
In this article, we will discuss the most important points that we should consider when designing an optimal SQL index. Before going through the index design procedure, let us revise the SQL Server index concept.
Note: To learn more about SQL Server indexes, please read SQL Server Indexes: Key Requirements, Performance Impacts and Considerations article.
SQL Server index overview
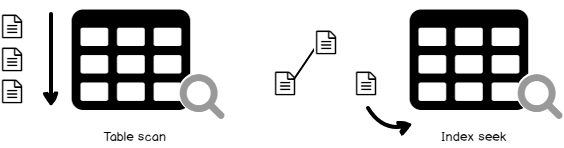
SQL index is considered as one of the most important factors in the SQL Server performance tuning field. It helps in speeding up the queries by providing swift access to the requested data, called index seek operation, instead of scanning the whole table to retrieve a few records. It works similar to the book’s index that helps in identifying the location of each unique word, by providing the page where you can find that word, rather than spending the whole weekdays reading the book to check a specific subject or identifying that word. In other words, the existence of that index will save time and resources.
For more information about the SQL index structure, different operations that can be performed on an index and how to take advantage of the index in tuning the T-SQL queries performance, check the following articles:
SQL Server provides us with two main types of indexes. The clustered index that is used to store the whole table data based on a select index key consists of one or multiple columns, with the ability to create only one clustered index per each table. The clustered index existence covert the table from an unsorted heap table to a sorted clustered table.
- For more information about the clustered index, check Designing effective SQL Server clustered indexes.
The second main type of SQL Server indexes is the non-clustered index in which the leaf nodes of that index stores only the index key values with a pointer to the storage location of that rows in the main heap table or the clustered index, with the ability to create up to 99 non-clustered indexes per each table.
- For more information about the non-clustered index, check Designing effective SQL Server non-clustered indexes.
SQL Server provides us also with other special purposes SQL indexes, derived from the clustered and non-clustered types, that can help in improving the performance of the T-SQL queries. These indexes include the Unique index, Filtered index, Spatial Index, XML index, Clomunstore index, Full-Text index, and Hash index.
- For deeper details about these types, check Working with different SQL Server indexes types.
After creating the index, we need also to monitor that index usage to make sure that it still efficient and useful for us. This can be performed by gathering statistical information about the indexes and its usage then perform the proper maintenance operation on these indexes to keep it in a healthy state.
Index design considerations
The target of the SQL Server index design task is to have an index that SQL Server Query Optimizer will choose to enhance the performance of the submitted queries. I used to describe the index, in all my articles and sessions, as a double-edged sword. In this way, I will make sure that we are not blaming the index for our mistakes. The index will be our superhero and improve the performance of our queries if we design it in a correct way. But if that index is poorly designed, it will cause performance degradation in our queries and slow down the data retrieval process. In other words, the absence of poorly designed indexes is better than its existence.
The process of selecting the right SQL Server index that fits your database and workload requirements is not an easy mission, but also not impossible mission. In this process, you need to balance between the index gain in the shape of speeding up the data retrieval operation and the index overhead on the data insertion and modification operations.
To help you in designing a proper index that SQL Server Query Optimizer will take advantage of to enhance your queries performance, we will discuss here the top five points that you need to consider when planning to create an index.
Database design
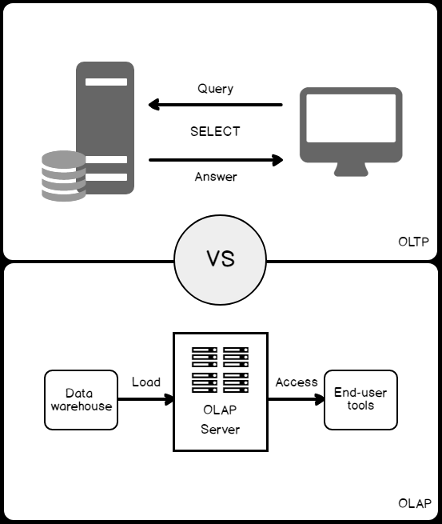
In order to design a proper index, you need to study the characteristics of the database on which the SQL Server index will be created. If the database is created to handle the Online Transaction Processing (OLTP) workload, with a large number of inserting and data modification queries, it is recommended not to overload the database with a large number of indexes. This is due to the fact that inserting, updating or deleting any row on the underlying table will also require reflecting the same changes to all related indexes in that table. So, you should create the minimum possible number of indexes in the OLTP tables with the least possible number of columns participating in the index’s key. In this way, we can take advantage of the created SQL indexes in speeding up the data retrieval process with minimal overhead on the data modification operations.
If the database is created to handle Online Analytical Processing (OLAP) workload, which is used in Data Warehouse as a part of the Business Intelligence structure, most of the workload will be in the shape of SELECT queries to retrieve a large amount of analytical data for analysis or reporting purposes, and a small number of data modification queries. In this case, you can create a large number of SQL Server indexes, adding all required columns as index key or non-key columns to enhance the performance of the SELECT queries and get the requested data faster.
Another thing to consider when indexing a database table is the size of the table. If the table is small with less than 1000 pages, no performance enhancement can be gained from indexing that table, as SQL Server Query Optimizer will prefer scanning the whole table rather than examining the SQL index and try to create the best possible plan. In other words, this index on the small table will not be used and will have overhead on the table as it should be maintained when the table is changed.
You need also to have a look at the database views and check the ones that contain multiple joins and aggregations and create indexes on these views to enhance the performance of reading from it.
- For more information about the index’s views, check SQL Server Indexed Views.
T-SQL query
Studying the queries that are hitting the database tables very frequently, by checking with the system developer or using the profiling tools such as SQL Profiler or Extended Events, will help in designing the SQL Server index that helps more in enhancing the overall system performance.
After getting statistics about the frequently executed queries, we should check the columns that are used in the predicates and join conditions in these queries and create the proper index, by adding all necessary columns to the index to cover the frequently executed query and avoid any unnecessary column, to speed up the data retrieval operation.
As a SQL Server developer, it is recommended to write data insertion and modification queries to insert, update or delete as many rows as possible in the same query, rather than writing multiple queries. This will help in reducing the overhead of the index on the data modification statement, where all these changes performed on the table will be replicated to the SQL index as one-shot when executed as a single query.
Columns
After studying the characteristic of the frequently executed query that we need to enhance and having a list of columns to participate in the index key, we need to consider some points when choosing which column we should add to the index.
The first point is the column characteristic. Not all data types are recommended to be used as an index key. For example, the best candidate data type for the SQL Server index is the integer column due to its small size. On the other hand, columns with text, ntext, image, varchar(max), nvarchar(max), and varbinary(max) data types cannot participate in the index key. However, most of it still can be added to the non-clustered non-key columns. A column with XML data type can be added only to an XML index. In addition, a column with UNIQUE and NOT NULL values will be a good candidate, due to its high selectivity level, as an index key column that makes the index more useful.
The second point is the location of the column in the query. For instance, the columns used in the WHERE clause, the JOIN prediction, LIKE and the ORDER BY clause are the best candidate columns to be indexed. In addition, indexing the computed columns and the foreign key columns will enhance the performance of the queries that read from these columns.
An important point to consider after selecting the proper columns to be involved in the index key is the order of the columns in the index key, especially when the key consists of multiple columns. Try to place the columns that are used in the query conditions first in the SQL Server index key. Also, try to define the columns sorting criteria, ascending or descending, in a way that matches the order used in the ORDER BY clause in your query. In this way, you will overcome the SORT operator high overhead, enhancing the performance of the query.
Index types
To that step, we have made a decision that we need to create an index in a specific database table to cover a specific query that is called very frequently, and we need to add candidate column(s) to the index key. We need now to decide which SQL index type fits the query requirements. In other words, we need to specify if we should create a clustered or non-clustered index, a unique or non-unique index, columnstore, or rowstore index. All these decisions will be made based on the query coverage and enhancements requirement.
As mentioned previously, SQL Server provides us with different types of special purposes indexes that we can use to enhance the performance of the queries. For example, try to use a Filtered index on the columns that have well-defined data subsets, such as Sparse columns with mostly NULL values.
- For more information about the different types of SQL indexes, check Working with different SQL Server indexes types.
It is recommended to start indexing the table by creating a clustered index, that covers the column(s) called very frequently, which will convert it from the heap table to a sorted clustered table, then create the required non-clustered indexes that cover the remaining queries in the system. In this way, the non-clustered indexes will be built over the SQL Server clustered index and the pointers on the leaf level nodes of the non-clustered indexes will also point to the location of the row in the sorted clustered index.
If the clustered index is created on a table with clustered indexes already exist, all the non-clustered indexes will be dropped and created again to change the pointers in the leaf level nodes that were pointing to the heap table to point to the newly-created clustered index. So that, creating it in the correct order will overcome the overhead of recreating the non-clustered index again.
Index storage
When a SQL Server index is created, it will be stored in the same filegroup where the main table is created. The partitioned clustered index and the non-clustered index can be stored on the same filegroup as the main table or on a different filegroup.
Selecting the proper storage criteria for the index during the design phase will help in improving the query performance by increasing the I/O performance. For instance, creating the non-clustered index on a filegroup located in a different disk drive than the disk drive where the main table is created will improve the performance of the queries that use that non-clustered index, as it will not be affected by the concurrent reading of the data and SQL index pages, that are spread across different disks, which will be performed on different disk drives.
In addition, the clustered and non-clustered indexes, that are created over large tables, can be partitioned across multiple filegroups, with each filegroup stored on a separate disk drive, improving the concurrent data access and retrieval operations, due to the fact that the data is distributed over different disk drives within the SQL index and the Query Optimizer will process only the partitions that the query will access, excluding all other partitions.
Another important storage concept that should be considered also is the FILLFACTOR option, which is an option that can be defined when creating or rebuilding an index, with its value between 0 and 100, that specifies the percentage of space that will be filled on each leaf-level data page in the created index. For example, setting the FILLFACTOR value to 80% will leave 20% of each page empty during the SQL Server index creation or rebuilding process, and this 20% percent will help when a new data is inserted, or an existing data is modified but not fit in the current space, where the data will be inserted in that free space instead of splitting the current page into multiple pages causing index fragmentation issue that will degrade the index performance with time. Fill factor will help in enhancing the performance of the T-SQL queries and minimize the amount of index storage and index maintenance overhead.
It is also recommended to create narrow indexes with the least possible number of useful columns, rather than creating wide indexes with many unnecessary columns, as it requires less disk space and will have less SQL Server index maintenance overhead.
All the previously mentioned points will help in designing the most optimal index that enhance the performance of the T-SQL queries, but it is very important to test the index first on a development environment before creating it on the production environment and make sure that it is useful for your workload and keep monitoring it and marinating it once created on the production environment.

He is a Microsoft Certified Solution Expert in Data Management and Analytics, Microsoft Certified Solution Associate in SQL Database Administration and Development, Azure Developer Associate and Microsoft Certified Trainer.
Also, he is contributing with his SQL tips in many blogs.
View all posts by Ahmad Yaseen
- Azure Data Factory Interview Questions and Answers - February 11, 2021
- How to monitor Azure Data Factory - January 15, 2021
- Using Source Control in Azure Data Factory - January 12, 2021