
In the previous article of this series on the SQL Server transaction log, we discuss the SQL Server database recovery models, Full, Simple and Bulk-Logged, and the how the recovery model option of the database affects the way the SQL Server Engine works with the transaction logs. In this article, we will discuss the different types of high availability and disaster recovery solutions and the role of the SQL Server transaction log in these technologies.
High Availability and Disaster Recovery Overview
We live now in an IT based world, in which the success and the growth of the business depends mainly on the availability of the critical systems that run it. You will probably not be surprised to hear during Service Level Agreement (SLA) discussions, topics including Recovery Time Objective (RTO) and recovery Point Objective (RPO), and that a second of downtime in financial or tracking systems will not be accepted.
The availability of business applications depend also on the availability of the data that these applications process and store. What is the need for an application that is available without being able to reach to the databases that this application uses?
Working as a database administrator in an international company or a company that provides financial services, you will be asked to provide a reliable high availability and disaster recovery solution that ensures the minimum possible downtime for the database systems in case or any crash, failure or disaster situation. Microsoft provides us with number of technologies that can be used easily to design a reliable high availability and disaster recovery solution.
High availability concepts
Before going through the different high availability and disaster recovery technologies, we should understand the difference between the high availability and disaster recovery concepts. High Availability means that the SQL Server instances or databases will be available and reachable, with the least possible downtime, in case of any server crash or failure. The availability of the SQL Server that is provided by the solution is measured by the number of 9’s in the availability percentage that this solution provides, and the total period of annual downtime, as per the Microsoft table below:
Number of 9’s | Availability Percentage | Total Annual Downtime |
2 | 99% | 3 days, 15 hours |
3 | 99.9% | 8 hours, 45 minutes |
4 | 99.99% | 52 minutes, 34 seconds |
5 | 99.999% | 5 minutes, 15 seconds |
On the other hand, Disaster Recovery means that, when the primary datacenter experiences a catastrophic event, such as an earthquake, flood or war, the system should be brought online and serve the users in another secondary site.
Let us now discuss the different high availability technologies provided by Microsoft SQL Server and the role of the SQL Server transaction log in these technologies.
Log Shipping
The SQL Server Log Shipping is a database level high availability solution, that fits the less mission critical databases with flexible recovery point and recovery time. It consists of one primary database server and one or more standby secondary servers that can be used for reporting purposes.
The operation of the Log Shipping feature requires the database to be in Full recovery model as it depends highly on the Transaction Logs. It starts by restoring the primary database to the secondary servers then the secondary database will be synchronized by the cumulative SQL Server transaction log backups that are taken from the primary database. This will be performed automatically using three SQL Server Agent jobs. The first job will take transaction log backup from the primary database, the second job will copy that transaction log backup to the secondary servers and the third job will restore these transaction log backups to the secondary databases, without performing the recovery process on the secondary databases. This means that, the secondary databases will not be brought online. Instead, it will be in restoring or standby mode, waiting for the next SQL Server transaction log backup from the primary server, as shown below:
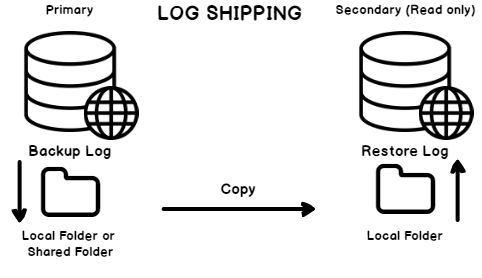
The failover between the primary and the secondary servers in Log Shipping, known as role change, should be performed manually using a T-SQL command. Check What is the SQL Server Log Shipping and How to Create SQL Server Log Shipping for more information.
Transactional Replication
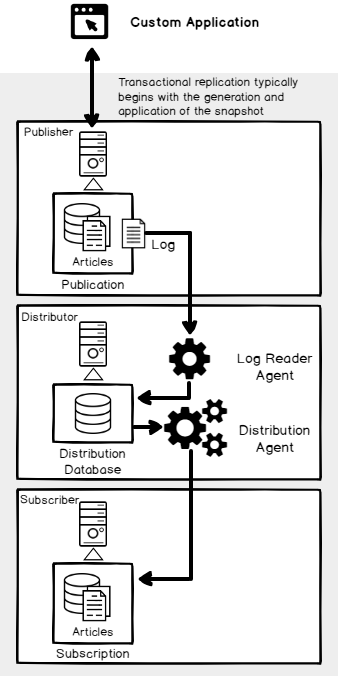
SQL Server Transactional Replication is a real time, database level, high availability solution, that consists of one primary server, known as Publisher, that distributes all the database tables, or selected tables known as articles, to one or more secondary servers, known as Subscribers, that can be also used for reporting purposes.
As the name indicates, Transactional Replication depends on a synchronization process with the SQL Server Transaction Logs.
It works with three agents;
- the SQL Server Snapshot Agent that prepares the starting snapshot file that contains the database objects to be replicated, you can imagine it as a full backup file
- The Distribution Agent is responsible for copying the initial snapshot and the cumulative logs to the subscribers
- The Log Reader Agent is responsible for monitoring the SQL Server transaction log in the publisher database and copy these transactions from the transaction log file of that database to the distribution database, to be copied to the subscribers by the distribution agent later, as shown below:
- Note: Please see the following articles on SQL Replication basics, SQL Server Transactional Replication and SQL Server Replication configuration for more information.
Database Mirroring
SQL Server Database Mirroring is a database level high availability solution, that can be configured on databases with full recovery model. It consists of minimum two servers; the primary SQL Server, known as Principal server and the secondary server, known as the Mirror server, and optionally a third server, known as Witness server. The Witness server will monitor the connection between these two servers and its availability and perform the automatic failover, or the role change, between these two servers.
SQL Server Database Mirroring works in two synchronization mode;
- High-safety mode, also known as synchronous mode, in which the transaction will be committed on the principal database after committing it and writing it to the transaction log file on the mirror database, which increases the possibility of transactions latency
- In high-performance synchronization mode, also known as Asynchronous mode, the transaction will be committed on the principal database without waiting for it to be committed on the mirror server, decreasing the possibility of transactions latency but increasing the possibility of data loss
Database Mirroring is started by restoring a full backup and a SQL Server Transaction Log backup from the principal database to the mirror server, without bringing the mirror database online. After configuring Database Mirroring, the mirror database will be synchronized by sending the active Transaction Log records to the mirror database and redoing all these operations on the mirror database, as shown below:
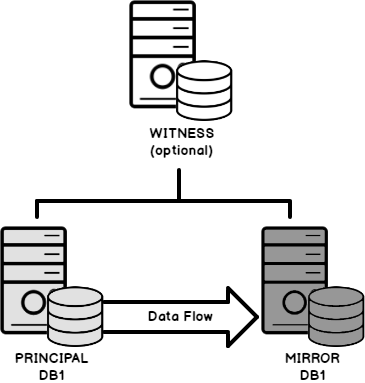
Check the SQL Server mirroring concept, How to configure SQL Server Mirroring and Configuring the SQL Server Mirroring on TDE encrypted database, for more information.
Always on Failover Cluster
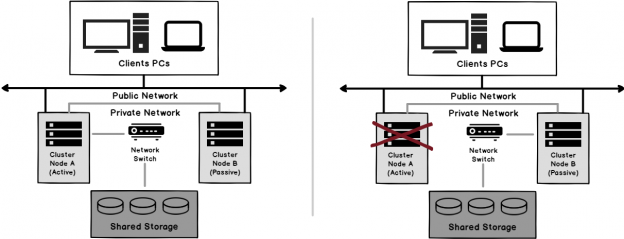
SQL Server Always on Failover Cluster is an instance level high availability solution, that is built over the Windows Server Failover Clustering functionality. It consists of number of servers, known as cluster nodes, that has the same hardware and software components, in order to provide high availability for the failover cluster instance through that redundancy.
When the SQL Server Failover Cluster is configured and started, the SQL Server services and the resource groups, including the shared storage, the network name and the virtual IPs, can be owned only by one of the cluster nodes at a given time.
If any failure, such as operating system, hardware or service failure, occurred on the active node that owns the resource groups and has the SQL Server service online, or simply a planned reboot or upgrade for that active node will be performed, the ownership of the resource group will be completely moved to another cluster node, where the SQL Server instance will be taken offline on the previous active node then brought online on the new node that is owning the resource group, as shown below:
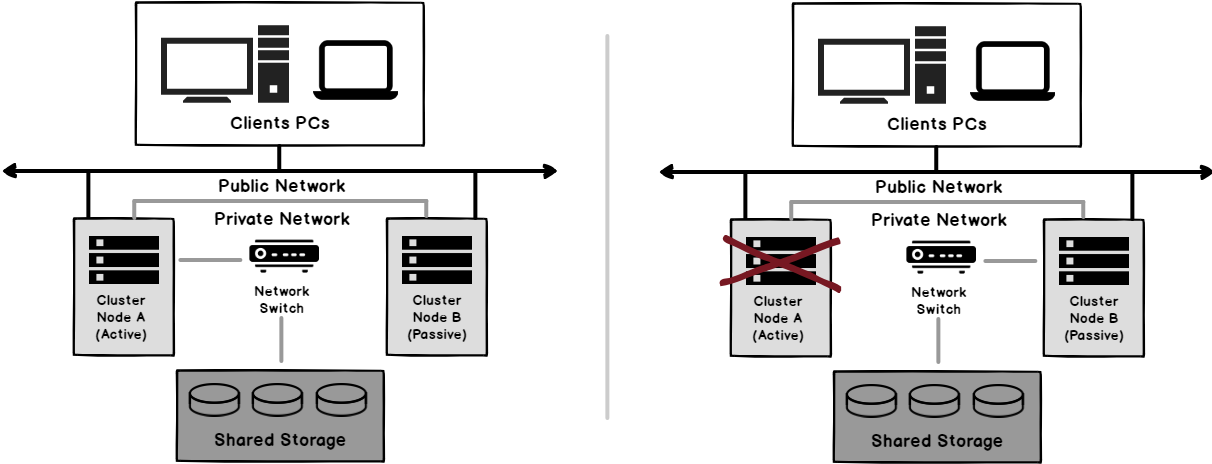
You can see that, in the SQL Server Always On Cluster, there is no role for the SQL Server Transaction Log, as it will be configured at the SQL Server instance level, without the need to synchronize the changes between the different nodes. In other words, the SQL Server database will be located and online on one node at a given time, with no replica for that database on the other cluster nodes.
- Note: See the articles What is SQL Server Failover Clustering and How to Install a Clustered Instance for more information.
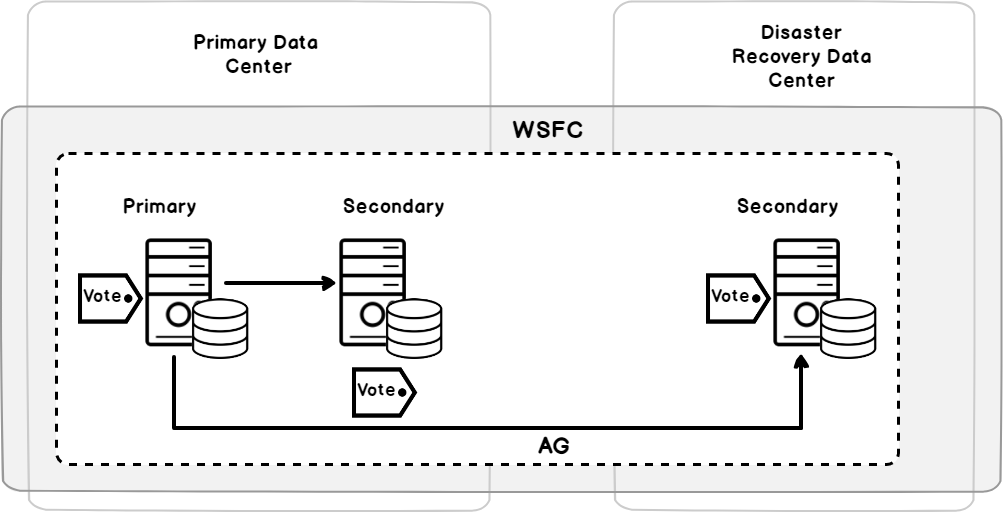
Always on Availability Groups
The SQL Server Always on Availability Group feature, introduced the first time in SQL Server 2012, is a database level high availability solution, that is built over the Windows Server Failover Clustering functionality. It consists of number of one primary server, known as Primary replica, in which the databases will be available to serve read-write connections, and up to eight secondary servers, known as Secondary replicas, that can be used to serve read-only connections for reporting purposes.
The Availability Group is a set of user databases that failover together between the availability replicas. In other words, a database level issue, such as database corruption or data loss, will not force the availability group to be failed over to another replica, where a database failure will not affect other databases in the same availability group.
To make it easier for the database users to connect to the availability group without the need to know which SQL Server instance is hosting the primary replica, an Availability Group Listener can be created. An availability group listener is a virtual network name, that consists of a unique DNS name, one or more virtual IP addresses and a TCP port number, that provides a direct connection to the appropriate replica of the availability group, by routing the read-write workload to the primary replica and route the read-only workload to the secondary replica, if the read-only routing list is configured on that availability group.
- Note: See the article How to Configure Read-only Routing List for an Availability Group for more information.
The data synchronization between the primary replica and the secondary replicas occurs at the database level and depends highly on the SQL Server Transaction Log of that database. The primary replica sends the transaction log records from each database participating in the availability group to all secondary replicas. In the other side, the secondary replicas will write these transaction logs in the database transaction log file for caching, then redo these logs in the corresponding secondary database. If the secondary replica is configured for asynchronous-commit mode, the primary replica will not wait for the secondary replica to write incoming transaction log records to disk. Take into consideration that, the server level changes or changes that are not written to the SQL Server transaction log file, such as the logins, linked servers and the SQL Agent jobs, will not be synchronized automatically between the availability group replicas and require you to synchronize it manually in the secondary replicas.
- Note: See the articles Always On Availability Groups, Always On Availability Groups with Direct Seeding, and Synchronizing the SQL Server Instance Objects in Always On Availability Groups for more information.
For this point, we should understand the importance of the SQL Server Transaction Log for the different types of the high availability and disaster recovery solutions. In the next article, we will show how to manage and monitor the growth of the SQL Server Transaction Log file. Stay tuned!
Table of contents

He is a Microsoft Certified Solution Expert in Data Management and Analytics, Microsoft Certified Solution Associate in SQL Database Administration and Development, Azure Developer Associate and Microsoft Certified Trainer.
Also, he is contributing with his SQL tips in many blogs.
View all posts by Ahmad Yaseen
- Azure Data Factory Interview Questions and Answers - February 11, 2021
- How to monitor Azure Data Factory - January 15, 2021
- Using Source Control in Azure Data Factory - January 12, 2021