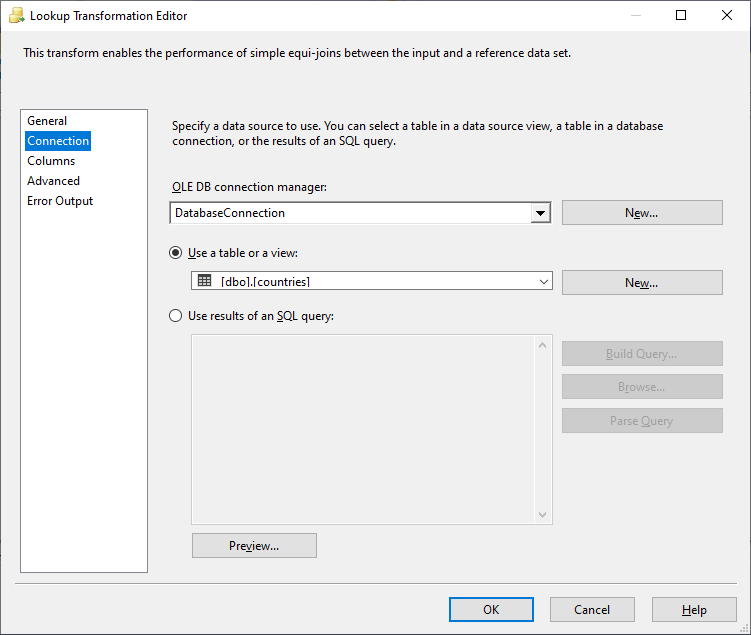
Figure 4 – Lookup transformation editor’s connection page
In this example, we select the countries table as the reference dataset. After choosing the lookup table, we should go to the columns tab page to specify the columns used to join the source data set with the lookup table and select the columns in the reference table that we need to add to the data pipeline.
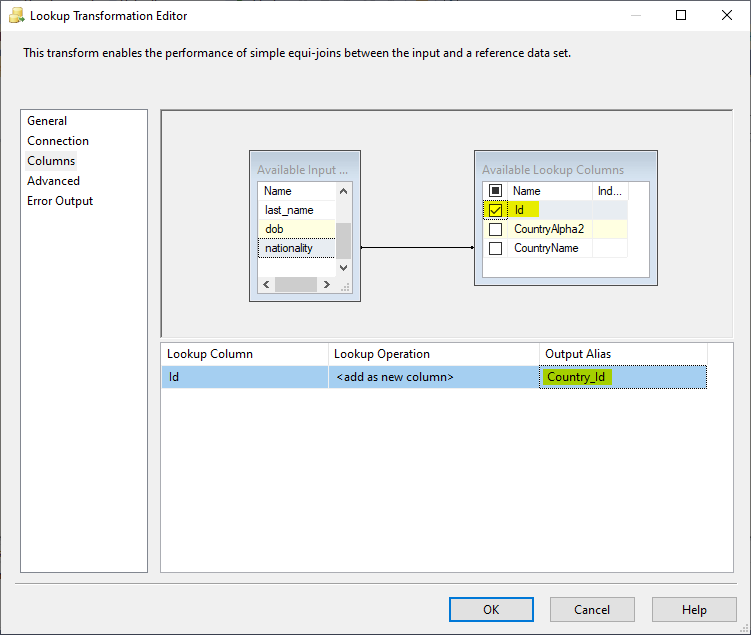
Figure 5 – Configuring lookup columns
After configuring the SSIS lookup transformation, we add an OLE DB destination component at the end of the data pipeline after selecting the “Lookup Match Output” as an input.
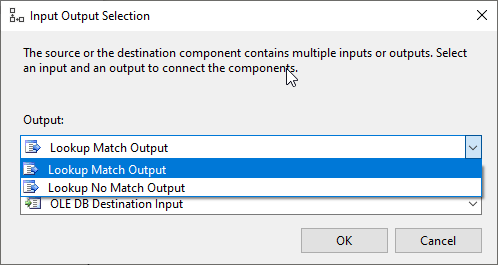
Figure 6 – Selecting the lookup match output
In the OLE DB destination, we should map the columns correctly, as shown in the image below.
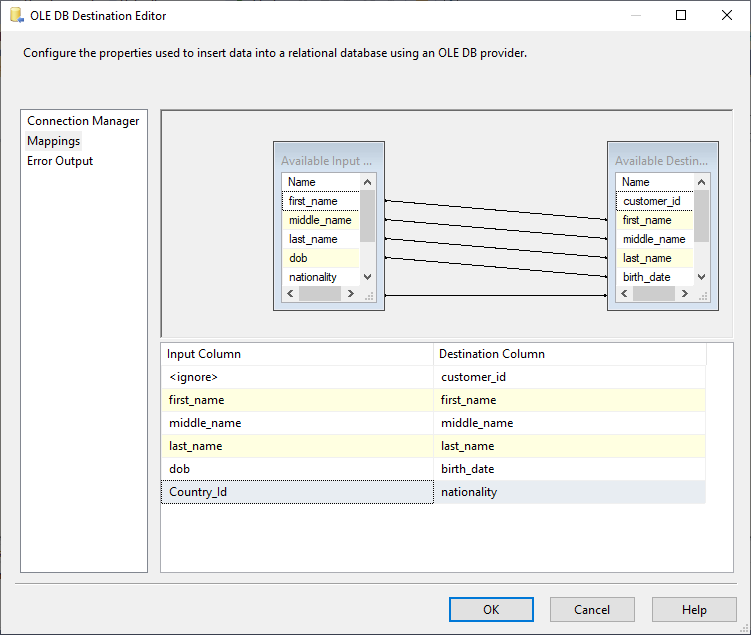
Figure 7 – Mapping columns in the OLE DB destination
As mentioned previously, we configured the SSIS lookup transformation to redirect the non-matching rows to the “Lookup no match output”. For this purpose, we add another OLE DB Destination component to store the non-matching rows in another SQL table.
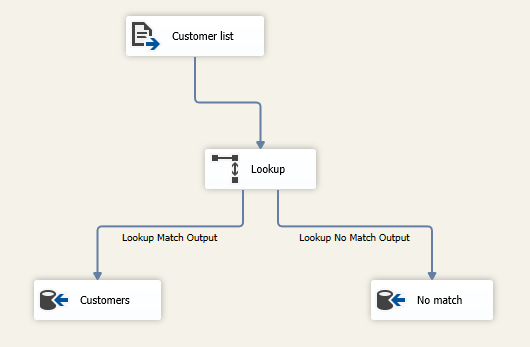
Figure 8 – Data Flow Task
Let’s try to execute the package, as shown in the image below three rows were inserted into the customers table while two others are redirected to the non-matched rows table.
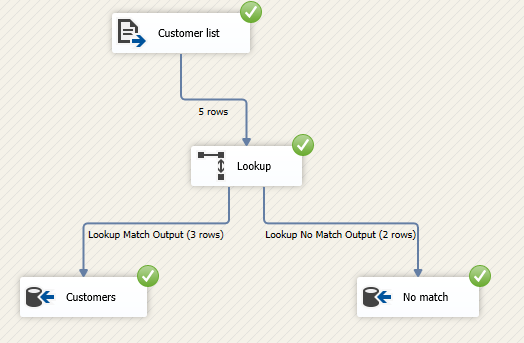
Figure 9 – Data flow task after execution
After checking the SQL table, the “customers” table shows that the nationality column contains the numeric values taken from the countries table.
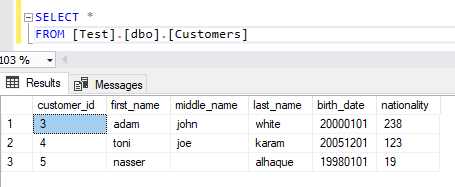
Figure 10 – Matched rows
While the non-matched rows table shows that we have some typos in the countries name.
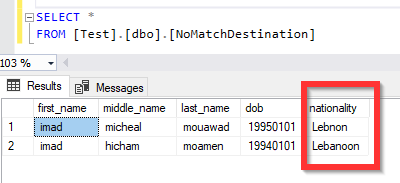
Figure 11 – Non matched rows
Fuzzy lookup transformations
As defined in Wikipedia, Fuzzy matching is a technique used in computer-assisted translation as a special case of record linkage. It works with matches that may be less than 100% perfect when finding correspondences between segments of a text and entries in a database of previous translations.
The Fuzzy lookup is another lookup transformation available in SSIS. Rather than using equality join to link the main data pipeline to the reference data set, it uses fuzzy matching to return one or more close matches from the lookup table.
Figure 12 – Fuzzy lookup description from the SSIS toolbox
As explained in the previous section, redirecting non-matched rows is one approach used to handle non-matched values. Another approach is to use the fuzzy lookup to minimize the number of those values as much as possible. Let’s apply that in our previous example.
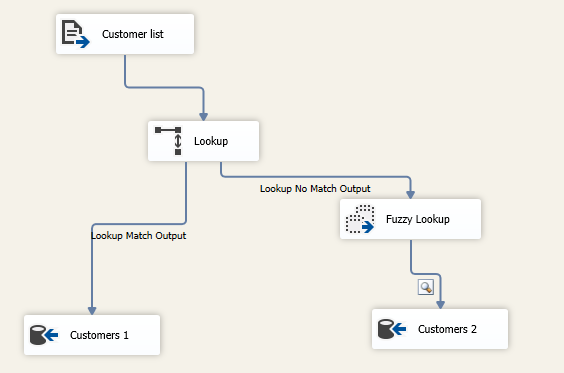
Figure 13 – Data flow task after adding the fuzzy lookup component
The fuzzy lookup configuration is very similar to the SSIS lookup transformation. As shown in the images below, we must choose the reference (lookup) table, the columns used to join this table with the main data pipeline.
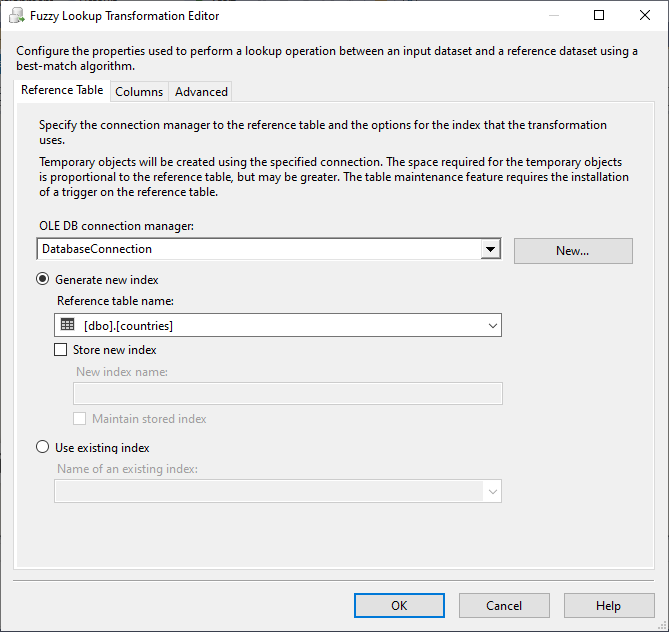
Figure 14 – Selecting the reference data set
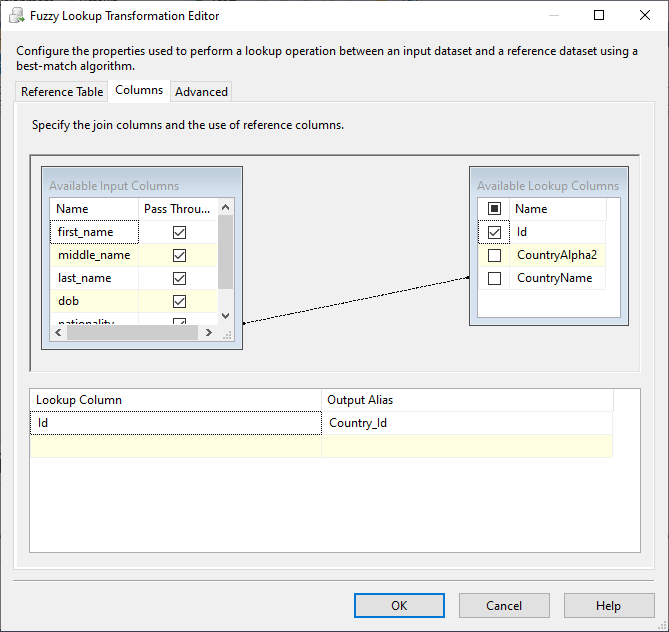
Figure 15 – Configuring the fuzzy lookup columns
The fuzzy lookup requires some additional configuration, such as the similarity threshold and the delimiters used to tokenize the values before matching them with the reference column.
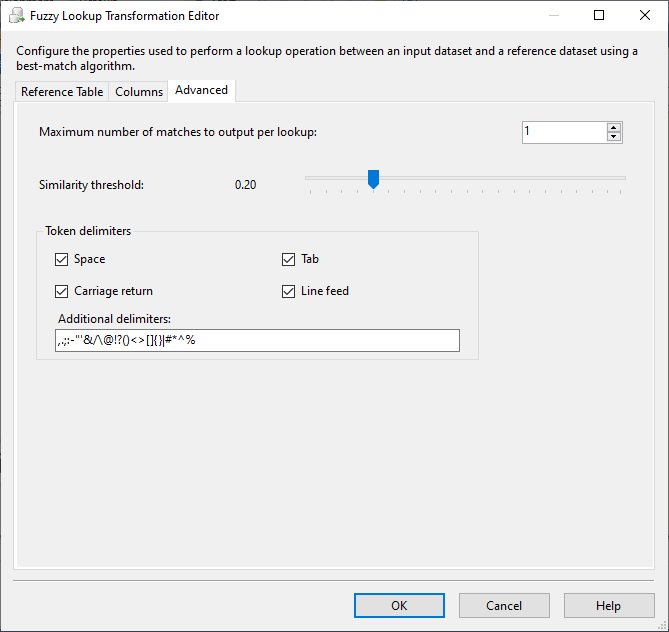
Figure 16 – Fuzzy lookup advanced configuration
By selecting a similarity threshold of 20%, we can note that one from two redirected non-matched values is matched while the other one is not.
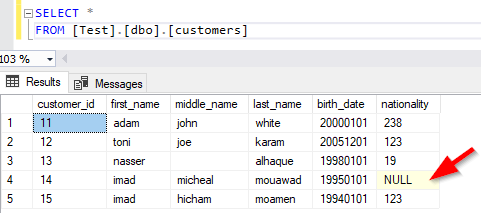
Figure 17 – Only one value is not matched after adding the fuzzy lookup to the data flow
Lookup vs. Fuzzy lookup
There are many differences between the lookup and fuzzy lookup transformations in SSIS. Some of them are illustrated in the following table.
|
Lookup |
Fuzzy Lookup |
|
|
Matching values |
Equality |
Similarity threshold |
|
Non matched rows handling |
Redirect rows, Ignoring, Throwing an exception |
Ignoring |
|
Need an Index for comparison |
No |
Yes |
|
Has error output |
Yes |
No |
|
Cache support |
Yes |
No |
|
SQL command support |
Yes |
No |
|
Number of matches |
Only one match |
One or more |
Table – Lookup’s comparison
External resources
In this article, we tried to explain both components simply without providing too many details. You can refer to the following articles for more information:
Summary
This article explained lookups and why they are used while handling data. Then, we explained the SSIS lookup transformation and how to configure it to standardize data values. Also, we illustrated the fuzzy lookup component and how to use it to minimize the number of non-matched rows by the lookup transformation. Finally, we compared both lookup components and provided some external resources.
Table of contents

Besides working with SQL Server, he worked with different data technologies such as NoSQL databases, Hadoop, Apache Spark. He is a MongoDB, Neo4j, and ArangoDB certified professional.
On the academic level, Hadi holds two master's degrees in computer science and business computing. Currently, he is a Ph.D. candidate in data science focusing on Big Data quality assessment techniques.
Hadi really enjoys learning new things everyday and sharing his knowledge. You can reach him on his personal website.
View all posts by Hadi Fadlallah
- An overview of SQL Server monitoring tools - December 12, 2023
- Different methods for monitoring MongoDB databases - June 14, 2023
- Learn SQL: Insert multiple rows commands - March 6, 2023