
In this article, I am going to discuss Apache Spark and how to create robust ETL pipelines for transforming big data. I will start from the very basics of Spark and then provide details on how to install Spark and start building the pipelines. In the later part of the article, I will also discuss how to leverage the Spark APIs to do transformations and obtain data into Spark data frames and SQL to continue with the data analysis.
By the definition from Wikipedia – “Apache Spark is an open-source distributed general-purpose cluster-computing framework. Spark provides an interface for programming entire clusters with implicit data parallelism and fault tolerance.”.
From the official website of Spark – “Apache Spark™ is a unified analytics engine for large-scale data processing.”
Figure 1 – Apache Spark – The unified analytics engine (Source)
Some of the most important features of using Apache Spark as follows.
- As compared to the traditional data processing tools, it is a lot faster and can process larger datasets almost 100 times faster. The in-memory processing technology of Spark allows it to be 100 times faster for data stored in the RAM and almost 10 times for data in the storage as compared to MapReduce
- It provides libraries out of the box to deal with SQL, Graph, and Streaming APIs. This enables the users to query and process data using the standard SQL statements and can be queried using the Spark data frame
- It is convenient for the programmers to begin using Spark as there is no need to learn any new programming language. Spark is mainly developed using Scala and the data pipelines can be implemented using Scala, R or Python. Personally, I feel the PySpark library to be very useful while writing Spark data frames in Python. We will learn more about PySpark in the later
Understanding the Apache Spark Ecosystem Components
Let’s now take a look at the various components of Spark.
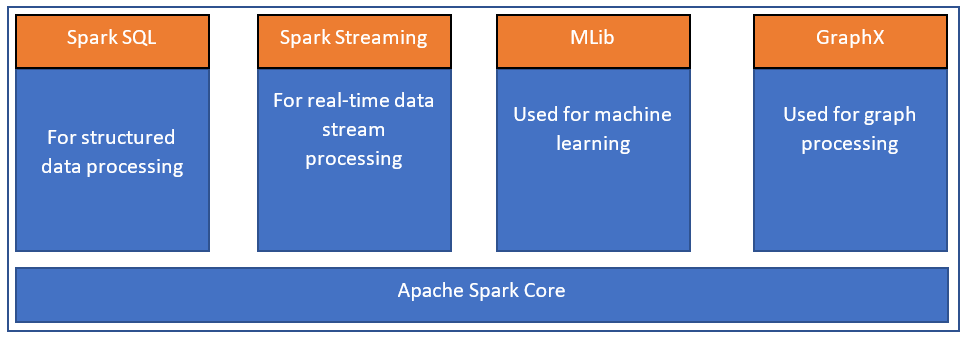
Figure 2 – Components of Spark Core (Source)
From the figure above, we can see that Spark is built on top of its core engine known as the “Apache Spark Core”. This is the all-purpose general execution engine that is used to run and execute all the other functionalities within Spark. All the other components like Spark SQL, Spark Streaming, MLlib, and GraphX work in conjunction with the Spark Core engine.
- Spark SQL – This is one of the most common features of the Spark processing engine. This allows users to perform data analysis on large datasets using the standard SQL language. It also allows us to run native Hive queries on the existing Hadoop environments available. Spark SQL can be used to extract and run data transformation queries as well
- Spark Streaming – Running analytic workloads on top of fast-moving streaming data is possible with the help of this unique feature in Spark. It helps to analyze large volumes of data as and when they arrive by running special operations on the data. It continuously uses the Spark Core engine to ingest data in a small-scaled cluster and performs RDD (will understand later in the article) on those
- MLlib – Machine Learning is one of the profound capabilities that most users desire to implement using Spark. Running Machine Learning algorithms on top of the Spark Core engine is done with the help of MLlib. It leverages the in-memory distributed data structures for training the data models which is quite faster as compared to the previous version of Apache Mahout
- GraphX – It is a distributed graph data processing engine built using the Spark Core engine. On a very high level, it extends the functionality of the Spark RDD by creating a Resilient Distributed Property Graph. It is a simple structure that associates nodes and their properties by using vertices and edges
Overview of the Spark Architecture
Now that we have some idea about the components of the Spark ecosystem, let’s try to understand the architecture behind Spark and how the components are related to each other.
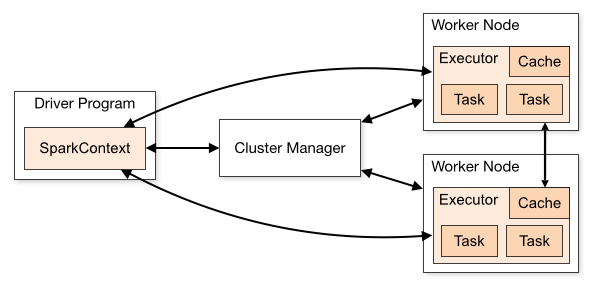
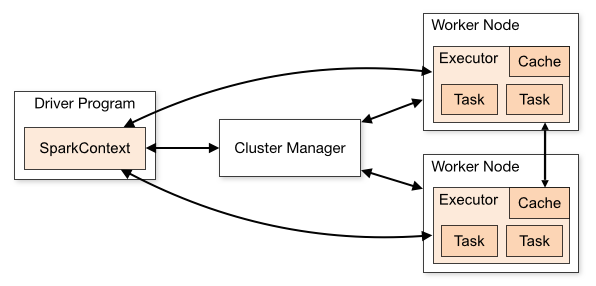
Figure 3 – Overview of Spark Architecture (Source)
As you can see in the figure above, on the left we have a Driver Program that runs on the master node. The master node is the one that is responsible for the entire flow of data and transformations across the multiple worker nodes. Usually, when we write our Spark code, the machine to which we deploy acts as the master node. After the Driver Program, the very first thing that we need to do is to initiate a SparkContext. The SparkContext can be considered as a session using which you can use all the features available in Spark. For example, you can consider the SparkContext as a database connection within your application. Using that database connection you can interact with the database, similarly, using the SparkContext you can interact with the other functionalities of Spark.
There is also a Cluster Manager installed that is used to control multiple worker nodes. The SparkContext that we have generated in the previous step works in conjunction with the Cluster Manager to manage and control various jobs across all the worker nodes. Whenever a job has to be executed by the Cluster Manager, it splits up the entire job into multiple individual tasks and then these tasks are distributed over the worker nodes. This is taken care of by the Driver Program and the SparkContext. As soon as an RDD is created, it is distributed by the Cluster Manager across the multiple worker nodes and cached there.
On the right-hand side of the architecture diagram, you can see that we have two worker nodes. In practice, this can range from two to multiple worker nodes depending on the workload of the system. The worker nodes actually act as the slave nodes that execute the tasks distributed to them by the Cluster Manager. These worker nodes return the execution result of the tasks to the SparkContext. A key point to mention here is that you can increase your worker nodes such that all the jobs are distributed to each of the worker nodes and as such the tasks can be performed parallelly. This will increase the speed of data processing to a large extent.
Some other concepts involved in Spark
Here are some of the important concepts necessary for understanding the Spark ecosystem.
- RDDs (Resilient Distributed Datasets) – These are the fundamental data structures used in Spark. Resilient means it is fault-tolerant and the datasets are distributed across multiple worker nodes, hence it’s distributed
- DAG (Direct Acyclic Graph) – These are defined processes of workflow in the form of graphs and nodes such that each of the tasks has a sequence and works after the completion of the task before it. DAGs are used to define the various tasks in a job
Conclusion
In this article, we have understood what Apache Spark is, the components of Spark, and the underlying architecture. We have also learned in detail about the components like Spark SQL, Spark Streaming, MLlib, and GraphX in Spark and their uses in the world of data processing. Spark is a unified data processing engine that can be used to stream and batch process data, apply machine learning on large datasets, etc. Spark is not suitable for use in a multi-user the environment at the moment. In the next article, I will provide details to get started with some hands-on using Spark. Some other topics worth giving a read on Apache Spark are mentioned below.
- Learn more about Spark from the official documentation
- Read about DataBricks – The Unified Analytics Engine
- You can also run Spark on AWS as an Amazon EMR Cluster

He is a prolific author, with over 100 articles published on various technical blogs, including his own blog, and a frequent contributor to different technical forums.
In his leisure time, he enjoys amateur photography mostly street imagery and still life. Some glimpses of his work can be found on Instagram. You can also find him on LinkedIn
View all posts by Aveek Das
- Getting started with PostgreSQL on Docker - August 12, 2022
- Getting started with Spatial Data in PostgreSQL - January 13, 2022
- An overview of Power BI Incremental Refresh - December 6, 2021