
This article gives an introduction of the non-clustered index in SQL Server using examples.
Introduction
In a previous article Overview of SQL Server Clustered indexes, we explored the requirement of an index and clustered indexes in SQL Server.
Before we proceed, let’s have a quick summary of the SQL Server clustered index:
- It physically sorts data according to the clustered index key
- We can have only one clustered index per table
- A table without a clustered index is a heap, and it might lead to performance issues
- SQL Server automatically creates a clustered index for the primary key column
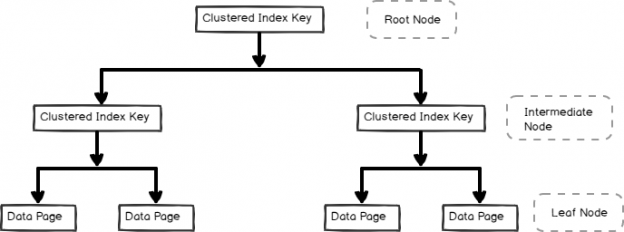
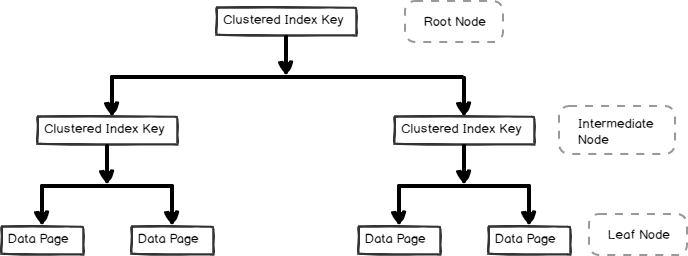
- A clustered index is stored in b-tree format and contains the data pages in the leaf node, as shown below
Non-Clustered indexes are also useful for query performance and optimization depending upon query workload. In this article, let’s explore the non-clustered index and its internals.
Overview of the non-clustered index in SQL Server
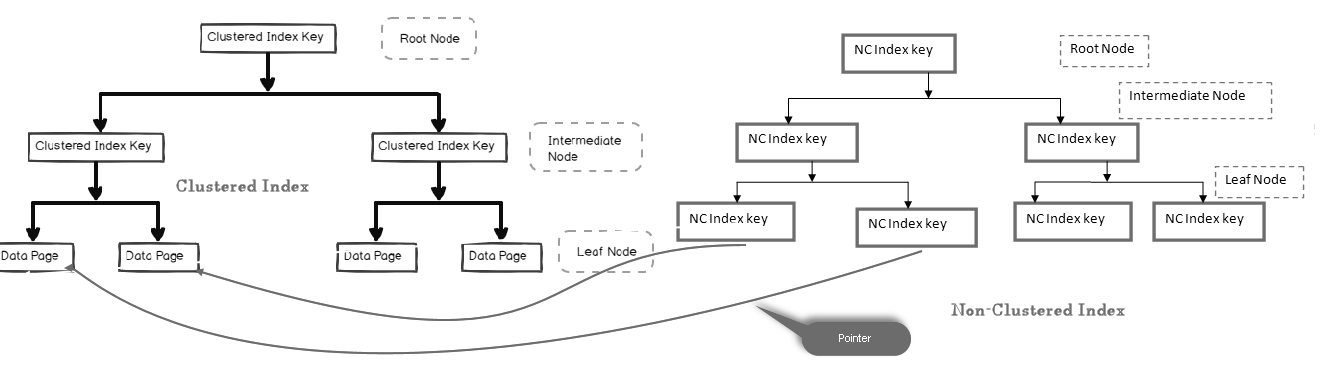
In a non-clustered index, the leaf node does not contain the actual data. It consists of a pointer to the actual data.
- If the table contains a clustered index, leaf node points to the clustered index data page that consists of actual data
- If the table is a heap (without a clustered index), leaf node points to the heap page
In the below image, we can look at the leaf level of non-clustered index pointing towards data page in the clustered index:
We can have multiple non-clustered indexes in SQL tables because it is a logical index and does not sort data physically as compared to the clustered index.
Let’s understand the non-clustered index in SQL Server using an example.
-
Create an Employee table without any index on it
123456CREATE TABLE dbo.Employee(EmpID INT,EMpName VARCHAR(50),EmpAge INT,EmpContactNumber VARCHAR(10)); -
Insert few records in it
123Insert into Employee values(1,'Raj',32,8474563217)Insert into Employee values(2,'kusum',30,9874563210)Insert into Employee values(3,'Akshita',28,9632547120) -
Search for the EmpID 2 and look for the actual execution plan of it
1Select * from Employee where EmpID=2It does a table scan because we do not have any index on this table:

-
Create a unique clustered index on the EmpID column
1CREATE UNIQUE CLUSTERED INDEX IX_Clustered_Empployee ON dbo.Employee(EmpID); -
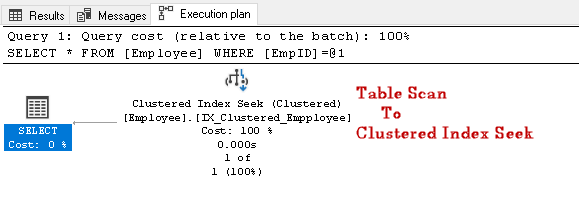
Search for the EmpID 2 and look for the actual execution plan of it
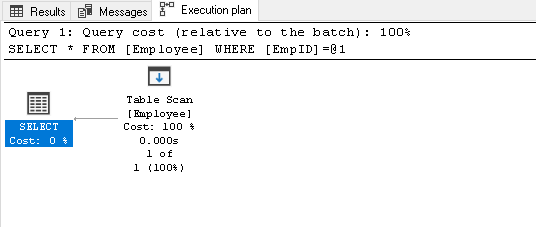
In this execution plan, we can notice that the table scan changes to a clustered index seek:
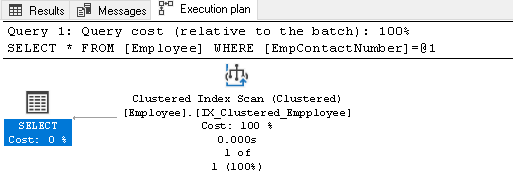
Let’s execute another SQL query for searching Employee having a specific contact number:
|
1 |
Select * from Employee where EmpContactNumber='9874563210' |
We do not have an index on the EmpContactNumber column, therefore Query Optimizer uses the clustered index, but it scans the whole index for retrieving the record:
Right-click on the execution plan and select Show Execution Plan XML:
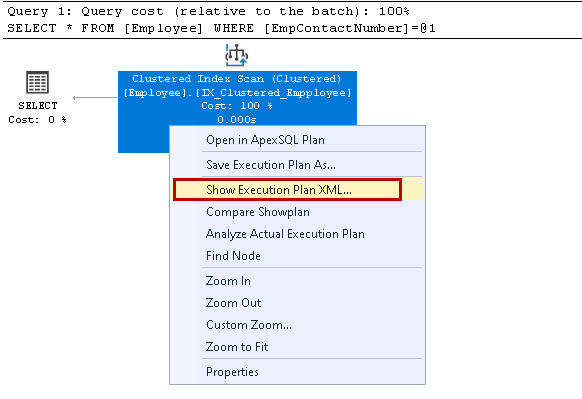
It opens the XML execution plan in the new query window. Here, we notice that it uses the clustered index key and reads the individual rows for retrieving the result:

Let’s insert a few more records in the Employee table using the following script:
|
1 2 3 |
Insert into Employee values(4,'Manoj',38,7892145637) Insert into Employee values(5,'John',33,7900654123) Insert into Employee values(6,'Priya',18,9603214569) |
We have six employees’ records in this table. Now, execute the select statement again for retrieving employee records with a specific contact number:
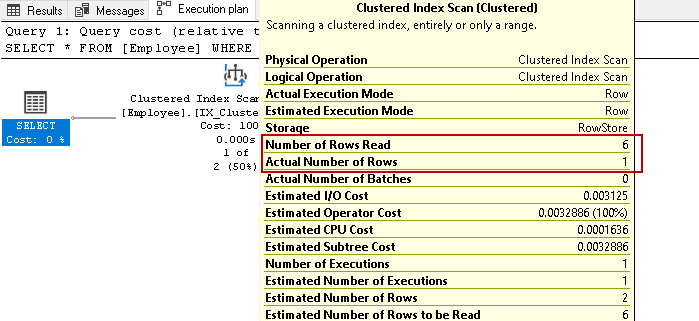
It again scans all six rows for the result based on the specified condition. Imagine we have millions of records in the table. If SQL Server has to read all index key rows, it would be a resource and time-consuming task.
We can represent clustered index (not actual representation) in the B-tree format as per the following image:

In the previous query, SQL Server reads the root node page and retrieves each leaf node page and row for data retrieval.
Now Let’s create a unique non-clustered index in SQL Server on the Employee table on the EmpContactNumber column as the index key:
|
1 |
CREATE UNIQUE NONCLUSTERED INDEX IX_NonClustered_Employee ON dbo.Employee(EmpContactNumber); |
Before we explain this index, rerun the SELECT statement and view the actual execution plan:
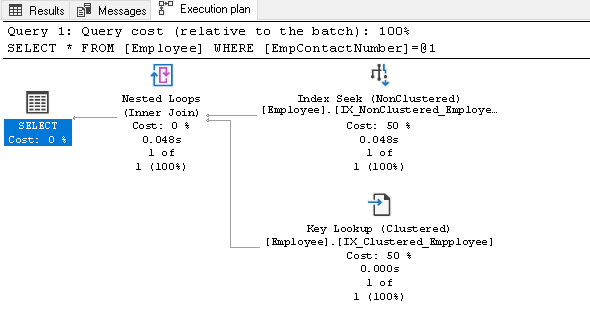
In this execution plan, we can see two components:
- Index Seek (NonClustered)
- Key Lookup (Clustered)
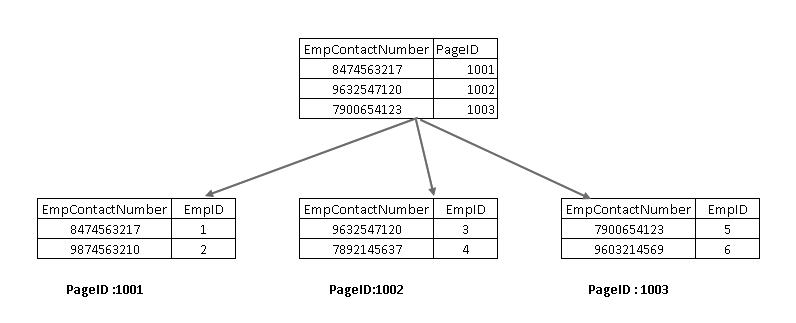
To understand these components, we need to look at a non-clustered index in SQL Server design. Here, you can see that the leaf node contains the non-clustered index key (EmpContactNumber) and clustered index key (EmpID):
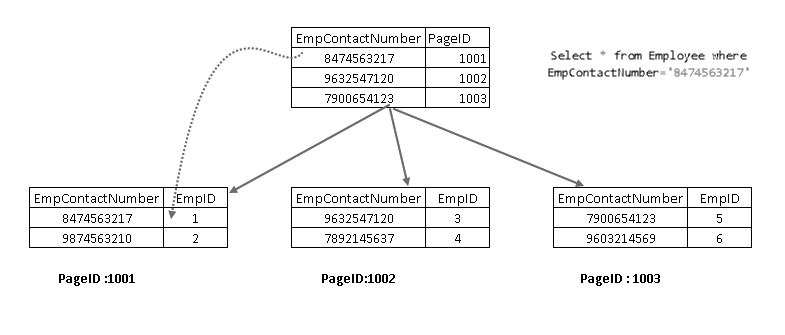
Now, if rerun the SELECT statement, it traverses using the non-clustered index key and points to a page with clustered index key:
It shows that it retrieves the record with a combination of clustered index key and non-clustered index key. You can see complete logic for the SELECT statement as shown below:
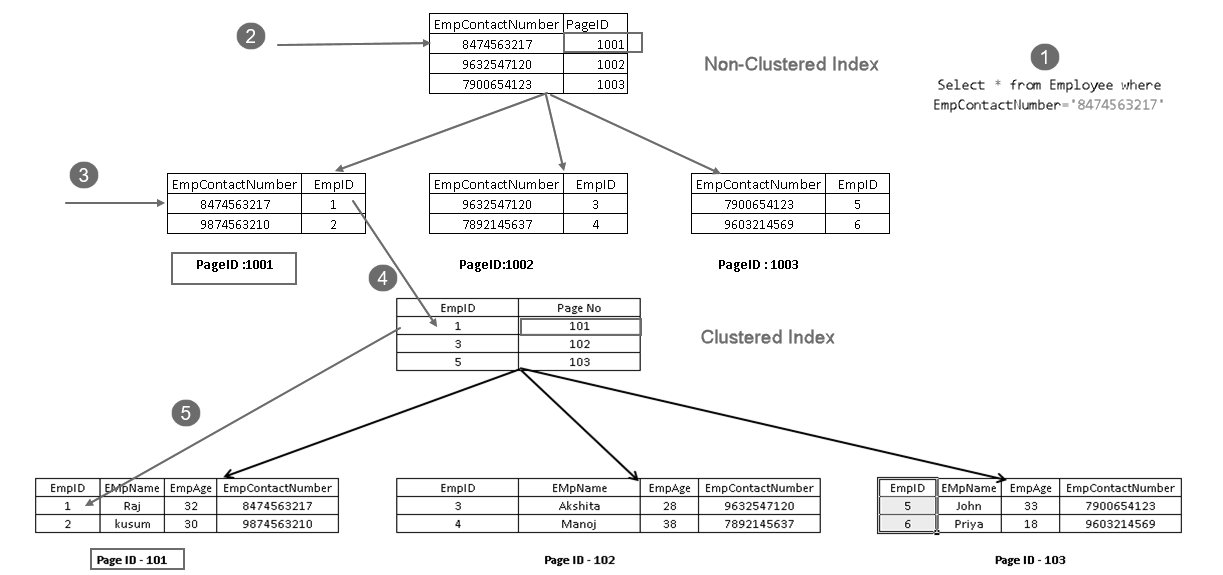
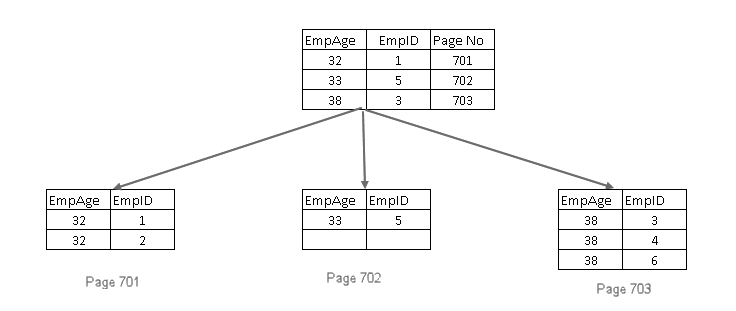
- A user executes a select statement to find employee records matching with a specified contact number
- Query Optimizer uses a non-clustered index key and finds out the page number 1001
- This page consists of a clustered index key. You can see EmpID 1 in the above image
- SQL Server finds out page no 101 that consists of EmpID 1 records using the clustered index key
- It reads the matching row and returns the output to the user
Previously, we saw that it reads six rows to retrieve the matching row and returns one row in the output. Let’s look at an execution plan using the non-clustered index:

Non-unique non-clustered index in SQL Server
We can have multiple non-clustered indexes in a SQL table. Previously, we created a unique non-clustered index on the EmpContactNumber column.
Before creating the index, execute the following query so that we have duplicate value in the EmpAge column:
|
1 2 3 |
Update Employee set EmpAge=32 where EmpID=2 Update Employee set EmpAge=38 where EmpID=6 Update Employee set EmpAge=38 where EmpID=3 |
Let’s execute the following query for a non-unique non-clustered index. In the query syntax, we do not specify a unique keyword, and it tells SQL Server to create a non-unique index:
|
1 |
CREATE NONCLUSTERED INDEX NCIX_Employee_EmpAge ON dbo.Employee(EmpAge); |
As we know, the key of an index should be unique. In this case, we want to add a non-unique key. The question arises: How will SQL Server make this key as unique?
SQL Server does the following things for it:
- It adds the clustered index key in the leaf and non-leaf pages of the non-unique non-clustered index
- If the clustered index key is also non-unique, it adds a 4-byte uniquifier so that the index key is unique
Include non-key columns in non-clustered index in SQL Server
Let’s look at the following actual execution plan again of the following query:
|
1 2 |
Select * from Employee where EmpContactNumber='8474563217' |
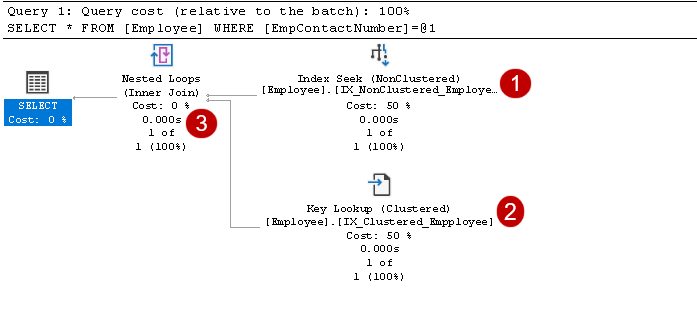
It includes index seek and key lookup operators, as shown in the above image:
- The index seeks: SQL Query Optimizer uses an index seek on the non-clustered index and fetches EmpID, EmpContactNumber columns
-
In this step, Query Optimizer uses key lookup on the clustered index and fetches values for EmpName and EmpAge columns
-
In this step, Query Optimizer uses the nested loops for each row output from the non-clustered index for matching with the clustered index row
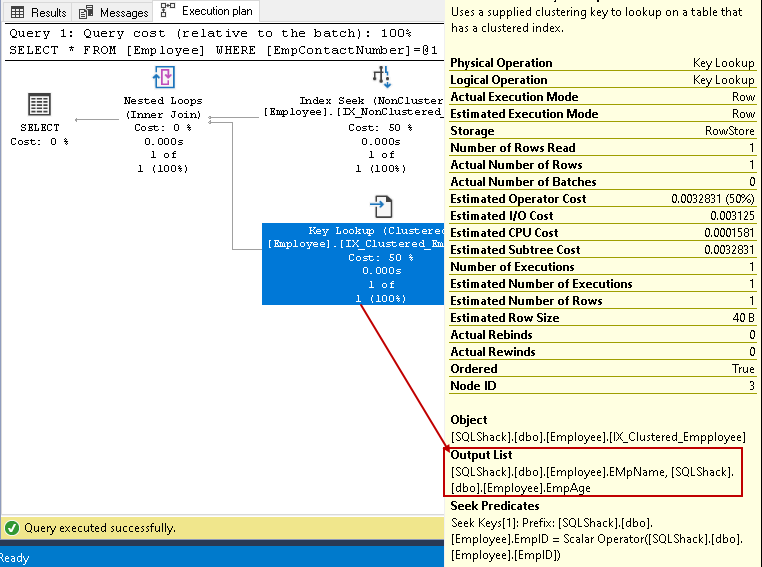
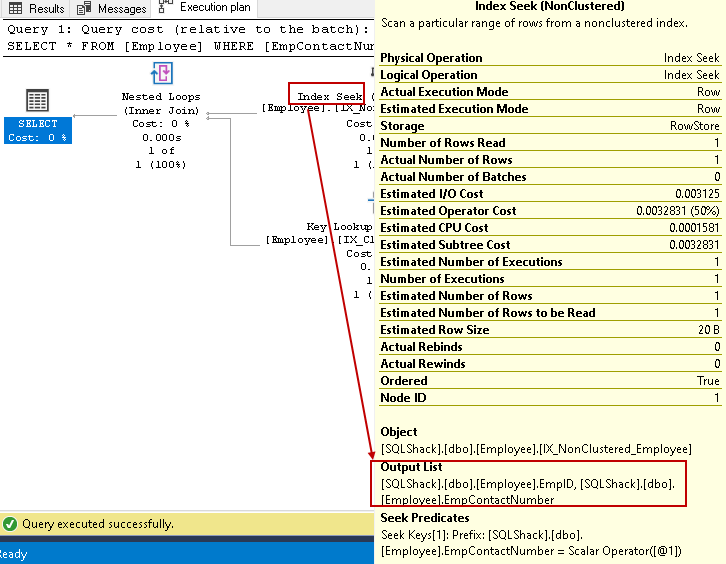
The nested loop might be a costly operator for large tables. We can reduce the cost using the non-clustered index non-key columns. We specify the non-key column in the non-clustered index using the index clause.
Let’s drop and created the non-clustered index in SQL Server using the included columns:
|
1 2 3 4 5 6 7 |
DROP INDEX [IX_NonClustered_Employee] ON [dbo].[Employee] GO CREATE UNIQUE NONCLUSTERED INDEX [IX_NonClustered_Employee] ON [dbo].[Employee] ( [EmpContactNumber] ASC ) INCLUDE(EmpName,EmpAge) |
Included columns are part of the leaf node in an index tree. It helps to fetch the data from the index itself instead of traversing further for data retrieval.
In the following image, we get both included columns EmpName and EmpAge as part of the leaf node:
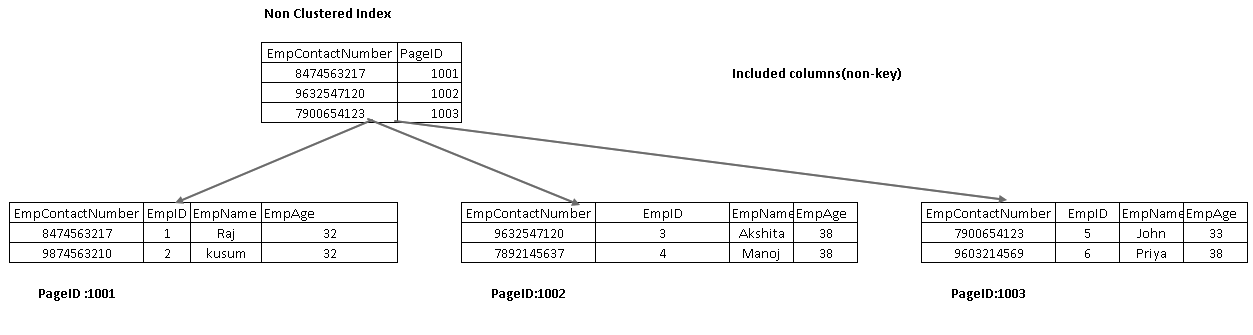
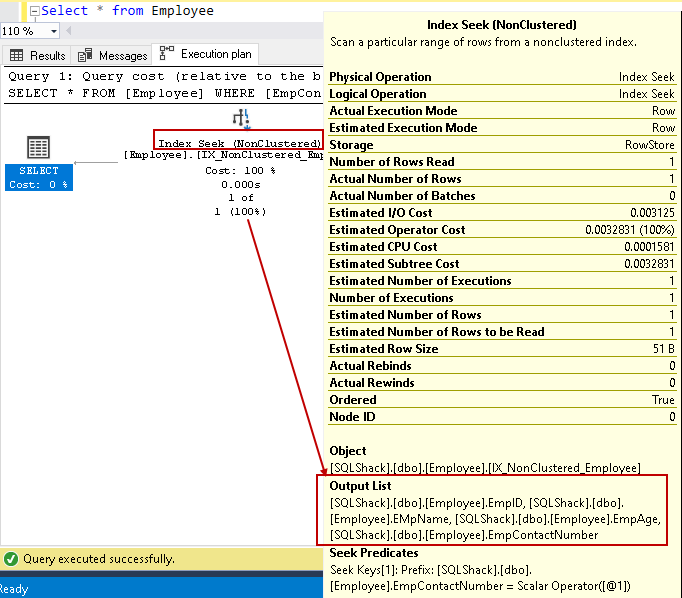
Re-execute the SELECT statement and view the actual execution plan now. We do not have key lookup and nested loop in this execution plan:

Let’s hover the cursor over the index seek and view the output columns list. SQL Server can find all the columns using this non-clustered index seek:
We can improve query performance using the covering index with the help of included non-key columns. However, it does not mean we should all non-key columns in the index definition. We should be careful in index design and should test the index behavior before deployment in the production environment.
Conclusion
In this article, we explored the non-clustered index in SQL Server and its usage in combination with the clustered index. We should carefully design the index as per the workload and query behavior.

I am the author of the book "DP-300 Administering Relational Database on Microsoft Azure". I published more than 650 technical articles on MSSQLTips, SQLShack, Quest, CodingSight, and SeveralNines.
I am the creator of one of the biggest free online collections of articles on a single topic, with his 50-part series on SQL Server Always On Availability Groups.
Based on my contribution to the SQL Server community, I have been recognized as the prestigious Best Author of the Year continuously in 2019, 2020, and 2021 (2nd Rank) at SQLShack and the MSSQLTIPS champions award in 2020.
Personal Blog: https://www.dbblogger.com
I am always interested in new challenges so if you need consulting help, reach me at rajendra.gupta16@gmail.com
View all posts by Rajendra Gupta
- Understanding PostgreSQL SUBSTRING function - September 21, 2024
- How to install PostgreSQL on Ubuntu - July 13, 2023
- How to use the CROSSTAB function in PostgreSQL - February 17, 2023