
In this article, we will explore the Composite Index SQL Server and the impact of key order on it. We will also view SQL Server update statistics to determine an optimized execution plan of the Compositive index.
Introduction
SQL Server indexes are a vital factor in query performance and overall system performance. We use clustered and non-clustered indexes with different configurations. You should go through SQLShack articles category Indexes to get familiar with indexes in SQL Server.
I would list a few useful articles for reference purposes:
- Overview of Non-Clustered indexes in SQL Server
- Overview of SQL Server Clustered indexes
- Top five considerations for SQL Server index design
- Optimizing SQL Server index strategies
- Working with different SQL Server indexes types
Overview of Composite Indexes SQL Server
We can use single or multiple columns while creating an index in SQL Server.
- Single Index: It uses a single column in the index key
- Composite Index: If we use multiple columns in the index design, it is known as the Composite Index
Let’s understand the composite index SQL Server using an example. For this demo, create the [EmpolyeeData] table with the below script:
|
1 2 3 4 5 6 7 |
CREATE TABLE dbo.EmployeesData (EmpId INT IDENTITY(1, 1) PRIMARY KEY CLUSTERED, FirstName VARCHAR(50), LastName VARCHAR(50), Country VARCHAR(50) ); GO |
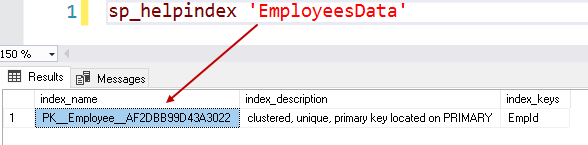
It creates the primary clustered key index on the [EmpID] column. We can check the existing index on a table using the sp_helpindex system procedure. It is a single index because it uses a single column for the clustered index key.
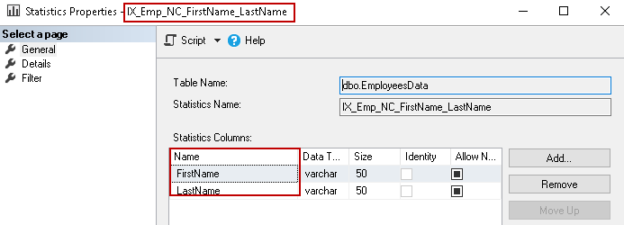
As we can have one clustered index on a SQL table, let’s create a non-clustered index on the [FirstName] and [LastName] columns:
|
1 2 |
CREATE NONCLUSTERED INDEX IX_Emp_NC_FirstName_LastName ON dbo.EmployeesData(FirstName, LastName); |
It is a composite non-clustered index because we use multiple columns in the index definition.

In the above composite index definition, we defined the order key as FirstName, LastName. Suppose you created the index with the order key as LastName, FirstName.
Do the column orders make any difference in the composite index? Let’s explore it using various examples.
Example 1: Use the FirstName and LastName columns in Where clause in a similar order of index keys
In the below query, we use the columns in where condition similar to the index order keys. Before executing the query, press CTRL + M to enable the actual execution plan in SSMS:
|
1 2 3 4 5 6 7 |
SET STATISTICS IO ON; SELECT EmpId, FirstName, LastName FROM dbo.EmployeesData WHERE FirstName = 'Ali' AND LastName = 'Campbell'; |
It uses the non-clustered index (composite index) and index seek operator to filter the results.
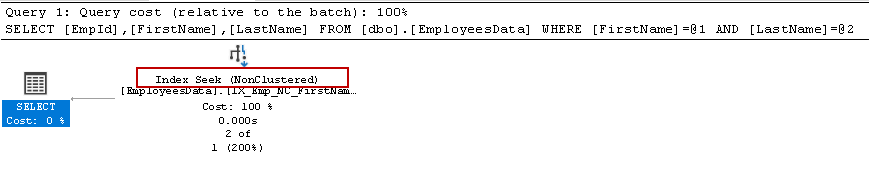
In the index seeks operator, we can see the seek operation using the same index key order.
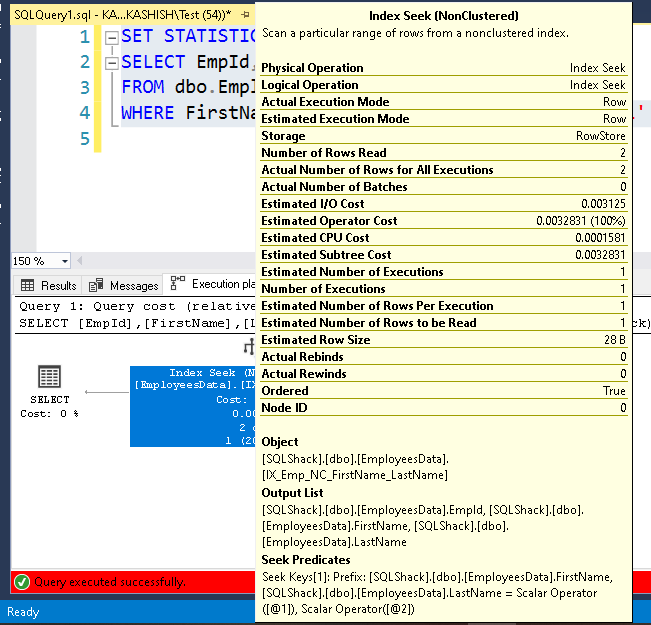
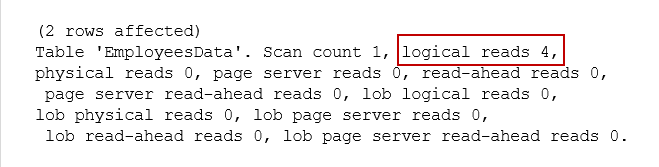
Now, switch to the messages tab, and you see it used 4 logical reads for the entire query.
Example 2: Use the FirstName and LastName columns in Where clause in reverse order of index keys
In this example, we reverse the column order in the Where clause compared to the index key orders. It gives the same results but let’s view the actual execution plan:
|
1 2 3 4 5 6 7 |
SET STATISTICS IO ON; SELECT EmpId, FirstName, LastName FROM dbo.EmployeesData WHERE LastName = 'Campbell' AND FirstName = 'Ali'; |
We see a similar index seek operator using the composite index SQL Server.

No difference in the logical reads as well. Both queries use the 4 logical reads.

In the seek predicates of an index seek, we see it using the column order similar to the composite index key.
Example 3: Use the first key column of the composite index SQL Server in Where clause
In this example, we want to filter records based on the [FirstName] column. It is the first index key column defined in the composite index:
|
1 2 3 4 5 6 |
SET STATISTICS IO ON; SELECT EmpId, FirstName, LastName FROM dbo.EmployeesData WHERE FirstName = 'Ali'; |
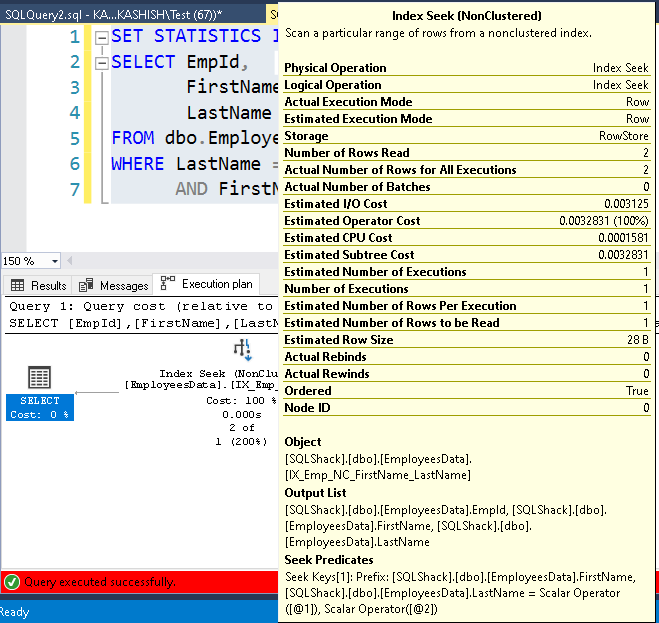
It still uses the same execution plan with an index seek operator on the composite index SQL Server.
It retrieved 6 records compared to 2 records in the previous examples (1&2) but still using the 4 logical reads for the result.
No differences, right! It means you can use columns in any order in the composite index SQL Server. Wait. Let’s look at the next example before making the decision.
It uses seek predicates for the [FirstName] columns, and it is the first column specified in composite index SQL Server.
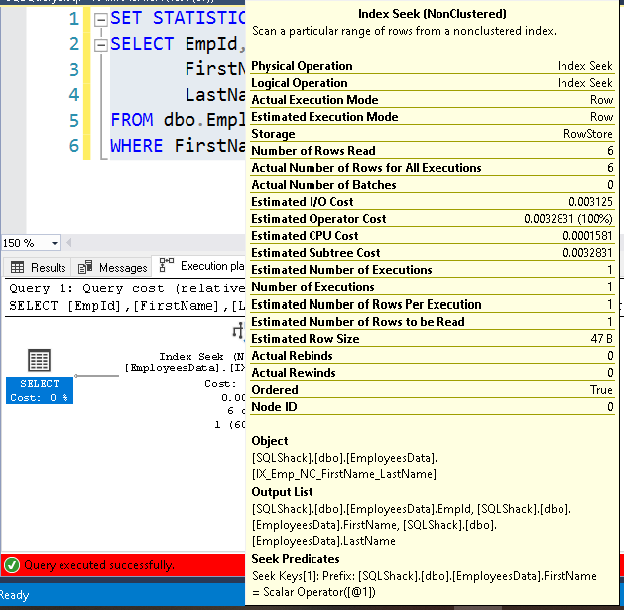
Example 4: Use the second key column of the composite index SQL Server in Where clause
In this example, we want to filter records based on the [LastName] column. It is the second index key column defined in the composite index:
|
1 2 3 4 5 6 |
SET STATISTICS IO ON; SELECT EmpId, FirstName, LastName FROM dbo.EmployeesData WHERE LastName = 'Campbell'; |
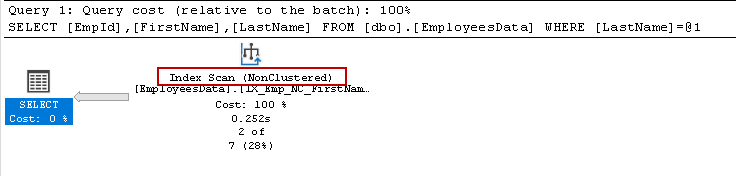
It is using the same composite index, but this time Index seeks converts into the Index scan. You might know that an index scan is a costly operator compare to an index seek in most cases.
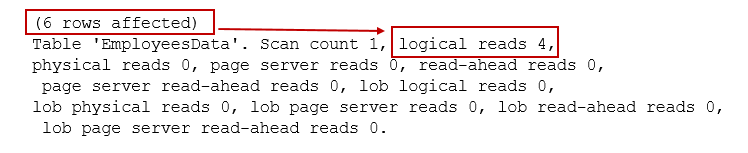
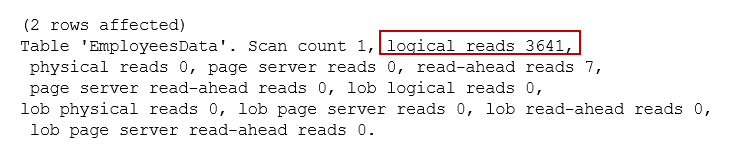
Let’s switch to the Messages tab and look at the impact of it. It retrieves two rows, but logical reads jump to 3641 compared to 4 logical reads in the previous examples.
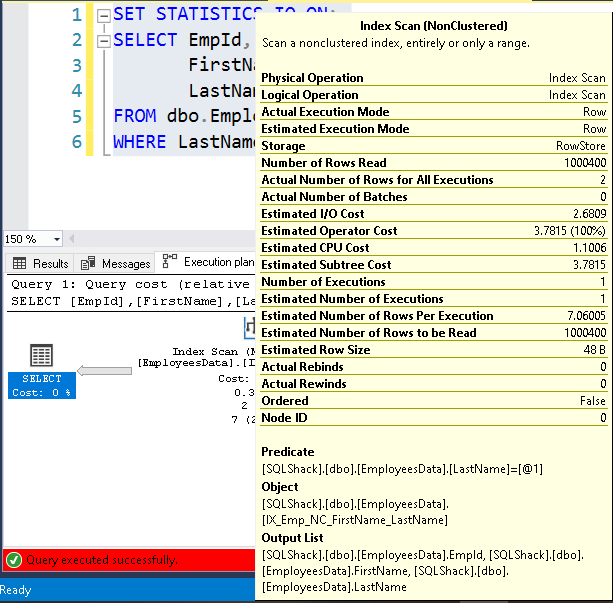
We do not see index seek predicates because it was using the index scan operator.
Now, execute all queries together in a single query window. It shows the query cost compared to other queries:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
SELECT EmpId,FirstName,LastName FROM dbo.EmployeesData WHERE FirstName = 'Ali' AND LastName = 'Campbell'; Go SELECT EmpId,FirstName,LastName FROM dbo.EmployeesData WHERE LastName = 'Campbell' AND FirstName = 'Ali'; Go SELECT EmpId,FirstName,LastName FROM dbo.EmployeesData WHERE FirstName = 'Ali'; Go SELECT EmpId,FirstName,LastName FROM dbo.EmployeesData WHERE LastName = 'Campbell' Go |
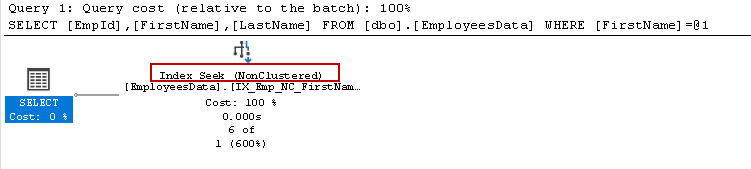
In the below query execution plan, we can note the following:
- The query that uses the first column [FirstName] in the where clause is optimized correctly and cause 0% cost
- The query that uses the second column [LastName] in the where clause is costliest with 100% cost comparatively

Understand the column order impact on your query for a composite index SQL Server
SQL Server uses available statistics to determine the optimized query execution plan. This optimized query plan has operators such as index seeks and index scans. You should go through SQL Server Statistics and how to perform Update Statistics in SQL article to understand SQL Server update statistics.
Expand the SQL table [EmployeeData] and look at the statistics. It shows you the following statistics.
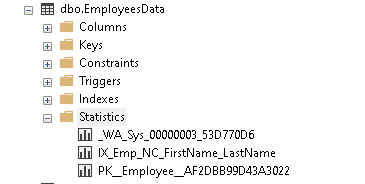
Primary key SQL Server statistics
SQL Server creates it once we define a primary key column. Right-click on the primary key statistic (PK__Employee__AF2DBB99D43A3022) and verify that it using the primary key column, i.e. [EmpID] in my example.
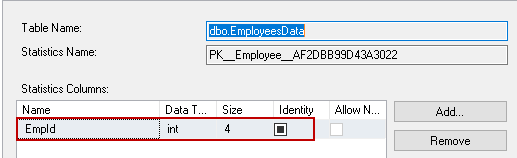
Composite key statistics for composite index SQL Server
We created a non-clustered index with a composite key. SQL Server creates the statistics for this index.
To verify, view the following statistics columns screenshot as well.
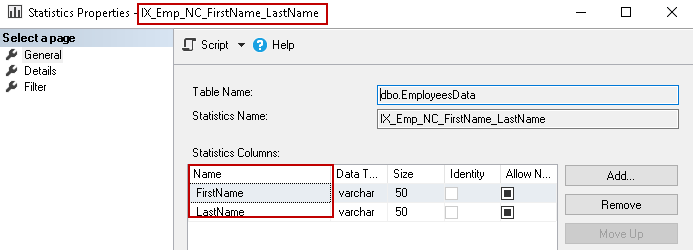
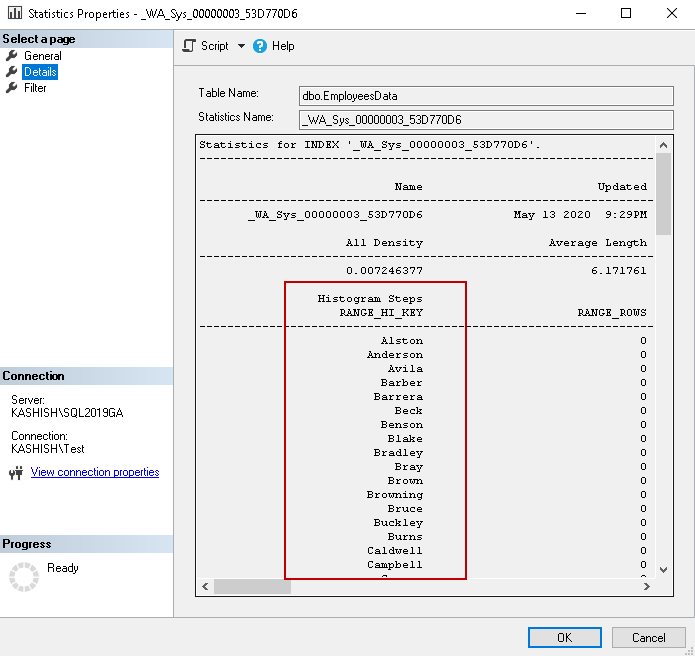
Let’s understand this statistic further. Click on the Details page. It gives you information about index density and histogram steps.
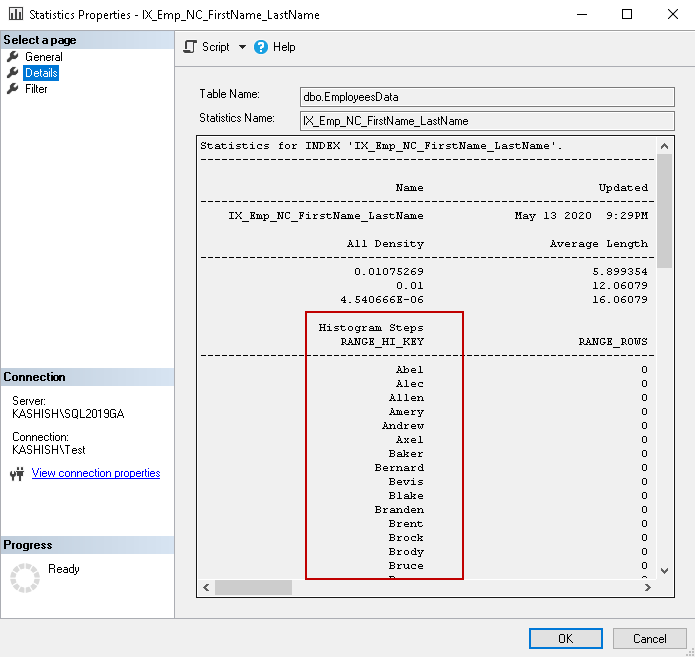
SQL Server stores the first key column of the index in the histogram. As you can see above, histogram steps RANGE_HI_KEY showing values from the [FirstName] column.
SQL Server uses the left-based subset for other key columns we defined in the composite index SQL Server. If we do not filter the results based on the first index key, it might not help query optimizer to choose the proper index or operator. You might see an index scan in comparison to an index seek operator as we saw in previous examples.
Auto-created key SQL Server statistics
As we know now that SQL Server uses the first key for the histogram. In this case, we filtered records on [LastName] column, so it creates a new statistic for it. You can see auto-created statistics starting from _WA_sys. We can verify from the below screenshot that It created statistics for the [LastName] column.
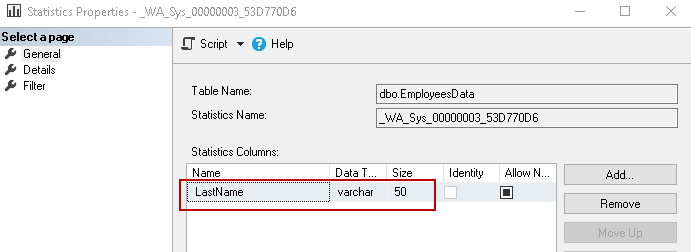
In the details, you can verify that histogram takes data from the LastName column values.
Now, in the actual execution plan, right-click and click on Show Execution Plan XML. It gives you plan in an XML format. It is comparatively complex to understand an XML plan. In this plan, we can see that query optimizer decides to create the new statistics for the [EmployeeData] table based on the where clause column.
|
1 2 3 |
<OptimizerStatsUsage> <StatisticsInfo Database="[SQLShack]" Schema="[dbo]" Table="[EmployeesData]" Statistics="[_WA_Sys_00000003_53D770D6]" ModificationCount="0" SamplingPercent="22.6649" LastUpdate="2020-05-13T21:29:48.49" /> </OptimizerStatsUsage> |
In the output, it retrieves the columns we require as result of table scan operation.

Conclusion
In this article, we explored the impact of column orders in the composite index SQL Server. We also looked at the SQL Server update statistics to determine the optimized execution plan. It depends upon the workload, and you need to design your index keys depending upon the requirement. It might require testing in a lower environment with production workload simulation.

I am the author of the book "DP-300 Administering Relational Database on Microsoft Azure". I published more than 650 technical articles on MSSQLTips, SQLShack, Quest, CodingSight, and SeveralNines.
I am the creator of one of the biggest free online collections of articles on a single topic, with his 50-part series on SQL Server Always On Availability Groups.
Based on my contribution to the SQL Server community, I have been recognized as the prestigious Best Author of the Year continuously in 2019, 2020, and 2021 (2nd Rank) at SQLShack and the MSSQLTIPS champions award in 2020.
Personal Blog: https://www.dbblogger.com
I am always interested in new challenges so if you need consulting help, reach me at rajendra.gupta16@gmail.com
View all posts by Rajendra Gupta
- Understanding PostgreSQL SUBSTRING function - September 21, 2024
- How to install PostgreSQL on Ubuntu - July 13, 2023
- How to use the CROSSTAB function in PostgreSQL - February 17, 2023