
In this article, we will talk about two query optimization myths and these myths can be changed according to the characteristics of the queries. Every query can exhibit different behaviors according to data distribution, SQL Server version, database settings, and other tons of parameters therefore the fixed ideas may not help to overcome the query performance issues. In the next part of the article, we will focus on the following most known discourse:
- Read execution plans right to left
- Merge join is faster than hash match join
Introduction
The execution plans are a vital tool that helps to figure out all behaviors and data flow of a query. Execution plans are generated by the query optimizer mainly consider CPU, IO, and memory metrics. So, when we understand a query execution plan properly we can solve the query performance issues more easily. Anyway, to cut a long story short, let’s get into action and work on our examples.
Pre-requirements
In this article, we will use the AdventureWorks database and we will also use the enlarging script that helps to obtain a larger copy of this database.
A query plan is worth a hundred words
The actual execution plan gives more information than the estimated one because it also includes runtime statistics about the executed query and these metrics are very valuable. Therefore, as much as possible, we need to use an actual execution plan to examine the queries. After enabling the actual execution plan of the following query, we will start examining it.
|
1 2 3 4 |
SELECT SUM([UnitPrice]*SalesHeader.SubTotal) AS SubTotal FROM Sales.SalesOrderHeaderEnlarged SalesHeader INNER JOIN sales.SalesOrderDetailEnlarged SalesDetail ON SalesDetail.SalesOrderID = SalesHeader.SalesOrderID WHERE SalesDetail.ProductID >12 |
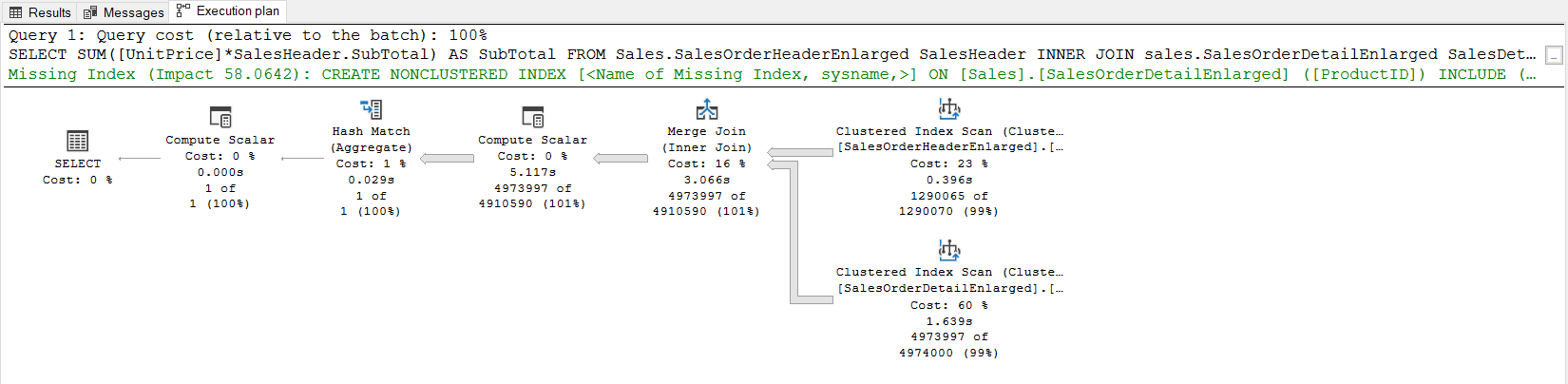
Practically, for the query plans, we need to read an execution plan from the right to the left and from the top to the bottom. However, before starting to read the execution plan of the select statements, we need to glance at the select operator because it contains some different statistics from the other operators. This method always helps us when we deal with query optimization.
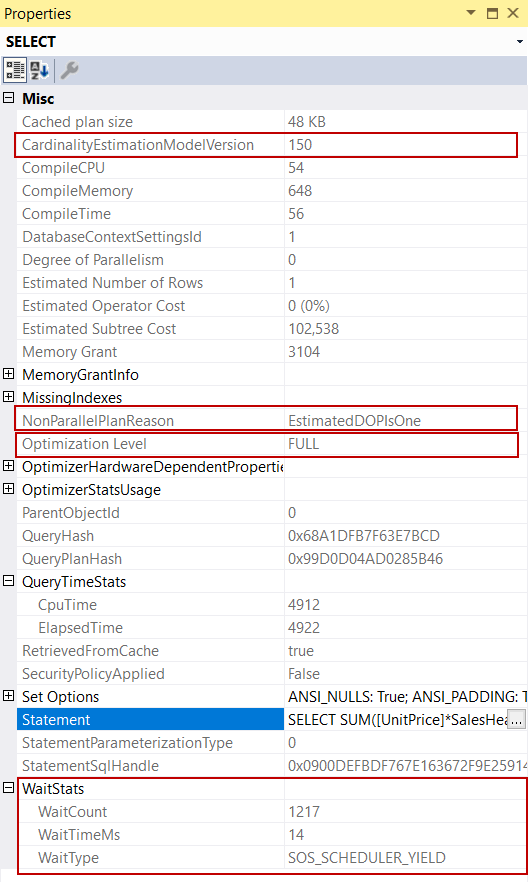
The Cardinality Estimator estimates how many rows will return when a query is executed. The estimated information uses by the query optimizer to calculate the memory requirement of a query. So, if we don’t have any valid reason, we need to enable the latest cardinality estimator model for query optimization and it will be a correct approach. In our example, the query has been executed in SQL Server 2019 for this reason CardinalityEtimationModelVersion shows the value 150. The NonParallelPlanReason attribute shows why the query optimizer does not generate a parallel execution plan. EstimtedDOPIsOne value expresses that the maximum degree of parallelism setting is determined as one. The Optimization Level attribute shows the FULL and it means that the optimizer works well and completes all phases of the query optimization. The WaitStats attribute shows which wait type has occurred during the execution of the query and this information may help to resolve bottlenecks of a query. As a last, we need to consider QueryTimeStats options which help to realize the execution time statistics. We can interpret the execution plan by tracking the numbers on the operators but the select operator includes so valuable details, therefore we have to look at the select operator before reading the execution plan.
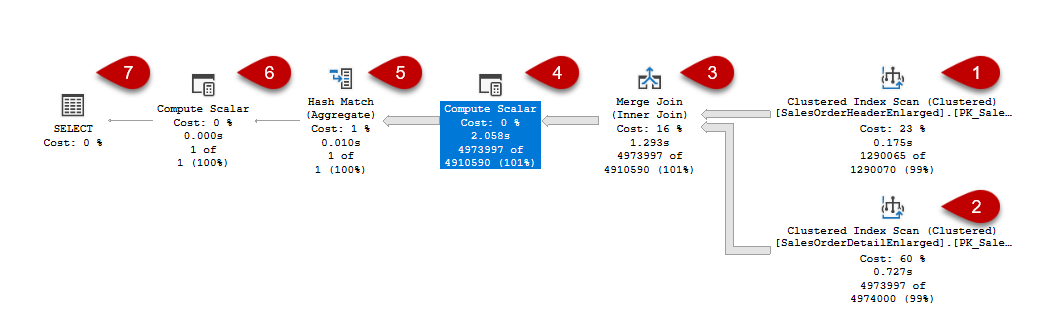
Why a merge join is used in this query plan
Merge join is the most effective way to join type for the large datasets but the two input datasets must be in a sorted manner before processing by it. In the sample execution plan, the clustered index scan operators have returned their result sets in a sorted manner because data is sorted according to the SalesOrderID column so the data engine avoids extra sort activity. We can realize this situation when we look into the Ordered attribute of the clustered index scan operator.
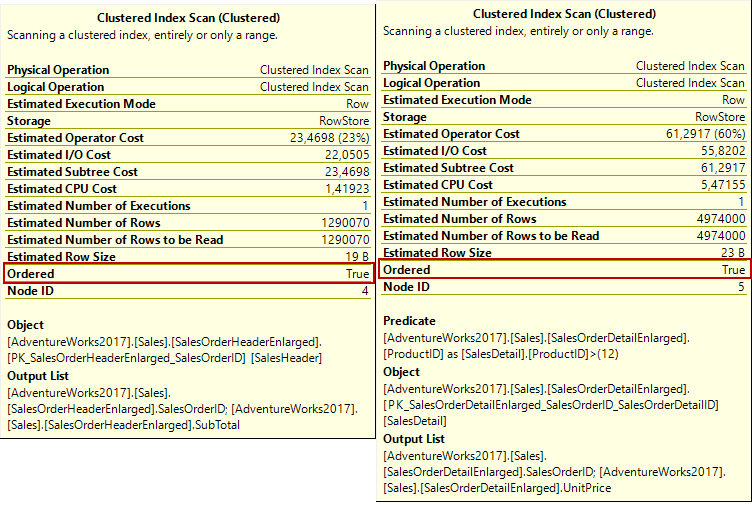
The query optimizer decided to use merge join when its cost is lower than the other join types. If we compare the three different execution plan cost which includes the different join types, we can obviously see the why the query optimizer select the merge join type. In order to see the estimated execution plan of the following queries, we click the Display Estimated Execution Plan and generate their execution plans.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
SELECT SUM([UnitPrice]*SalesHeader.SubTotal) AS SubTotal FROM Sales.SalesOrderHeaderEnlarged SalesHeader INNER JOIN sales.SalesOrderDetailEnlarged SalesDetail ON SalesDetail.SalesOrderID = SalesHeader.SalesOrderID WHERE SalesDetail.ProductID >12 SELECT SUM([UnitPrice]*SalesHeader.SubTotal) AS SubTotal FROM Sales.SalesOrderHeaderEnlarged SalesHeader INNER HASH JOIN sales.SalesOrderDetailEnlarged SalesDetail ON SalesDetail.SalesOrderID = SalesHeader.SalesOrderID WHERE SalesDetail.ProductID >12 SELECT SUM([UnitPrice]*SalesHeader.SubTotal) AS SubTotal FROM Sales.SalesOrderHeaderEnlarged SalesHeader INNER LOOP JOIN sales.SalesOrderDetailEnlarged SalesDetail ON SalesDetail.SalesOrderID = SalesHeader.SalesOrderID WHERE SalesDetail.ProductID >12 |
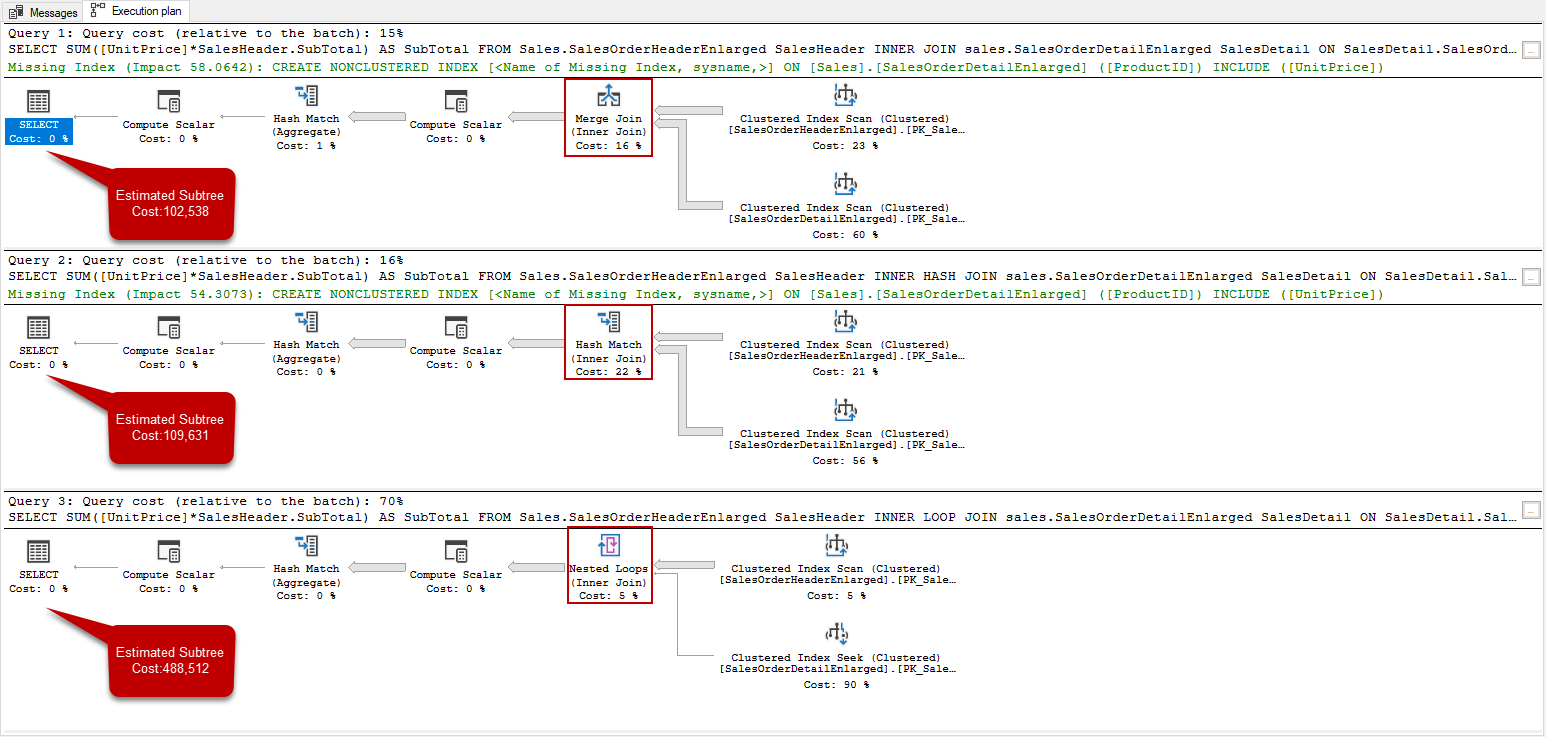
Clearly seen in the above image, the first execution plan cost is lower than the others, for this reason, the optimizer has decided to use hash match join. Understanding the query optimizer cost-based approach is very important for query optimization because execution plan selection is based on this approach.
Which is faster? Merge Join vs Hash Match Join
The hash match join is preferred by the execution plan to join unsorted large datasets but it consumes more memory than the other join types. Now we will force the query optimizer to use hash match join type with help of the HASH JOIN hint and examine the execution plan.
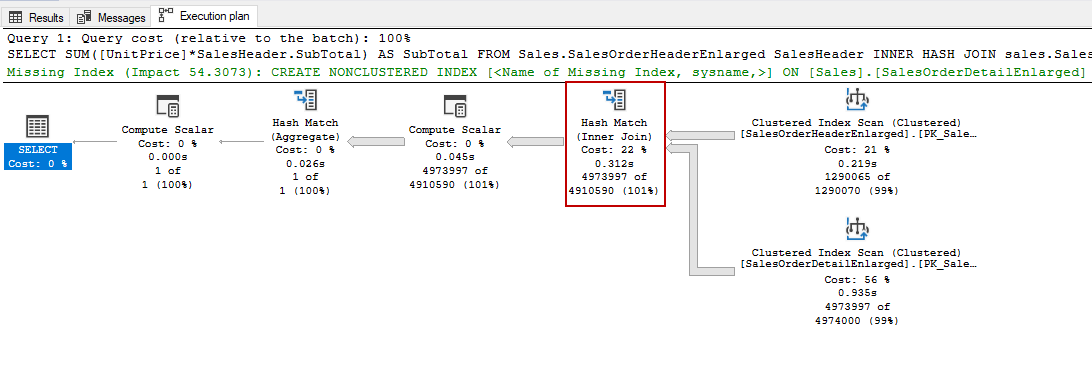
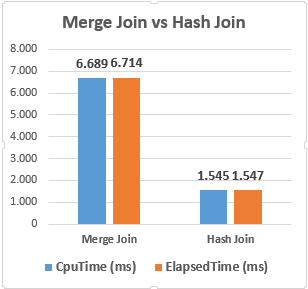
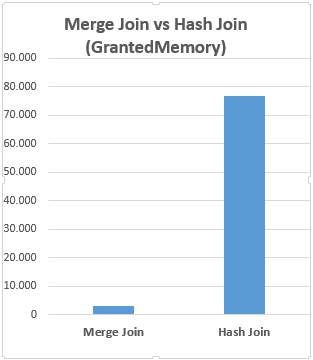
As we can see, the hash match join operator is used instead of the merge join and another interesting thing is related to the execution time of the query. The query which used the hash match join is 4 times faster than the first query.
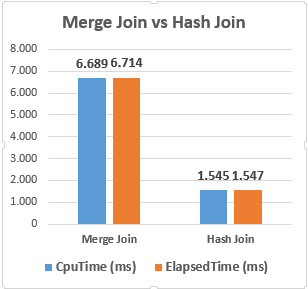
The above graphic illustrates that the hash match join has boosted the performance of the query despite that it has consumed much memory.
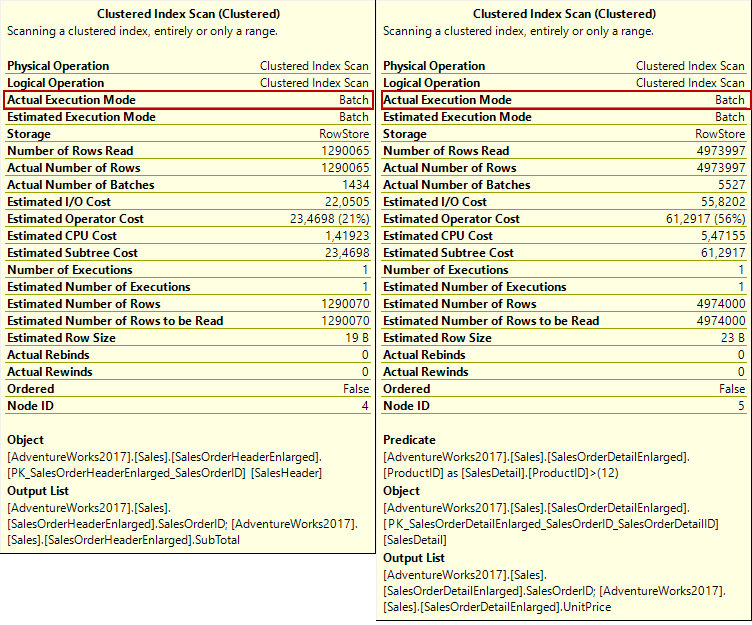
However, we should not overlook one point about the execution plan that includes hash match join. When we hover over the mouse into the clustered index scan operator we will come across an interesting thing. SQL Server has accessed the data using a new feature, named Batch Mode on Rowstore. This feature can handle multiple rows at one time so it helps to improve the performance of the query and hash match join.
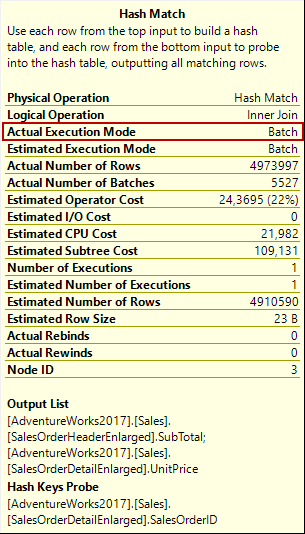
For this execution plan, the hash match join operator will process the mode in batch mode so it also improves the performance of the query.
As a result of this demonstration, hash match join has shown better performance but it consumed much memory. Merge join and hash match join types have advantages and disadvantages, for this reason, their performance can change depending on the various metrics.
Keep Calm and Make Your Choice
In this part of the article, we will prevent the query optimizer to use the merge join operator in their execution plans. The QUERYRULEOFF is used to eliminate some rule for a specific query. When we add the JNtoSM rule after this query hint, the query optimizer eliminates the execution plans which include the merge join operator. In this circumstance, there are only two candidates left, the nested loop join or hash join. Now, execute the following query and look at its execution plan
|
1 2 3 4 5 |
SELECT SUM([UnitPrice]*SalesHeader.SubTotal) AS SubTotal FROM Sales.SalesOrderHeaderEnlarged SalesHeader INNER JOIN sales.SalesOrderDetailEnlarged SalesDetail ON SalesDetail.SalesOrderID = SalesHeader.SalesOrderID WHERE SalesDetail.ProductID >12 OPTION( QUERYRULEOFF JNtoSM ) |
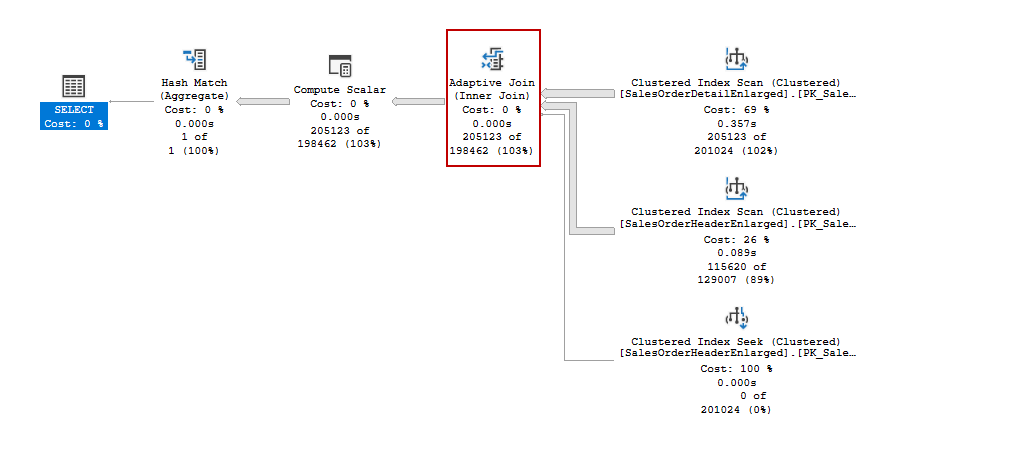
In the execution plan, we see a new operator and its name is Adaptive Join. With the help of this feature, SQL Server decides the join type on the runtime of the query. If the row count is under the Adaptive Threshold value it decides to use Nested Loop join otherwise it will use the Hash Match Join. So that, this approach helps in the query optimization process automatically. For our sample query, adaptive join has decided to use hash match join, because the Actual Join Type property shows this situation.
Conclusion
In this article, we have talked about some query optimization myths. When we deal to improve query performance, we have to analyze the execution plan with all details because lots of question answers are hidden on it. At the same time, we have to ask them questions, if they talk about the below scenarios:
- Read execution plans right to left
- Merge join is faster than hash match join

Most of his career has been focused on SQL Server Database Administration and Development. His current interests are in database administration and Business Intelligence. You can find him on LinkedIn.
View all posts by Esat Erkec
- SQL Performance Tuning tips for newbies - April 15, 2024
- SQL Unit Testing reference guide for beginners - August 11, 2023
- SQL Cheat Sheet for Newbies - February 21, 2023