This article gives you an overview of representing coronavirus spread using Power BI Desktop visualizations.
Read more »Rajendra Gupta

Hi! I am Rajendra Gupta, Database Specialist and Architect, helping organizations implement Microsoft SQL Server, Azure, Couchbase, AWS solutions fast and efficiently, fix related issues, and Performance Tuning with over 14 years of experience.
I am the author of the book "DP-300 Administering Relational Database on Microsoft Azure". I published more than 650 technical articles on MSSQLTips, SQLShack, Quest, CodingSight, and SeveralNines.
I am the creator of one of the biggest free online collections of articles on a single topic, with his 50-part series on SQL Server Always On Availability Groups.
Based on my contribution to the SQL Server community, I have been recognized as the prestigious Best Author of the Year continuously in 2019, 2020, and 2021 (2nd Rank) at SQLShack and the MSSQLTIPS champions award in 2020.
Personal Blog: https://www.dbblogger.com
I am always interested in new challenges so if you need consulting help, reach me at rajendra.gupta16@gmail.com
View all posts by Rajendra Gupta
I am the author of the book "DP-300 Administering Relational Database on Microsoft Azure". I published more than 650 technical articles on MSSQLTips, SQLShack, Quest, CodingSight, and SeveralNines.
I am the creator of one of the biggest free online collections of articles on a single topic, with his 50-part series on SQL Server Always On Availability Groups.
Based on my contribution to the SQL Server community, I have been recognized as the prestigious Best Author of the Year continuously in 2019, 2020, and 2021 (2nd Rank) at SQLShack and the MSSQLTIPS champions award in 2020.
Personal Blog: https://www.dbblogger.com
I am always interested in new challenges so if you need consulting help, reach me at rajendra.gupta16@gmail.com
View all posts by Rajendra Gupta
Latest posts by Rajendra Gupta (see all)
- Understanding PostgreSQL SUBSTRING function - September 21, 2024
- How to install PostgreSQL on Ubuntu - July 13, 2023
- How to use the CROSSTAB function in PostgreSQL - February 17, 2023
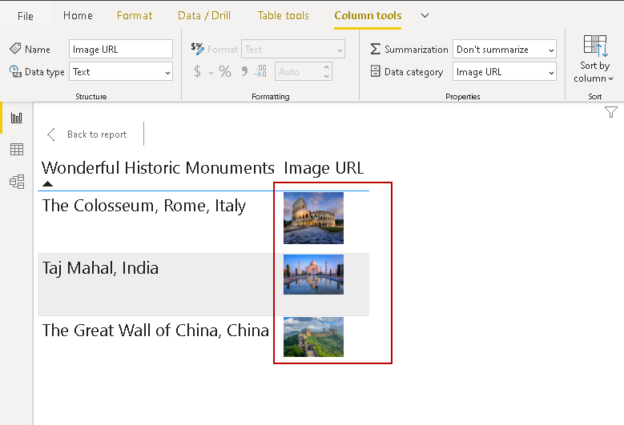
Working with images in Power BI Desktop reports
April 6, 2020Introduction
In the article Web URL configuration in a Power BI Desktop report, we explored a different method to use Web URL in a Power BI report. Images help to improve the visual appearance of a report. You can convey messages easily using these images in a report.
Read more »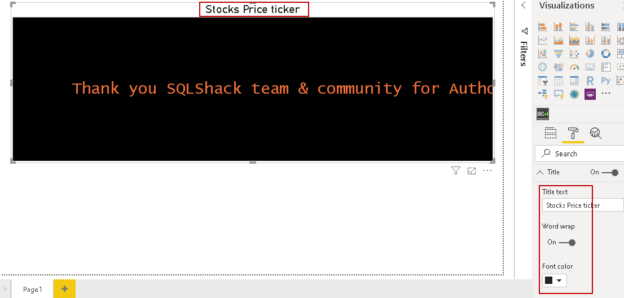
Scroller visual for Stock price movements in Power BI Desktop
March 31, 2020In the article, Candlestick chart for stock data analysis in Power BI Desktop, we explored Power BI Desktop to analyze stock prices. If you follow the stock market, you might have noticed a ticker (similar to the following image) showcasing stock prices and changes since the last close price. It shows an up and down indicator depending upon the positive or negative change in the stock price.
Read more »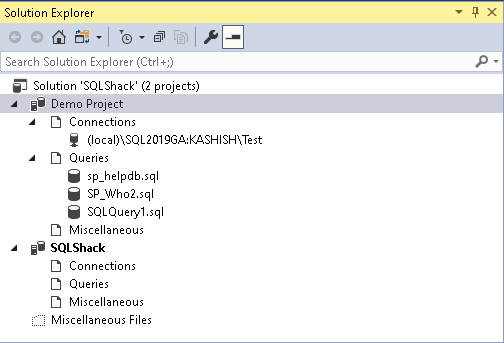
Overview of Solutions and Projects in SSMS
March 30, 2020DBAs and developers manage a broad set of queries, codes, applications. It is a good practice to organize code or t-SQL scripts so that we can easily access them without wasting time searching for them. You might use Visual Studio, GitHub source control for it. In this article, we look at how Solutions and Projects help to organize T-SQL scripts.
Read more »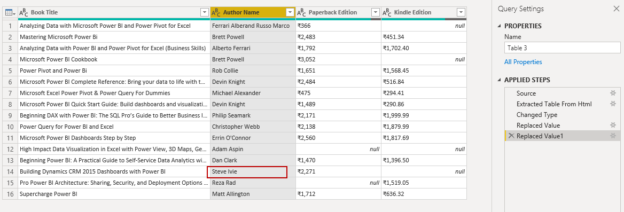
How to use a Web data source in Power BI Desktop reports
March 30, 2020This article explores various ways to use a Web data source in Power BI Desktop reports.
Read more »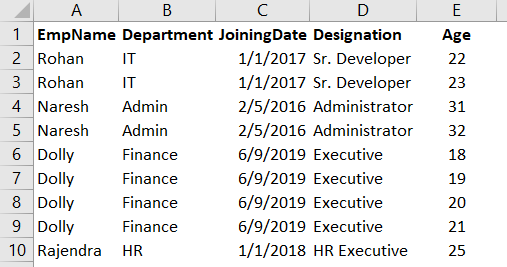
Removing duplicates in an Excel sheet using Python scripts
March 24, 2020In the article, Python scripts to format data in Microsoft Excel, we used Python scripts for creating an excel and do various data formatting. Python is an interesting high-level programming language. You can go through various use cases of Python on SQLShack.
Read more »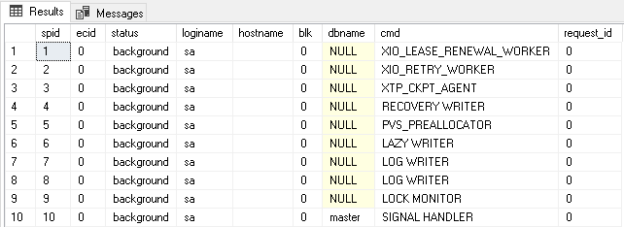
An overview of the sp_WhoIsActive stored procedure
March 23, 2020This article gives a comprehensive overview of custom stored procedure sp_whoisactive.
Read more »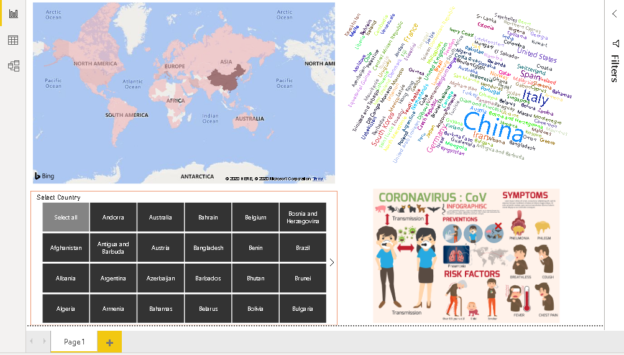
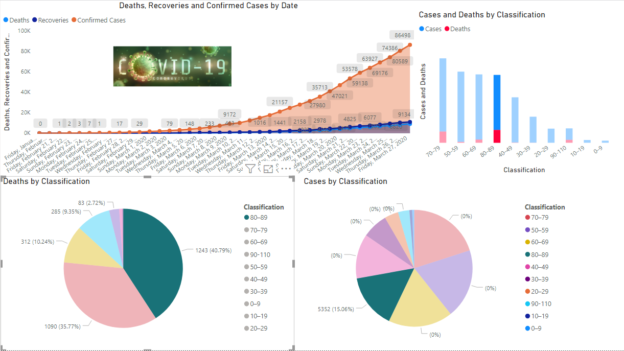
Visualize Coronavirus impact using a Power BI Dashboard
March 20, 2020This article demonstrates Power BI visuals for visualizing Coronavirus impact worldwide using various visuals such as a filled map, Word Cloud, Slicer, Q&A.
Read more »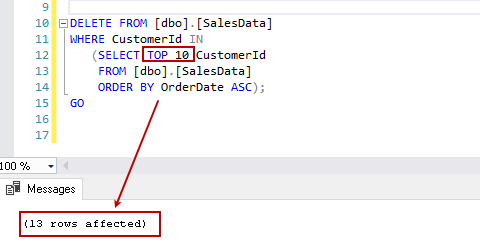
SQL Server TOP clause overview and examples
March 19, 2020This article explores the SQL Server TOP clause using various examples, along the way, we will also run through performance optimization while using the TOP clause in SQL Server.
Read more »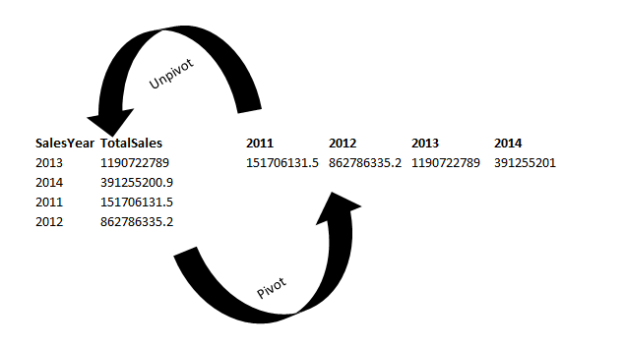
Python scripts for pivot tables in SQL Server
March 13, 2020This article talks about Python scripts for creating pivot tables in multiple ways.
Read more »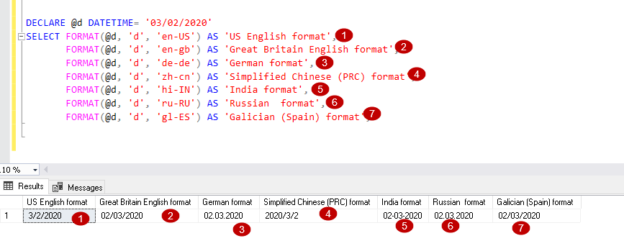
A comprehensive guide to the SQL Format function
March 11, 2020This article explains the usage of SQL Format function and performance comparison with SQL CONVERT.
Read more »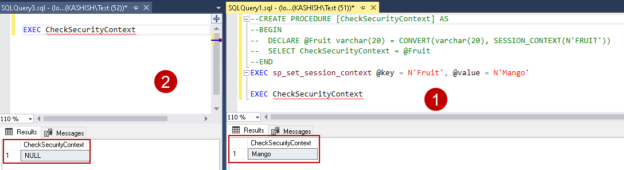
SQL Server SESSION_CONTEXT() function with examples
March 9, 2020This article explores the SQL Server session context function, SESSION_CONTEXT() and performs its comparison with the function, CONTEXT_INFO().
Read more »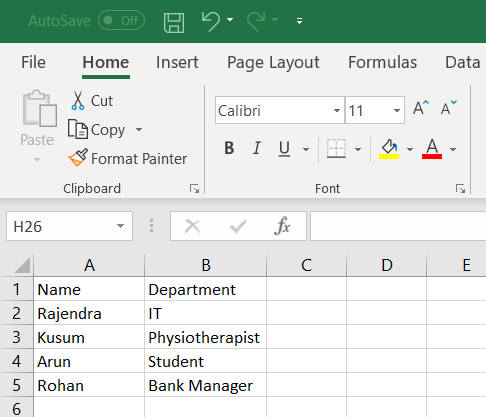
Python scripts to format data in Microsoft Excel
March 9, 2020In this article, we will use Python scripts for data formatting in Microsoft Excel sheet with various examples.
Read more »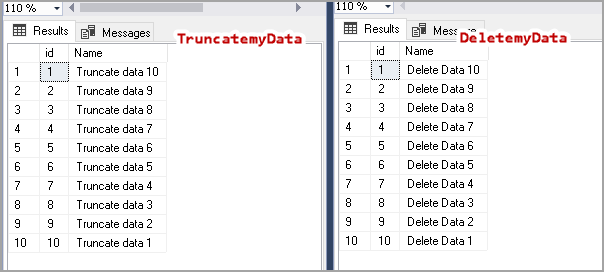
How to use database backups to recover data after SQL Delete and SQL Truncate statements
March 4, 2020This article explores the recovery of data removed by SQL Delete and SQL Truncate statements using SQL database backups.
Read more »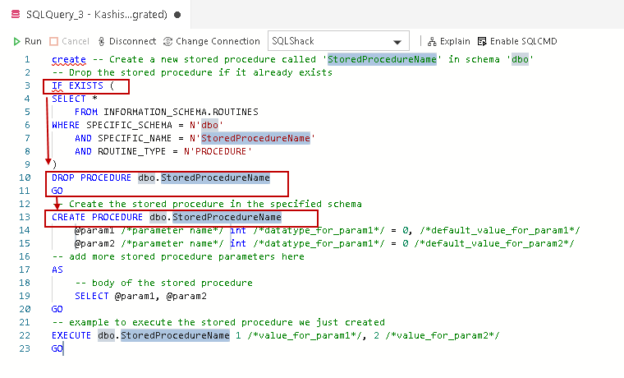
Overview of the T-SQL If Exists statement in a SQL Server database
March 3, 2020This article walks through different versions of the T-SQL IF EXISTS statement for the SQL database using various examples.
Read more »
Learn Markdown language for SQL Notebooks in Azure Data Studio
February 26, 2020Microsoft supports SQL Notebooks in Azure Data Studio. It is an exciting feature that allows creating a notebook for multiple languages such as Python, SQL, PowerShell. You might have heard about the Jupyter notebook. It is a popular web-based notebook that provides rich programming language support. SQL Notebook is an inspiration for the Jupyter notebook.
Read more »
Learn Jupyter Notebooks for SQL Server
February 25, 2020Introduction
The Jupyter notebook is a powerful and interactive tool that supports various programming languages such as Python, R, Julia. This open-source utility is popular among data scientists and engineers. This notebook integrates both code and text in a document that allows you to execute code, view visualization, solve mathematical equations.
Read more »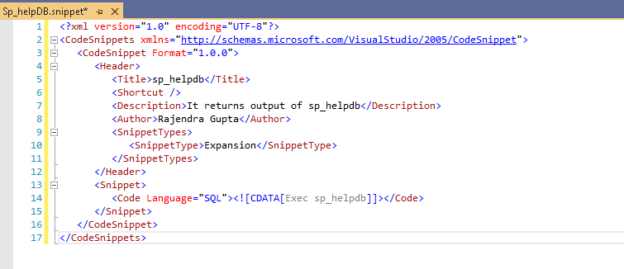
An overview of Code Snippets in SSMS
February 24, 2020This article explores the SSMS Code Snippet feature and ways to customize it.
Read more »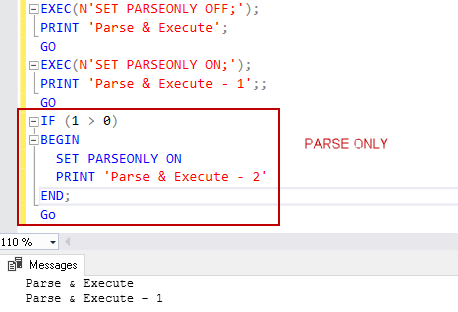
The PARSEONLY SQL command overview and examples
February 21, 2020This article explores the uses of the SET PARSEONLY SQL command for SQL Server queries.
Read more »
The internals of SQL Truncate and SQL Delete statements
February 21, 2020This article gives you an insight into the SQL Truncate and SQL Delete commands behavior.
Read more »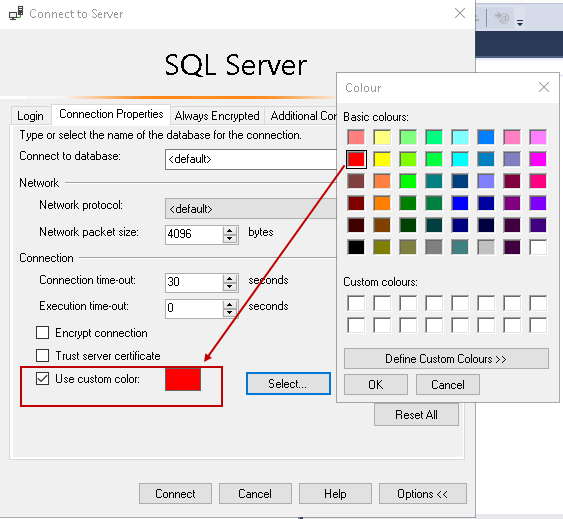
How to set custom colors in the SSMS status bar
February 19, 2020This article explains the process of defining custom color codes for SQL Server connections in SSMS.
Read more »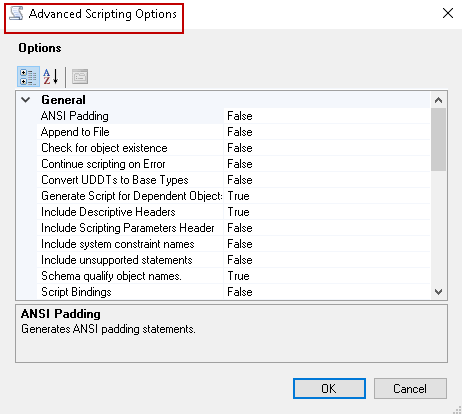
Methods to script SQL Server database objects
February 14, 2020In this article, we will explore various ways for scripting SQL Server database objects.
Read more »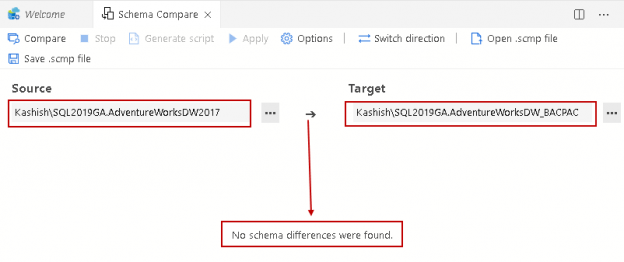
Importing a BACPAC file for a SQL database using SSMS
February 6, 2020This article gives you an overview of BACPAC package and its usage in SQL Database data refresh (data import and export) using SQL Server management studio.
Read more »
Web URL configuration in a Power BI Desktop report
February 6, 2020Power BI Introduction
Power BI Desktop provides many useful visualizations with simple configurations. You can represent data visually in different forms that help users and management in data interpretation. You can explore a broad category of Power BI articles here on SQLShack.
Read more »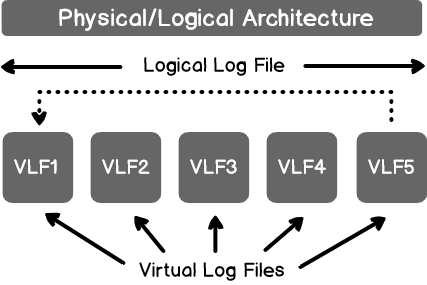
Drop unwanted (secondary) SQL Server transaction log files
January 31, 2020This article explores the use of multiple SQL Server Transaction Log Files and the process of removing the secondary transaction log file.
Read more »