
The SQL update statement is used to modify an existing record or records in a table and it is commonly widely used in databases applications. In this article, we will examine the update statement in terms of the performance perspective.
Best practices to improve SQL update statement performance
As with the select queries, some best practice suggestions can be made to improve the performance of SQL update statements:
- To optimize update operations, we should keep the transaction size as short as possible
- We need to consider the lock escalation mode of the modified table to minimize the usage of too many resources
- Analyzing the execution plan may help to resolve performance bottlenecks of the update query
- We can remove the redundant indexes on the table
- As possible as we need to use the WHERE clause in our update statements
- If it is possible we have to disable the delete triggers when we perform an update statement
- We should choose low peak usage times for major updates
Let’s tackle this “Analyzing the execution plan may help to resolve performance bottlenecks of the update query“ best practice with an example.
Understanding a very simple SQL update statement execution plan
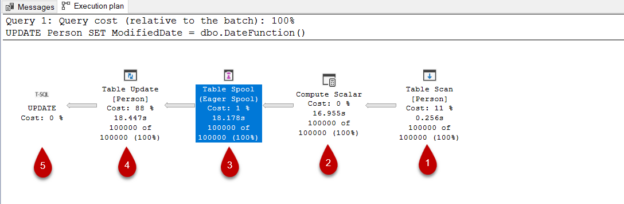
One of the most effective ways to understand SQL Server query performance details is to interpret the query plan. The query we will tackle below updates all rows in a heap table with a value that returned from a scalar-valued function. We will try to analyze and overcome its performance issue.
- Tip: A heap table is a table type that has not owned a clustered index so the data is not stored in a logical order
- Table Scan: The table scan operator begins to read the table at the beginning of the table and goes
through every row in the table. Includes the proper records into the result set based on matching criteria
- Tip: Sometimes the table scan and index scan operations can be confused but they have some differences. In the index scan operation, the data engine uses the existing index to read the data pages. Using the indexes for the data read operation reduces the number of I/O. Another point about the index scan operation is that usually, an index scan is less expensive than a table scan because it looks at sorted data
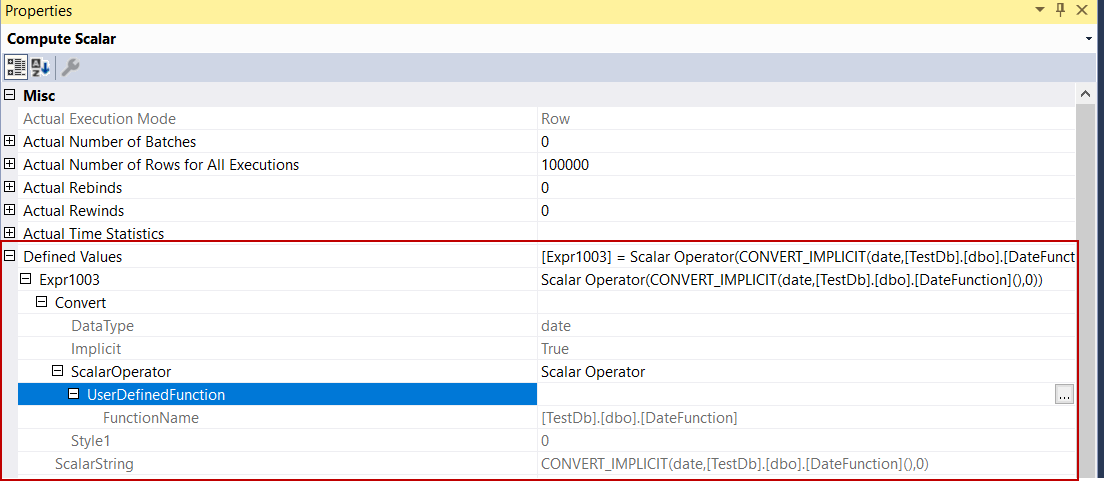
Compute Scalar: Compute scalar operator performs the scalar-valued function. When we look at the Defined Values attribute of this operator, we can see all details about it

- Table Spool (Eager Spool): This operator stores the data in tempdb until the data flow from the child (previous ) operator is completed and does not transfer it to the next operator. When the data flow is completed, the data is transferred to the next operator. Because of this working mechanism, the Eager Spool is a blocking operator. This operator is used when data is required to reuse during the execution of the query or prevent the query from the Halloween problem
- Table Update: This operator updates the input rows of the specified table
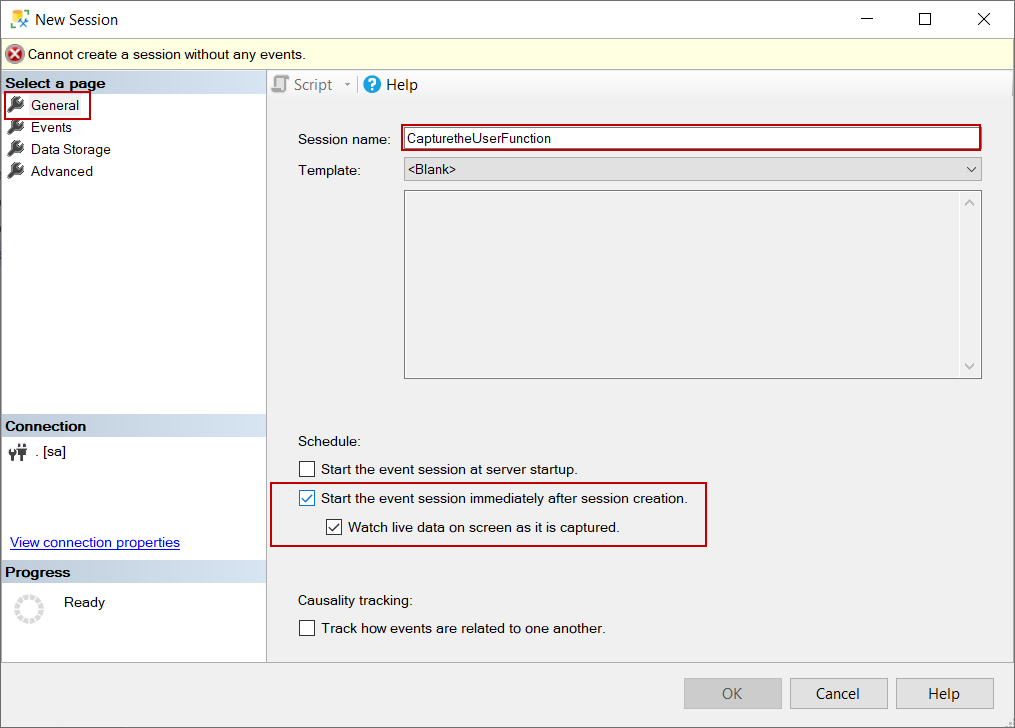
- Start the event session immediately after session creation
- Watch live data on screen as its captured
- Tip:The duration unit of the module_end event is a microsecond
- Tip: The trace flag 8649 and ENABLE_PARALLEL_PLAN_PREFERENCE query hint forces the optimizer to generate a parallel plan if it is possible
Use variable: We can assign the function result into a variable and then we can update the table to use this variable
123DECLARE @Dt AS DATETIMESELECT @Dt=dbo.Uf_LastModification()UPDATE Person SET ModifiedDate = @DtThis query only takes 1 second to complete
Change Database Complibity Level to 150: Scalar UDF Inlining feature announced with SQL Server 2019. Through this feature, the scalar function is converted into an expression or subquery and then adopted into the query automatically
- SQL Performance Tuning tips for newbies - April 15, 2024
- SQL Unit Testing reference guide for beginners - August 11, 2023
- SQL Cheat Sheet for Newbies - February 21, 2023
Firstly, with the help of the following query, we will create a Person table and will insert some 100k sample rows into this table.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
CREATE TABLE Person (PersonId INT IDENTITY(1,1) , PersonName NVARCHAR(100),ModifiedDate DATE) INSERT INTO Person VALUES(CONVERT(nvarchar(20),LEFT(REPLACE(NEWID(),'-',''),20)),GETDATE()) GO 100000 CREATE FUNCTION Uf_LastModification ( ) RETURNS DATETIME AS BEGIN DECLARE @ModificationDate DATETIME; SELECT TOP 1 @ModificationDate = ModifiedDate FROM Adventureworks2008R2.Sales.SalesOrderHeader ORDER BY ModifiedDate DESC; RETURN @ModificationDate; END; |
After creating the Person table, we will update the ModifiedDate column to use the Uf_LastModification scalar function.
|
1 2 3 |
SET STATISTICS IO ON GO UPDATE Person SET ModifiedDate = dbo.DateFunction() |
The Table Scan operator is chosen by the optimizer to read all data of the table. Actually, the optimizer has no other alternative to read the Person table data because the Person table is a heap, and it does not include any clustered index. Let’s start to read the execution plan right to left.
Finding the SQL update statement performance problem
When we look at this query execution plan, actually the problem is very simple because the scalar-valued function is invoked for each of the 100k rows every time so the query is slow down. We can use an extended event to capture to see the how many time the user-defined function is invoked. We can use the module_end event because it captures when a stored procedure or function is called and successfully completed. To create an extended event, we will right-click on the Sessions menu and select the New Session.
We will give a name to our event session and then we click the :
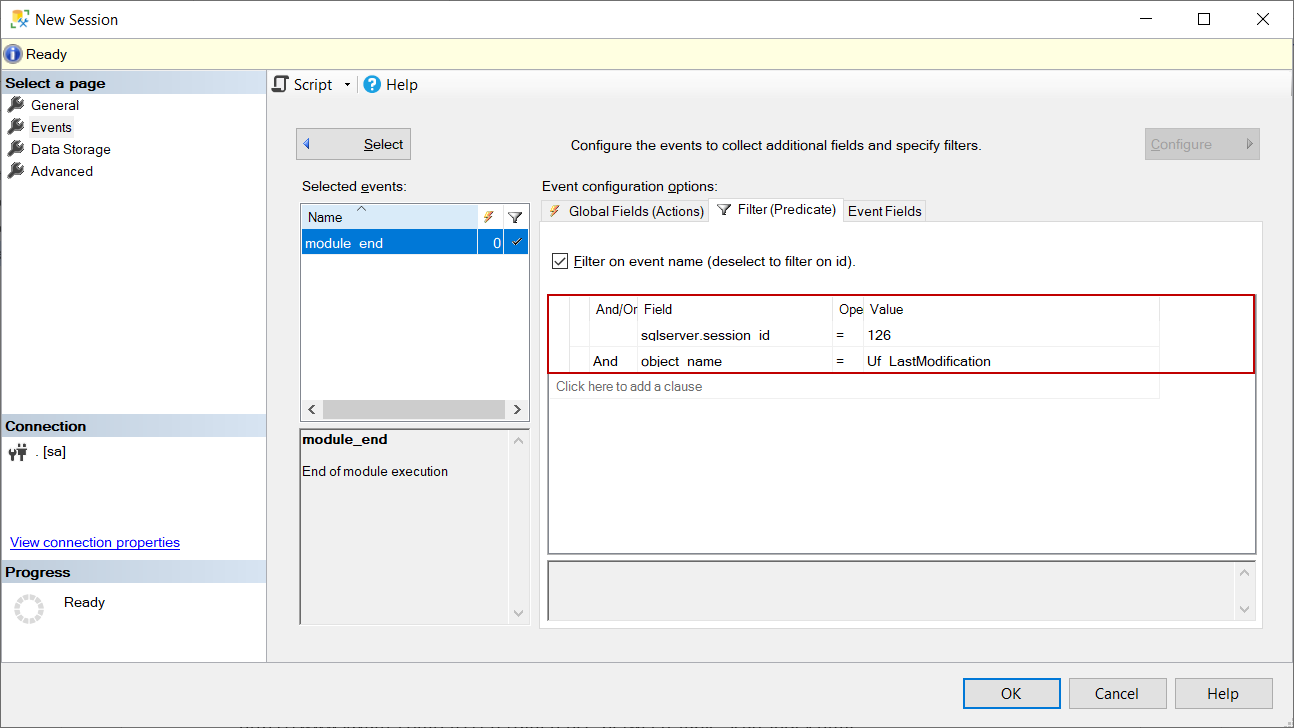
We click the Events tab and add the module_end event to Selected_events
After selecting the module_end event, we click the Configure button and set the filters. In this window, we select the session_id and object name as a filter field. The session_id filter helps to capture the events only for this session.
In the Data Storage tab, we will select a target storage type that the event data will be stored. We can choose the event file type. So that, the event data will be stored as SQL Server Extended Event File (XEL) file type in the specified folder.
As the last step, we will click the Advanced tab and select the Event retention mode. For this event session, we will select the No Event loss because we want to capture all invocation of the scalar-valued function. However, this option may cause performance problems for this reason It is better not to use it in the production environment.
After clicking the OK button, the Watch Live Data window will open and start the event data broadcasting when we execute the SQL update statement.
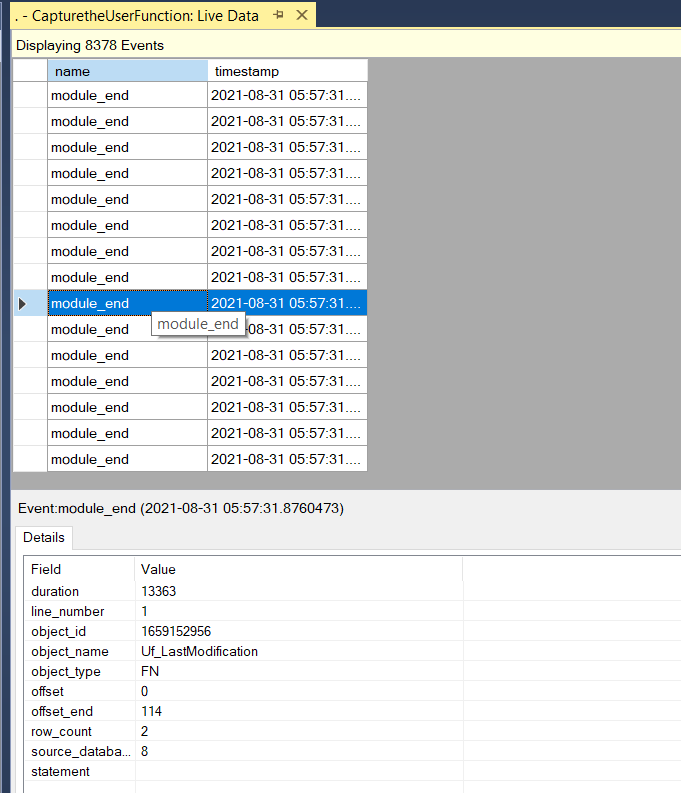
In this window, we open the Extended Event menu and then click Choose Columns menu item to group the event data according to the object name. So that we can easily see how many times the scalar-valued function is invoked.
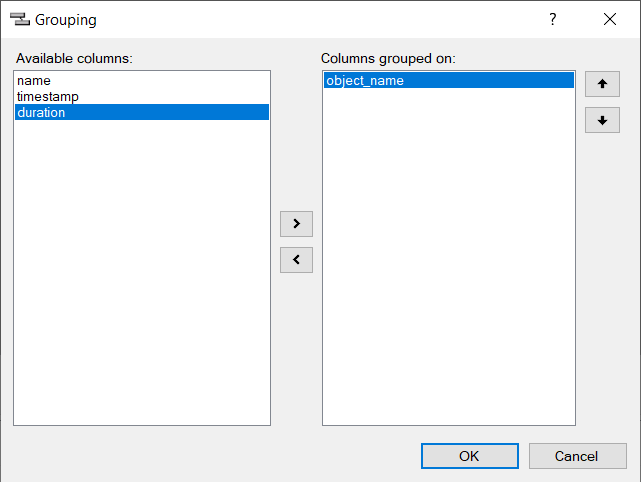
As the last step, we click the Aggregation menu item and select the SUM aggregate type for the duration column. So we can analyze the total time it takes to invoke the scalar-valued function for this SQL update statement.
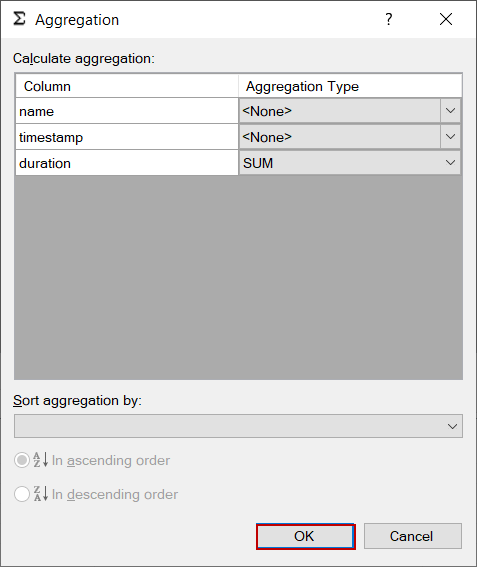
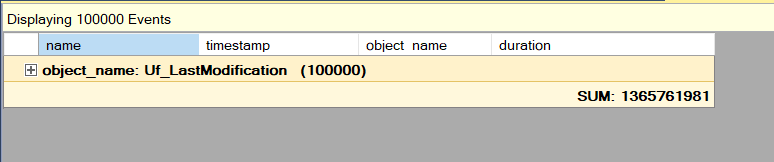
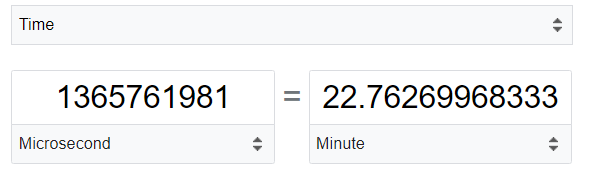
As seen above, SQL Server consumes 22 minutes to invoke this function.
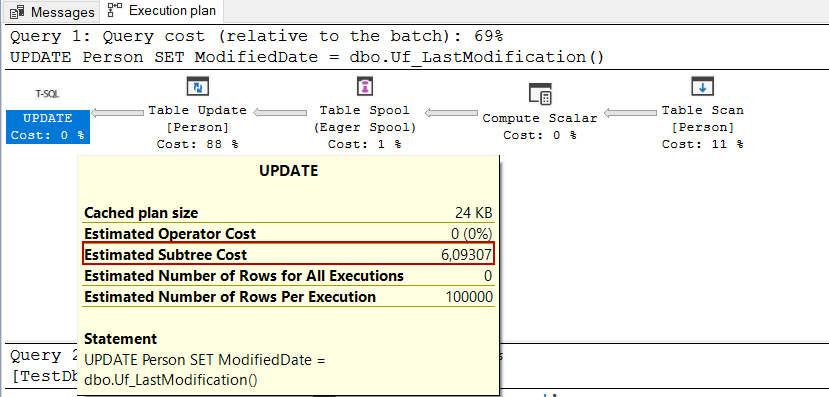
Another problem with this query is that the query optimizer cannot use a parallel plan due to scalar-valued function usage. When we look at the estimated cost of the query is higher than the server Cost threshold for Parallesim. However, the optimizer can not generate a parallel plan.
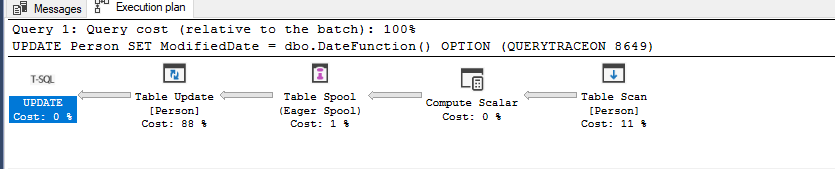
At the same time, we can find the NonParallelPlanReason attribute indicates CouldNotGenerateValidParallelPlan. On the other hand, using trace flag 8649 or ENABLE_PARALLEL_PLAN_PREFERENCE hint does not change this situation.
|
1 2 |
UPDATE Person SET ModifiedDate = dbo.DateFunction() OPTION (QUERYTRACEON 8649) |
Solving the SQL update statement performance problem
As we analyzed, this SQL update statement performance problem is related to using scalar-valued function usage. How we can get rid of this function:
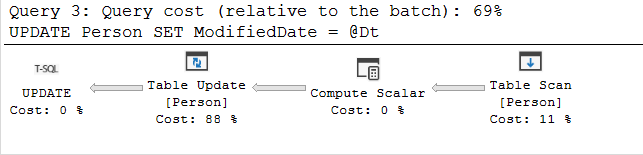

As seen above, the execution plan that is created in SQL Server 2019 enables parallelism and is different than the previous one. The section in the red box has been implemented to the query plan due to the scalar UDF inlining feature. So that, we get rid of to call scalar function 100k times.
Conclusion
In this article, we have learned performance details about the SQL update statement and we also analyze query performance with all details.

Most of his career has been focused on SQL Server Database Administration and Development. His current interests are in database administration and Business Intelligence. You can find him on LinkedIn.
View all posts by Esat Erkec