
In this article, we will discuss the Dirty Read concurrency issue and also learn the details of the Read Uncommitted Isolation Level.
A transaction is the smallest working unit that performs the CRUD (Create, Read, Update, and Delete) actions in the relational database systems. Relevant to this matter, database transactions must have some characteristics to provide database consistency. The following four features constitute the major principles of the transactions to ensure the validity of data stored by database systems. These are;
- Atomicity
- Consistency
- Isolation
- Durability
These four properties are also known as ACID principles. Let’s briefly explain these four principles.
Atomicity
This property is also known as all or nothing principle. According to this property, a transaction can not be completed partially, so if a transaction gets an error at any point of the transaction, the entire transaction should be aborted and rollbacked. Or, all the actions contained by a transaction must be completed successfully.
Consistency
According to this property, the saved data must not damage data integrity. This means that the modified data must provide the constraints and other requirements that are defined in the database.
Durability
According to this property, the committed will not be lost even with the system or power failure.
Isolation
The database transactions must complete their tasks independently from the other transactions. This property enables us to execute the transactions concurrently on the database systems. So, the data changes which are made up by the transactions are not visible until the transactions complete (committed) their actions. The SQL standard describes three read phenomena, and they can be experienced when more than one transaction tries to read and write to the same resources.
- Dirty-reads
- Non-repeatable reads
- Phantom reads
What is Dirty Read?
The simplest explanation of the dirty read is the state of reading uncommitted data. In this circumstance, we are not sure about the consistency of the data that is read because we don’t know the result of the open transaction(s). After reading the uncommitted data, the open transaction can be completed with rollback. On the other hand, the open transaction can complete its actions successfully. The data that is read in this ambiguous way is defined as dirty data. Now we will explain this issue with a scenario:
Assuming we have a table as shown below that stores the bank account details of the clients.
AccountNumber | ClientName | Balance |
7Y290394 | Betty H. Bonds | $78.00 |
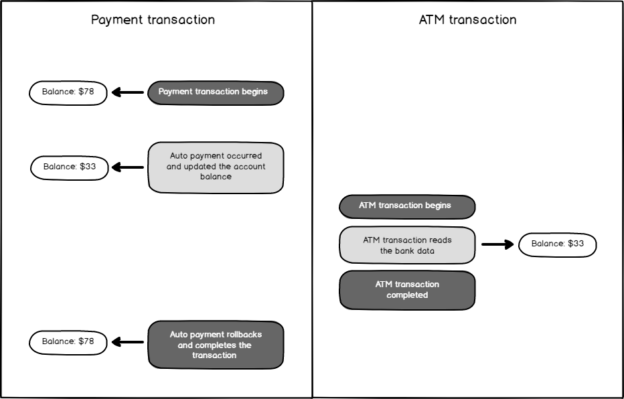
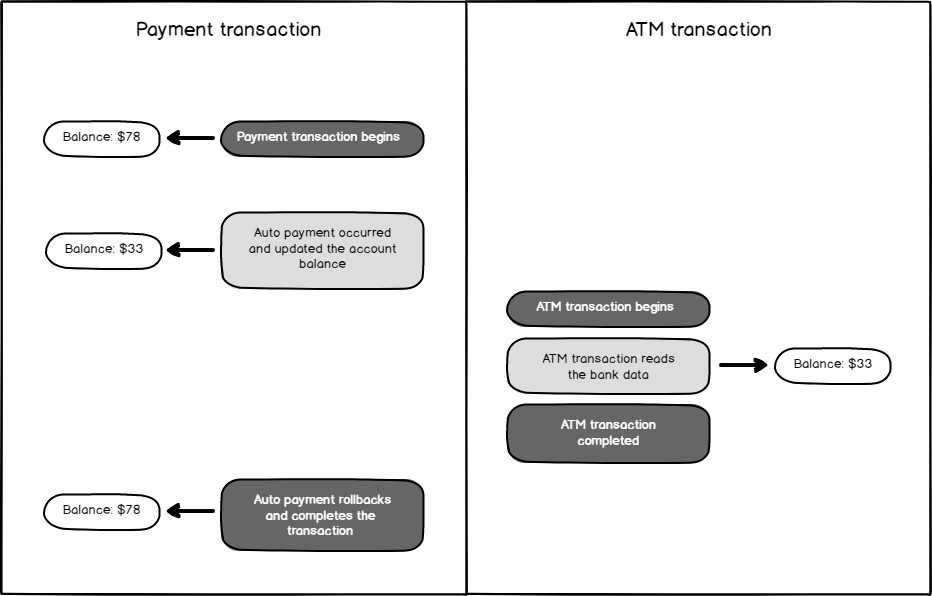
In this scenario, Betty has $78.00 in her bank account, and the automatic payment system withdraws $45 from Betty’s account for the electric bill. At that time, Betty wants to check her bank account on the ATM, and she notices $33 in her bank account. However, if the electric bill payment transaction is rollbacked for any reason, the bank account balance will be turned to $78.00 again, so the data read by Betty is dirty data. In this case, Betty will be confused. The following diagram illustrates this dirty read scenario in a clearer manner.
Now we will realize this scenario in practice with SQL Server. Firstly we will create the BankDetailTbl table that stores the bank account details of the clients.
|
1 2 3 4 5 6 7 |
CREATE TABLE BankDetailTbl ( Id INT PRIMARY KEY IDENTITY(1, 1), AccountNumber VARCHAR(40), ClientName VARCHAR(100), Balance MONEY); |
As a second step, we will insert a sample row to it.
|
1 2 3 |
INSERT INTO BankDetailTbl VALUES ('7Y290394', 'Betty H. Bonds', '78'); |
Now we will execute the following queries, the Query-1 updates the balance value of the particular bank account, and then it will wait 20 seconds and rollback the data modification. At this moment, we will immediately execute the Query-2, and this query reads the modified but uncommitted data.
Query-1:
|
1 2 3 4 5 6 7 8 9 10 11 |
BEGIN TRAN; UPDATE BankDetailTbl SET Balance=Balance-45 WHERE AccountNumber = '7Y290394'; WAITFOR DELAY '00:00:20'; ROLLBACK TRAN; SELECT * FROM BankDetailTbl WHERE AccountNumber = '7Y290394'; |
Query-2:
|
1 2 3 4 5 6 |
SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED; BEGIN TRAN; SELECT * FROM BankDetailTbl WHERE AccountNumber = '7Y290394'; COMMIT TRAN; |
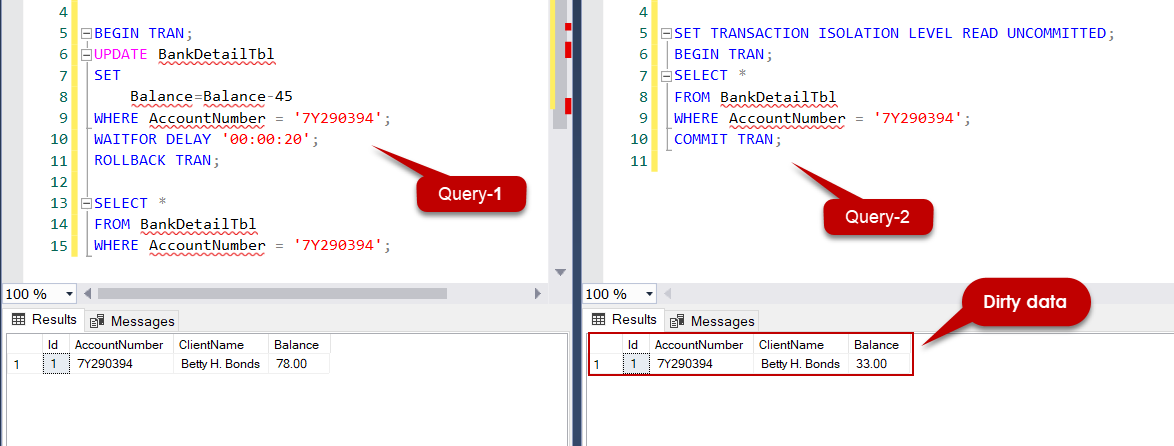
As a result, the data read by Query-2 was dirty because the data was returned to its first state because of the rollback process.
The Read Uncommitted vs Read Committed Isolation Level
As we explained, a transaction must be isolated from other transactions according to the isolation property of the ACID transactions. In this context, isolation levels specify the isolation strategy of a transaction from the other transactions.
What is Exclusive Lock?
By default, SQL Server sets an exclusive lock for data that is being modified to ensure data consistency until the transaction is complete. So, it isolates the modified data from the other transaction.
Read uncommitted is the weakest isolation level because it can read the data which are acquired exclusive lock to the resources by the other transactions. So, it might help to avoid locks and deadlock problems for the data reading operations. On the other hand, Read Committed can not read the resource that acquires an exclusive lock, and this is the default level of the SQL Server.
Now we will work on an example of this difference to figure this out. With the help of the Query-3, we will change the ClientName column value of a client. During this time, Query-4 tries to read the same client details, but Query-4 could not be read the data until the Query-3 completes the update action. At first, we will execute the Query-3.
Query-3:
|
1 2 3 4 5 6 7 |
BEGIN TRAN; UPDATE BankDetailTbl SET ClientName='Doris P. Barnum' WHERE AccountNumber = '7Y290394'; WAITFOR DELAY '00:00:50' ROLLBACK TRAN |
After executing the Query-3, we are executing the Query-4 immediately on another query window at this moment.
Query-4:
|
1 2 3 4 5 6 7 8 9 10 11 |
DECLARE @TimeDiff AS INT DECLARE @BegTime AS DATETIME DECLARE @EndTime AS DATETIME BEGIN TRAN SET @BegTime = GETDATE() SELECT ClientName FROM BankDetailTbl WHERE AccountNumber = '7Y290394'; SET @EndTime = GETDATE() SET @TimeDiff = DATEDIFF(SECOND,@EndTime,@BegTime) SELECT @TimeDiff AS QueryCompletionTime COMMIT TRAN |
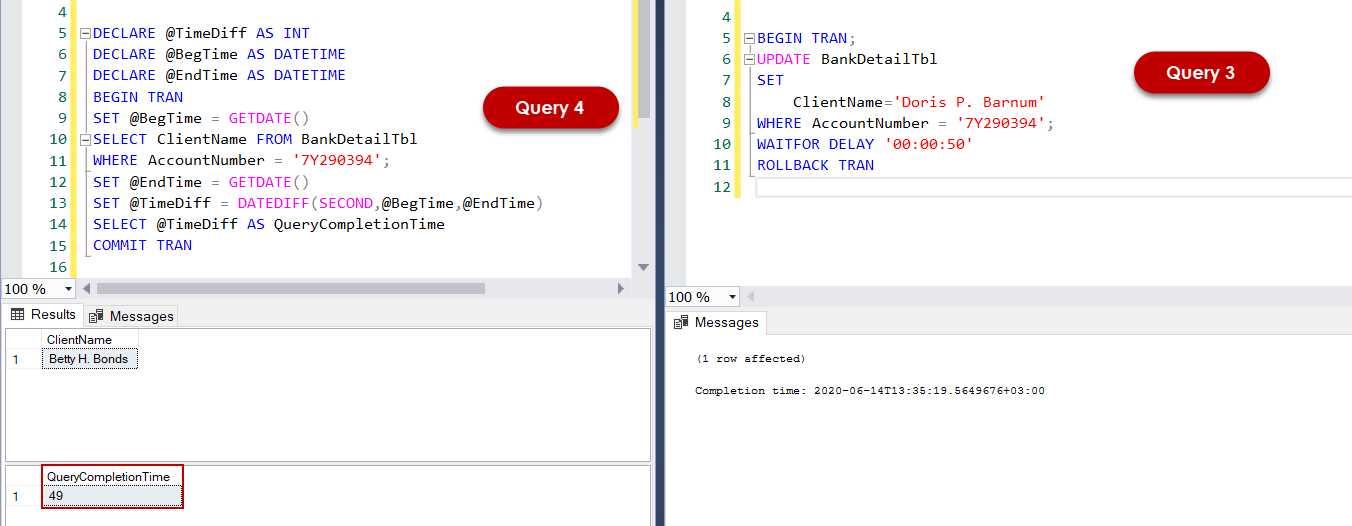
In Query-4, we have measured the query completion time, and the @TimeDiff variable indicates this measured time. As we have seen, Query-4 has completed on 49 seconds because it has waited for the completion of the Query-3 because the Read Committed level does not allow dirty reads. Now we will change this level to Read Uncommitted for Query-4. SET TRANSACTION ISOLATION LEVEL statement helps to explicitly change the isolation level for a transaction. We will execute the Query-3 and Query-4 at the same order and will observe the result.
Query-3:
|
1 2 3 4 5 6 7 |
BEGIN TRAN; UPDATE BankDetailTbl SET ClientName='Doris P. Barnum' WHERE AccountNumber = '7Y290394'; WAITFOR DELAY '00:00:50' ROLLBACK TRAN |
Query-4:
|
1 2 3 4 5 6 7 8 9 10 11 |
DECLARE @TimeDiff AS INT DECLARE @BegTime AS DATETIME DECLARE @EndTime AS DATETIME BEGIN TRAN SET @BegTime = GETDATE() SELECT ClientName FROM BankDetailTbl WHERE AccountNumber = '7Y290394'; SET @EndTime = GETDATE() SET @TimeDiff = DATEDIFF(SECOND,@EndTime,@BegTime) SELECT @TimeDiff AS QueryCompletionTime COMMIT TRAN |
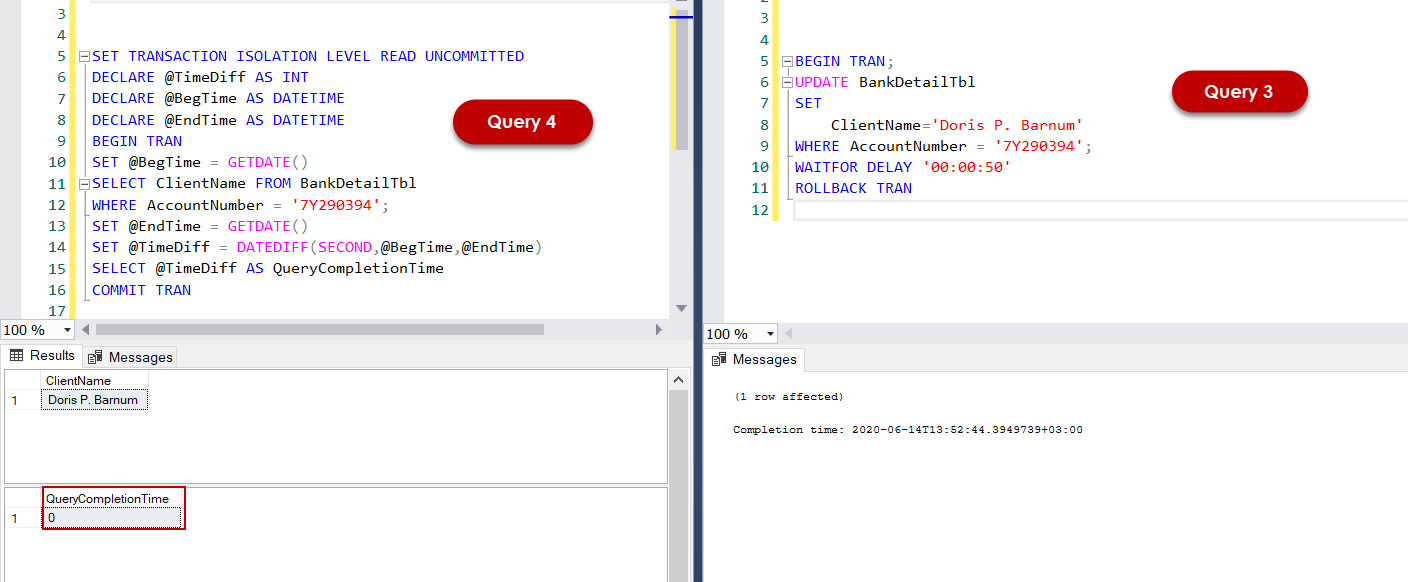
As we can see, the Query-4 did not wait for the completion of the Query-3 and completed as soon as possible.
Allocation Order Scans and Read Uncommitted Isolation Level
In this section, we will discuss an internal secret of the query execution mechanism of the SQL Server. At first, we will execute the following query in the AdventureWorks2017 sample database.
|
1 2 3 4 5 6 7 8 9 |
CHECKPOINT; DBCC DROPCLEANBUFFERS; GO BEGIN TRAN SELECT WorkOrderID, StartDate, EndDate FROM Production.WorkOrder; COMMIT TRAN |
These query results are sorted by the WorkOrderId column.
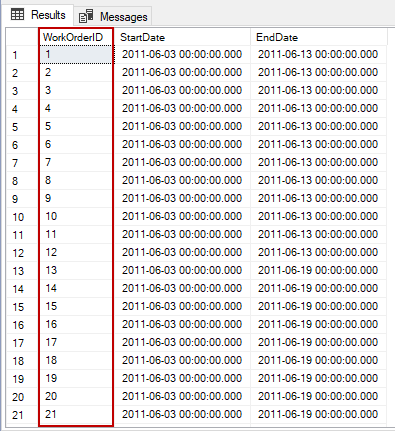
Now, we will change the isolation and execute the same query on another query window. However, the result is slightly different than we expected because of the WorkOrderID column sort.
|
1 2 3 4 5 6 7 8 9 10 |
CHECKPOINT; DBCC DROPCLEANBUFFERS; GO SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED BEGIN TRAN SELECT WorkOrderID, StartDate, EndDate FROM Production.WorkOrder; COMMIT TRAN |
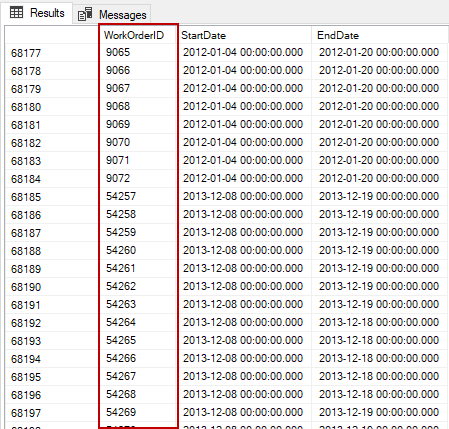
When we compare the execution plans of these two queries, we could not find any logical difference between them.

In the execution plan, if we look at the clustered index scan operator Ordered attribute, it shows the “False” value.
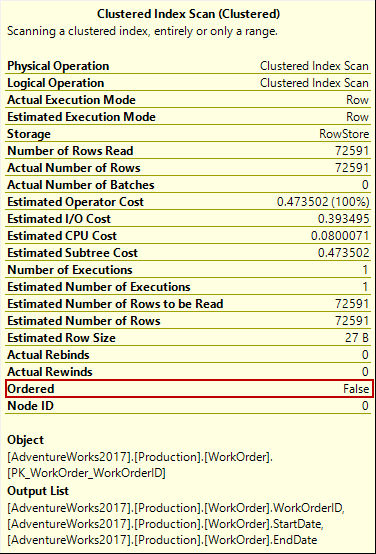
In this case, the storage engine has two options for accessing the data. The first one is an index order scan that uses the B-tree index structure. The second option is an allocation order scan, and it uses the Index Allocation Map (IAM) and performs the scan in the physical allocation order.
Allocation order scans can be considered by the database engine when the following reason meets because we don’t care about the data read data consistency.
- The index size is greater than 64 pages
- The query is running under the Read Committed level or using the NOLOCK hint
- The Ordered attribute of the Index Scan operator is false
Tip: Allocation order scans can be performed when we use the TABLOCK hint in a query.
|
1 2 3 4 5 6 7 8 9 |
CHECKPOINT; DBCC DROPCLEANBUFFERS; GO BEGIN TRAN SELECT WorkOrderID, StartDate, EndDate FROM Production.WorkOrder WITH(TABLOCK); COMMIT TRAN |
Conclusion
In this article, we discussed the dirty read issue and also explained the Read Uncommitted Isolation Level differences. This level has its own characteristics, so when you decide to use it, we need to take into account lock, data consistency, and other issues. At the same time, we also explored the allocation order scan data access method and details.

Most of his career has been focused on SQL Server Database Administration and Development. His current interests are in database administration and Business Intelligence. You can find him on LinkedIn.
View all posts by Esat Erkec
- SQL Performance Tuning tips for newbies - April 15, 2024
- SQL Unit Testing reference guide for beginners - August 11, 2023
- SQL Cheat Sheet for Newbies - February 21, 2023