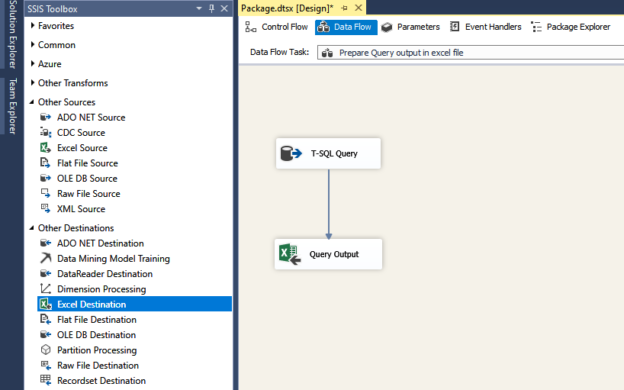
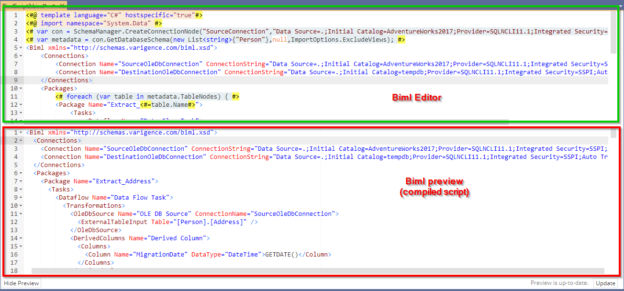
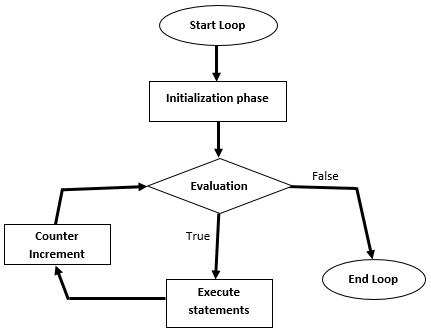
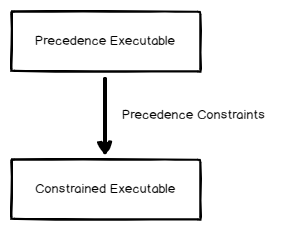
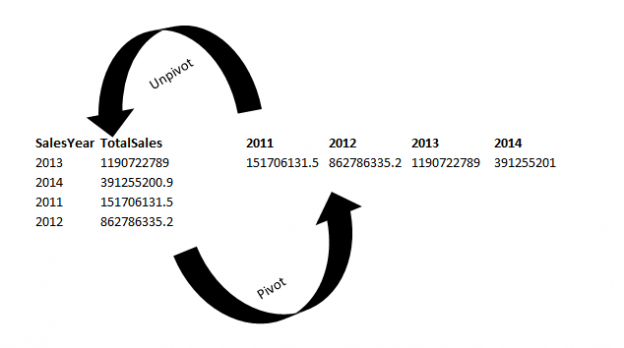
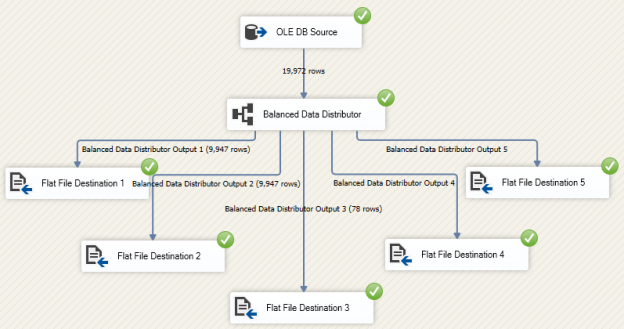
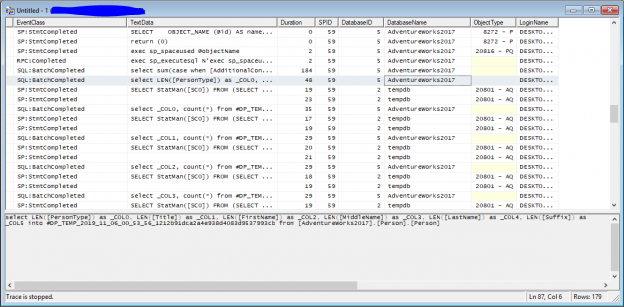
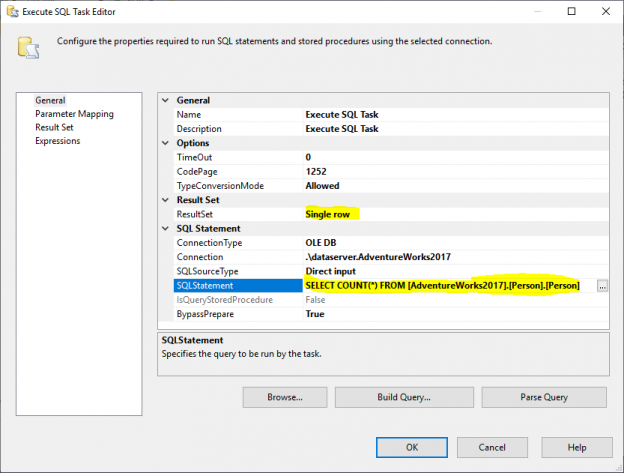
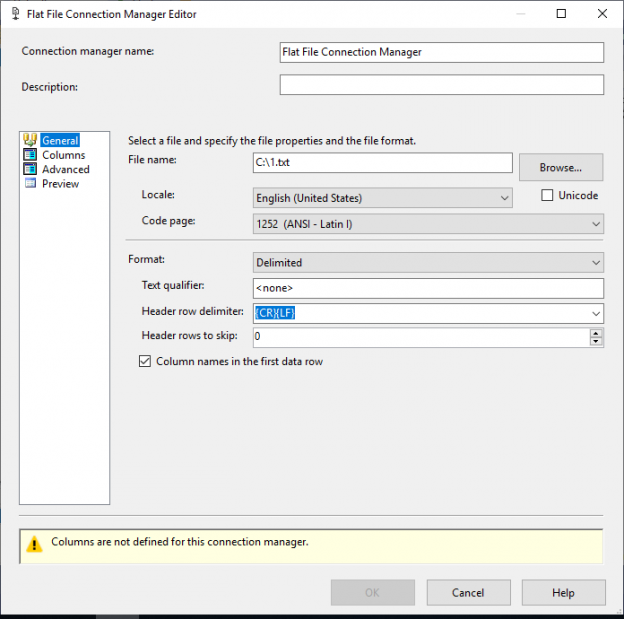
In this article, we will learn to upload the excel file to Azure blob storage using SQL Server Integration Service Package. The excel file contains the output of a T-SQL query. This article is a small demonstration that gives some idea about the Azure Blob Upload task and how it can be used to upload files using SSIS.
Read more »