
This article gives you an insight into SQL Server Index properties in SSMS.
Introduction
We can create indexes in SQL Server using both GUI and t-SQL method. Once we create an index using t-SQL, we specify the index name, key columns, included columns, filter to create it. We do not consider other index options. While on the other hand, if you use the SSMS GUI method, it gives many options to you. You might get overwhelmed with all SSMS index options. In this article, we will take a look at all SSMS index properties.
Let’s first create a table for demo and use the CREATE INDEX command for the clustered index on it. In the index script, we specified the clustered index key, and it creates the index with all default options:
|
1 2 3 4 5 |
CREATE TABLE Test (id INT, name VARCHAR(50) ); CREATE CLUSTERED INDEX ix_1 ON Test(id); |
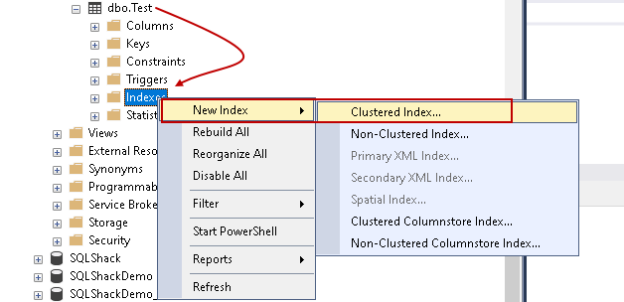
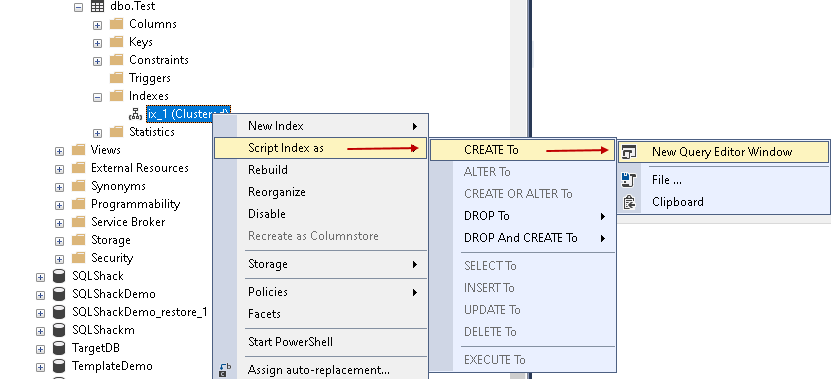
To verify the index, navigate to source database -> Tables -> dbo.Test-> Indexes. Right-click on the index -> Script Index as -> Create To -> New Query Editor Window:
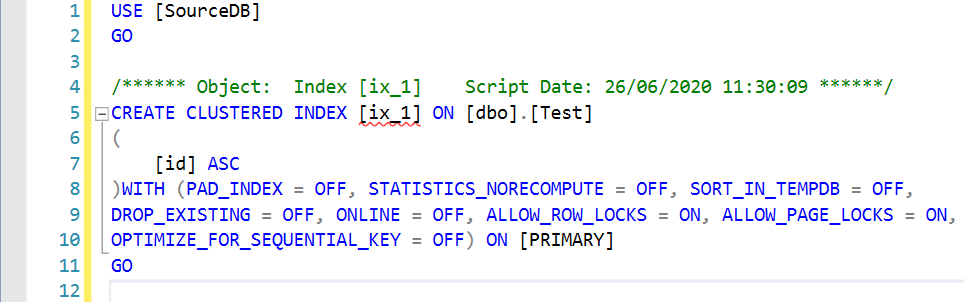
It gives you the following script with all default configurations:
We can see these index properties while creating the index using SSMS Index GUI. For this purpose, right-click on the earlier index and drop it.
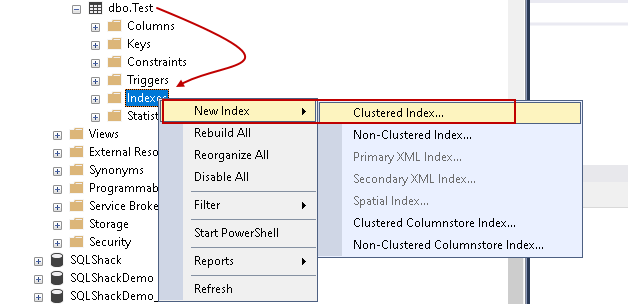
Now, we will create the same clustered index using SSMS. First right-click on the Indexes and choose the required index type such as clustered index, Non-Clustered index, XML index, Clustered Columnstore index, Non-Clustered columnstore index:
- Note: If you are not sure about Index type, you can refer Performance tuning – Indexes section at SQLShack to learn all about SQL Server Indexes
General tab
It gives you the following create new index window.
Table Name
It gives you the table name for which we want to create an index.
SQL Server Index Name
By default, it generates a unique name for the index in the format of [Index type]_YYYYMMDD-hhmmss. You should use a proper format to easily identify the index, its type, table, key from the index name. for example, you can use format such as [IX_Index name_tablename_keycolumn].
Index type
As we have chosen to create a clustered index, it shows that in the index type. You can put a check on the UNIQUE to create a Unique Clustered Index:
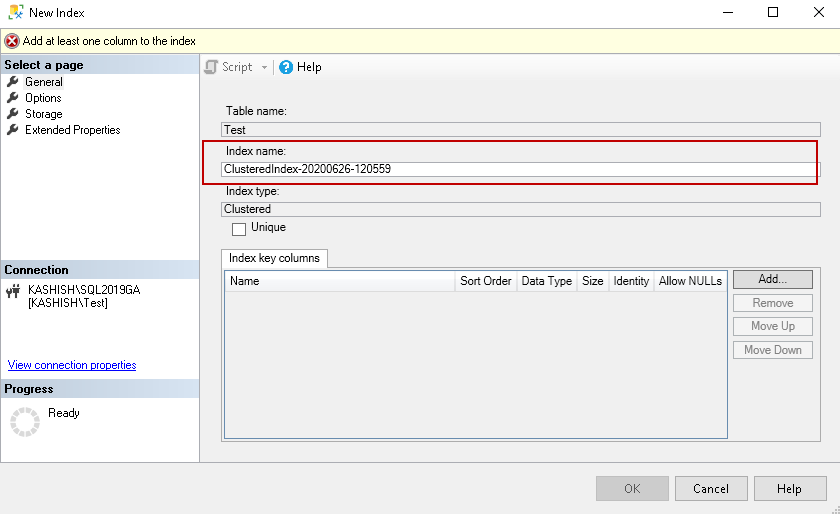
Index Key Columns
It is the key column in a table for which we want to create the index. Click on Add, and you can see all columns of the selected table:
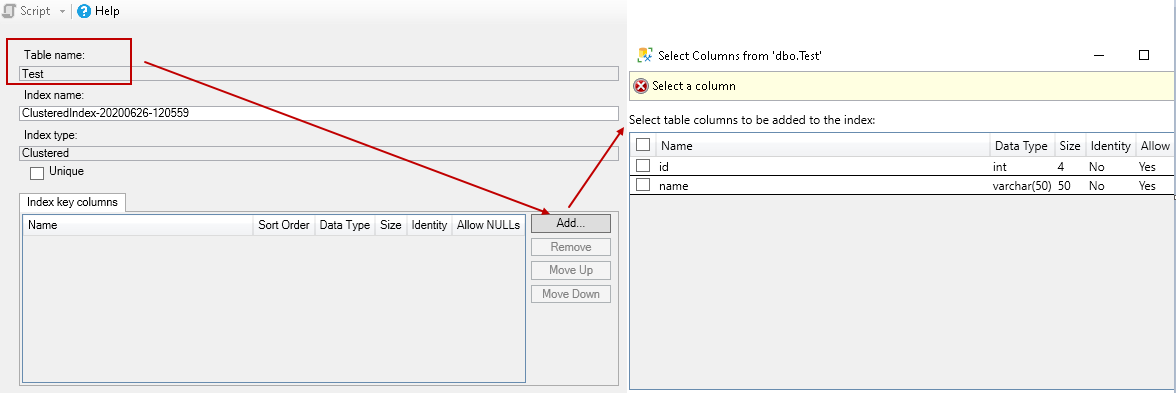
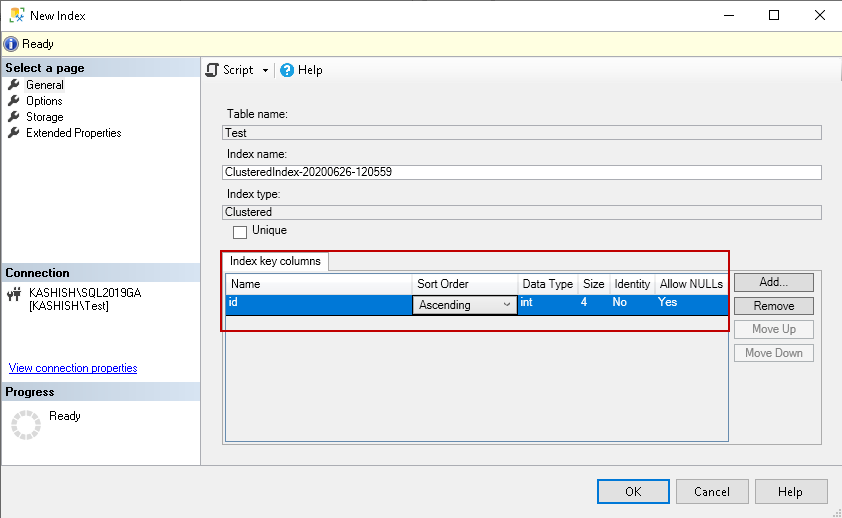
Once you select the key column, it shows you on the general page. By default, it shows an ascending order for the key column. You can change the value as descending if required.
Note: You should analyze whether ascending or descending order is useful for your workloads:

SQL Server Index Options page
Click on the options page to set various index properties of a specified index. You can see that each property has its default value.
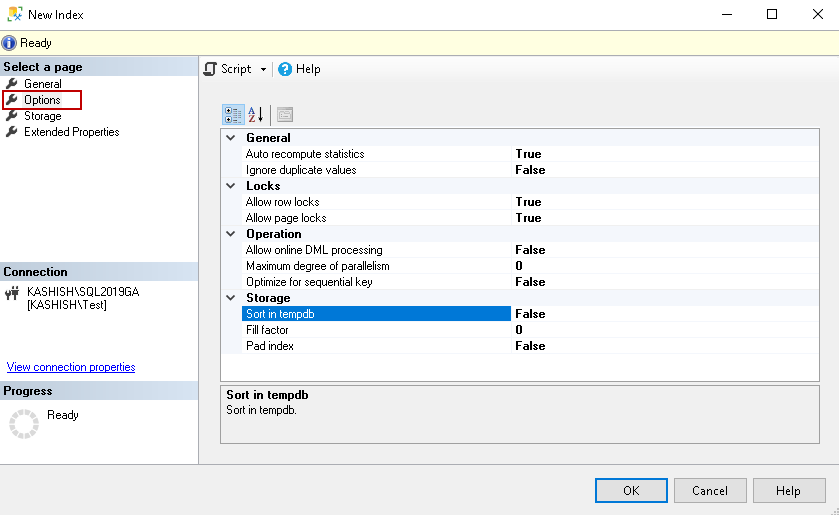
It is an important aspect to know these properties before creating the index. You should be careful in changing the default value for an index as it might change your index behavior. Let’s understand these options.
Auto recompute statistics
You should have updated statistics in SQL Server so that query optimizer can create the optimized execution plan. This property defines whether you require SQL Server to update index statistics automatically or not. By default, it is enabled. You should leave this option to default unless you update them regularly.
By default, SQL Server uses the following mechanism for automatically update statistics.
SQL Server 2014 or below: It uses a threshold for the percentage number of rows modified.
- Table cardinality<500 : Update statistics for every 500 modifications
- Table cardinality>500: Update statistics for every 500 + 20 % of the total number of rows in the table at the time of statistics computation
SQL Server 2016 and above: It uses a decreasing, dynamic statistics update threshold, but the database should be compatibility level 130 or more. It uses the following formula for calculating the threshold:
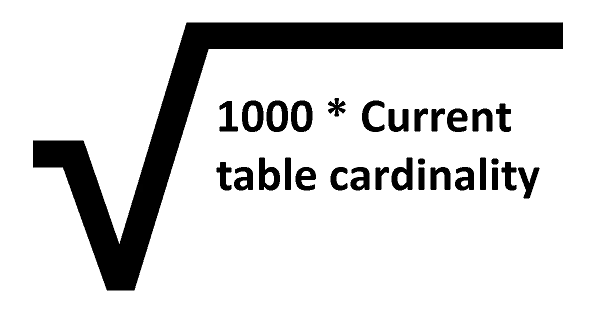
As per the above formula, for a table with 1 million rows, it updates the statistics for every 31622 modifications:
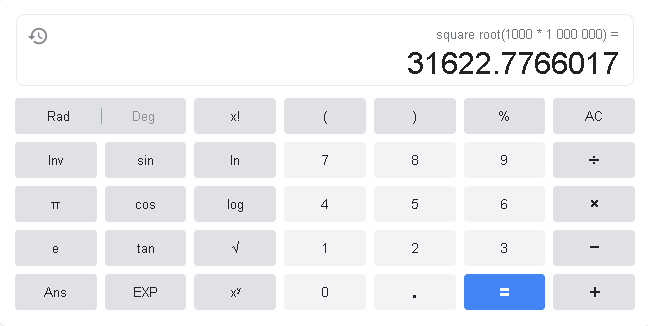
You can go through Microsoft docs for detailed knowledge of SQL Server statistics.
Ignore Duplicate Values
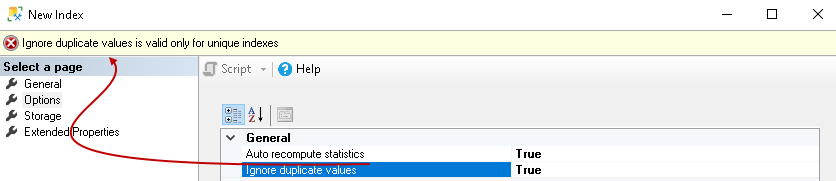
It defines whether we can have a duplicate key in the index column or not. By default, it is set to False which means if someone tries to insert a duplicate key value, SQL Server generates an error message and rollbacks the transaction.
If we set it to true, SQL Server will ignore the duplicate key and does not give any error message. We can use ignore duplicate values with unique indexes. You get an error message for non-unique indexes:
You can understand about unique index in the article, Difference between Unique Indexes and Unique Constraints in SQL Server.
Allow row locks and Allow page locks
We can specify to allow or not row-level locking or page lock using these properties. You should not make changes to this property unless you are confident about it. Turning if off might improve index maintenance, but it causes blockings. You should allow SQL Server to choose the locking mechanism efficiently.
Allow Online DML processing
In a 24*7 OLTP environment, it is challenging to get a window for index maintenance. By default, you face blockings while you perform index maintenance. SQL Server enterprise edition provides options for online index maintenance.
You can set this option to true so that Index rebuild is online and it does not block other user’s queries. Users can perform data manipulations queries during an index maintenance operation.
You can refer to the article Maintaining SQL Server indexes for more details for online index maintenance.
Maximum degree of parallelism for SQL Server Index
Usually, we set MAXDOP at the SQL Server instance to limit the number of processors for parallel query execution. By default, its value is 0 which shows it can use all available processors. Sometimes, you face issues due to parallelism, and you want to limit the processors. You can set this property either at the instance level or in the index definition. You can specify the value in this property to create an index that uses specific MAXDOP.
Optimize For Sequential Key
This option is available in SQL Server 2019. It solves the performance issues due to concurrent inserts. We can use this option OPTIMIZE_FOR_SEQUENTIAL_KEY to control the rate at which new heads can request latch. It also provides high throughput.
You can refer article Behind the Scenes on OPTIMIZE_FOR_SEQUENTIAL_KEY to learn about the internals of Optimize For Sequential Key in SQL Server Index.
Sort in Tempdb
We can store the sort results for index creation in the TempDB using this property. By default, SQL Server uses the database in which index lies. Usually, we store TempDB on a faster disk IO throughput so we can set this property to true and it uses TempDB for its sort operation. You should consider the storage requirement as well as the TempDB to use this configuration.
SQL Server Index Fill Factor
Fill factor in an index that how much the leaf level page of each index can be for SQL Server. For example, if we specify the fill factor value is 90, it means that 10 percent of each leaf node page will be empty for future data inserts. We can specify a value between 1 and 100 in this. By default, it shows value 0 that is equivalent to 100. You should consider changing the value with attention as it could cause page splits that impact database performance.
You can refer article Specify Fill Factor for an Index for more details.
Pad index
Pad index is similar to a fill factor except that it applies to the non-leaf levels of an index. This index configuration is available only when we set the fill factor as well. By default, it is turned off.
Storage
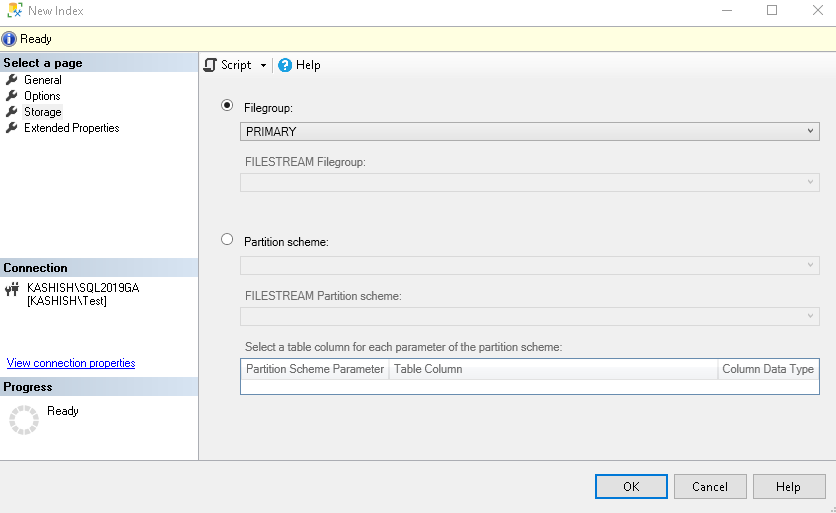
Click on the Storage tab in the new index. Here, you can define the filegroup for the index along with the partition scheme. You can use the partition scheme if you have defined partitions in SQL Server table.
By default, SQL Server stores all data and indexes in a primary filegroup. As the best practices, you should create a new filegroup to store indexes. If you have created the filegroup, you can select the filegroup from the drop-down:
Conclusion
In this article, we explored various configurations in the SSMS for SQL Server Index. We should be aware of all these index properties and configure them as per our workload requirement.
You should not change the default value directly in a production database. It should be implemented in non-prod instance with proper load testing.

I am the author of the book "DP-300 Administering Relational Database on Microsoft Azure". I published more than 650 technical articles on MSSQLTips, SQLShack, Quest, CodingSight, and SeveralNines.
I am the creator of one of the biggest free online collections of articles on a single topic, with his 50-part series on SQL Server Always On Availability Groups.
Based on my contribution to the SQL Server community, I have been recognized as the prestigious Best Author of the Year continuously in 2019, 2020, and 2021 (2nd Rank) at SQLShack and the MSSQLTIPS champions award in 2020.
Personal Blog: https://www.dbblogger.com
I am always interested in new challenges so if you need consulting help, reach me at rajendra.gupta16@gmail.com
View all posts by Rajendra Gupta
- Understanding PostgreSQL SUBSTRING function - September 21, 2024
- How to install PostgreSQL on Ubuntu - July 13, 2023
- How to use the CROSSTAB function in PostgreSQL - February 17, 2023