
In this article, we will explore some internal working principles of SQL Server statistics.
What is Cardinality Estimator (CE)?
The Cardinality Estimator (CE) is the core subunit of the SQL Server query optimizer and its responsibility is to predict how many rows will be returned from a query. The accuracy of this prediction directly affects the generated query plan efficiency. Hence, this effect upon the query plan makes CE decisive and critical on the query performance.
SQL Server statistics and Cardinality Estimator
SQL Server statistics stores the columns data distributions and they use histograms to organize the distribution of the data. The cardinality estimator uses these histograms to obtain the required analytical data and then runs a mathematical algorithm to estimate how many rows could be returned from a query. In order to figure out how the cardinality estimator performs these predictions more clearly, we will make some examples. However, firstly we require a sample table thus we will create a sample table through the following query. This table is a heap copy of the SalesOrderHeader table of the Adventureworks database.
|
1 2 3 |
SELECT * INTO TempSalesOrder FROM Sales.SalesOrderHeader |
What is the meaning of predicate?
A predicate defines a conditional expression that is applied to rows of the table to filter the result set of the query.
Single Predicate Example:
In this first example, we want to only return particular rows that the Freight column equals a specified value. Before executing the query, we will enable the actual execution plan.
|
1 2 3 |
SELECT * FROM TempSalesOrder WHERE Freight=89.4568 |
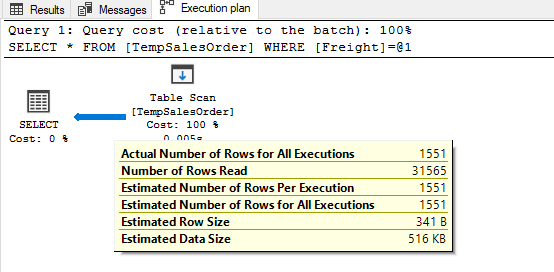
As seen in the execution plan of the query, the Estimated Number of Rows for all Execution has been estimated at 1551 rows by the CE, and this estimation is calculated using a particular statistic. The used statistics details can be seen under the OptimizerStatsUsage attribute of the execution plan.
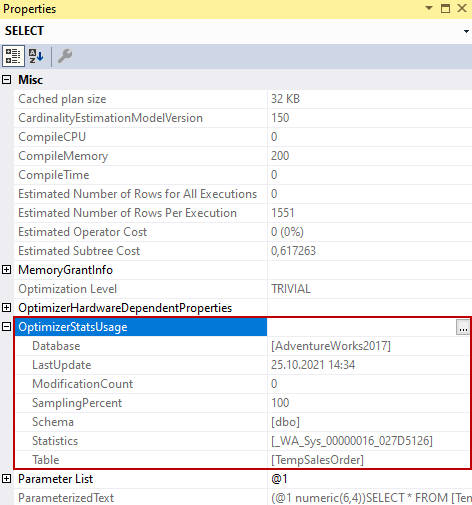
Through the DBCC SHOW_STATISTICS command, we can obtain detailed information about the statistics density and its histogram.
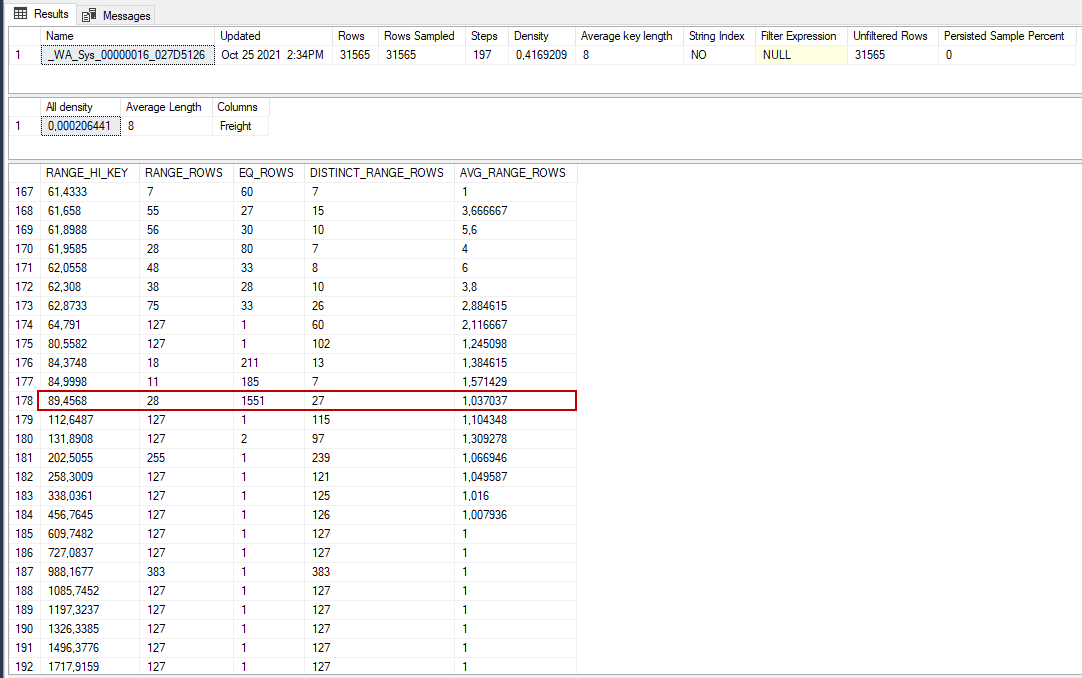
The histogram data EQ_ROWS column shows the number of rows that have the same value as the predicate. The 178th row of the histogram matches with the predicate row and the estimated rows calculation is equal to 1551.
Double Predicate Example:
In this second example, we will apply two predicates in the query. In this case, the cardinality estimator uses a complicated formulation to calculate the estimated number of rows. At first, we will execute the following query and check out the estimated number of rows.
|
1 2 3 |
SELECT * FROM TempSalesOrder WHERE Freight =89.4568 |
AND CurrencyRateId IS NULL
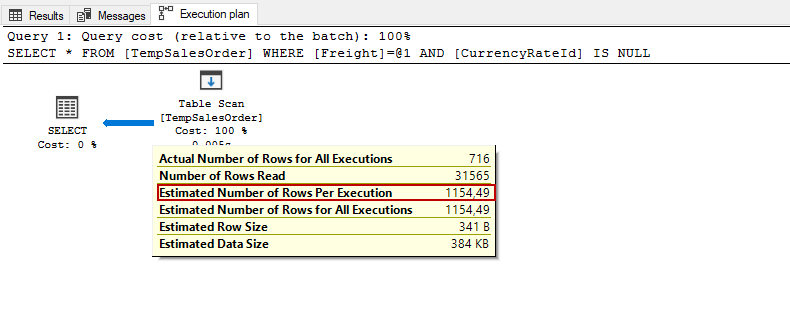 As we can see, the optimizer calculated the estimated number of rows is 1154,49, and this estimation is made using the following formula:
As we can see, the optimizer calculated the estimated number of rows is 1154,49, and this estimation is made using the following formula:
Estimated Number of Rows = (P0*P1^(1/2)*P2^(1/4)*P3^(1/8))*Card
P() expression indicates the selectivity of the predicates and Card expression shows the table total number of the rows. The selectivity is calculated by dividing the number of table rows by the estimated number of rows. As a first step, we will calculate the selectivity using the histograms.
|
1 2 3 |
DBCC SHOW_STATISTICS ('TempSalesOrder','_WA_Sys_00000016_027D5126') |
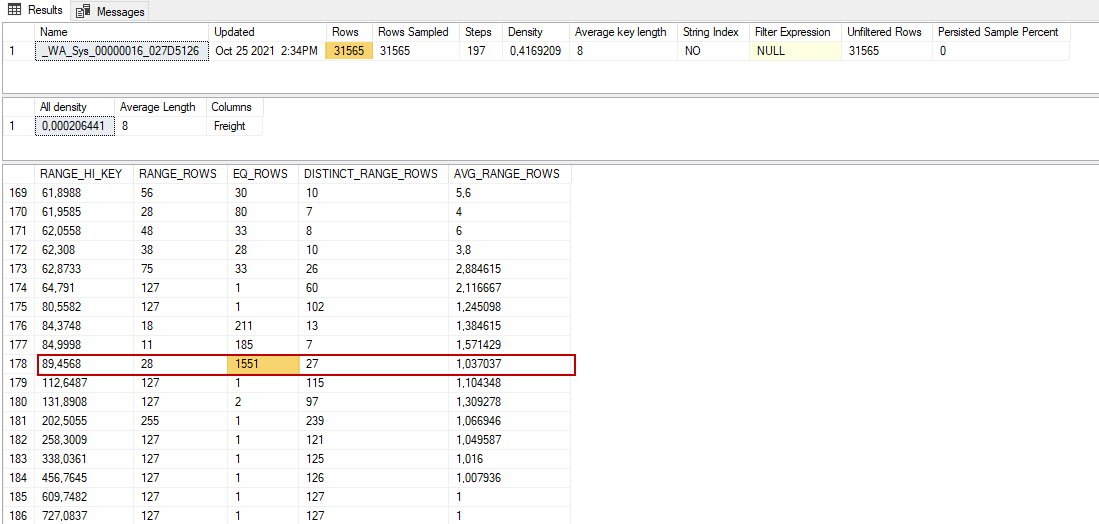
As we can see, the estimated rows are 1551, and the total number of the table is 315645. We apply the following formula to calculate the first predicate selectivity.
P() = Estimated Rows / Total Row Number of Table
P0 = 1551 / 31565
P0 = 0,049137
|
1 2 3 |
DBCC SHOW_STATISTICS ('TempSalesOrder','_WA_Sys_00000013_027D5126') |
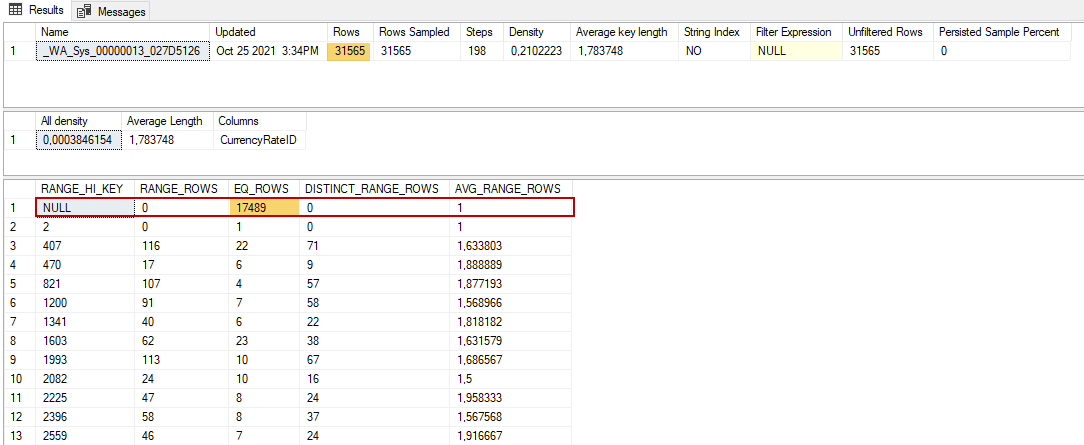
We use the same formula to calculate selectivity for the second predicate.
P1= 17489 / 31565
P1 = 0,55406
Combined selectivity: P0*P1 =0,036575
The estimated number of rows = 31565* 1154,493
The estimated number of rows = 1154,493
As we can see, we achieved the estimated number of rows using SQL Server statistics. However, we need to take into account one point in this formula, before starting the calculation we need to sort the selectivity of predicates into ascending order and then apply the formula.
P0<P1<P2<P3
Multiple Predicates Example:
In this last example, we will add three predicates in our sample query and we will use the query_optimizer_estimate_cardinality event. This event can be used to diagnose cardinality estimate issues. Through the following query, we will create an event session and start it.
|
1 2 3 4 5 6 7 8 9 10 |
CREATE EVENT SESSION [CaptureCEActivities] ON SERVER ADD EVENT sqlserver.query_optimizer_estimate_cardinality( ACTION(sqlserver.sql_text) WHERE ([sqlserver].[like_i_sql_unicode_string]([sqlserver].[sql_text],N'%TempSalesOrder%'))) ADD TARGET package0.event_file(SET filename=N'C:\temp1.xel',metadatafile=N'c:\temp1.xel1.xem') WITH (STARTUP_STATE=OFF) GO ALTER EVENT SESSION CaptureCEActivities ON SERVER STATE = START |
As the second step, we will execute the following query.
|
1 2 3 4 5 |
SELECT * FROM TempSalesOrder WHERE Freight =89.4568 AND CurrencyRateId IS NULL AND TerritoryID =4 OPTION (RECOMPILE) |
The event session captured our query and returned detailed information about the internals of the CE. When we click the CalculatorList field we can find out the selectivity of each predicate.
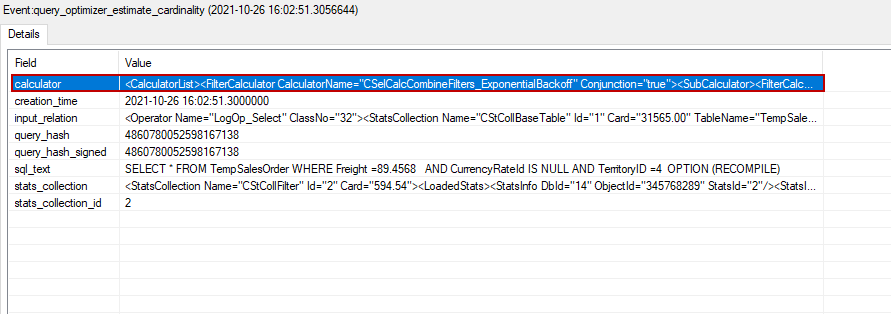
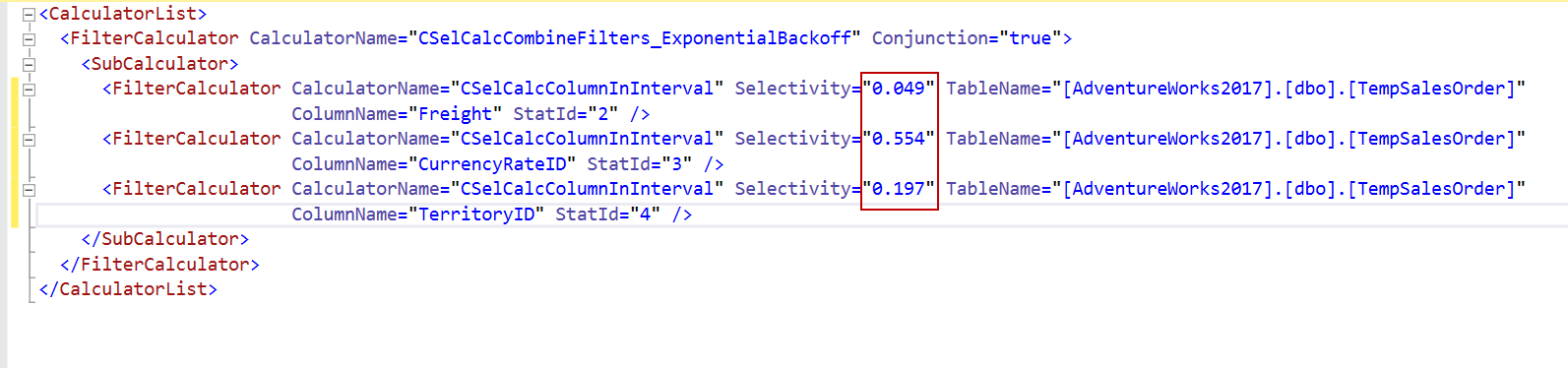
At first, we will sort the predicate selectivity and then apply the formula:
P0=0,049
P1=0,197
P2=0,554
The estimated number of rows = 0,049 * SQRT(0,197) * SQRT(SQRT(0,554)) * 31565
The estimated number of rows = 592,26
As can be seen, the result we found is almost the same as the estimated number of rows returned from the query.
SQL Server statistics and Legacy Cardinality Estimator
In software, development Legacy code terms describe the inherited codes from an older version of the software.
Microsoft has made radical changings the cardinality estimator algorithm in SQL Server 2014 version but the legacy cardinality estimator is still enabled in SQL Server.
We can use the FORCE_LEGACY_CARDINALITY_ESTIMATION hint in the queries to enable this legacy cardinality estimatimator. When we want to enable legacy cardinality at the database level we can apply the following changes in our database :
|
1 2 3 |
ALTER DATABASE SCOPED CONFIGURATION SET LEGACY_CARDINALITY_ESTIMATION = ON; |
As an alternative method, we can enable legacy cardinality in the Database Scoped Configurations.
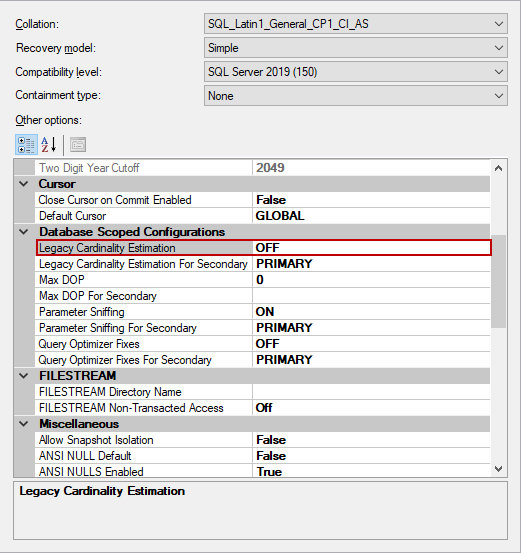
However, if we apply this change to any database the cached query plan will be removed, and if we don’t have serious reason to use legacy estimator using FORCE_LEGACY_CARDINALITY_ESTIMATION hint will be more reasonable at the query level. Using the legacy cardinality estimator will change the estimated number of rows because of the legacy estimated row calculation algorithm. We will execute the following query using the FORCE_LEGACY_CARDINALITY_ESTIMATION query hint.
|
1 2 3 4 5 |
SELECT * FROM TempSalesOrder WHERE Freight =89.4568 AND CurrencyRateId IS NULL OPTION (USE HINT ('FORCE_LEGACY_CARDINALITY_ESTIMATION'),RECOMPILE) |

As we can see, the estimated number of rows is changed when we use the legacy cardinality estimator. In order to calculate the estimated rows when a query uses a legacy cardinality estimator the formula is:
Estimated Number of Rows = P0*P1*P2*…*Pn*Card
Estimated Number of Rows = 0,049137 * 0,55406 * 31565
Estimated Number of Rows = 859,3523
The result we found exact matches with the estimated number of rows returned from the query.
Updating SQL Server statistics in Parallel
Starting from SQL Server 2016 SP2 we can use the MAXDOP hint when we create or update statistics manually. However, how does SQL Server behave when automatically creating or updating statistics operations? The best option to find out this question is monitoring the activities that are performed by the SQL Server behind the scene when it creates SQL Server statistics automatically. In order to demonstrate this scenario, we need to drop all automatically created statistics in the sample table.
|
1 2 3 4 5 6 7 8 |
DROP STATISTICS dbo.TempSalesOrder._WA_Sys_0000000D_149C0161 GO DROP STATISTICS dbo.TempSalesOrder._WA_Sys_00000013_149C0161 GO DROP STATISTICS dbo.TempSalesOrder._WA_Sys_00000016_149C0161 GO |
We will create an event session to capture which activities are performed by the SQL Server.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
CREATE EVENT SESSION [MonitorAutoCreatedStatistics] ON SERVER ADD EVENT sqlserver.auto_stats( ACTION(sqlserver.sql_text) WHERE ([sqlserver].[session_id]=(125))), ADD EVENT sqlserver.object_created( ACTION(sqlserver.sql_text) WHERE ([sqlserver].[session_id]=(125))), ADD EVENT sqlserver.sp_statement_completed( ACTION(sqlserver.sql_text) WHERE ([sqlserver].[session_id]=(125))), ADD EVENT sqlserver.sql_statement_completed( ACTION(sqlserver.sql_text) WHERE ([sqlserver].[session_id]=(125))) WITH (STARTUP_STATE=OFF) GO ALTER EVENT SESSION MonitorAutoCreatedStatistics ON SERVER STATE = START |
In this last step, we execute our sample query. During the execution of this query SQL Server will create three individual statistics.
|
1 2 3 4 5 |
SELECT * FROM TempSalesOrder WHERE Freight =89.4568 AND CurrencyRateId IS NULL AND TerritoryID =4 OPTION (RECOMPILE) |
After execution of the query let’s interpret the extended event data.
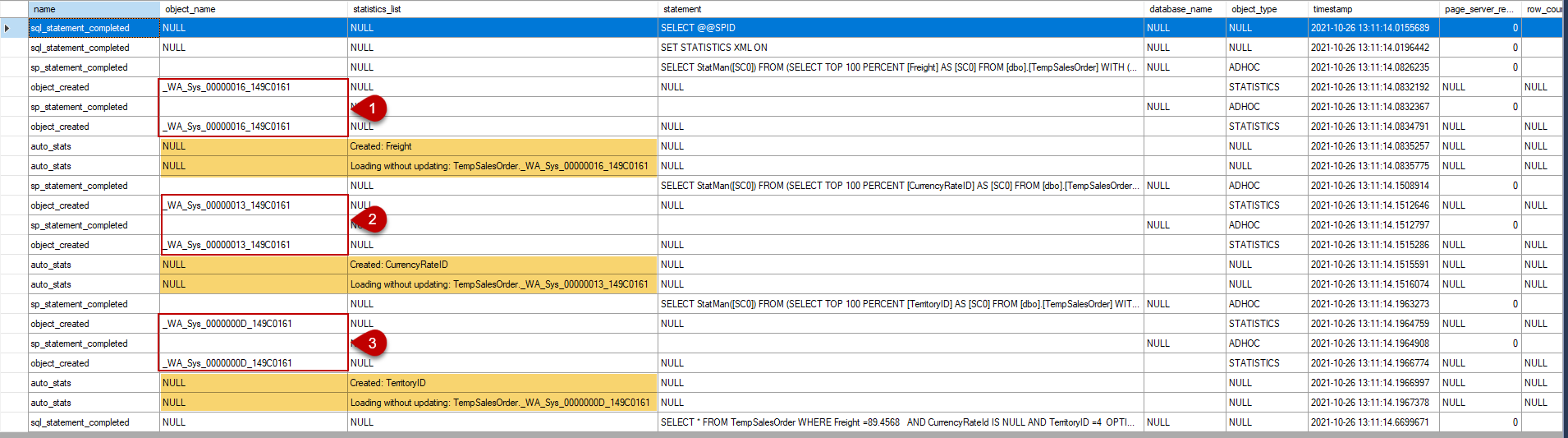
The object_created event shows us three different SQL Server statistics have been created and these statistics are created for every predicate in the query. The auto_stats event indicates these statistics are used by the optimizer after they have been created.
The StatMan is an internal aggregation function and used for statistics operations. We can see the usage of this function in the captured event data.
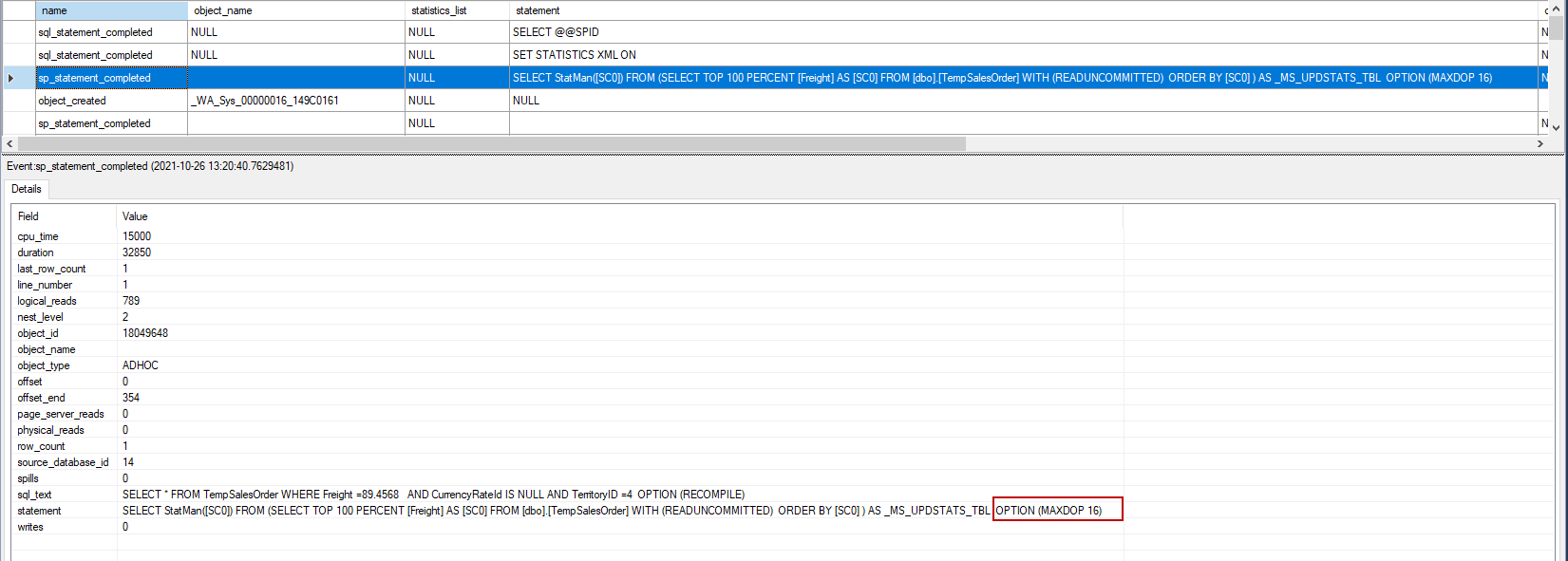
We can see the MAXDOP hint at the end of the query where the Statman function is used, and this shows us that the SQL Server statistics generation process is done in parallel. Shortly, we can say that auto-create and update SQL Server statistics operations can be performed in parallel.
Summary
SQL Server statistics are extremely critical objects for the query optimizer to generate more effective query plans. And also, the cardinality estimator is the core functionality of the optimizer so understanding the cardinality estimator and statistics synergy can be very helpful to interpret query plans more clearly.
References:
SQL Server CE: Multiple single-column statistics
Statistics – Single Threaded & Parallel Operations

Most of his career has been focused on SQL Server Database Administration and Development. His current interests are in database administration and Business Intelligence. You can find him on LinkedIn.
View all posts by Esat Erkec
- SQL Performance Tuning tips for newbies - April 15, 2024
- SQL Unit Testing reference guide for beginners - August 11, 2023
- SQL Cheat Sheet for Newbies - February 21, 2023