
This article targets the beginners and gives an introduction of the clustered index in SQL Server.
Introduction
An index plays a crucial role in SQL Server query performance. Consider a book library with thousands of books.

You want to search for a specific book that contains the keyword “adventure” in the title. The books in the library are unorganized.
- You need to fetch each book from the shelf, read it and put it back if it does not satisfy your requirements
- In a big library, it might take you a few days to find a single book
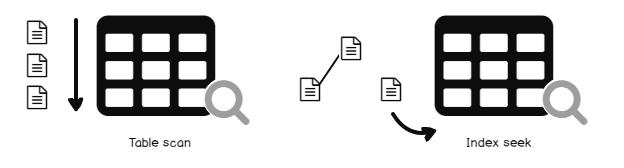
Suppose this library is a SQL table so in SQL Server terms, scanning all books in a library is known as table (index) scan.
Suppose you find two books for the “adventure” keyword and now you are interested in searching for another keyword in that book. Each book contains 2,000 pages.
Is it possible for you to search for a particular keyword in a book without reading it?
In a book, we use indexes for locating the page where you can find keywords. In SQL Server terms, we call it an index seek operation.

We can visualize the table scan and index seek operation as per the following image:
We have mainly two types of indexes in SQL Server:
- Clustered index(CI)
- Non-clustered index
Overview of a Clustered index in SQL Server
SQL Server creates the index in a B-tree structure. SQL Server organizes data in this structure to quickly search for the required data instead of a table scan.
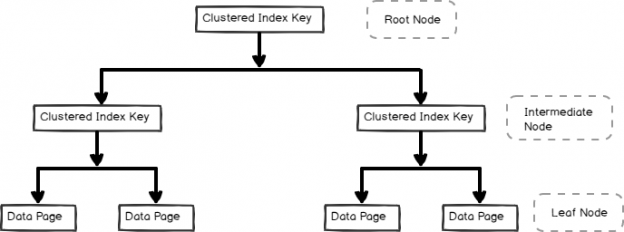
As shown in the following image, we have three levels in a B-tree structure index:
Root Node
It is a top node and consists of a pointer for the intermediate index pages or leaf node (data pages).
Intermediate level
It consists of index key values along with pointers to the next intermediate level pages or the leaf data pages. It depends upon the size of the data for the number of intermediate levels.
Lead Node
It consists of actual data pages. Consider this as a point where actual data is stored in a clustered index in SQL Server.
Let’s imagine this b-tree for our library example. Suppose we have 10,000 books in the library and created CI on the bookid column of the library table:
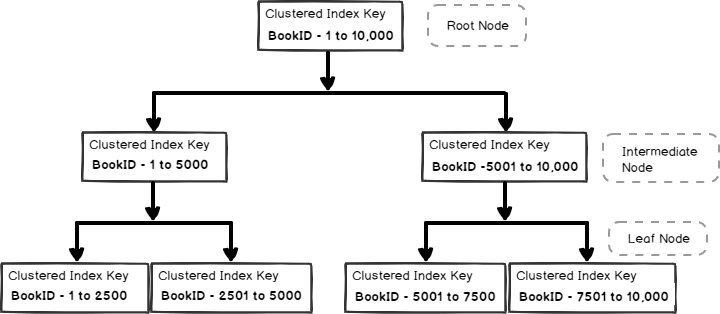
As shown in the above image, we defined the index on the bookid column of the library table. Now, if we want to retrieve a specific book say bookid 7579, SQL Server reads the following pages:
- Root page: Root page points SQL Server for the intermediate node 5001 to 10,000
- Intermediate Node: SQL Server reads the intermediate index page and gets a pointer for the actual data page in the leaf node
- Leaf node: SQL Server reads the data page in the leaf node as per our requirement
As highlighted earlier, SQL Server reads the index page and returns the information. This process is known as Index seek. In certain situations, SQL Server reads all leaf-level data pages. It is known as an index scan. Undoubtedly, the index seek is faster than the index scan.
Create a Clustered index in SQL Server using SSMS
Let’s create a test table and create an index using SQL Server Management Studio GUI method:
|
1 2 3 4 5 6 |
CREATE TABLE dbo.bookstore (book_id INT NOT NULL, book_name VARCHAR(100) ); Insert into dbo.bookstore values(1,'Learn ABC of SQL Server') Insert into dbo.bookstore values(2,'Advanced troubleshooting step SQL Server') |
We do not have any index on the table. A table without a CI is known as the heap table. You can read more about heap tables, and its performance issue in the article Forwarded Records Performance issue in SQL Server.
Expand Databases and locate the table in which we want to define an index. Expand table and right-click on Indexes | New Index | Clustered Index:
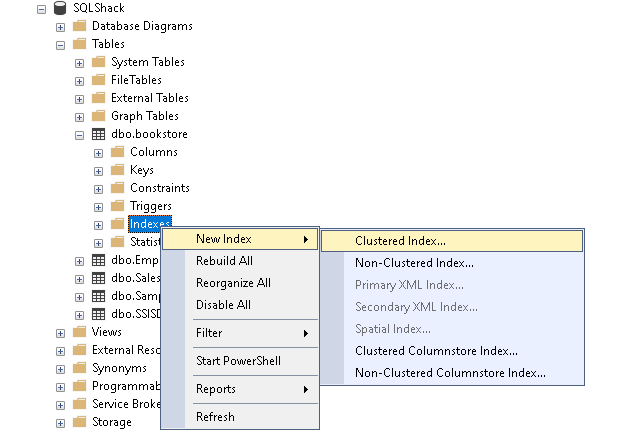
It opens the following New Index configuration window. It highlights an error message that at least one column should be there in an index:
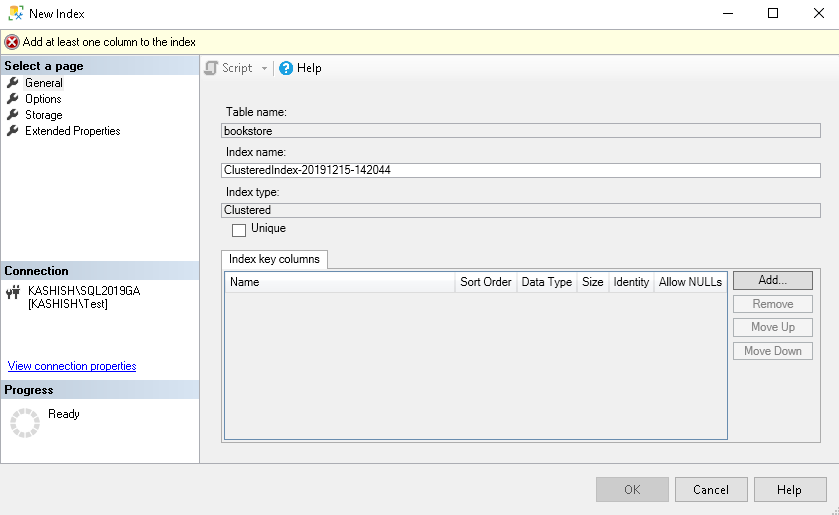
In the General page, it pre-populates the following pieces of information:
- Table name
- Index name: By default, it gives index name in the format of ClusteredIndex-YYYYMMDD-HHMMSS. We should avoid using this name for the index. We should use a familiar name and define a naming convention for all indexes in our databases
- Index Type: Clustered index
Specify an index name and click on Add to define the index key:
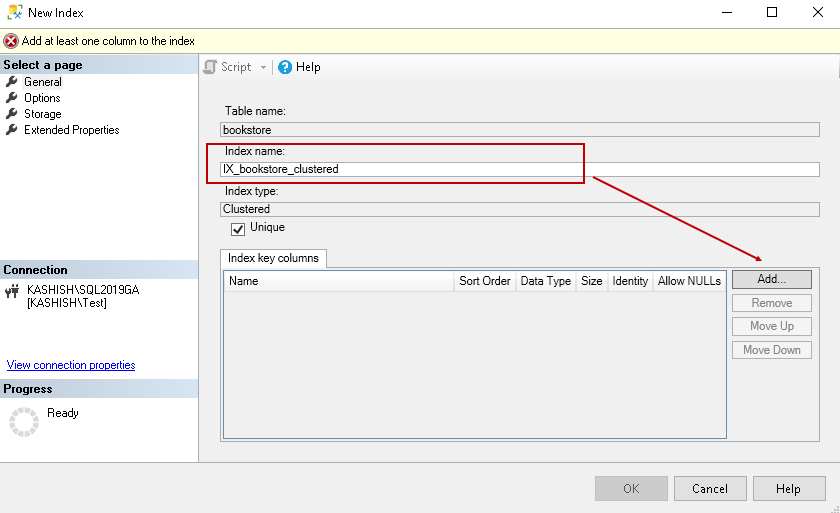
It opens following window to select CI key column on a specified table:
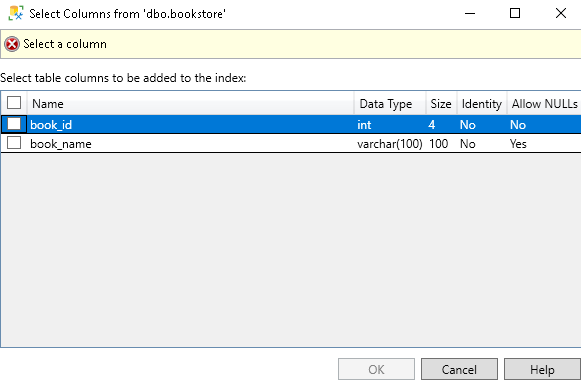
Once we select a column, it shows the status as Ready:
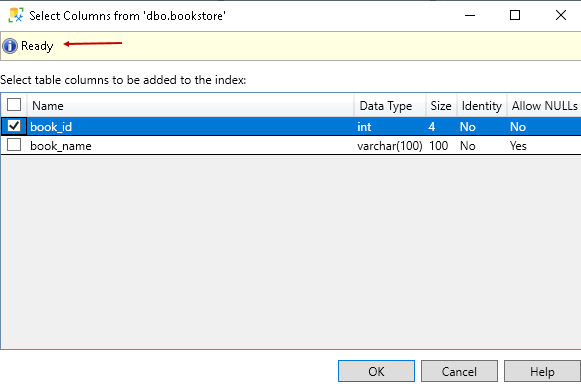
Click OK, and you can see the selected column in the Index key columns area:
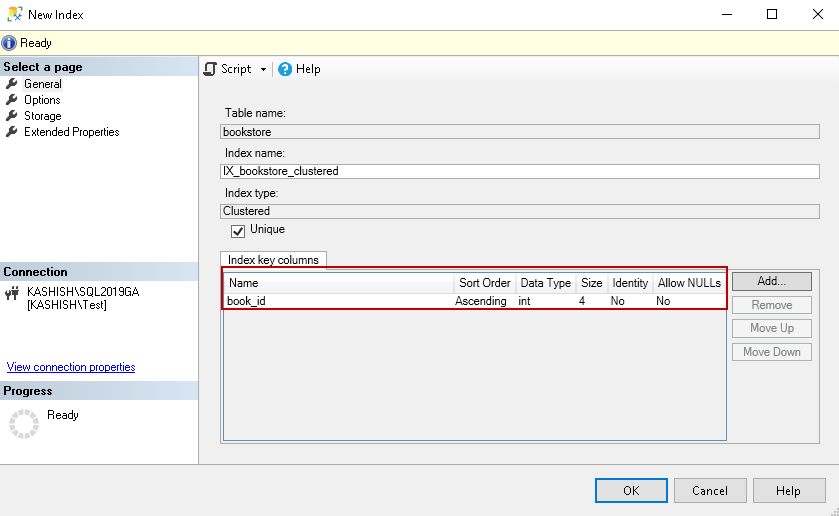
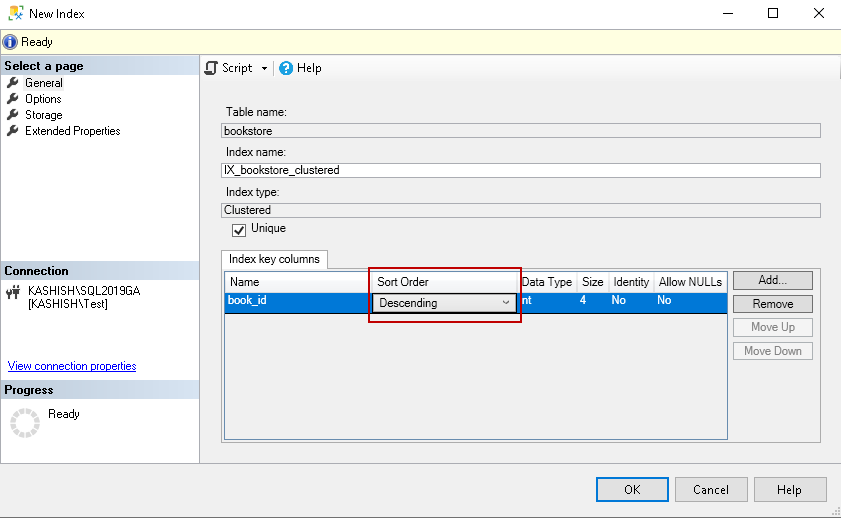
Under the Sort Order column, by default, it selects value Ascending. If we want to store the index key value in descending order, change the sort order as shown below:
Now click on Options, and you get a few configuration options for creating CI’s:
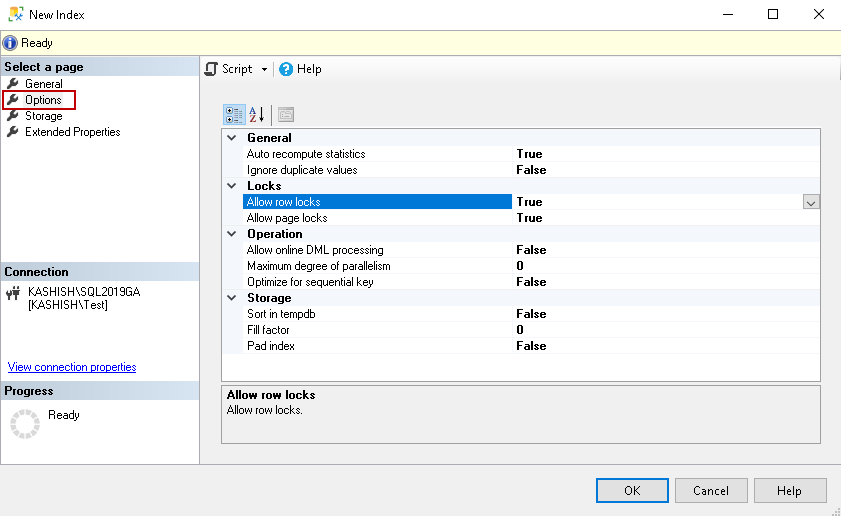
Few useful configuration options are as follows:
- Auto recompute statistics: By default, SQL Server recomputes the statistics based on pre-defined thresholds. We should not change its value unless required
- Ignore duplicate values: Default value is false. We specify index behaviour for duplicate rows
- IGNORE_DUP_KEY OFF: it gives an error message for duplicate row insertion
- IGNORE_DUP_KEY ON: It ignores any duplicate data insertion and gives a warning message
- Allow online DML processing: Using this option, we can allow concurrent users to access the table during the index operation. It is useful for a busy OLTP environment for performing online index maintenance
- Maximum degree of parallelism: We can limit the processors for parallel plan execution using this. We should make changes to this with proper testing
- Sort in tempdb: We can specify this option for asking SQL Server to sort results during index creation in the tempdb. By default, SQL Server uses the source database in which the table exists
- Fill factor: We can define a fill factor for the index. If we have specified this fil factor during index creation, it overrides the default value of the fill factor set at the instance level
We have set the following options in my demo for the CI:
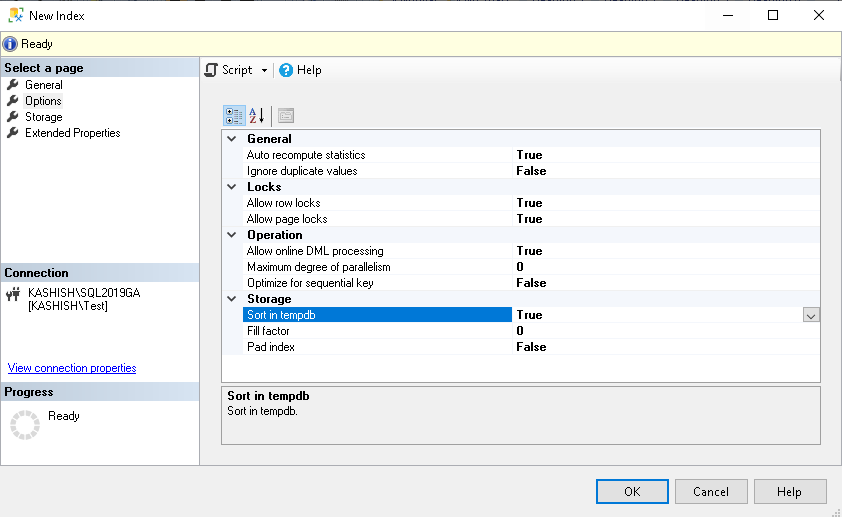
Storage
In the Storage page, we can specify the filegroup for the index. By default, it uses the filegroup in which the table exists:
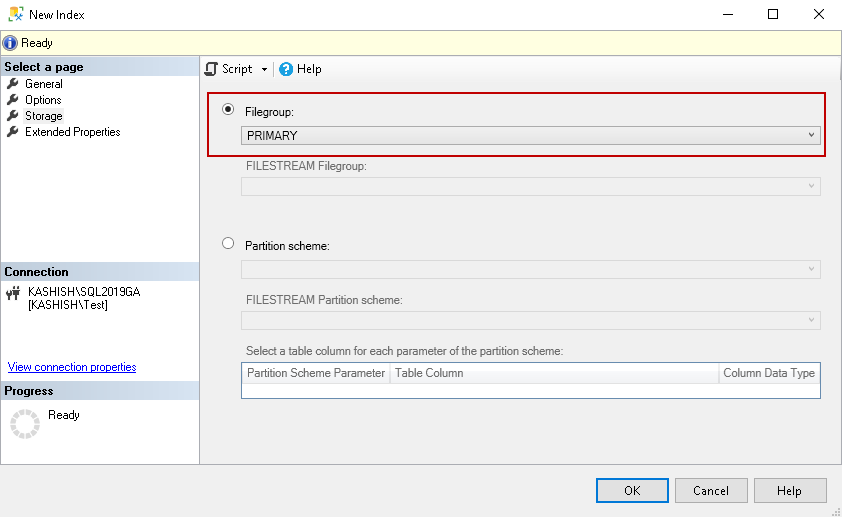
Once you have set all required configurations, we can click OK, and it creates the CI for you. It is always advisable to configure the inputs and generate a script for the index. For a large table, sometimes the GUI method does not work correctly.
Click on Script | New Query Editor Window as shown in the following image:
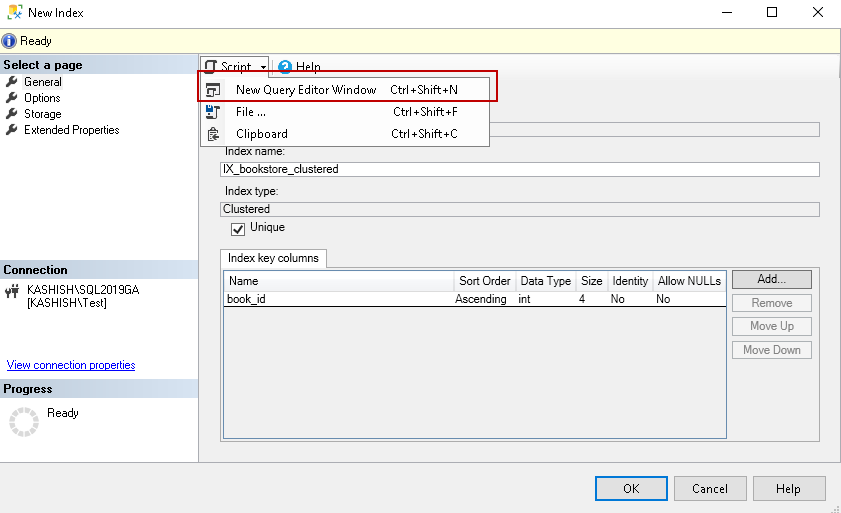
It gives the following script in a new query window:
|
1 2 3 4 5 6 |
CREATE UNIQUE CLUSTERED INDEX [IX_bookstore_clustered] ON [dbo].[bookstore] ( [book_id] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = ON, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = ON, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON, OPTIMIZE_FOR_SEQUENTIAL_KEY = OFF) ON [PRIMARY] |
Execute the script, and you can see the index in Object Explorer:
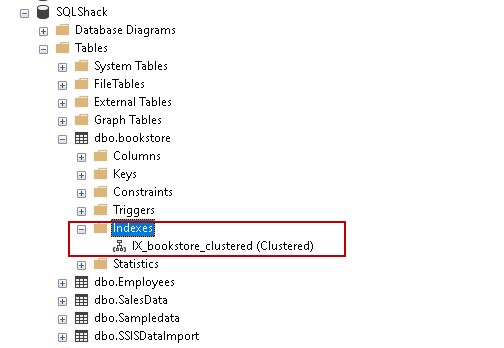
Note: If we define a primary key on a column, SQL Server automatically creates a CI on the primary key column
Check Clustered index levels in SQL Server
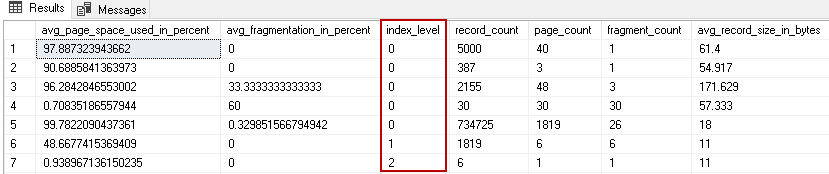
We can use DMV sys.dm_db_index_physical_stats for checking index fragmentation level, index levels for the CI. Insert a few records in the table and execute the following query:
|
1 2 3 4 5 6 7 8 9 10 |
SELECT avg_page_space_used_in_percent, avg_fragmentation_in_percent, index_level, record_count, page_count, fragment_count, avg_record_size_in_bytes FROM sys.dm_db_index_physical_stats(DB_ID('SQLShack'), OBJECT_ID('bookstore'), NULL, NULL, 'DETAILED'); GO |
In the following screenshot, we have two levels of an index:
View Execution plan for query with clustered index in SQL Server
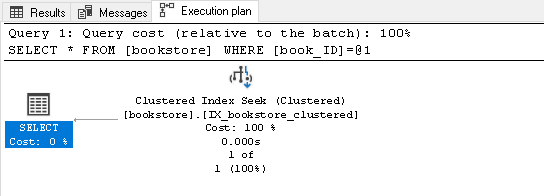
Let’s execute the following query and view the actual execution plan:
|
1 2 3 |
SELECT * INTO books_1 FROM bookstore; |
SQL Server uses index seek for retrieving the records from bookstore table:
Let’s create a backup table using the following query:
|
1 2 3 |
SELECT * INTO books_1 FROM bookstore; |
This backup table has a similar structure and data as of the main table. The only difference is that the backup table does not have any index while our main table contains CI on the books_ID column.
Let’s execute the following queries in a separate window and compare the execution plan:
|
1 2 3 4 5 6 7 |
SELECT * FROM book_1 WHERE book_ID = 10000; SELECT * FROM bookstore WHERE book_ID = 10000; |
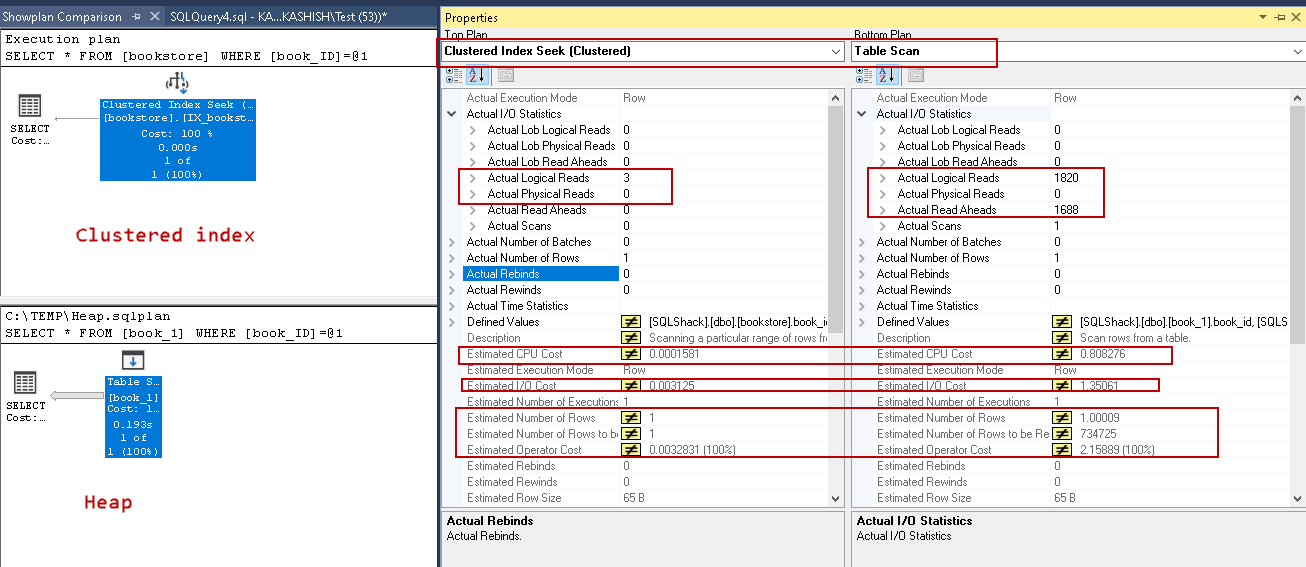
In the above screenshot, note the following differences. We can quickly figure out the performance comparison between a heap and a table with a clustered index:
|
Heap Table |
Table with a clustered index in SQL |
|
|
Logical Operation |
Table Scan |
Clustered seek |
|
Logical reads |
1820 |
3 |
|
Physical reads |
1688 |
0 |
|
Estimated number of rows to be read |
734725 |
1 |
|
Estimated operator cost |
2.15889 |
0.0032831 |
|
Estimated IO Cost |
1.35061 |
0.003125 |
|
Estimated CPU Cost |
0.808276 |
0.0001581 |
|
Number of rows read |
734725 |
1 |
Conclusion
In this article, we explored the clustered index in SQL Server along with GUI and t-SQL method to create it. We also learned the performance comparison between the heap and CI key table. You should define a CI as per the requirement for better query performance.

I am the author of the book "DP-300 Administering Relational Database on Microsoft Azure". I published more than 650 technical articles on MSSQLTips, SQLShack, Quest, CodingSight, and SeveralNines.
I am the creator of one of the biggest free online collections of articles on a single topic, with his 50-part series on SQL Server Always On Availability Groups.
Based on my contribution to the SQL Server community, I have been recognized as the prestigious Best Author of the Year continuously in 2019, 2020, and 2021 (2nd Rank) at SQLShack and the MSSQLTIPS champions award in 2020.
Personal Blog: https://www.dbblogger.com
I am always interested in new challenges so if you need consulting help, reach me at rajendra.gupta16@gmail.com
View all posts by Rajendra Gupta
- Understanding PostgreSQL SUBSTRING function - September 21, 2024
- How to install PostgreSQL on Ubuntu - July 13, 2023
- How to use the CROSSTAB function in PostgreSQL - February 17, 2023