
In the article, Python scripts to format data in Microsoft Excel, we used Python scripts for creating an excel and do various data formatting. Python is an interesting high-level programming language. You can go through various use cases of Python on SQLShack.
In this article, we will look at removing duplicate data from excel using the Python.
A quick recap of removing duplicate rows in Microsoft Excel
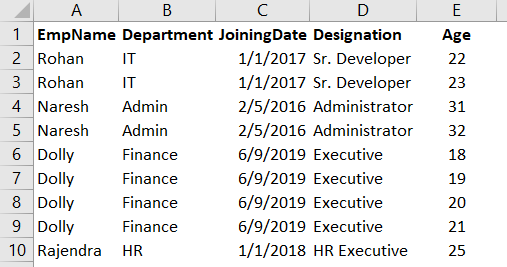
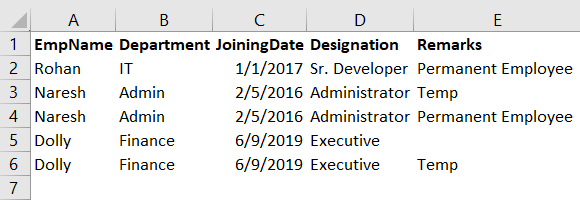
Suppose we have the following data in an excel sheet. We want to get rid of duplicate values in this sheet.
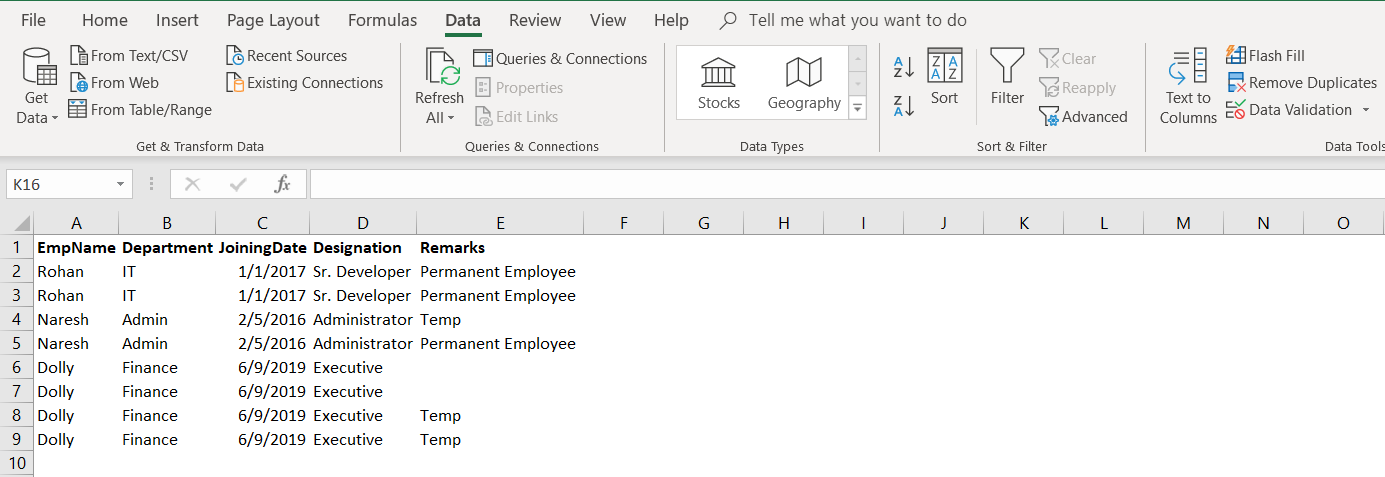
In Microsoft Excel, we use the Remove Duplicates button from the Data menu. This option checks duplicate values and retains the FIRST unique value and removes other values.
Let’s click on Remove Duplicates and select all columns.
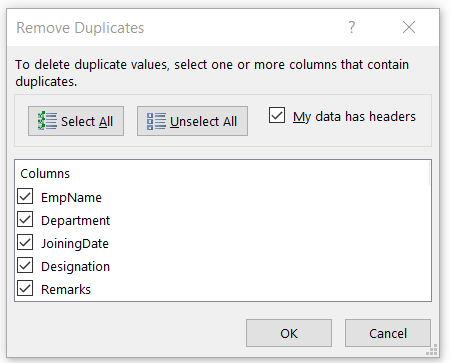
Click ok, and it removes the duplicate values 3 duplicate values and retains 5 unique values.
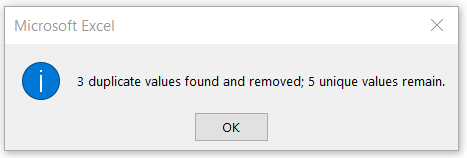
We have the following data after removing duplicates from this.
Suppose you are working in excel using Python language. If that excel contains duplicate values, we might not want to use Excel functionalities for it. Our script should be capable of handling such duplicate data and remove per our requirements such as remove all duplicates, remove all but the last duplicate, remove all but first duplicate.
Let’s look at the Python way of handling duplicate data in excel.
Python scripts for removing duplicates in an excel
Before we start with Python, make sure you run through the pre-requisites specified in the article, Python scripts to format data in Microsoft Excel.
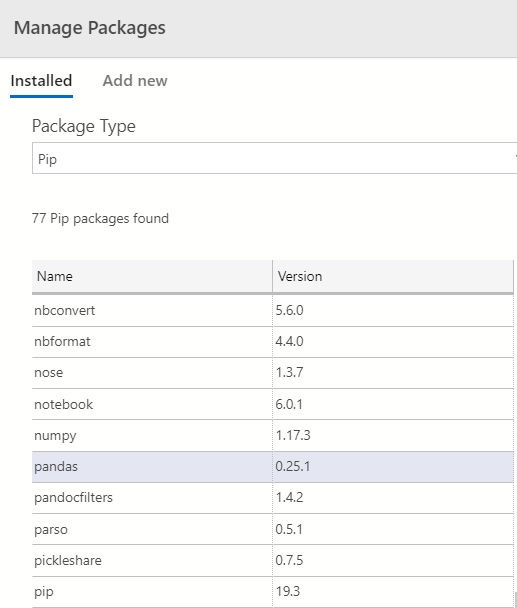
Launch SQL Notebook in Azure Data Studio and verify pandas, NumPy packages existence. You can click on Manage Extensions in Azure Data Studio for it.

Once you click on Manage Packages, it gives you a list of installed packages. Here, we can see both pandas and NumPy package along with pip utility.
We use the pandas read_excel() function to import an excel file. Create a new code block in SQL Notebook and execute the code. Here, the print statement prints the data frame that consists of excel sheet data.
First, we import the pandas library to read and write the excel sheets.
In this data, few columns contain NaN in the remarks column. Python display NaN for the cells that do not have any value/text.
|
1 2 3 |
import pandas as pd data = pd.read_excel('C:\Temp\data.xlsx') print(data) |
In the output, we also see index values for individual rows. The first row starts with index id 0 and increments by 1 with each new row.

We use drop_duplicates() function to remove duplicate records from a data frame in Python scripts.
Syntax of drop_duplicates() in Python scripts
DataFrame.drop_duplicates(subset=None, keep=’first’, inplace=False)
- Subset: In this argument, we define the column list to consider for identifying duplicate rows. If it considers all columns in case, we do not specify any values
- Keep: Here, we can specify the following values:
- First: Remove all duplicate rows except the first one
- Last: Remove all duplicate rows except the last one
- False: Remove all duplicate rows
- Inplace: By default, Python does not change the source data frame. We can specify this argument to change this behavior
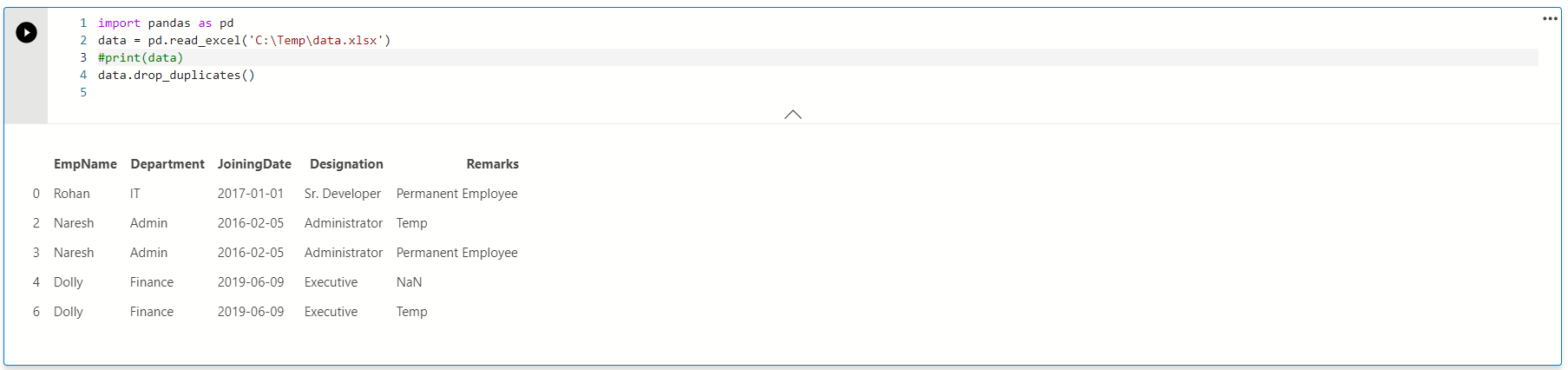
Example 1: Use drop_duplicates() without any arguments
In the following query, it calls drop.duplicates() function for [data] dataframe.
|
1 2 3 4 |
import pandas as pd data = pd.read_excel('C:\Temp\data.xlsx') #print(data) data.drop_duplicates() |
In the output, we can see that it removes rows with index id 1,5 and 7. It is the default behavior of the drop_duplicate() function. It retains the first value and removes further duplicates.
Example 2: Use drop_duplicates() along with column names
By default, Pandas creates a data frame for all available columns and checks for duplicate data. Suppose, we want to exclude Remarks columns for checking duplicates. It means if the row contains similar values in the rest of the columns, it should be a duplicate row. We have few records in our excel sheet that contains more duplicate values if we do not consider the remarks column.
In the following Python scripts, we specify column names in the subset argument. Pandas check for these columns and remove the duplicate values. It excludes the remarks column in this case.
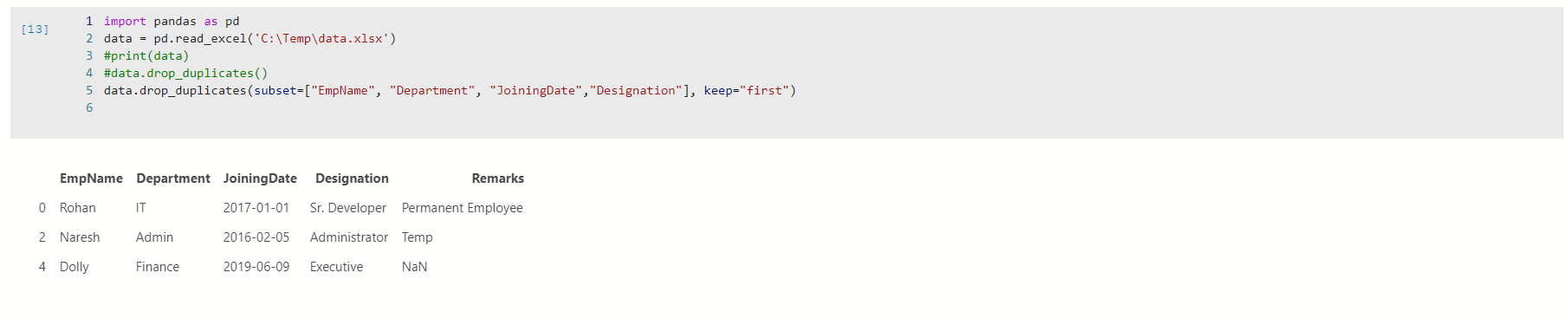
Example 2a: Keep=” first” argument
We also specify another argument keep=first to instruct Python to keep the first value and remove further duplicates. It is the default behaviors so that we can exclude this parameter here as well.
|
1 2 3 |
import pandas as pd data = pd.read_excel('C:\Temp\data.xlsx') data.drop_duplicates(subset=["EmpName", "Department", "JoiningDate","Designation"], keep="first") |
Look at the output, and we have only three records available. It removed all duplicate rows for the specified columns. We have rows with index id 0,2 and 4 in the output by using the first value in keep argument.
Example 2b: Keep=” last” argument
We can change the argument keep=last. It keeps the last row from the duplicates and removes previous duplicate rows. Let’s change the argument and view the output.
|
1 2 3 |
import pandas as pd data = pd.read_excel('C:\Temp\data.xlsx') data.drop_duplicates(subset=["EmpName", "Department", "JoiningDate","Designation"], keep="last") |
In this case, the output changes and we have rows with index id 1,2,7 in the output.
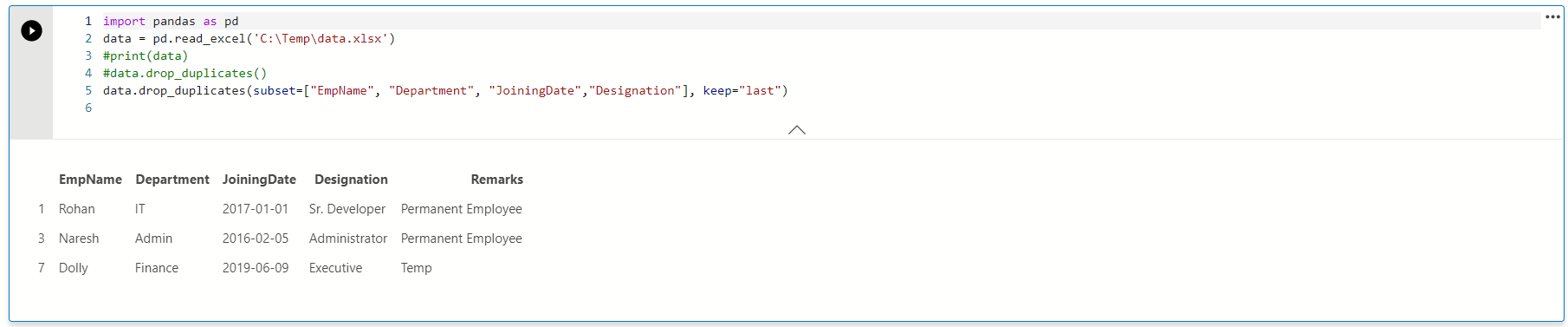
Example 2c: Keep=” false” argument
Previously, we kept either first or last rows and removed other duplicate rows. Suppose we want to remove all duplicate values in the excel sheet. We can specify value False in the keep parameter for it.
|
1 2 3 |
import pandas as pd data = pd.read_excel('C:\Temp\data.xlsx') data.drop_duplicates(subset=["EmpName", "Department", "JoiningDate","Designation"], keep="False") |
If we execute the above Python Script, we get the following error message.
ValueError: keep must be either “first”, “last” or False
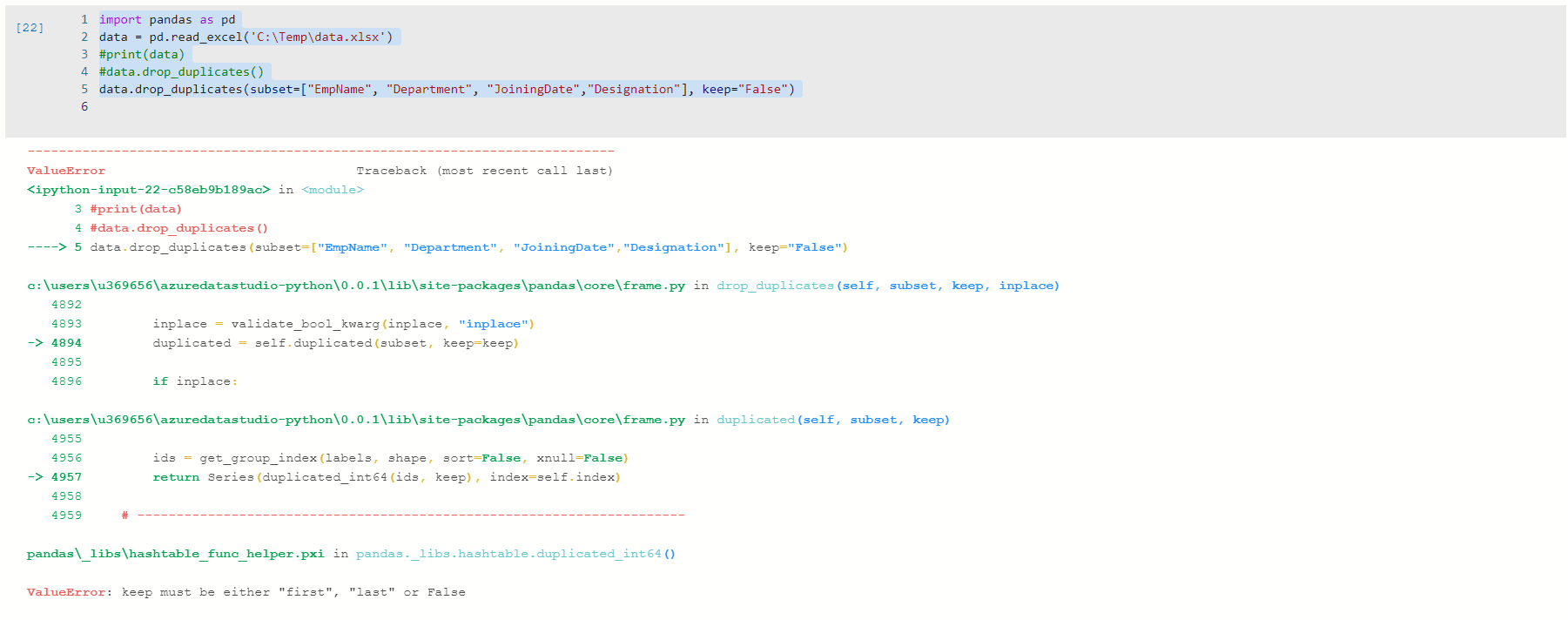
For the first and last value, we use double-quotes, but we need to specify False value without any quotes. Let’s remove the quote and execute the code.
|
1 2 3 |
import pandas as pd data = pd.read_excel('C:\Temp\data.xlsx') data.drop_duplicates(subset=["EmpName", "Department", "JoiningDate","Designation"], keep=False) |
In the output, we do not get any row because we do not have any unique rows in the excel sheet.

To test the above code, let’s add a new row in the excel and execute the above code. We should get the row in the output. The script works, and we get unique rows in the output.

Example 3: Remove duplicates by keeping the maximum and minimum value
Now, suppose we have a new column Age in the excel sheet. Someone has entered the wrong age for the employees. We want to remove the duplicate values but keep the row that has maximum age value for an employee. For example, Rohan has two entries in this sheet. Both rows look similar; however, one row shows age 22 while another row has age value 23. We want to remove the row with a minimum age. In this case, the row with age 22 for Rohan should be removed.
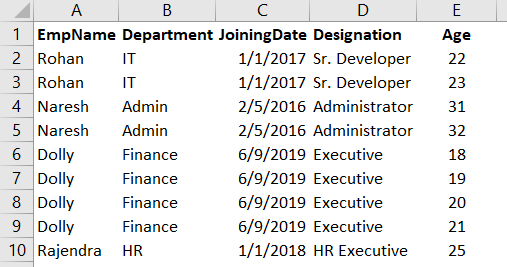
For this requirement, we use an additional Python script function sort_values(). In the following code, we sort the age values in ascending order using data.sort_values() function. In the ascending order, data is sorted from minimum to maximum age so we can keep the last value and remove other data rows.
|
1 2 3 |
import pandas as pd data = pd.read_excel('C:\Temp\data.xlsx') data.sort_values('Age',ascending=True).drop_duplicates(subset=["EmpName", "Department", "JoiningDate","Designation"], keep='last') |
In the output, we can see it has rows with maximum age for each employee. For example, Rohan shows age 23 that is the maximum age available from both records.
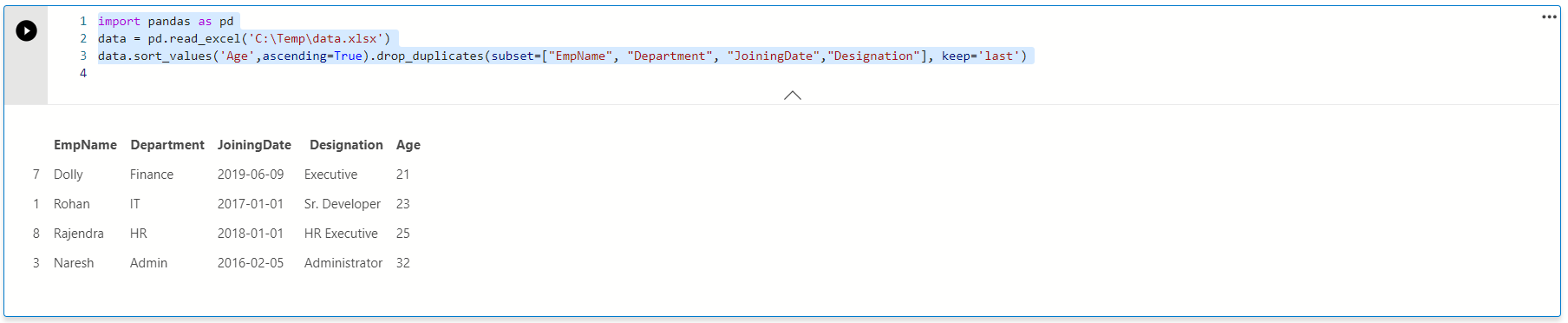
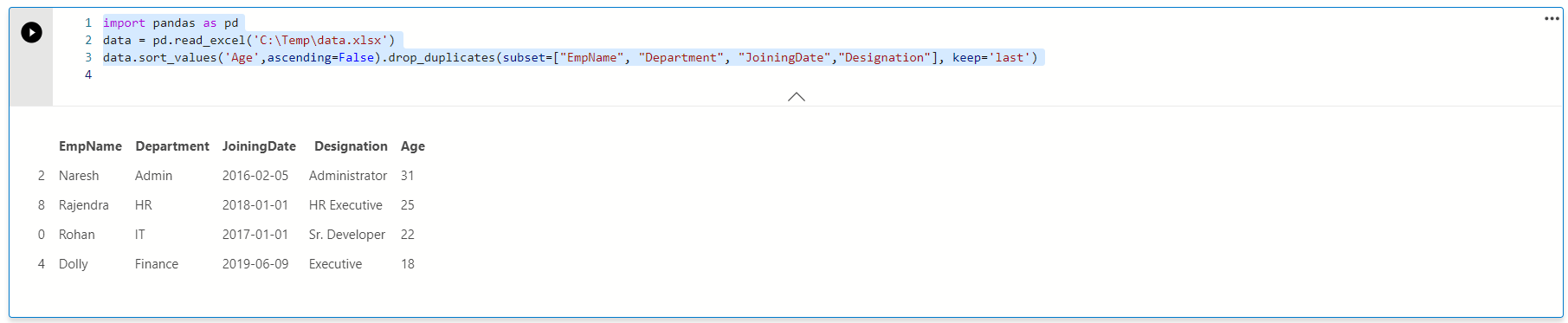
Similarly, we can change the data sort in descending order and remove the duplicates with minimum age values.
|
1 2 3 |
import pandas as pd data = pd.read_excel('C:\Temp\data.xlsx') data.sort_values('Age',ascending=False).drop_duplicates(subset=["EmpName", "Department", "JoiningDate","Designation"], keep='last') |
Example 4: drop_duplicate() function using inplace argument
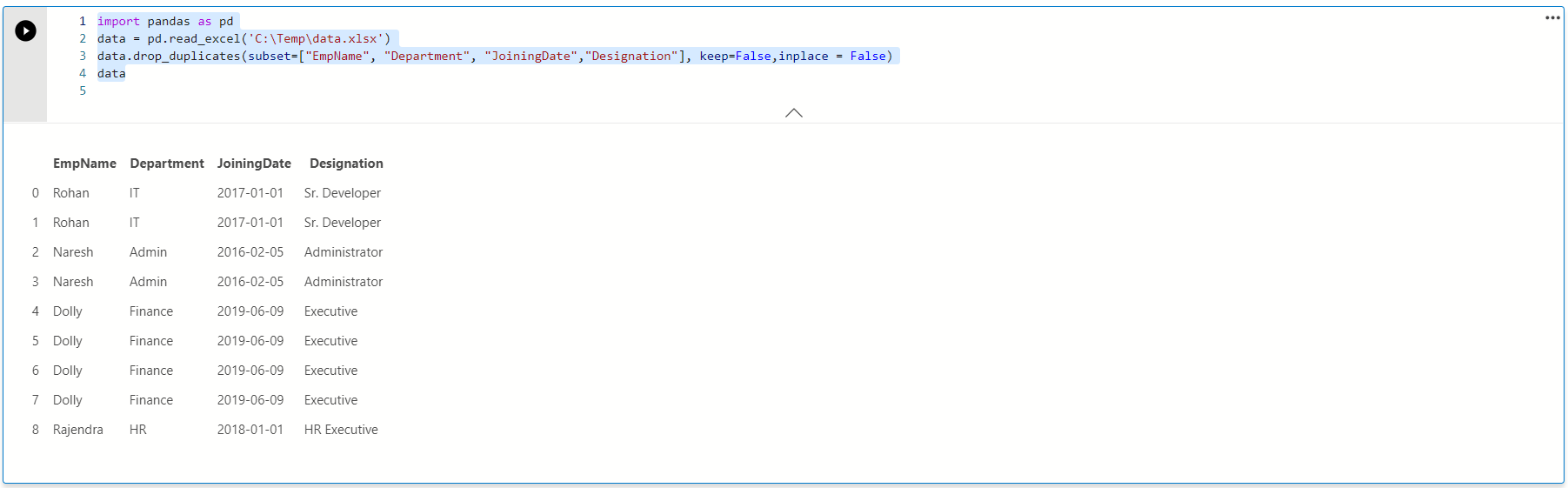
By default, Pandas returns a new data frame and does not changes the source data frame. We can specify the argument inplace=True, and it changes the source data frame also.
Execute the following query and call the data frame in the end; it returns the content of the source data frame.
|
1 2 3 4 |
import pandas as pd data = pd.read_excel('C:\Temp\data.xlsx') data.drop_duplicates(subset=["EmpName", "Department", "JoiningDate","Designation"], keep=False,inplace = False) data |
Let’s change the default value of inplace argument and view the change in the output.
|
1 2 3 4 |
import pandas as pd data = pd.read_excel('C:\Temp\data.xlsx') data.drop_duplicates(subset=["EmpName", "Department", "JoiningDate","Designation"], keep=False,inplace = True) data |

Highlight duplicate values with custom color codes
In many cases, we just want to check the duplicate data instead of removing it. Instead, we require to highlight the duplicate values and send them to the appropriate team for correction. It might be feasible in case we are receiving data from a third party.
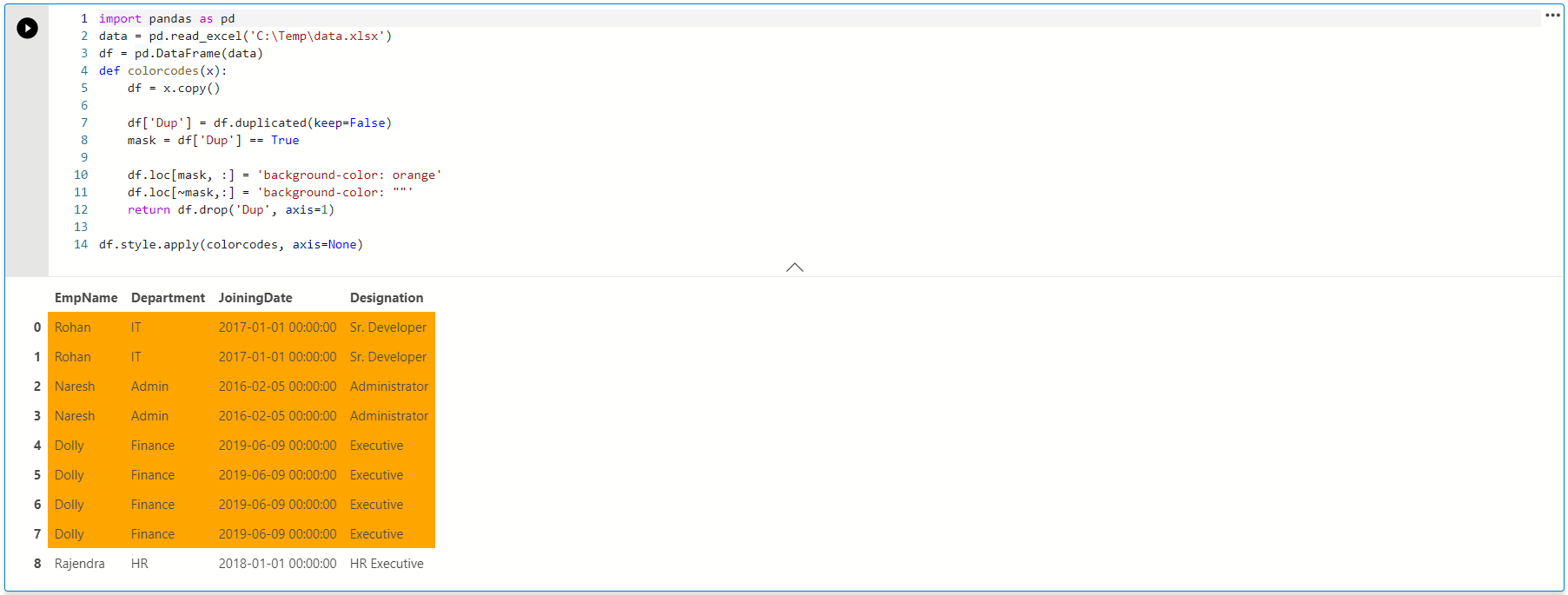
We can use conditional formatting and give a visual style ( color coding ) to duplicate rows. In the following code, we define a Python script function to highlight duplicate values in the orange background color. We will cover more about conditional formatting in upcoming articles.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
import pandas as pd data = pd.read_excel('C:\Temp\data.xlsx') df = pd.DataFrame(data) def colorcodes(x): df = x.copy() df['Dup'] = df.duplicated(keep=False) mask = df['Dup'] == True df.loc[mask, :] = 'background-color: orange' df.loc[~mask,:] = 'background-color: ""' return df.drop('Dup', axis=1) df.style.apply(colorcodes, axis=None) |
It gives us the following output, and we can easily interpret which rows contain duplicate values. It is useful, especially when we have a large number of rows. We cannot go through each row in this case, and color-coding helps us to identify the duplicate values.
Alternatively, we can use further functions such as GROUPBY and count the duplicate rows.
|
1 2 3 4 |
import pandas as pd data = pd.read_excel('C:\Temp\data.xlsx') df = pd.DataFrame(data) df.groupby(df.columns.tolist(),as_index=False).size() |
If any row count is greater than 1, it is a duplicate row. In the following output, we can note than Dolly appeared 4 times in the excel sheet which means it is a duplicate row. Rajendra does not contain any duplicate row, so its count is 1 in the output.

Conclusion
In this article, we explored the process to remove duplicate rows in an Excel sheet using Python scripts. I liked the way to deal with Excel files using Python. We will cover more useful scripts in the upcoming articles. Stay tuned!

I am the author of the book "DP-300 Administering Relational Database on Microsoft Azure". I published more than 650 technical articles on MSSQLTips, SQLShack, Quest, CodingSight, and SeveralNines.
I am the creator of one of the biggest free online collections of articles on a single topic, with his 50-part series on SQL Server Always On Availability Groups.
Based on my contribution to the SQL Server community, I have been recognized as the prestigious Best Author of the Year continuously in 2019, 2020, and 2021 (2nd Rank) at SQLShack and the MSSQLTIPS champions award in 2020.
Personal Blog: https://www.dbblogger.com
I am always interested in new challenges so if you need consulting help, reach me at rajendra.gupta16@gmail.com
View all posts by Rajendra Gupta
- Understanding PostgreSQL SUBSTRING function - September 21, 2024
- How to install PostgreSQL on Ubuntu - July 13, 2023
- How to use the CROSSTAB function in PostgreSQL - February 17, 2023