
In an article, An overview of the SQL table variable, we explored the usage of SQL table variables in SQL Server in comparison with a temporary table. Let’s have a quick recap of the table variable:
- We can define a table variable and use it similar to a temporary table with few differences. The table variable scope is within the batch
- The storage location of the table variable is in the TempDB system database
- SQL Server does not maintain statistics for it. Therefore, it is suitable for small result sets
- It does not participate in explicit transactions
- We cannot define indexes on table variables except primary and unique key constraints
Issues with SQL table variables
Let me ask a few questions to set agenda for this article:
- Have you seen any performance issues with queries using table variables?
- Do you see any issues in the execution plan of a query using these table variables?
Go through the article for getting the answer to these questions in a particular way.
Once we define a SQL table variable in a query, SQL Server generates the execution plan while running the query. SQL Server assumes that the table variable is empty. We insert data in a table variable during runtime. We might have an optimized execution plan of the query because SQL Server could not consider the data in the table variable. It might cause performance issues with high resource utilization. We might have a similar execution plan even if we have a different number of rows in each execution.
Let’s view the table variable issue in SQL Server 2017 with the following steps:
- Set Statistics IO ON and Set Statistics Time On to capture query IO and time statistics. It will help in performing a comparison of multiple query executions
- Define a table variable @Person with columns [BusinessEntityID] ,[FirstName] and [LastName]
- Insert data into table variable @person from the [Person] table in the AdventureWorks sample database
- Join the table variable with another table and view the result of the join operation
- View the actual execution plan of the query
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
SET STATISTICS IO ON; SET STATISTICS TIME ON; DECLARE @Person TABLE ([BusinessEntityID] INT, [FirstName] VARCHAR(30), [LastName] VARCHAR(30) ); INSERT INTO @Person SELECT [BusinessEntityID], [FirstName], [LastName] FROM [AdventureWorks].[Person].[Person]; SELECT * FROM @Person P1 JOIN [AdventureWorks].[Person].[Person] P2 ON P1.[BusinessEntityID] = P2.[BusinessEntityID]; |
- Note: In this article, I use ApexSQL Plan for viewing execution plans.
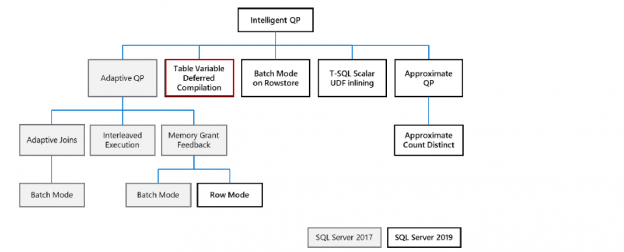
In the above screenshot, we can note the following.
- Estimated number of rows: 1
- The actual number of rows: 19,972
- Actual/estimated number of rows: 1997200%
Really! You can imagine the difference in the calculations. SQL Server missed the estimation of actual rows counts by 1997200% for the execution plan. You can see that SQL Server could not estimate the actual number of rows. The estimated number of rows is nowhere close to actual rows. It is a big drawback that does not provide an optimized execution plan.
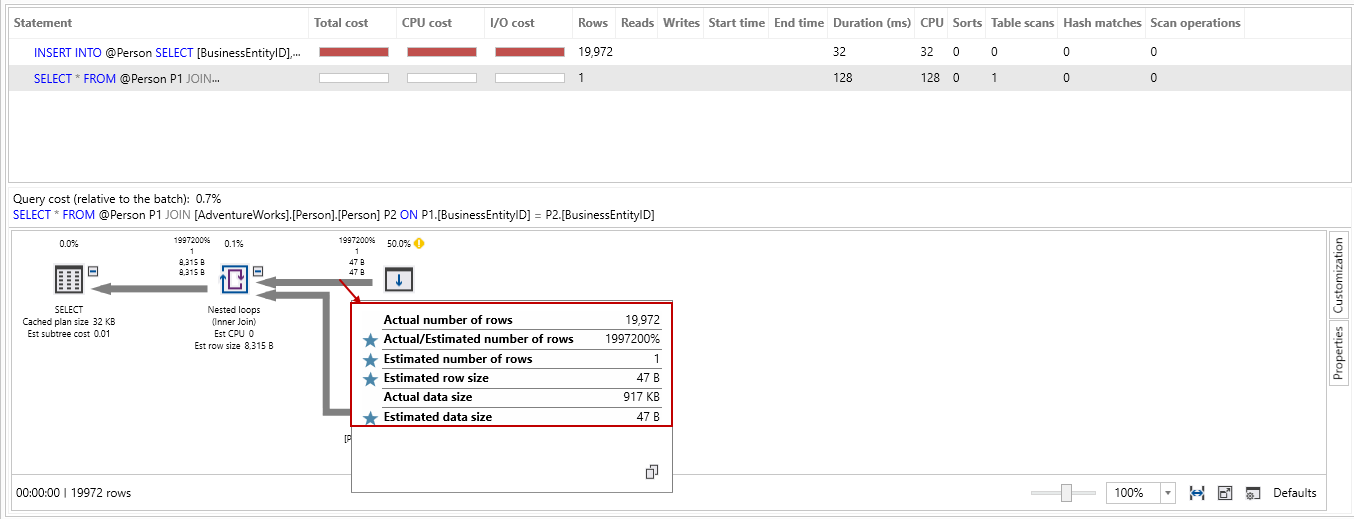
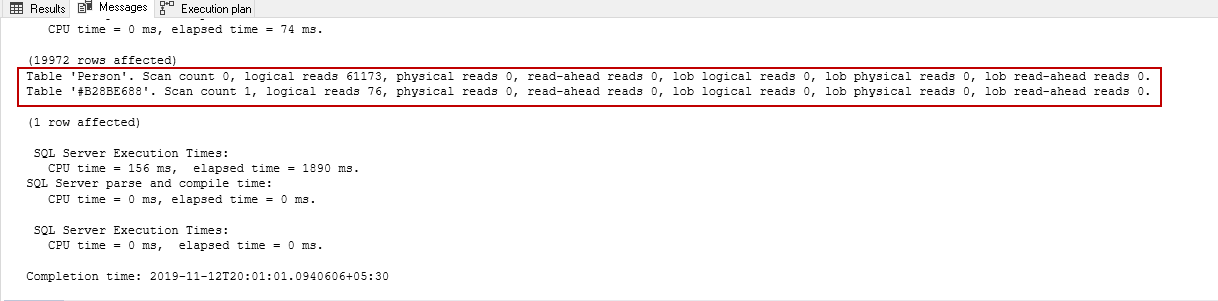
Let’s look at statistics in the message tab of SSMS. It took 59,992 logical reads (59916+76) for this query:
In SQL Server 2012 SP2 or later versions, we can use trace flag 2453. It allows SQL table variable recompilation when the number of rows changes. Execute the previous query with trace flag and observe query behavior. We can enable this trace flag at the global level using DBCC TRACEON(2453,-1) command as well:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
DBCC TRACEON(2453); SET STATISTICS IO ON; SET STATISTICS TIME ON; DECLARE @Person TABLE ([BusinessEntityID] INT, [FirstName] VARCHAR(30), [LastName] VARCHAR(30) ); INSERT INTO @Person SELECT [BusinessEntityID], [FirstName], [LastName] FROM [AdventureWorks].[Person].[Person]; SELECT * FROM @Person P1 JOIN [AdventureWorks].[Person].[Person] P2 ON P1.[BusinessEntityID] = P2.[BusinessEntityID]; |
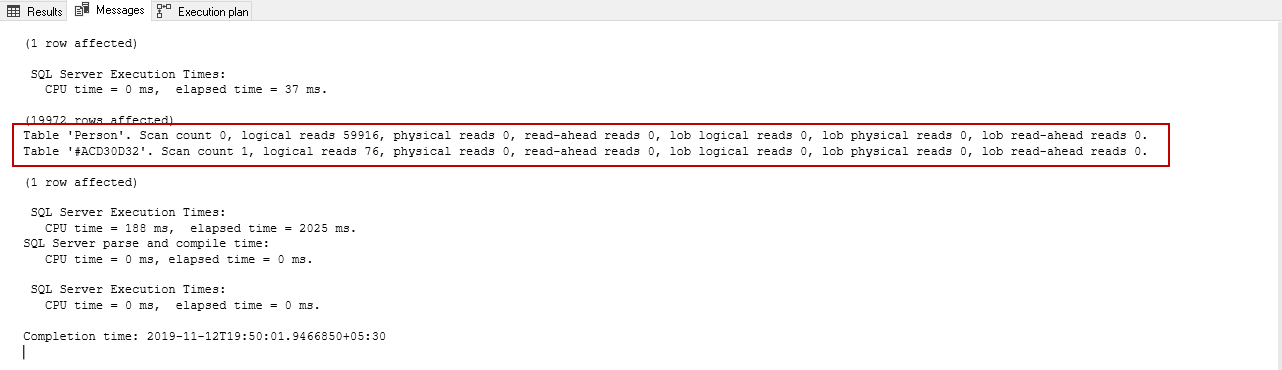
In the following screenshot of the execution plan after enabling the trace flag 2453, we can note the following:
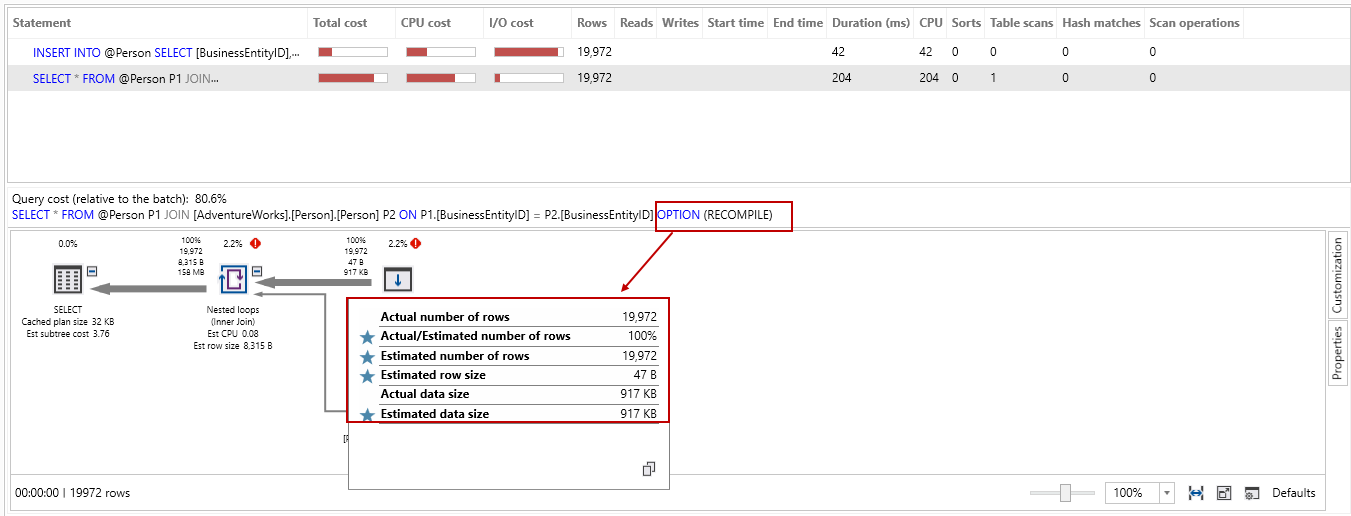
- Estimated number of rows: 19,972
- The actual number of rows: 19,972
- Actual/estimated number of rows: 100%
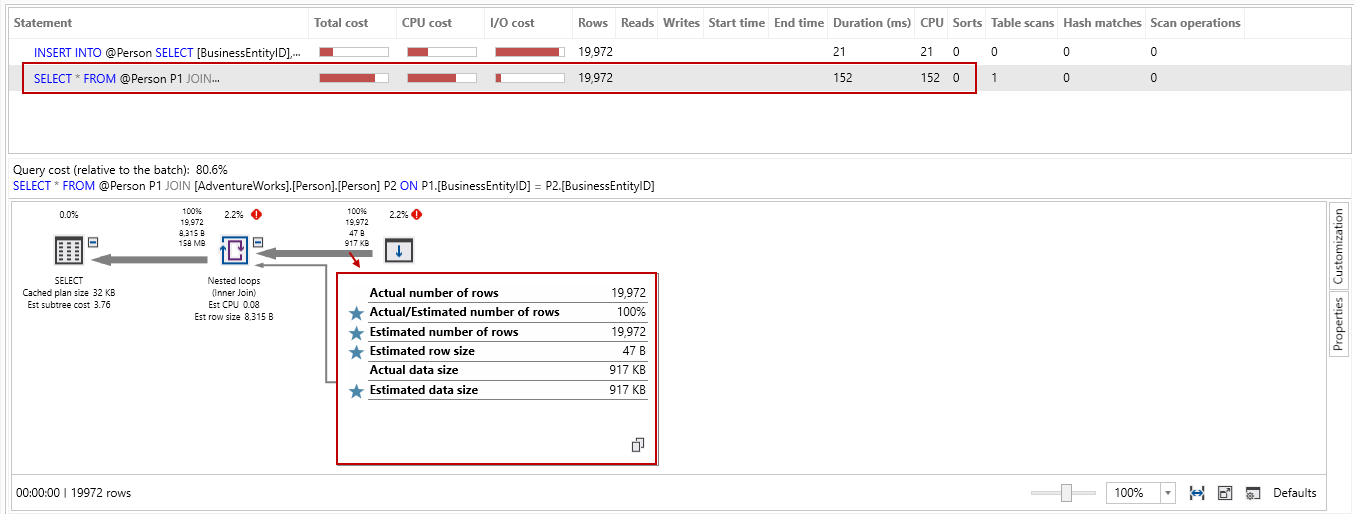
It improves the IO and Time statistics as well as compared to previous runs without the trace flag:
Trace flag 2453 works similar to adding a query hint OPTION (RECOMPILE). The difference between the trace flag and OPTION(RECOMPILE) is the recompilation frequency. Let’s execute the previous query with the query hint OPTION (RECOMPILE) and view the actual execution plan:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
SET STATISTICS IO ON; SET STATISTICS TIME ON; DECLARE @Person TABLE ([BusinessEntityID] INT, [FirstName] VARCHAR(30), [LastName] VARCHAR(30) ); INSERT INTO @Person SELECT [BusinessEntityID], [FirstName], [LastName] FROM [AdventureWorks].[Person].[Person]; SELECT * FROM @Person P1 JOIN [AdventureWorks].[Person].[Person] P2 ON P1.[BusinessEntityID] = P2.[BusinessEntityID] OPTION (RECOMPILE); |
We can see that using query hint also improves the estimated number of rows for the SQL table variable statement:
Trace flag recompiles the query once a predefined (internal) threshold changes for several rows while OPTION(RECOMPILE) compiles on each execution.
SQL Table Variable Deferred Compilation in SQL Server 2019
SQL Server 2017 introduced optimization techniques for improving query performance. These features are part of the Intelligent Query Processing (IQP) family.
In the following, image from SQL Server 2019 technical whitepaper, we can see new features introduced in SQL 2019:
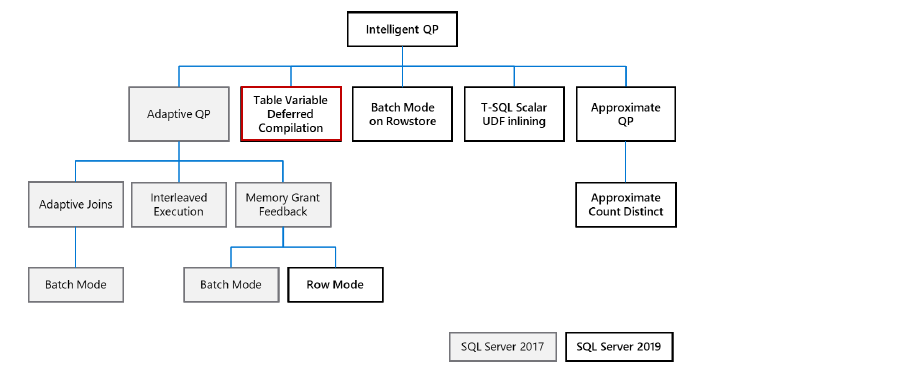
SQL Server 2019 introduces the following new features and enhancements:
- Table variable deferred compilation
- Batch mode on a Row store
- T-SQL scalar UDF Inlining
- Approximate Count Distinct
- Row mode memory grant feedback
Let’s explore the Table variable deferred compilation feature in SQL Server 2019. You can refer to SQL Server 2019 articles for learning these new features.
SQL Table variable deferred compilation
Once SQL Server compiles a query with a table variable, it does not know the actual row count. It uses a fixed guess of estimated one row in a table variable. We have observed this behavior in the above example of SQL Server 2017.
SQL Server 2019 table variable deferred compilation, the compilation of the statement with a table variable is deferred until the first execution. It helps SQL Server to avoid fix guess of one row and use the actual cardinality. It improves the query execution plan and improves performance.
To use this feature, we should have a database with compatibility level 150 in SQL Server 2019. If you have a database in another compatibility level, we can use the following query for changing it:
|
1 |
ALTER DATABASE [DatabaseName] SET COMPATIBILITY_LEVEL = 150; |
We can use sp_helpdb command for verifying database compatibility level:

Note: In this article, I use SQL Server 2019 general availability release announced on 4th November 2019 at Microsoft Ignite.
You should download the SQL 2019 General availability release and restore the AdventureWorks database before proceeding further with this article. We do not have a SQL 2019 version of this AdventureWorks database. You should change the database compatibility level after restoration.
Execute the earlier query (without trace flag) in SQL Server 2019 database and view the actual execution plan. We do not require enabling any trace flag for SQL table variable deferred compilation.
In the below screenshot, we can note the following:
- Estimated number of rows: 19,972
- The actual number of rows: 19,972
- Actual/estimated number of rows: 100%
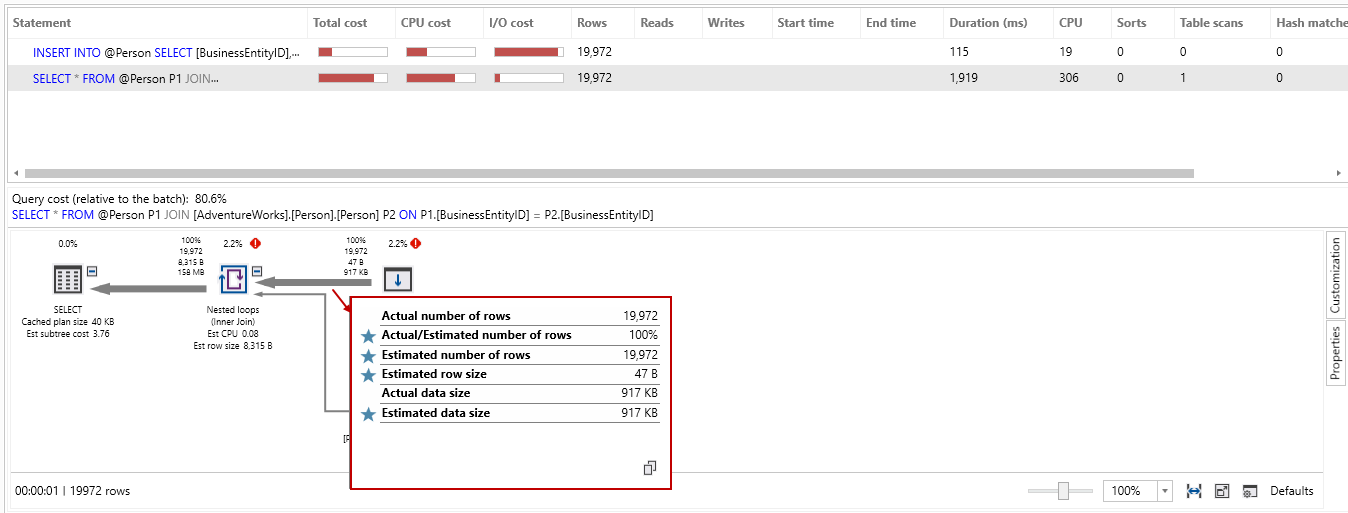
Bang on! The estimated and actual numbers of rows are the same. If we look at the statistics in SQL Server 2019, we can see it took 43,783 logical reads in comparison with 59,992 logical reads in SQL 2017. You might see more performance benefits while working with complex data and queries. My point is to show that SQL Server optimizer can match the estimation rows accurately:
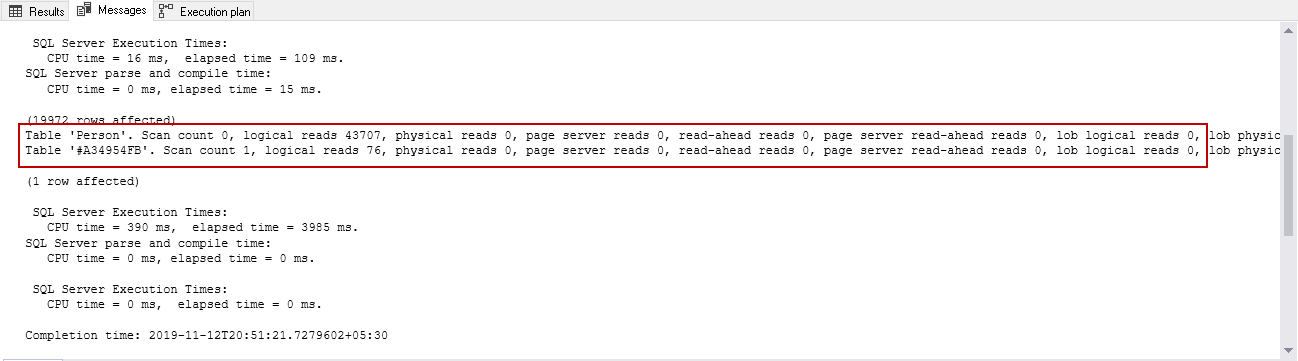
In the default behavior, it eliminates the requirement of:
- Trace flag 2453
- We can skip adding OPTION (RECOMPILE) at the statement level. It avoids any code changes, and SQL Server uses deferred compilation by default
- We do not require explicit plan hints
Conclusion
In this article, we explored the issues in query optimization with SQL table variables in SQL Server 2017 or before. It also shows the improvements in SQL Server 2019 using table variable deferred compilation. You might also face these issues. I would suggest downloading the general availability release and preparing yourself with enhancements and new features of SQL 2019.

I am the author of the book "DP-300 Administering Relational Database on Microsoft Azure". I published more than 650 technical articles on MSSQLTips, SQLShack, Quest, CodingSight, and SeveralNines.
I am the creator of one of the biggest free online collections of articles on a single topic, with his 50-part series on SQL Server Always On Availability Groups.
Based on my contribution to the SQL Server community, I have been recognized as the prestigious Best Author of the Year continuously in 2019, 2020, and 2021 (2nd Rank) at SQLShack and the MSSQLTIPS champions award in 2020.
Personal Blog: https://www.dbblogger.com
I am always interested in new challenges so if you need consulting help, reach me at rajendra.gupta16@gmail.com
View all posts by Rajendra Gupta
- Understanding PostgreSQL SUBSTRING function - September 21, 2024
- How to install PostgreSQL on Ubuntu - July 13, 2023
- How to use the CROSSTAB function in PostgreSQL - February 17, 2023