
Gaining experience in SQL query tuning can be very difficult and complicated for database developers or administrators. For this reason, in this article, we will work on a case study and we are going to learn how we can tune its performance step by step. In this fashion, we will understand well how to approach query performance issues practically.
Pre-requirements
In this article, we will use the Adventureworks2017 sample database. At the same time, we will also use the Create Enlarged AdventureWorks Tables script to obtain an enlarged version of the SalesOrder and SalesOrderDetail tables because the size of this database is not sufficient to perform performance tests. After installation of the Adventureworks2017 database, we can execute the table enlarging script.
Case Study: SQL Query tuning without creating a new index
Imagine that, you are employed as a full-time database administrator in a company and this company is still using SQL Server 2017 version. You have taken an e-mail from the software development team and they are complaining about the following query performance in their e-mail.
|
1 2 3 4 5 6 7 8 9 |
SELECT p.ProductID,p.ProductNumber , p.Name,s.CarrierTrackingNumber , h.AccountNumber, h.CreditCardApprovalCode, dbo.[ufnGetStock](p.ProductID) AS Stock , CONCAT(SUBSTRING(CarrierTrackingNumber,1,4), SUBSTRING(p.Class,1,4)) FROM Sales.SalesOrderDetailEnlarged s INNER JOIN Production.Product p ON s.ProductID = p.ProductID INNER JOIN Sales.SalesOrderHeaderEnlarged h ON h.SalesOrderID=s.SalesOrderID WHERE s.OrderQty > 2 AND LEN(CreditCardApprovalCode)>10 ORDER BY CONCAT(SUBSTRING(CarrierTrackingNumber,1,4), SUBSTRING(p.Class,1,4)),ProductID DESC |
Your objective is to improve the performance of the above query without creating a new index on the tables but you can re-write the query.
The first step of the SQL query tuning: Identify the problems
Firstly, we will enable the actual execution plan in the SSMS and execute the problematic query. Using the actual execution plan is the best approach to analyze a query because the actual plan includes all accurate statistics and information about a query. However, if a query is taking a long time, we can refer to the estimated execution plan. After this explanation, let’s examine the select operator of the execution plan.
- Note: If you are a newbie or beginner about analyzing the execution plan you can check out the following articles:
The ElapsedTime attribute indicates the execution time of a query and we figure out from this value that this query is completed in 142 seconds. For this query, we also see the UdfElapsedTime attribute and it indicates how long the database engine deal to invoke the user-defined functions in the query. Particularly for this query, these two elapsed times are very close so we can deduce that the user-defined function might cause a problem.
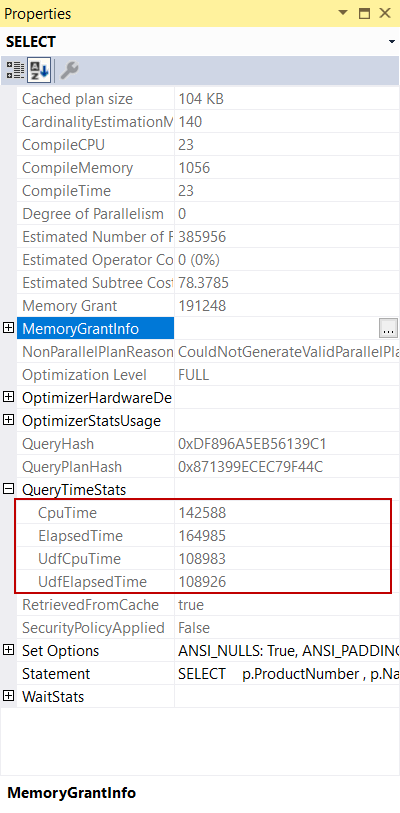
Another point to take into consideration for this query is parallelism. For this query, the Estimated Subtree Cost value exceeds the Cost Threshold for Parallelism setting of the server but the query optimizer does not generate a parallel execution plan because of the scalar function. The scalar functions prevent the query optimizer to generate a parallel plan.
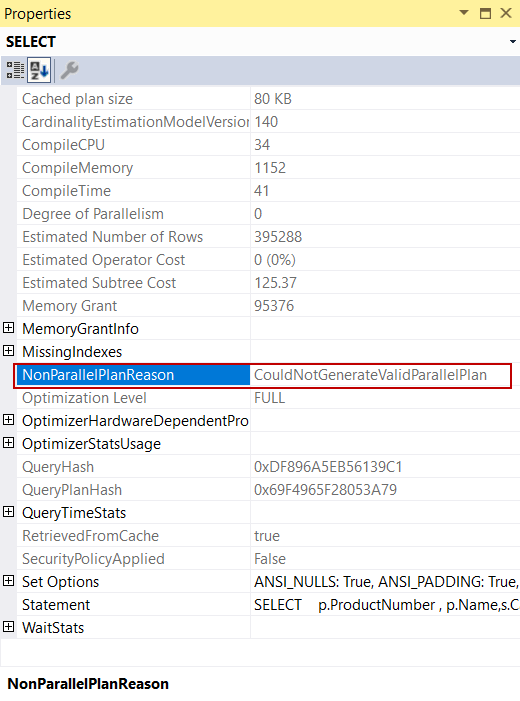
The last problem with this query is the TempDB spill issue and this problem is indicated with the warning signs in the execution plan.
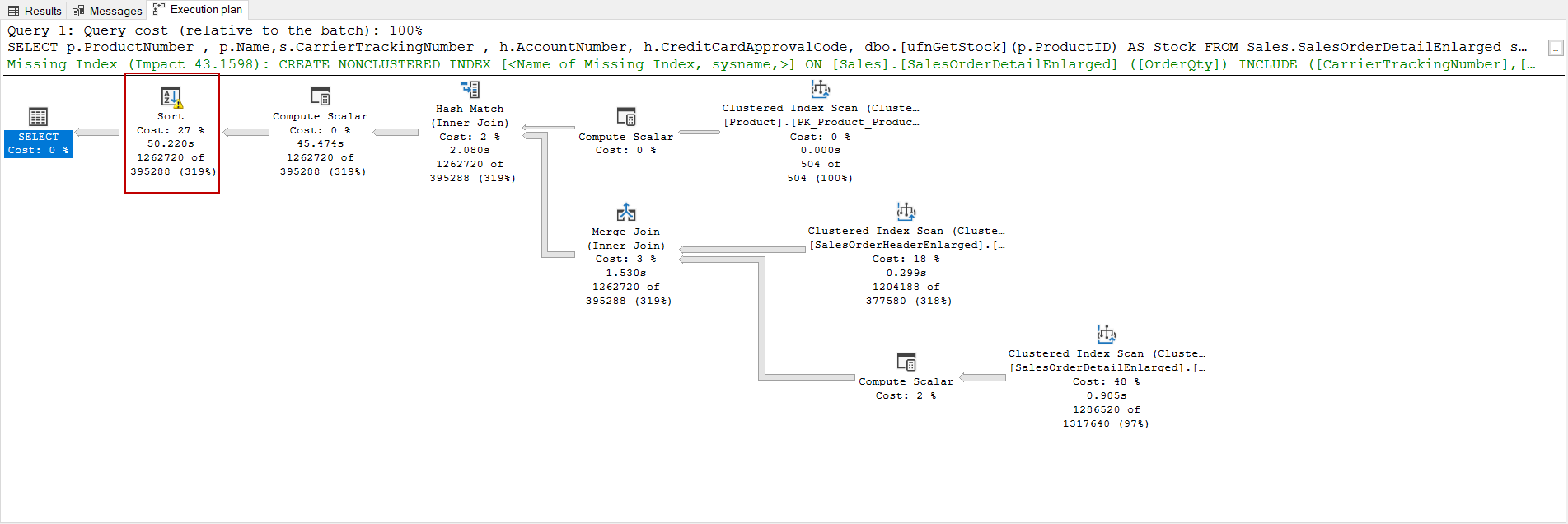
Outdated statistics, poorly written queries, ineffective index usage might be caused to tempdb spill issues.
Improve performance of the scalar-function in a query
The scalar-functions can be a performance killer for the queries, and this discourse would be exactly true for our sample query. Scalar-functions are invoked for every row of the result set by the SQL Server. Another problem related to the scalar-functions is the black box problem because the query optimizer has no idea about the code inside the scalar-function, due to this issue the query optimizer does not consider the cost impact of the scalar functions on the query.
A new feature has been announced with SQL Server 2019 and can help overcome most of the performance issues associated with scalar functions. The name of this feature is Scalar UDF Inlining in SQL Server 2019. On the other hand, if we are using earlier versions of SQL Server, we should adapt the scalar function code explicitly to the query if it is possible. The common method is to transform the scalar-function into a subquery and implement it to query with the help of the CROSS APPLY operator. When we look at the inside of the ufnGetStock function, we can see that it is summing the quantity of products according to the ProductId only a specific LocationId column.
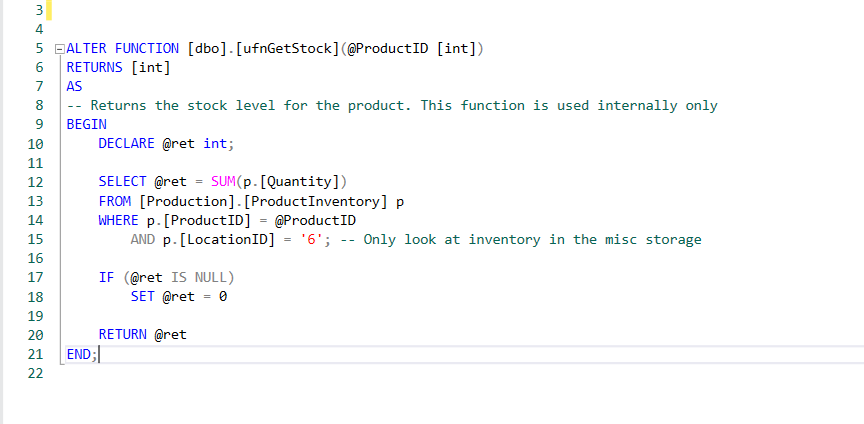
We can transform and implement the ufnGetStock scalar-function as shown below. In this way, we ensure that our sample query can run in parallel and will be faster than the first version of the query.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
SELECT p.ProductID,p.ProductNumber , p.Name,s.CarrierTrackingNumber , h.AccountNumber, h.CreditCardApprovalCode, Warehouse.Stock AS Stock FROM Sales.SalesOrderDetailEnlarged s INNER JOIN Production.Product p ON s.ProductID = p.ProductID INNER JOIN Sales.SalesOrderHeaderEnlarged h ON h.SalesOrderID=s.SalesOrderID CROSS APPLY ( SELECT ISNULL(SUM(Production.[Quantity]),0) AS Stock FROM [Production].[ProductInventory] Production WHERE Production.[ProductID] = p.ProductID AND Production.[LocationID] = '6' ) AS Warehouse WHERE s.OrderQty > 2 AND LEN(CreditCardApprovalCode)>10 ORDER BY CONCAT(SUBSTRING(CarrierTrackingNumber,1,4), SUBSTRING(p.Class,1,4)) , p.ProductID DESC |
This query has taken 71 seconds to complete but when we look at the execution plan, we see a parallel execution plan. However, the tempdb spill issue is persisted. This case obviously shows that we need to expend more effort to overcome the tempdb spill problem and try to find out new methods.
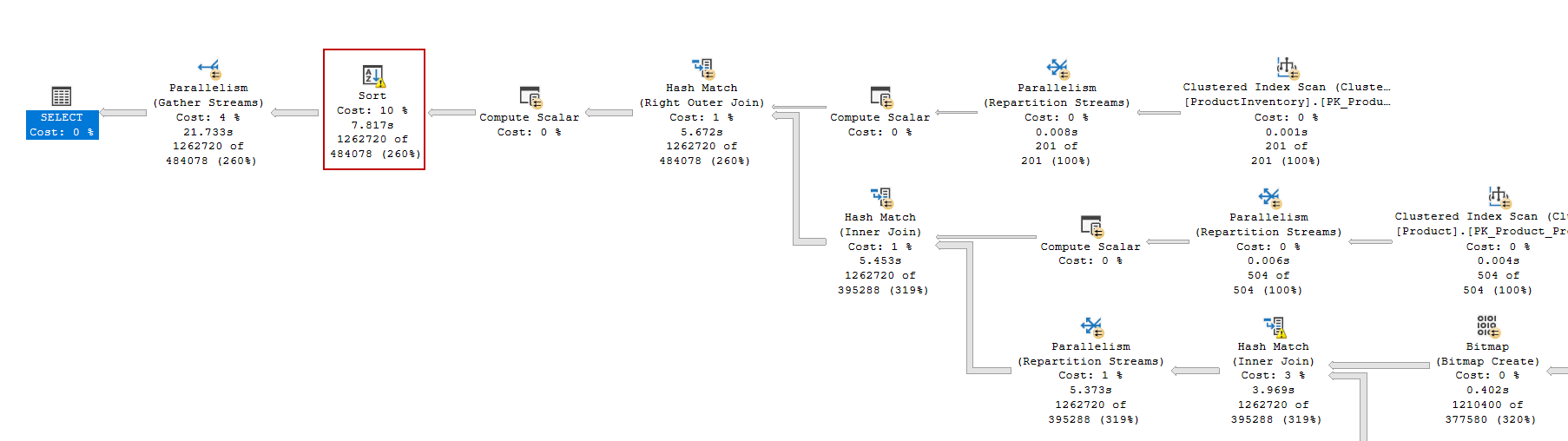
Think more creative for SQL query tuning
To get rid of the tempdb spill issue, we will create a temp table and insert all rows to this temporary table. The temporary tables offer very flexible usage so we can add a computed column instead of the LEN function which is placed on the WHERE clause. The insert query will be as below.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
IF OBJECT_ID(N'tempdb..#PerfmonTable') IS NOT NULL BEGIN DROP TABLE #PerfmonTable END CREATE TABLE #PerfmonTable( [ProductID] [int] NOT NULL, [ProductNumber] [nvarchar](25) NOT NULL, [Name] [nvarchar](50) NOT NULL, [CarrierTrackingNumber] [nvarchar](25) NULL, [AccountNumber] [nvarchar](15)NULL, [CreditCardApprovalCode] [varchar](15) NULL, [Stock] [int] NOT NULL, [SortParameter] [nvarchar](6) NOT NULL, SmallApp AS ISNULL(LEN(CreditCardApprovalCode),0) PERSISTED ) GO INSERT INTO #PerfmonTable WITH(TABLOCK) SELECT p.ProductID , p.ProductNumber , p.Name, s.CarrierTrackingNumber , h.AccountNumber, h.CreditCardApprovalCode, Warehouse.Stock, CONCAT(SUBSTRING(CarrierTrackingNumber,1,4), SUBSTRING(Class,1,4)) AS SortParameter FROM Sales.SalesOrderDetailEnlarged s INNER JOIN Production.Product p ON s.ProductID = p.ProductID INNER JOIN Sales.SalesOrderHeaderEnlarged h ON h.SalesOrderID=s.SalesOrderID CROSS APPLY ( SELECT ISNULL(SUM(Production.[Quantity]),0) AS Stock FROM [Production].[ProductInventory] Production WHERE Production.[ProductID] = p.ProductID AND Production.[LocationID] = '6' ) AS Warehouse WHERE s.OrderQty > 2 DELETE FROM #PerfmonTable WHERE SmallApp <=10 |
When we analyze this query we can see the usage of the TABLOCK hint after the INSERT statement. The usage purpose of this keyword is to enable a parallel insert option. So that, we can gain more performance. This situation can be seen in the execution plan.
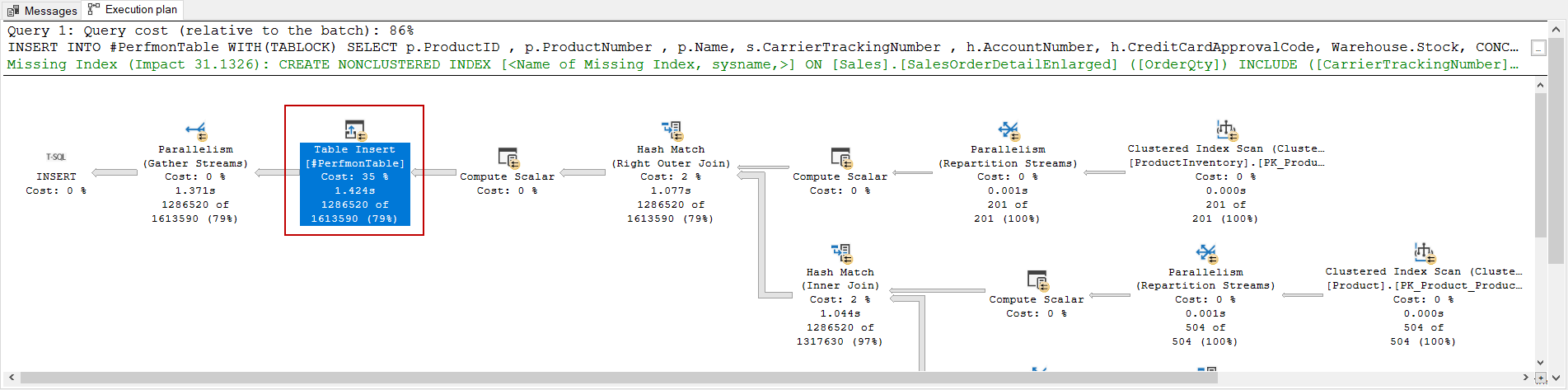
In this way, we have inserted the 1.286.520 rows into the temporary table in just one second. However, the temporary table still holds more data than we need because we haven’t filtered the CreditCard ApprovalCode column values with character lengths are greater than 10 in the insert operation. At this point, we will make a little trick and delete the rows whose are character length smaller than 10 or equal to 10. After the insert statement, we will add the following delete statement so that we will obtain the all qualified records in the temp table.
|
1 |
DELETE FROM #PerfmonTable WHERE SmallApp <=10 |
SQL Query tuning: Using indexes to improve sort performance
When we design an effective index for the queries which include the ORDER BY clause, the execution plan does not require to sort the result set because the relevant index returns the rows in the required order. Moving from this idea, we can create a non-clustered index that satisfies sort operation requirements. The important point about this SQL query tuning practice is that we have to get rid of the sort operator and the generated index advantage should outweigh the disadvantage. The following index will be helping to eliminate sort operation in the execution plan.
|
1 2 3 4 5 |
CREATE NONCLUSTERED INDEX IX_Sort ON #PerfmonTable(SortParameter,ProductID DESC) INCLUDE ([ProductNumber],[Name], [CarrierTrackingNumber],[AccountNumber], [CreditCardApprovalCode],Stock) |
Now, we execute the following query and then examine the execution plan of the select query.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 |
IF OBJECT_ID(N'tempdb..#PerfmonTable') IS NOT NULL BEGIN DROP TABLE #PerfmonTable END CREATE TABLE #PerfmonTable( [ProductID] [int] NOT NULL, [ProductNumber] [nvarchar](25) NOT NULL, [Name] [nvarchar](50) NOT NULL, [CarrierTrackingNumber] [nvarchar](25) NULL, [AccountNumber] [nvarchar](15)NULL, [CreditCardApprovalCode] [varchar](15) NULL, [Stock] [int] NOT NULL, [SortParameter] [nvarchar](6) NOT NULL, SmallApp AS ISNULL(LEN(CreditCardApprovalCode),0) PERSISTED ) GO INSERT INTO #PerfmonTable WITH(TABLOCK) SELECT p.ProductID , p.ProductNumber , p.Name, s.CarrierTrackingNumber , h.AccountNumber, h.CreditCardApprovalCode, Warehouse.Stock, CONCAT(SUBSTRING(CarrierTrackingNumber,1,4), SUBSTRING(Class,1,4)) AS SortParameter FROM Sales.SalesOrderDetailEnlarged s INNER JOIN Production.Product p ON s.ProductID = p.ProductID INNER JOIN Sales.SalesOrderHeaderEnlarged h ON h.SalesOrderID=s.SalesOrderID CROSS APPLY ( SELECT ISNULL(SUM(Production.[Quantity]),0) AS Stock FROM [Production].[ProductInventory] Production WHERE Production.[ProductID] = p.ProductID AND Production.[LocationID] = '6' ) AS Warehouse WHERE s.OrderQty > 2 DELETE FROM #PerfmonTable WHERE SmallApp <=10 CREATE NONCLUSTERED INDEX IX_Sort ON #PerfmonTable(SortParameter,ProductID DESC) INCLUDE ([ProductNumber],[Name], [CarrierTrackingNumber],[AccountNumber], [CreditCardApprovalCode],Stock) SELECT ProductID,[ProductNumber],[Name],[CarrierTrackingNumber],[AccountNumber] ,[CreditCardApprovalCode],Stock FROM #PerfmonTable ORDER BY SortParameter DESC |

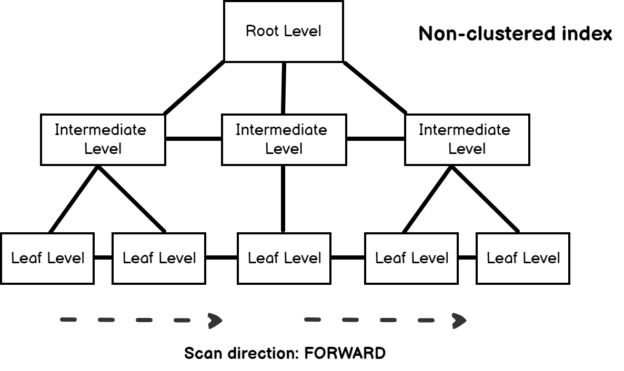
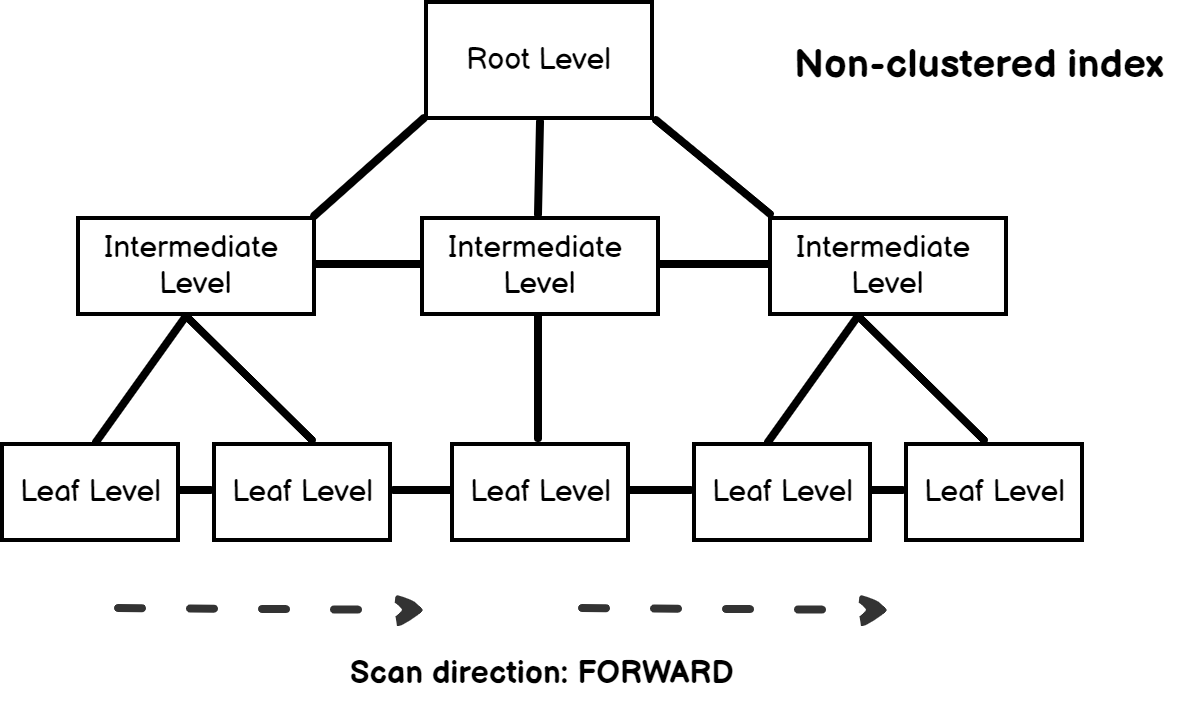
As we can see in the execution plan, the database engine used the IX_Sort index to access the records and it also did not require to use of a sort operator because the rows are the sorted manner. In the properties of the index scan operator, we see an attribute that name is Scan Direction.
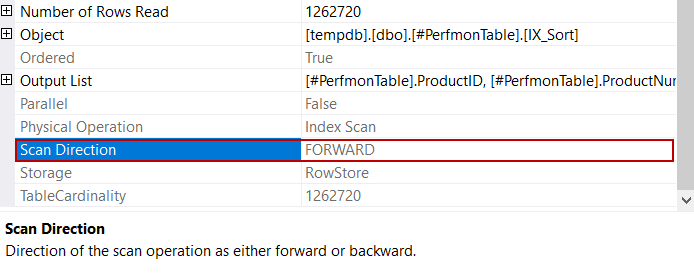
The scan direction attribute explains that SQL Server uses the b-tree structure to read the rows from beginning to the end at the leaf levels. At the same time, this index helps us to overcome the tempdb spill issue.
Finally, we see that the query execution time was reduced from 220 seconds to 33 seconds.
Conclusion
In this article, we learned practical details about SQL query tuning and these techniques can help when you try to solve a query performance problem. In the case study, the query which has a performance problem contained 3 main problems. These are:
- Scalar-function problem
- Using a serial execution plan
- Tempdb spill issue
At first, we transformed the scalar-function into a subquery and implement it to query with the CROSS APPLY operator. In the second step, we eliminated the tempdb spill problem to use a temporary table. Finally, the performance of the query has improved significantly.

Most of his career has been focused on SQL Server Database Administration and Development. His current interests are in database administration and Business Intelligence. You can find him on LinkedIn.
View all posts by Esat Erkec
- SQL Performance Tuning tips for newbies - April 15, 2024
- SQL Unit Testing reference guide for beginners - August 11, 2023
- SQL Cheat Sheet for Newbies - February 21, 2023