
This article explores the Hybrid Buffer Pool feature available in the SQL Server 2019.
Introduction
SQL Server uses Dynamic Random Access Memory (D-RAM) buffer pool for caching data pages retrieved from the disk. The buffer cache stores the page and writes back to disk only if it is modified. If a page is modified in the buffer cache, it is known as a dirty page. SQL Server considers a page as clean if its equivalent copy exists on the disk. The checkpoint writes the dirty pages and T-log information from memory to disk. The buffer pool is volatile, and every time you restart SQL Services, it gets flushed out.
The buffer pool is available for all databases for storing their cached data pages. Its size is dynamic, and you can configure it using the sp_configure. Usually, for an optimized SQL Server performance, the page should exist in the buffer cache instead of fetching it from the disk.
- Note: You can refer to Monitoring Memory Clerk and Buffer Pool Allocations in SQL Server to understand the buffer pool usage and monitor it
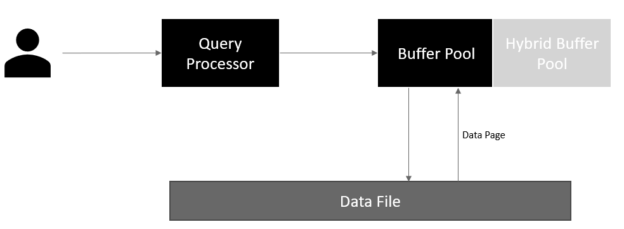
In the following high-level diagram, we can see that once a user submits a select query, the query processor optimizes the query plan and request the required pages from the buffer pool. If the page is not available in the buffer pool, it fetches data from the data file to the buffer pool to satisfy the user requests (DMLs).
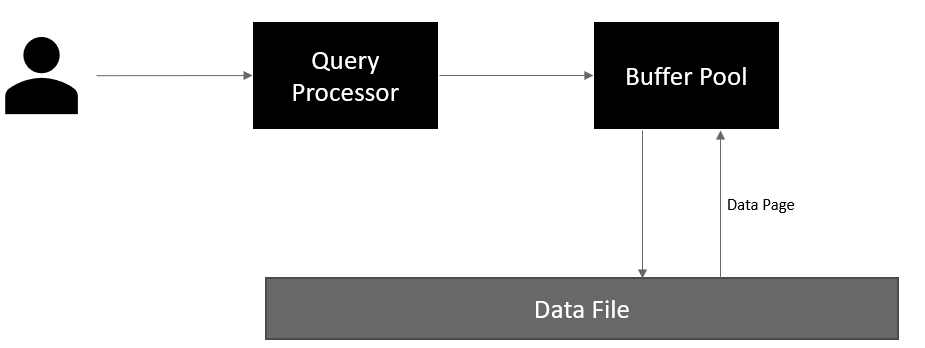
Similarly, the data modification requires pages to be modified in the buffer cache. SQL Server records the modification in the transaction logs using the Write-Ahead-Logging (WAL) and writes dirty pages (modified) back to the disk.
You can refer to Microsoft documentation here to understand the architecture in detail.
Overview of the Hybrid buffer pool
SQL Server 2019 has many enhancements for improving query performance, reducing system bottlenecks. SQL Server 2019 introduces a new concept – Hyper Buffer Pool (HPB) that enables the buffer pool objects to utilize persistent memory devices (PMEM) for referencing the data pages. It avoids copying those data pages to the volatile DRAM.
The PMEM is a high-performance solid-state device that uses a byte-addressable memory device. It provides the following benefits.
- It enables quick data access with minimum latency for large datasets
- It is ultra-fast and persistent, meaning data remains in memory even after system restart, Power interruption, or system crash. Therefore, SQL Server does not require caching pages again in the buffer pool and reduces IO requests from storage
- It increases the throughput more than the SSD and NVMe
- It is cost-effective and cheaper than the DRAM
The PEMM device can directly access the clean pages only. If a page is not present in the buffer pool or hybrid buffer pool, it still loads the data page from the disk to the buffer pool. Therefore, once a page is dirty, SQL Server copies it to the DRAM buffer pool and writes a clean copy into the PMEM device.
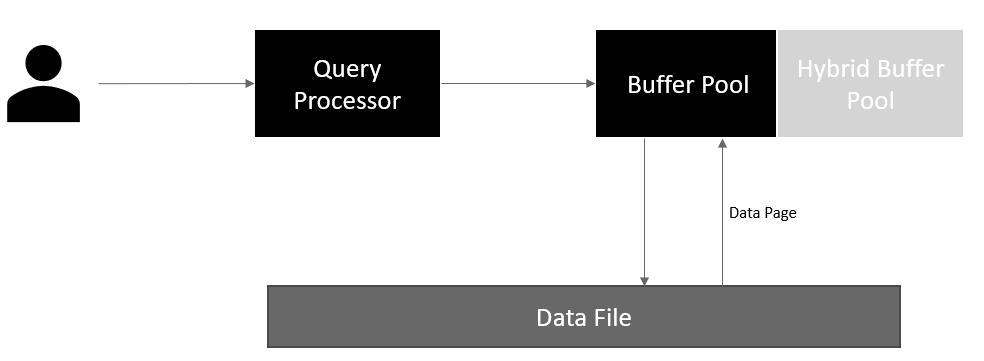
Therefore, the hybrid buffer pool avoids copying a data page to the buffer pool and improves query performances by reducing the IO. It can be helpful in the case of bulk transactions that require more memory for data processing.
The hybrid buffer pool is available on both Windows and Linux SQL Server. We need to format the disk with direct access supported file system. The supported file systems are as below.
- EXT4
- NTFS (New Technology File System)
- Extended File system (EFS)
SQL Server 2019 has the functionality to detect whether the data file resides on the supported PMEM device. It performs the memory mappings appropriately. You need to restart SQL Service for this mapping to occur upon startup.
The following image highlights the difference in the buffer pool with and without the hybrid buffer pool.
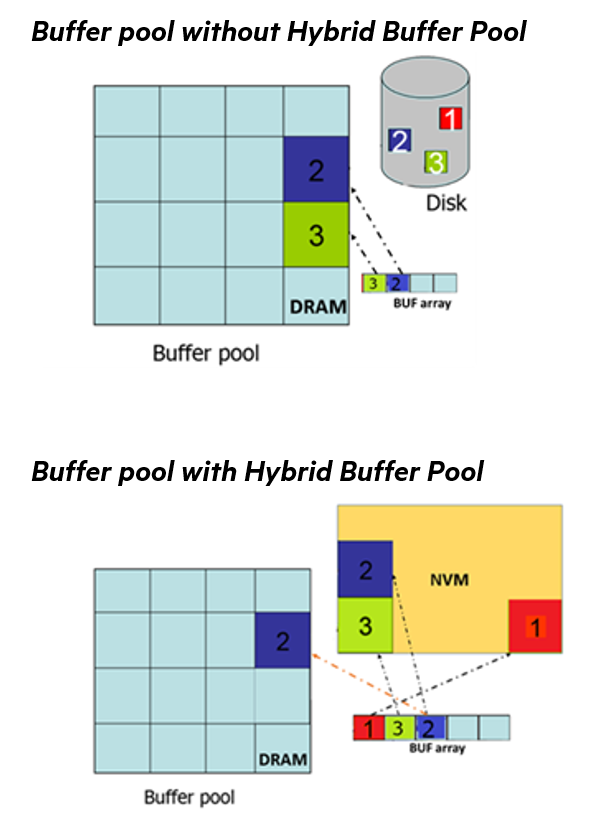
Image Reference: Microsoft docs
Pre-requisites
You require SQL Server 2019 for the demonstration in this article. You can navigate to Microsoft website and download the evaluation or development version.
- Note: I recommend you install SQL Server 2019 developer edition for learning purposes. It provides all enterprise-level features for learning and performing demonstrations
Requirements of the Hybrid Buffer Pool
To use this feature in SQL Server, you need to have the following environment.
- Windows Server 2019
- SQL Server 2019
- PMEM device
- Volume on the PMEM device with supported DAX file system
Enable hybrid buffer pool in SQL Server 2019
You can use dynamic data language (DDL) to control the hybrid buffer pool. By default, this feature is disabled on the instance level.
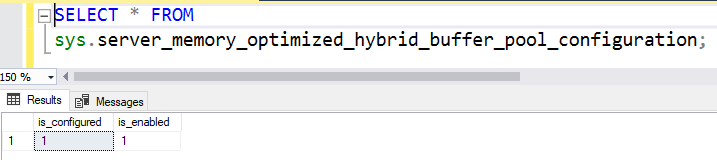
To validate it, we can use the query system view as shown below.
|
1 2 |
SELECT * FROM sys.server_memory_optimized_hybrid_buffer_pool_configuration; |

It is enabled for all databases in an instance of SQL Server 2019. You can query sys.databases system catalog view and check value for the is_memory_optimized_enabled as shown below.
|
1 |
SELECT name, is_memory_optimized_enabled FROM sys.databases; |

The following t-SQL script enables a hybrid buffer pool on a SQL instance.
|
1 |
ALTER SERVER CONFIGURATION SET MEMORY_OPTIMIZED HYBRID_BUFFER_POOL = ON; |
Note: It requires a restart of the SQL Server instance for this setting to take effect. It allocates hash pages as per the total PMEM capacity. Once you enable the feature at the instance level, you can view the following message in the error log:
The hybrid buffer pool memory-optimized configuration has been set to ‘enable’. Restart SQL server for the new setting to take effect
After SQL Service restart, the is_enabled column changes to 1, which shows the hybrid buffer pool is enabled for this instance.
Check the error log, and it gets the following highlighted entries.
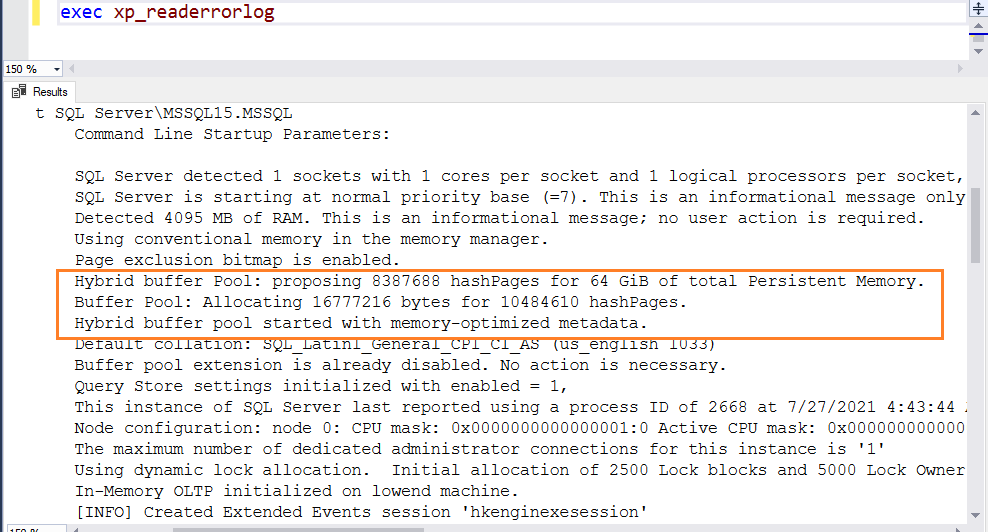
Message 1: In this message, SQL Server informs that hyper buffer pool is enabled for this SQL instance
2021-07-27 04:43:47.060 Server Hybrid buffer pool started with memory-optimized metadata
Message 2: Here, it gives allocation details of the hash pages
Buffer Pool: Allocating 16777216 bytes for 10484610 hash Pages
Message 3: Here, it gives information on total persistent memory
Hybrid buffer Pool: proposing 8387688 hash Pages for 64 GiB of total Persistent Memory
- Note: If you have enabled a hybrid buffer pool for a SQL instance, you do not need to enable it for the individual database
Disable hybrid buffer pool for SQL Server instance
You can disable the HBP configuration using a similar dynamic data language (DDL) statement. Here, we specify the value of HYBRID_BUFFER_POOL to OFF. You also need to restart SQL Service after disabling the hybrid buffer pool.
|
1 |
ALTER SERVER CONFIGURATION SET MEMORY_OPTIMIZED HYBRID_BUFFER_POOL = OFF; |
- Note: If you disable the feature at the instance level, it won’t be used by any database, even if it is enabled at the database level
Disable hybrid buffer pool for a specific SQL Server database
You can enable or disable a hybrid buffer pool for a specific SQL Server database using the Alter database statement. Suppose the HBP is enabled at the instance level, and you want to use it for a specific database. Therefore, you can enable it for a specific database.
|
1 2 3 4 5 6 |
--Enable hybrid buffer pool ALTER DATABASE <databaseName> SET MEMORY_OPTIMIZED = ON; --Disable hybrid buffer pool ALTER DATABASE <databaseName> SET MEMORY_OPTIMIZED = OFF; |
- Note: Even if you enable the HBD feature for a specific database, it takes effect once you restart SQL Service
Best Practices for hybrid buffer pool
Microsoft documentation gives few best practices for using the hybrid buffer pool feature.
- You should use the largest allocation unit size for NTFS ((2 MB in Windows Server® 2019) along with the device configured for DAX ( Direct Access)
- We require to enable Locked pages in Memory configuration in Windows
- The data file size should be in multiples of 2 MB
Conclusion
The Hybrid Buffer Pool improves database performance using direct data page access from the PMEM device. In this case, SQL Server does not need to copy the page to DRAM and reduces IO, especially for bulk transactions.

I am the author of the book "DP-300 Administering Relational Database on Microsoft Azure". I published more than 650 technical articles on MSSQLTips, SQLShack, Quest, CodingSight, and SeveralNines.
I am the creator of one of the biggest free online collections of articles on a single topic, with his 50-part series on SQL Server Always On Availability Groups.
Based on my contribution to the SQL Server community, I have been recognized as the prestigious Best Author of the Year continuously in 2019, 2020, and 2021 (2nd Rank) at SQLShack and the MSSQLTIPS champions award in 2020.
Personal Blog: https://www.dbblogger.com
I am always interested in new challenges so if you need consulting help, reach me at rajendra.gupta16@gmail.com
View all posts by Rajendra Gupta
- Understanding PostgreSQL SUBSTRING function - September 21, 2024
- How to install PostgreSQL on Ubuntu - July 13, 2023
- How to use the CROSSTAB function in PostgreSQL - February 17, 2023