
In this article, we will learn the SQL Server clustered index concept and some internal details. Indexes are the database objects that accelerate the performance of data accessing when are designed properly. A clustered index is one of the main index types in SQL Server and the working principle is a bit complicated but in the next sections of this article, we are going to simply learn the clustered index working principle and uncover the secrets.
What is a clustered index?
SQL Server clustered index creates a physical sorted data structure of the table rows according to the defined index key.
- Secret:
- The physical word is mostly used in clustered index descriptions, but the clustered index does not guarantee the physical order of the rows
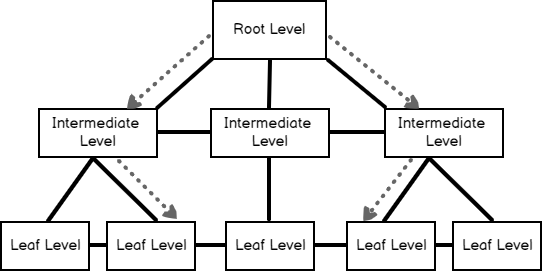
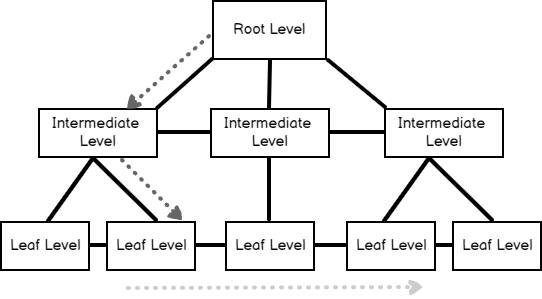
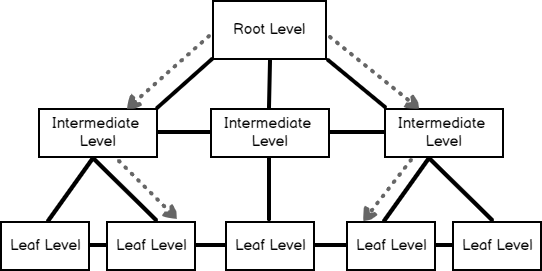
This sorted data structure is called a B-tree (balanced tree). B-tree structure enables us to find the queried rows faster to using the sorted key value(s). Table data can be sorted physically in only one direction for this reason we can define only one clustered index per table. The following image illustrates a logical structure of the clustered index.
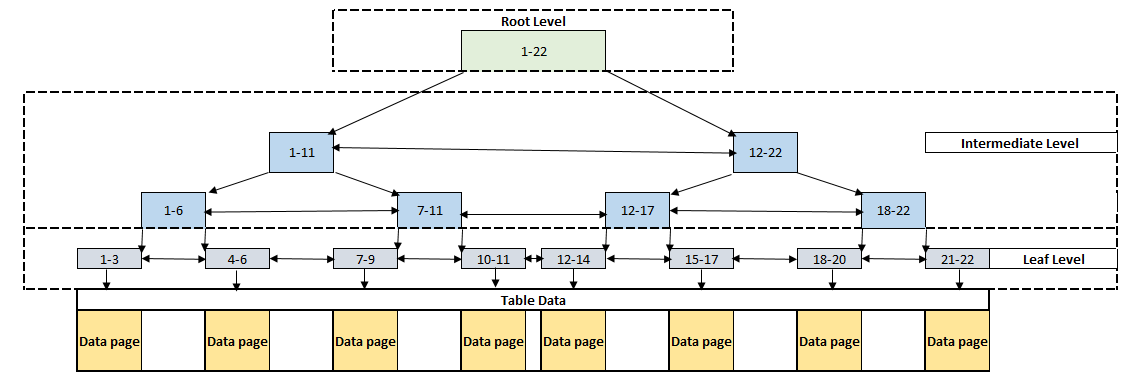
The root and intermediate levels contain the index key values and page pointers. The page pointers point to the previous and subsequent index pages of their own. These two levels don’t store any row data. At the same time, index pages hold information about the ahead and behind index page numbers.B-tree structure based-on three different levels:
- Root level: The top level of the B-tree is called as root level. The root level is the starting point of the data searching
- Intermediate level: This level provides a connection between root and leaf levels. SQL Server does not create an intermediate level when the amount of data rows are too small
- Leaf Level: This level is the lowest level of the clustered index and all records are stored at this level
For example, when we want to query a row that’s record number 10, the storage engine will travel across the following red dotted path. The searching mechanism begins its travel at the root level and reaches the data row at the leaf level.
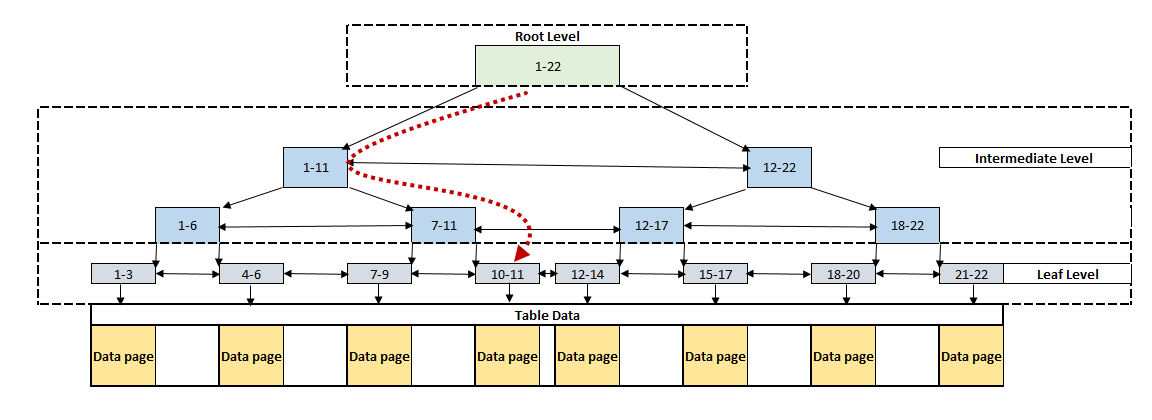
As we can see, the searched row was found with the minimum read operation by the storage engine otherwise it has to read whole table rows.
SQL Server Clustered Index and Singleton Seek
After briefly discussing the clustered index structure, let’s go into the details of how a record in a table is searched by the clustered index. Firstly, we will create a Cars table and then we will populate some sample data into it.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
CREATE Table Cars (Id INT, BrandName VARCHAR(100)) GO INSERT INTO Cars VALUES(1,'Ford') INSERT INTO Cars VALUES(2,'Fiat') INSERT INTO Cars VALUES(3,'Mini') INSERT INTO Cars VALUES(4,'Jaguar') INSERT INTO Cars VALUES(5,'Kia') INSERT INTO Cars VALUES(6,'Nissan') INSERT INTO Cars VALUES(7,'BMW') INSERT INTO Cars VALUES(8,'Mercedes') INSERT INTO Cars VALUES(9,'Mazda') INSERT INTO Cars VALUES(10,'Volvo') INSERT INTO Cars VALUES(11,'Lexus') INSERT INTO Cars VALUES(12,'Buick') INSERT INTO Cars VALUES(13,'GMC') INSERT INTO Cars VALUES(14,'Honda') INSERT INTO Cars VALUES(15,'Lotus') INSERT INTO Cars VALUES(16,'Opel') INSERT INTO Cars VALUES(17,'Bentley') INSERT INTO Cars VALUES(18,'Dodge') INSERT INTO Cars VALUES(19,'Tesla') INSERT INTO Cars VALUES(20,'Porche') INSERT INTO Cars VALUES(21,'Ferrari') INSERT INTO Cars VALUES(22,'Audi') GO |
We will define a unique clustered index to the Cars table.
|
1 2 |
CREATE UNIQUE CLUSTERED INDEX IX_001 ON Cars (Id); |
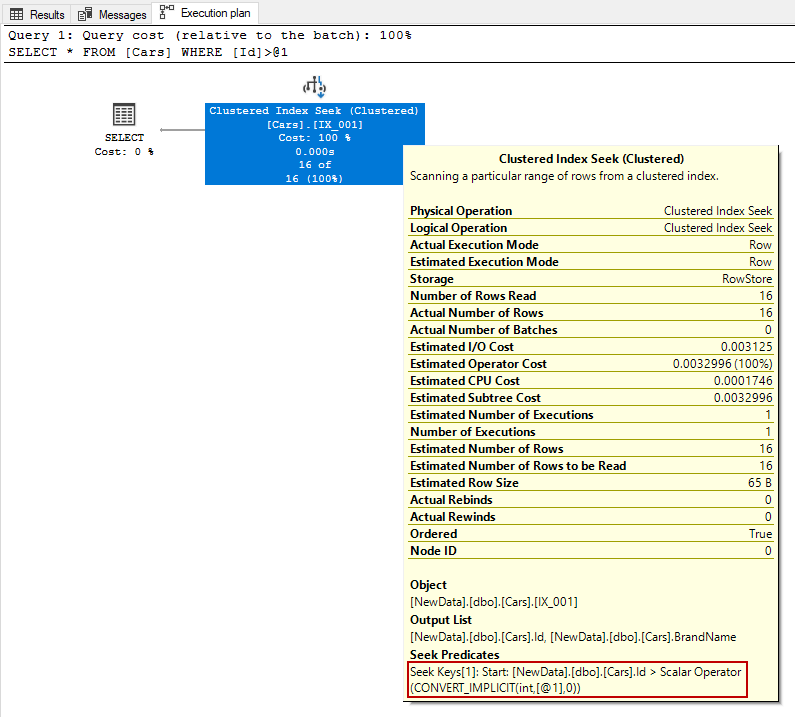
SQL Server performs a clustered index seek process when it accesses data to using the B-tree structure. This operation type is represented by the following icon in the execution plans.
![]()
When we execute the following query, it will perform a clustered index seek operation. The clustered index seek operation uses the structure of the B-tree structure very efficiently and easily finds the qualified row(s).
|
1 2 3 |
SELECT * FROM Cars WHERE Id = 12; |
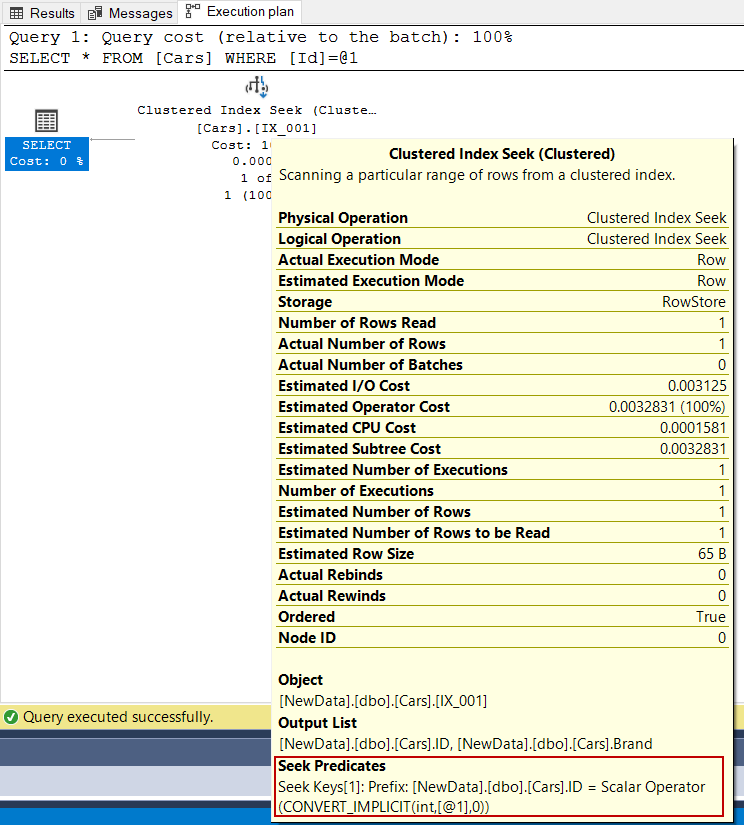
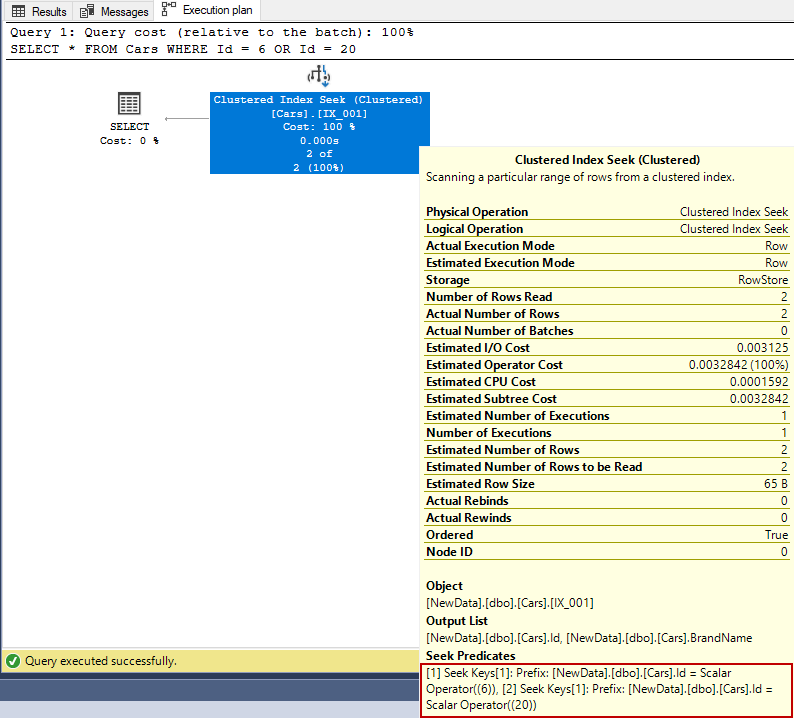
In this execution plan, the seek predicates indicate that the storage engine uses the B-tree structure and finds the leaf level that stores the data rows. For this query, the uniqueness of the clustered index is very important because this constraint guarantees that only one row will return from the query. This data searching concept is called singleton seek.
- Secret:
- Defining a clustered index as unique can gain performance improvements when the indexed column(s) is used after the WHERE clause
SQL Server Clustered Index and Range Scan
When we explain the structure of the clustered index, we mentioned an interconnection between the index pages and its backward and forward pages. This connection is very useful for queries that have upper or lower boundaries or have both of them. For example, the following query will perform singleton seek firstly and reaches the leaf level that contains the data row (Id=12). According to retrieve the index keys, the range scans operation has been performed either in forward or backward directions.
|
1 2 3 |
SELECT * FROM Cars WHERE Id > 12; |
In the execution plan, the ScanDirection attributes show the direction of the range seek process.

The following image illustrates how the range scan process works.
Most of the time, we can hear that the SQL Server clustered index seek operator is super faster than the other data searching operations. However, this myth may not be exactly true for some queries that perform a range scan. For example, we create a table and insert some synthetic data.
|
1 2 3 4 5 6 7 8 9 10 |
CREATE TABLE TestPerformance ( ID INT IDENTITY(1, 1), TextList VARCHAR(100)); GO INSERT INTO TestPerformance VALUES ( 'Any Text'); GO 15000 |
Now we execute the following query and examine the execution plan.
|
1 2 3 |
SELECT * FROM TestPerformance WHERE Id > 2; |
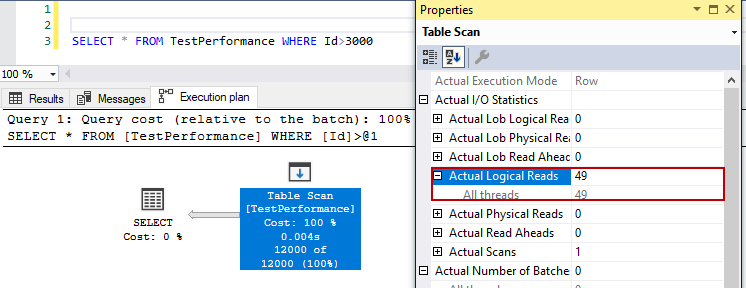
It has read 49 pages and has performed a table scan.
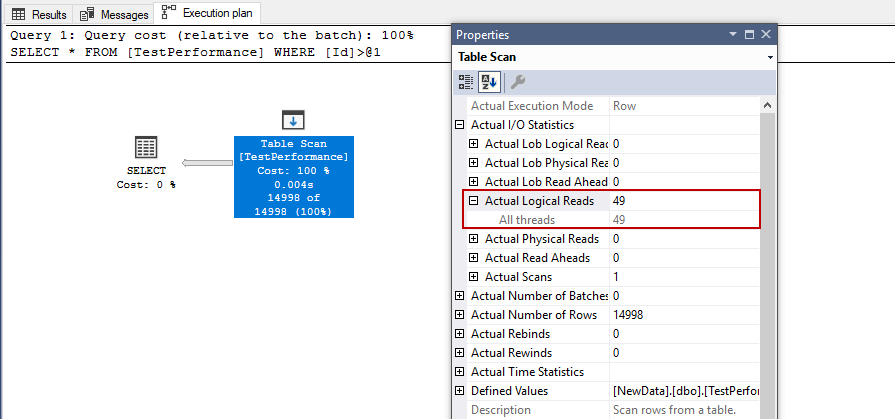
In this step, we will add a unique non-clustered index and re-execute the previous query.
|
1 2 3 |
CREATE UNIQUE CLUSTERED INDEX IX_001 ON TestPerformance (Id); |
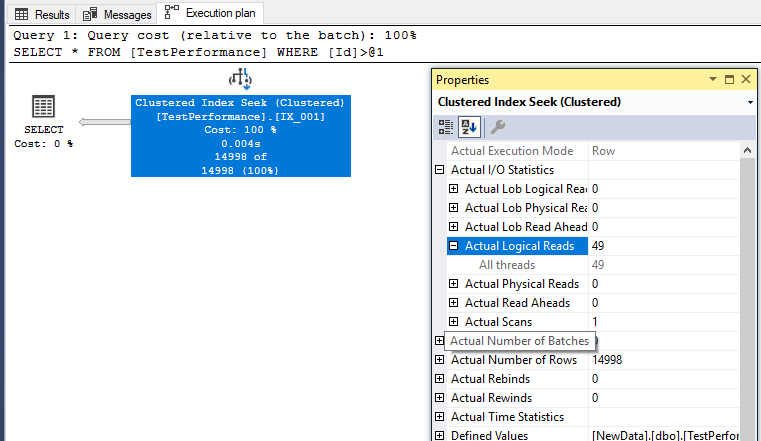
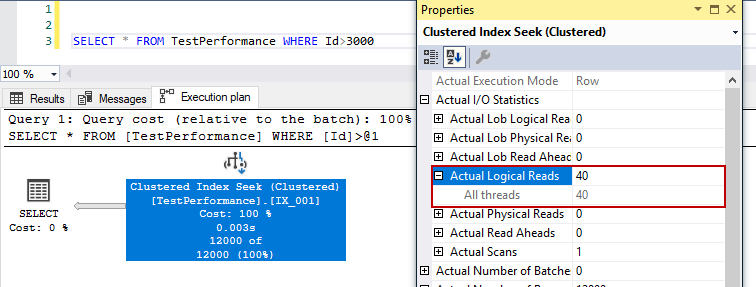
For this query, the clustered index seek operator does not change the performance of the query and both of them have read the same amount of the data. The problem of this query is it reads whole leaf pages of the index so it doesn’t make any difference in performance between the table scan and index seek search. On the other hand, if we repeat the same test for the following query, we will not obtain the same result.
|
1 2 3 |
SELECT * FROM TestPerformance WHERE Id > 3000; |
Without the clustered index:
With the clustered index:
Besides that, the singleton seeks principle can also work multiple times for some queries as we can see in the below query.
|
1 2 3 4 |
SELECT * FROM Cars WHERE Id = 6 OR Id = 20; |
The following image illustrates how the multiple singleton seek process works:
The following query is another example of the multiple singleton seeks:
|
1 2 3 |
SELECT * FROM Cars WHERE Id IN (1,4,8,12,22) |
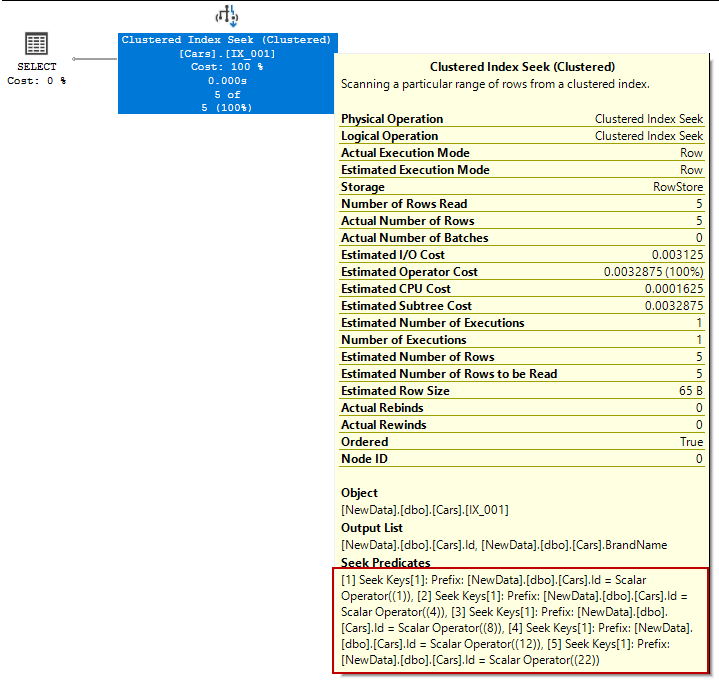
SQL Server Clustered Index and Primary Key
The primary key ensures that the values of a column in the table are unique so that all rows are identified with a unique key. By default when we create a primary key SQL Server creates a unique clustered index. However, we can create a primary key without a clustered index because the only mandatory requirement is uniqueness for the primary key. So the main differences between the primary key and clustered index are:
- A primary key is a logical structure and it provides the uniqueness for a table
- A clustered index is a physical structure and it provides the physical order of the records on the storage
Perhaps, this question is the right one to ask:
“Why we use the primary key and clustered indexes on the same key column?”
SQL Server adds a 4-byte uniquefier value for every duplicate index key on the non-unique clustered indexes.
At first, we will create a very basic table, it will include only two-column and then we create a non-unique clustered index for this table.
|
1 2 3 4 5 6 7 8 |
CREATE TABLE TestDublicate ( IdNumber INT, Col1 VARCHAR(100)); GO CREATE CLUSTERED INDEX IX_001 ON TestDublicate (IdNumber); |
Now, we will insert a row to this table and querying the size of max and minimum record size of the index pages with help of the sys.dm_db_index_physical_stats view.
|
1 2 3 4 5 6 7 8 9 10 11 |
INSERT INTO TestDublicate (IdNumber, Col1) VALUES ( 1, 'Text-1'); SELECT min_record_size_in_bytes, max_record_size_in_bytes FROM sys.dm_db_index_physical_stats (DB_ID(), OBJECT_ID('TestDublicate'), NULL, NULL, N'SAMPLED'); |

We will add a duplicate row and re-examine the max record size column.
|
1 2 3 4 5 6 7 8 9 10 11 |
INSERT INTO TestDublicate (IdNumber, Col1) VALUES ( 1, 'Text-2'); SELECT min_record_size_in_bytes, max_record_size_in_bytes FROM sys.dm_db_index_physical_stats (DB_ID(), OBJECT_ID('TestDublicate'), NULL, NULL, N'SAMPLED'); |

Now let’s look at the metadata of the index page. At first, we will determine the page id of the clustered index page.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
SELECT DB_NAME(PageDetail.database_id) AS DatabaseName, OBJECT_NAME(PageDetail.object_id) AS TableName, ind.Name IndexName, allocated_page_page_id FROM sys.dm_db_database_page_allocations (DB_ID('NewData'), OBJECT_ID('TestDublicate'), 1, NULL, 'DETAILED') PageDetail LEFT OUTER JOIN sys.indexes ind ON ind.object_id = PageDetail.object_id AND ind.index_id = PageDetail.index_id WHERE is_allocated = 1 AND page_type IN (1, 2) ORDER BY page_level DESC, is_allocated DESC, previous_page_page_id; |

DBCC PAGE command shows the contents of the data and index page. We will use this command to find out detailed information about the index page.
|
1 2 |
DBCC TRACEON(3604) DBCC PAGE('NewData',1,280,3) WITH TABLERESULTS |
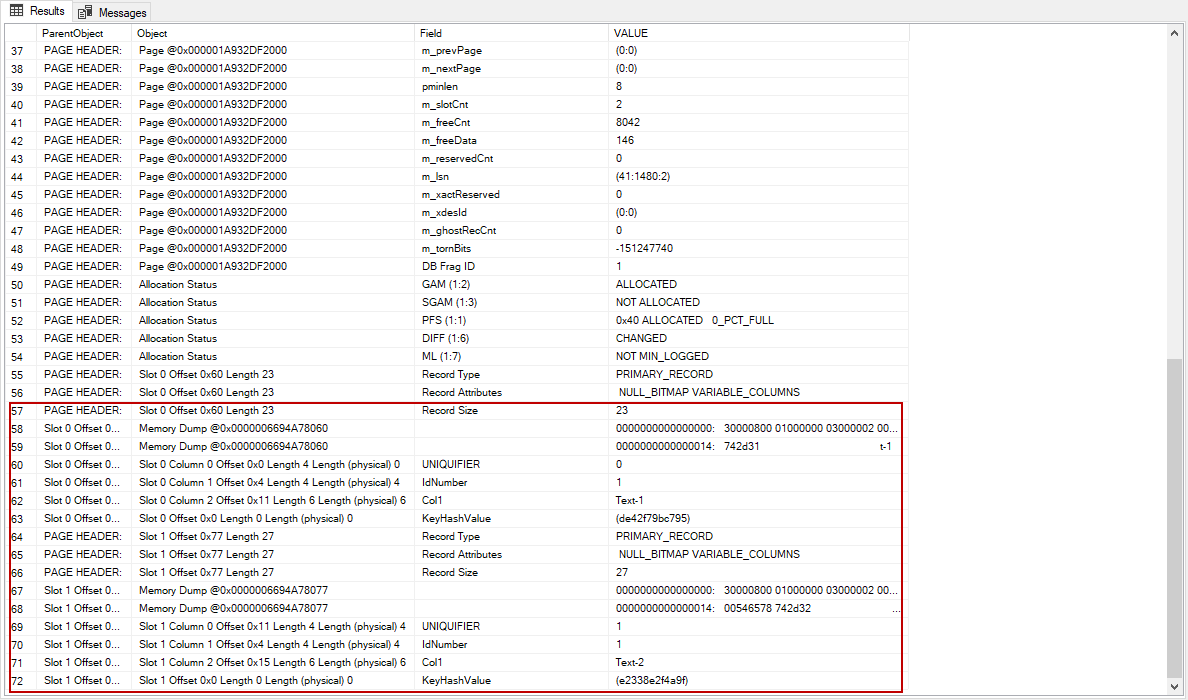
As we can see the first index page uniquifier field value is 0 which means there isn’t a uniquifier defined for this index page. However, the second index page includes an uniquifier field value is 1 which means SQL Server adds an additional KeyHashValue.
Conclusion
In this article, we have uncovered some secrets of SQL Server clustered indexes. Actually clustered indexes are widely used by the SQL developers or DBAs but some details can go unnoticed. Singleton seek and range scan have to be considered for the performance of the clustered index.

Most of his career has been focused on SQL Server Database Administration and Development. His current interests are in database administration and Business Intelligence. You can find him on LinkedIn.
View all posts by Esat Erkec
- SQL Performance Tuning tips for newbies - April 15, 2024
- SQL Unit Testing reference guide for beginners - August 11, 2023
- SQL Cheat Sheet for Newbies - February 21, 2023