
This article will cover SQL Server replication configuration including Peer to peer replication and merge replication, initial configuration, adding nodes and data verification.
Configuring Peer to Peer SQL Server Replication
SQL Server Peer to Peer replication is a replication type where the publisher server replicates data to multiple subscriber servers at the same time.
Peer to peer SQL Server replication is useful for multiple data center locations across the globe. One centralized data center manages the data on the other datacenter data.
Pre-requisites
Before configuring SQL Server replication, we need to sync the database which needs to replicate, with all other nodes. We will make the database in sync with other peer nodes by taking a backup of the database on the publisher server and restore it on the peer nodes.
After restoring the database on the peer nodes, there should not any changes in the published database before configuring SQL Server replication; otherwise, it may occur conflict. If there are any data changes in the database, then we need to take a new backup and specify a new backup file path.
We will use the following server configuration to configure Peer to Peer replication-
- SQL1 – The Publisher
- SQL2 – The Subscriber act as a 1st peer node
- SQL3 – The Subscriber act as a 2nd peer node
- Database – AdventureWorksLT2012
Configure the Distribution
In the Peer to Peer replication, we need to configure the Distribution database on all the peer nodes.
Note: Configure the Distribution database on all the peer nodes in the same way as per the Steps PART-1 Configure the Distribution from the SQL Server replication: Configuring Snapshot and Transactional Replication article.
Database backup restore on the peer nodes
Once the distribution database configured on each node, before setting the publication on the SQL1, we need to restore the backup of the published database AdventureWorksLT2012 on each peer nodes. Once a backup is restored, we will proceed to configure the Publication.
Configure the Publisher
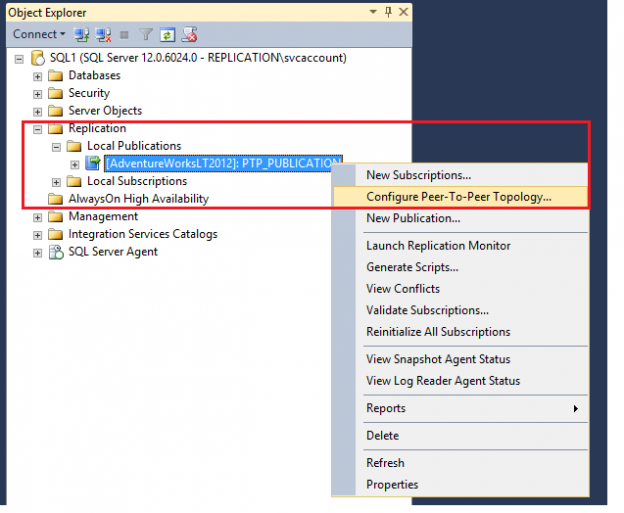
- Right-click the New Publication and Select New Publication
-
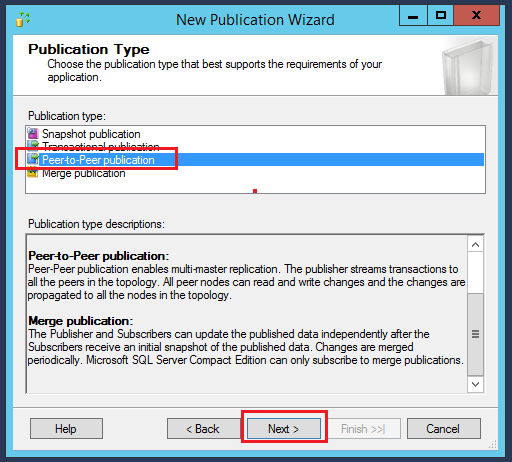
Select Peer-to -Peer publication as a publication type and click Next

- Next, kindly proceed to the next steps as per the standard configuration steps of the publication as per PART-2 Configure the Publisher from the SQL Server replication: Configuring Snapshot and Transactional Replication article
-
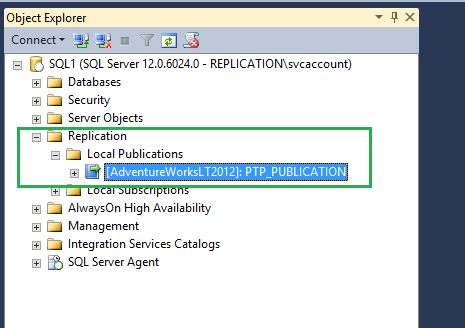
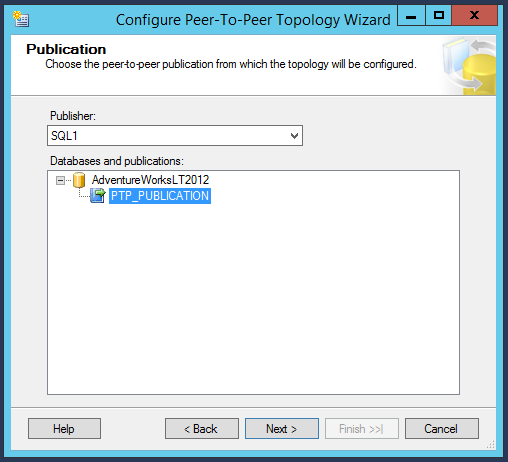
Once Publication configured, we can see publication [AdventureWorksLT2012]: PTP_PUBLICATION is ready to use as shown in the following fig
Configure Peer to Peer Topology
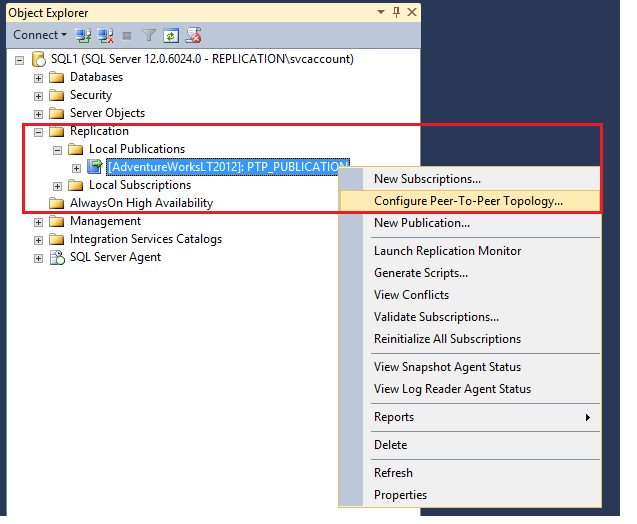
- Right-click publication and select Configure Peer to Peer topology
-
Select SQL1 as the publication and click Next
-
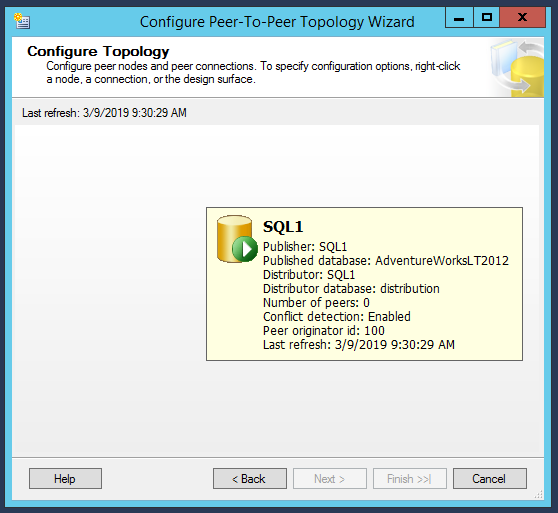
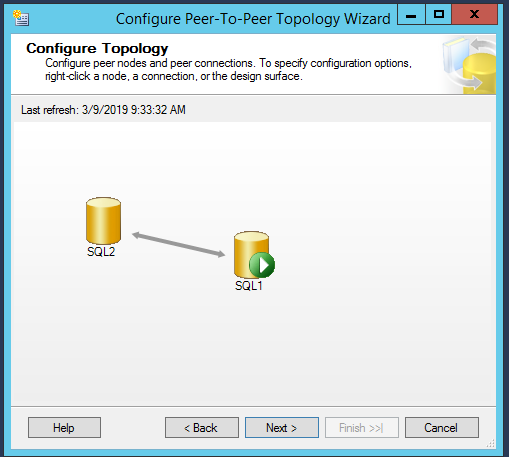
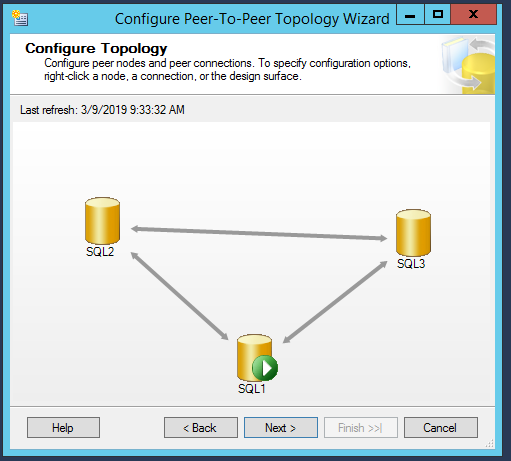
In the configure topology window, SQL1 set as the published database. A green arrow indicates the published database. We need to add another node as a peer under the published database. It is recommended to make any Insert, update, delete and schema changes from the publisher to the peer nodes to avoid the data conflicts
- Peer originator id is 100, so any other peer which we will add should not have the same identifier
- We can see Conflict detection is enabled so that if the update operation is running on peer node and at the same time, someone initiates to delete same data from the publisher, then conflict will occur, and it will generate an alert
-
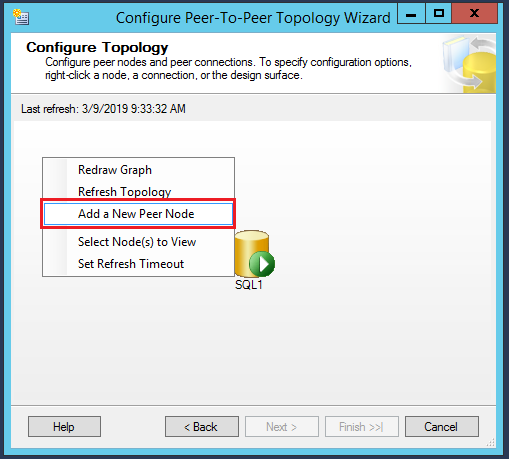
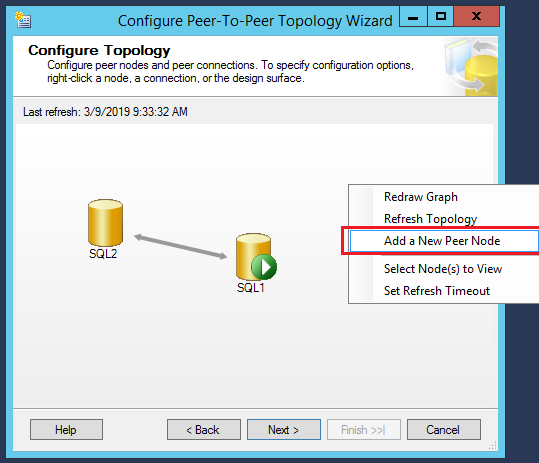
To add a node, Right click in the gray surface area and select Add a New Peer Node
-
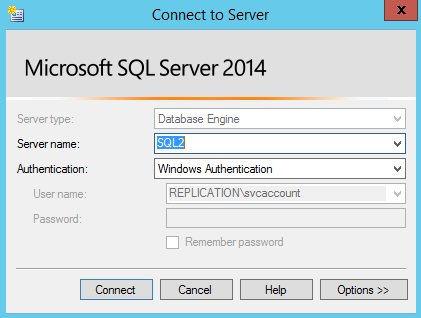
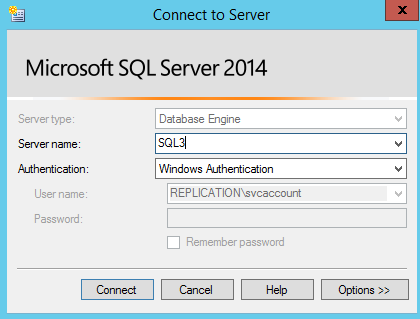
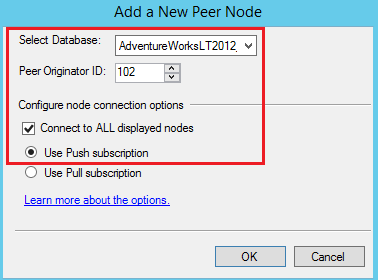
Connect to node SQL2
-
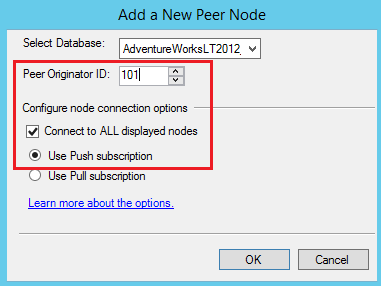
Select the database on the node SQL2 and configure the option as shown in the following window. We will select Peer Originator ID 101, as the published database has peer originator ID 100. In the Push subscription, all the agent will configure at the publisher who will transfer transaction data to the subscriber. It will push the data from the Publisher to subscriber
-
SQL2 is added as a peer node into topology as shown in the following window. Click Next
-
We will add one more node SQL3 in the peer to peer topology in the same way
-
The node SQL2 and SQL3 are added into peer to peer topology as shown in the following window. The arrow which is connecting to each node indicates the data flow
-
Next, click on the below icon and proceed to provide connection of the service account
-
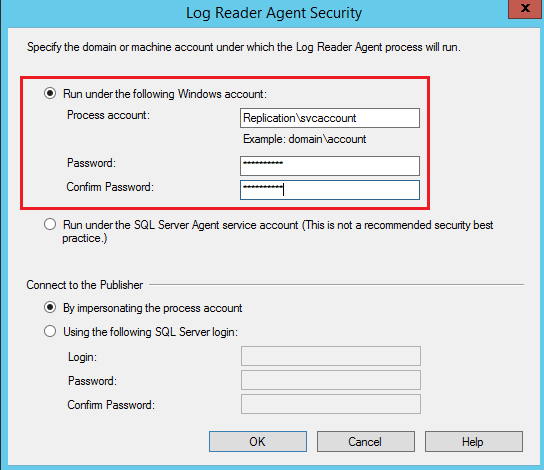
Provide the service account login details and click Next
-
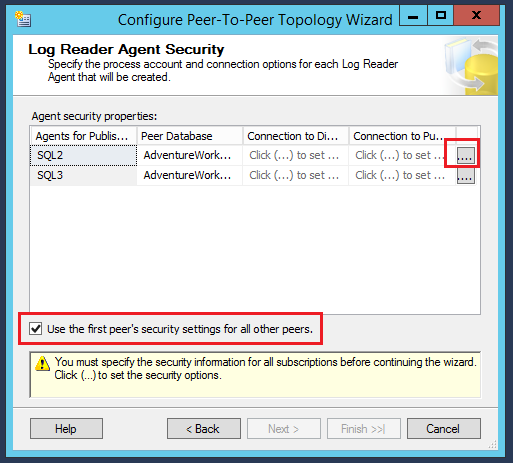
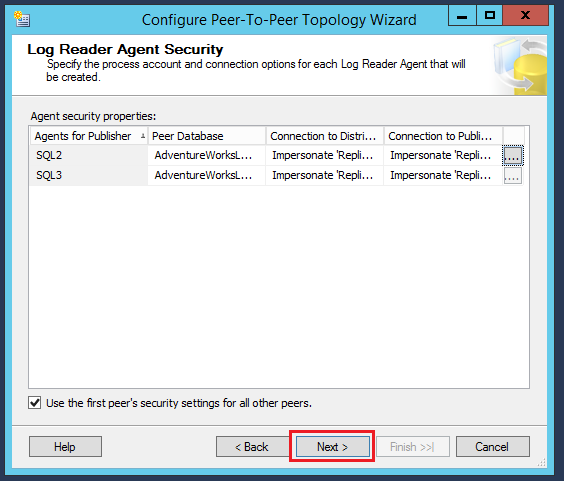
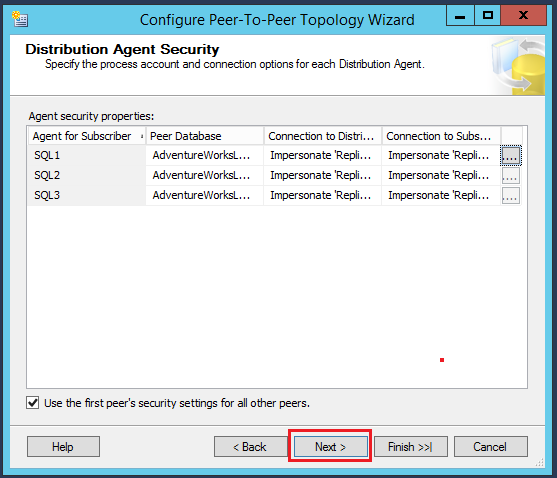
In the distribution agent security, provide the connection details of the service account the same as the previous step
-
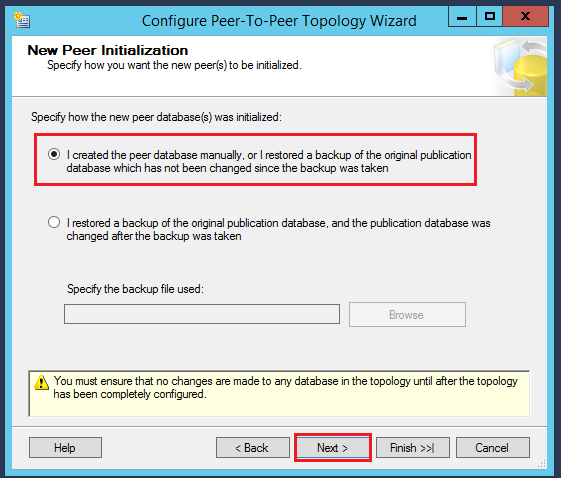
In the New Peer initialization step: – There are two options:
- Backup restored, and a published database not changed
If the backup of the published database restored on the other peer nodes SQL2 and SQL3, then data on the peer nodes should not have changed since the last backup
- Backup restored, and the published database changed
We need to select this option when we restored the published database backup to the peer nodes, and after restoration, the published database changed, then again, we need to take backup of the database and specify the path of the new backup file
- Backup restored, and a published database not changed
-
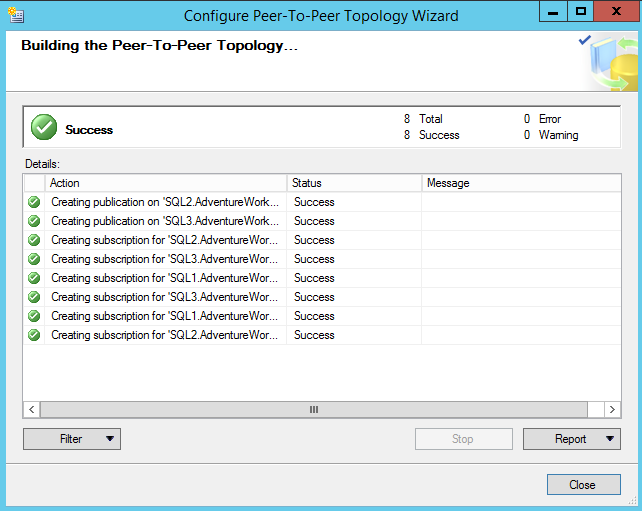
Review the following actions for the publication and subscription for the peer nodes. Click Finish
-
The following peer to peer topology process completed successfully

Data Verification
In this example, we will make data change on the Publisher server SQL1 and will verify whether it makes the same change or not on the peer node server SQL2 and SQL3
-
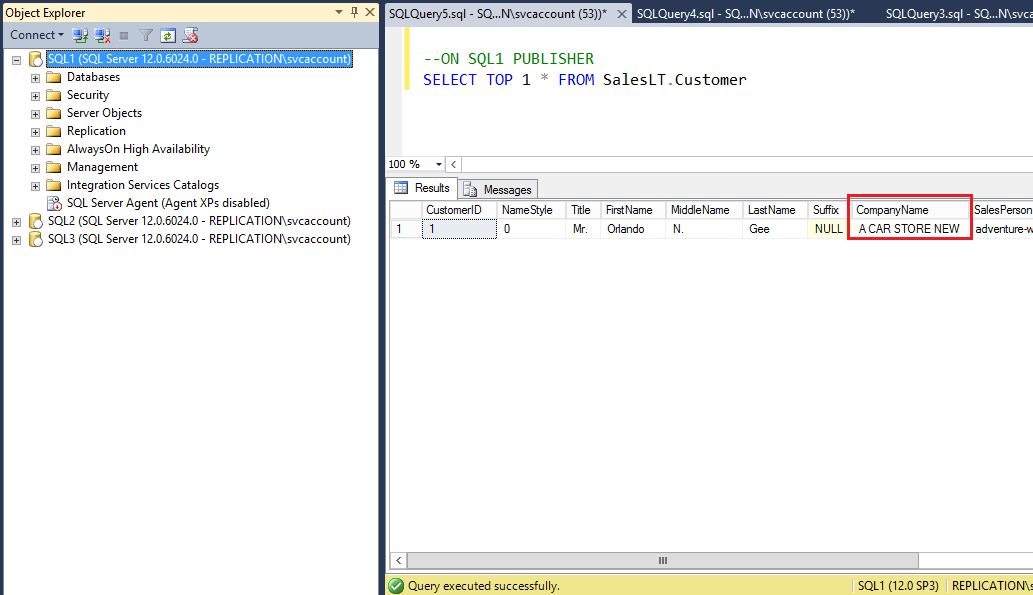
On the Publisher SQL1, we will update the CompanyName Column value of the table CUSTOMER
-
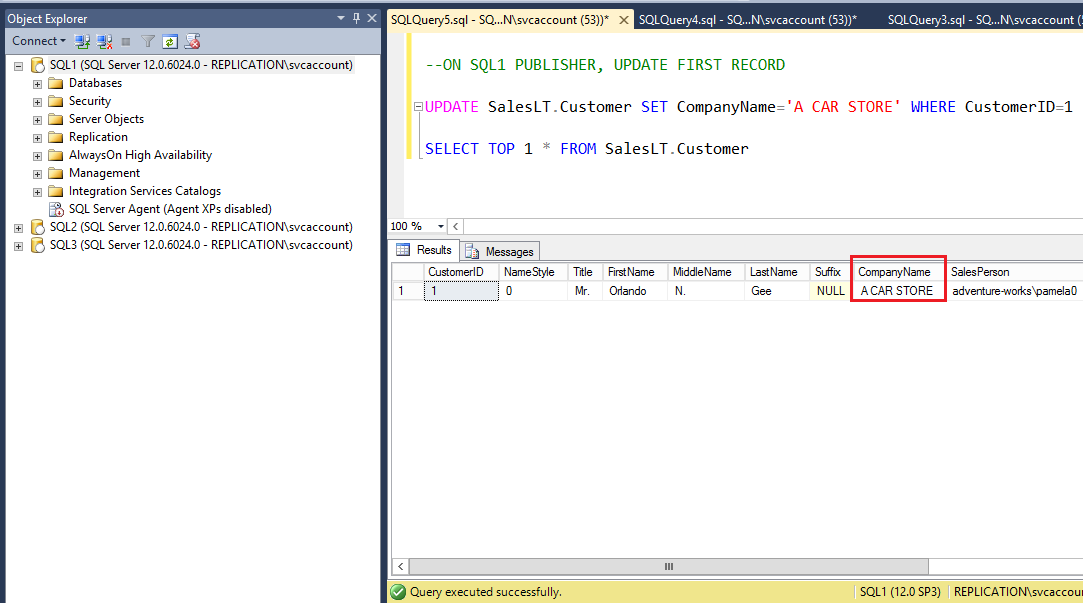
On the SQL1, Update CompanyName column value to new value A CAR STORE
-
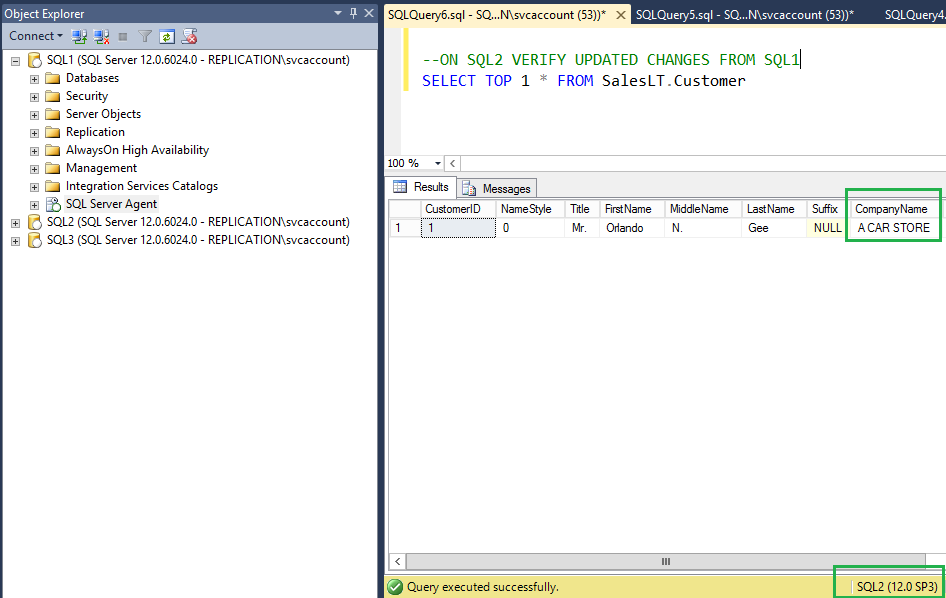
On the Peer node SQL2, verify new value has been updated for the CompanyName column as shown in the following fig
-
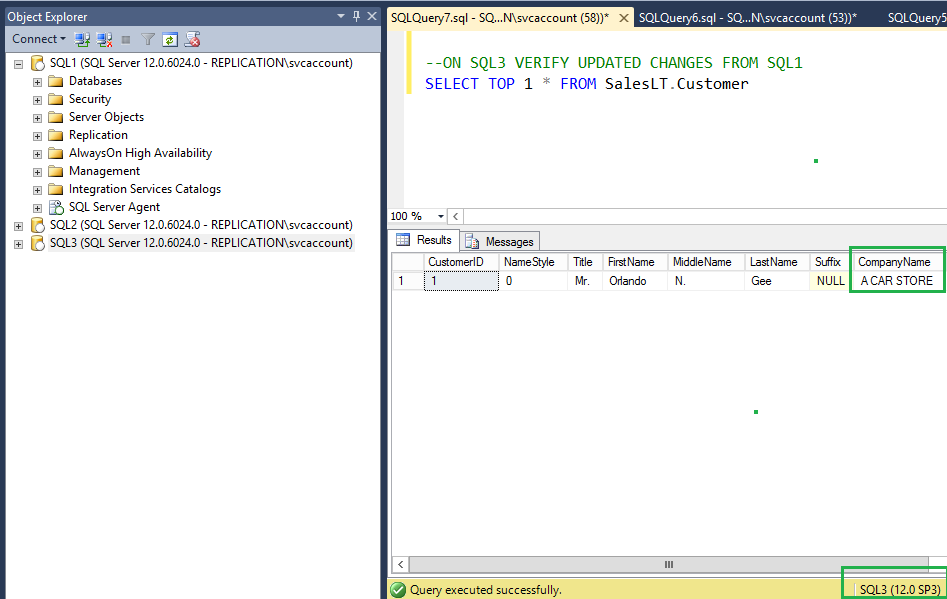
On the Peer node SQL3, verify new value has been updated for the CompanyName column as shown in the following fig
Configuring Merge Replication
Merge Replication is the same as SQL Server Transactional replication; however, Merge replication replicates data from the Publisher to Subscriber and vice-a-versa. Though Merge replication is two-way change replication; however, we need to make any Schema changes only on the publisher, schema changes will not allow on the subscriber. Any schema changes on the publisher will make the change on the subscriber.
Merge replication uses the Snapshot Agent and the Merge Agent. The snapshot agent takes the snapshot of the published articles and put it into the snapshot folder. Merge agent can connect to both the publisher and the subscriber, it applies the Snapshot to the subscriber, and it tracks the changes from both publisher and the subscriber and transfers those changes to the distribution database further to use to the subscriber. The advantage of merge replication is that it can also work with no network connection.
Configure the Distribution
- Configure the Distribution step by step as per PART-1 Configure the Distribution from the SQL Server replication: Configuring Snapshot and Transactional Replication article
Configure the Publication
- Right click local publication and select New Publication
-
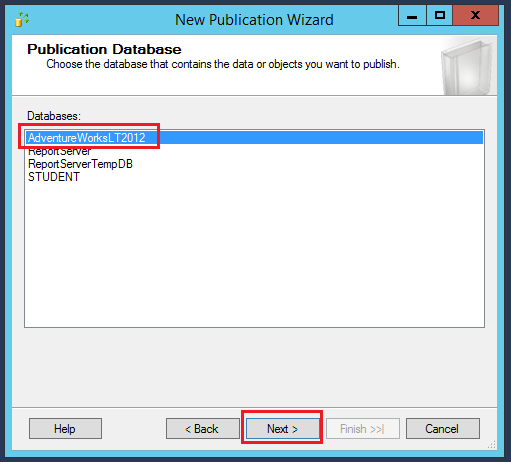
Select the database and click Next
-
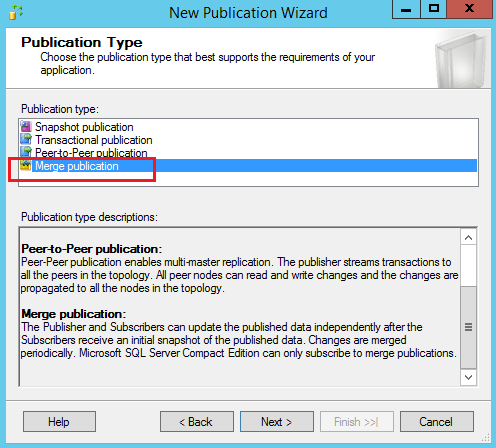
Select Merge publication as a publication type and click Next
-
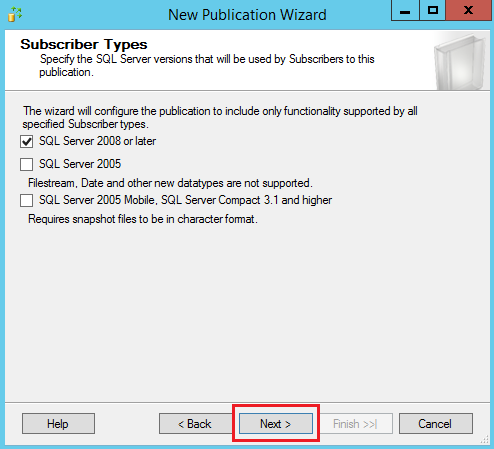
Select the version of the SQL Server in the following window and click Next
-
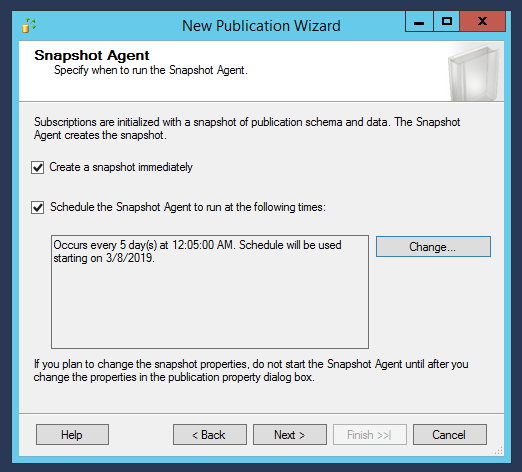
Tick Create a Snapshot immediately option and schedule the snapshot agent as per your requirement
- Kindly proceed to next publisher steps same as PART-2 Configure the publication from the SQL Server replication: Configuring Snapshot and Transactional Replication article
- To configure the Subscriber, kindly continue to perform steps same as PART-3 Configure the Subscriber from the SQL Server replication: Configuring Snapshot and Transactional Replication article
- Once the Publisher and the Subscriber configured, we can see the database AdventureWorksLT2012_MERGE is online in the subscriber instance SQL2
Data verification for Merge Replication
In this example, we will make data change on the Subscriber server SQL2 and will verify whether it makes the same change or not on the Publisher server SQL1.
-
Run below query on the subscriber SQL2
-
Update records on the subscriber SQL2
- Verify the data on Publisher SQL1
- The modified value of the column CompanyName on the subscriber is updated on the publisher SQL1 as shown in the following window. So, data changes on the publisher, it will also change on the subscriber and vise-a-versa
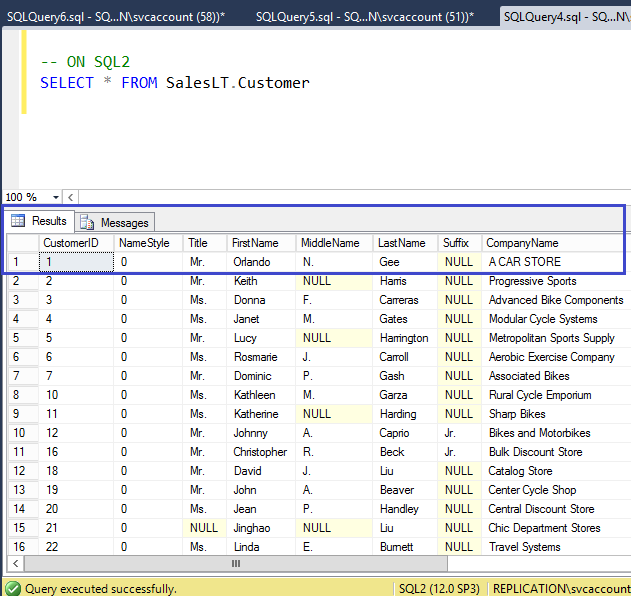
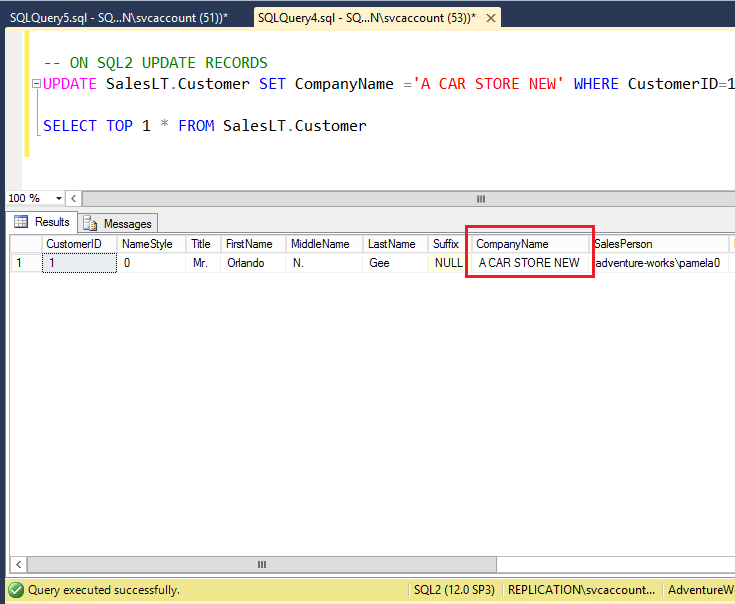
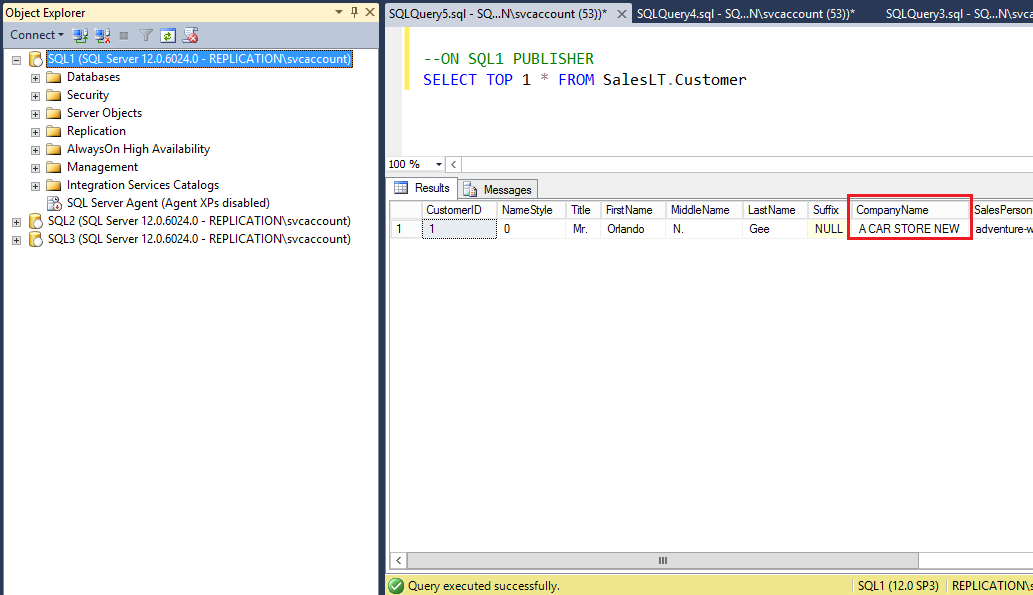
Table of contents
| SQL Server replication configuration: Peer to Peer and Merge Replication |
| SQL Server replication: Configuring Snapshot and Transactional Replication |
| Add new articles, drop the article, change the snapshot folder path and Data filter rows in SQL Server Replication |

- Add new articles, drop the article, change the snapshot folder path and Data filter rows in SQL Server Replication - April 2, 2019
- SQL Server replication: Configuring Snapshot and Transactional Replication - March 15, 2019
- SQL Server replication configuration: Peer to Peer and Merge Replication - March 15, 2019