
Introduction
Since data warehouse is an important element in the data strategy of any organization, it is essential to take necessary actions during designing a Data Warehouse. There are several different designing patterns in a data warehouse, in this article, we will look at what you should avoid during the data warehouse designing.
Places Text Attributes in a Fact Table
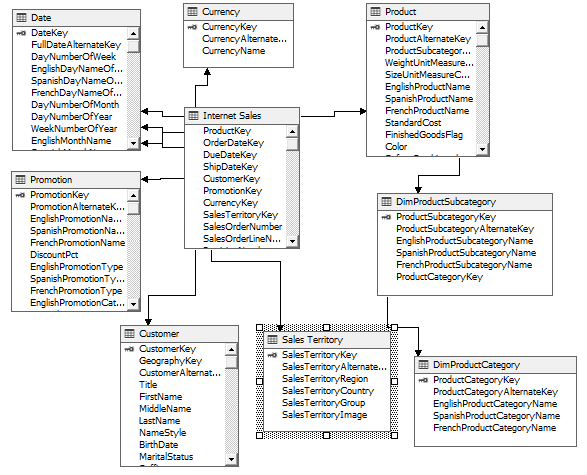
Fact and Dimension tables are the main two tables that are used when designing a data warehouse. The fact table contains measures of columns and surrogate keys that link to the dimension tables. Measure columns are the values that you store in order to measure the business fact. For example, sales amount, quantity are examples for measure columns in a data warehouse. These measures are analyzed with the dimension attributes. Therefore, a fact table should have surrogate keys to join with dimension tables.
The following screenshot shows a relationship between a Fact and Dimension table.
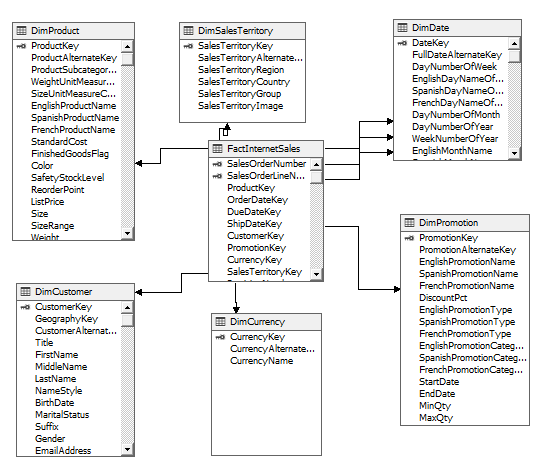
Ideally, you should not have any text columns in the fact table. For example, you tend to have status columns in the fact table to avoid dimension tables. However, ultimately this practice will end up with many status columns in the fact table. Better design practice when designing a data warehouse would be to move all the status to a “Junk-Dimension” and relate the combinations to the fact table with an additional surrogate key.
However, there can be situations where you need to store columns such as Order number in the fact tables. These types of columns are considered audit columns and they are perfectly better to be in the fact table for troubleshooting purposes.
Limit Verbose Descriptors to save space
In typical design in operational databases, we tend to limit the descriptors. For example, instead of storing, Male, we tend to store M and for Females, we tend to store F. We need to understand that data warehouse is a framework that will be used by the middle managers to the top management. When top management is dealing with data, you need to include descriptive values rather than coded values. In today’s world, we are not much concerned about saving space as storage is not costly. Instead, we are looking at delivering better quality services to end-user efficiently during designing a Data Warehouse.
Leave users to calculate measures at Run Time
When we design operational databases, we tend to store only the primary value columns. For example, in an order table, we will limit our columns to Quantity and Unit Price and the Amount will be calculated at the run time. This is done to reduce storage. However, in the world of data warehousing, since we are dealing with data for more than decades, calculating them during the run time will impact the performance of the queries. Therefore, in a data warehouse, we can create physical derived columns in order to improve the performance. Again, we don’t place much emphasis on storage at the designing a data warehouse these days as it is not a scarce resource.
Split Hierarchies into Multiple Dimensions
We have discussed hierarchies in the data warehouse in a previous article, Enhancing Data Analytics with SSAS Dimension Hierarchies. When we create hierarchies, it is important to include all the hierarchies’ members in a single dimension. Since we follow the denormalization structures when designing a data warehouse, typically these members will be in a dimension table.
However, in SQL Server Analysis Services (SSAS), if you have a proper relationship between dimension tables, even if these attributes are split between multiple tables, the tool will integrate these attributes into one dimension.
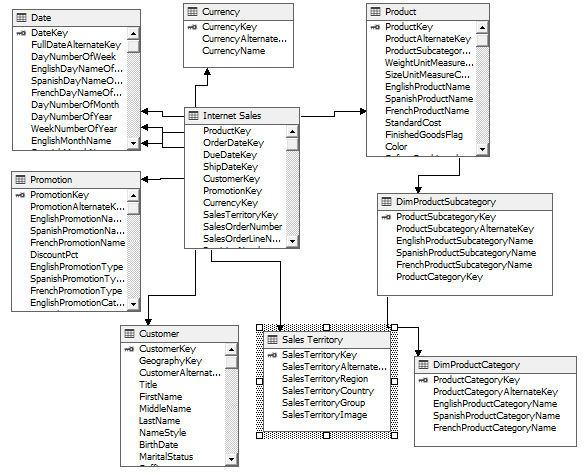
In the above data warehouse schema design, the Product dimension is split between Production, DimProductSubcategory, and DimProductCategory tables. When a hierarchy is created for Product Category, Product Subcategory, and Product Name attributes, the SSAS OLAP cube will be created with one dimension.
Ignore the need to track dimension changes
One of the important design concepts in data warehousing is tracking the changes in Dimension attributes. Though we may not need to track historical changes in OLTP, we need to track the changes in a data warehouse. There are different types of Slowly Changing Dimension (SCD) to achieve the historical aspect in a data warehouse. The most popular SCD is a type 2 SCD. However, at the design stage, you need to identify what dimension should be covered with Type 2 SCD as well as you need to identify what are the relevant attributes that you need to cover for historical changes.
Though the implementation of Type 2 SCD can be done later, it is important to identify the Type 2 SCD at the early stage so that you will capture all the changes in the relevant Dimension.
Solve all Performance problems with more Hardware
You are dealing with a large volume of data in the data warehouse. Further, most of your reports need a large volume of data to be read. Due to these properties, you tend to confer with performance issues in the data warehouse. Not only in a data warehouse, but in OLTP, most of the administrators will decide to increase hardware resources to improve performance. Though you will experience some improvements with the increase of hardware resources, this is not a permanent solution. At the time of designing a Data Warehouse, you need to consider the performance of the data warehouse not when the data warehouse is being used by the users.
If the volume is very high, you can consider aggregated tables, indexes, column store indexes, OLAP cube, etc. to improve the data warehouse query performance.
Use operational keys to join Dimensions and Facts
We use surrogate keys to join the Fact and Dimension table in the data warehouse instead of Operational keys in OLTP. There can be situations where operational keys can be modified in the OLTP end. If that happens, you need to change all the values in a fact table. We need to understand that the fact table consists of many records. If you are changing a large number of records, the fact table will not be accessible until the modifications are completed.
Further, operational keys can be string columns and when joining from string columns, there can be performance issues. Since data warehouse designers do not have control over the operational keys, to mitigate the performance issues, we need to introduce a customized column.
In the case of Type 2 SCDs, there can be situation multiple rows will exist for the same operational value. In that situation, we can only create Primary Key by introducing a surrogate key.
Neglect to declare and comply with Fact Grain
It is essential to declare the Fact grain at the design stage. Every fact table should have one grain and you should be having multiple grain levels in the same fact table. For example, students’ attendance will be daily while their marks are on a term basis. This means you cannot have attendance and marks in the same fact unless you aggregate the students’ attendance to a term basis.
In most incidents, at the designing stage of the data warehouse, you tend to declare and comply with the defined fact grain. However, when there are modifications requested by the end-users, in the interest of time, you tend to violate the grain. This violation will result in many other performance issues and a lot of maintenance issues later.
Use a report to design the Dimensional Model
A data warehouse is a framework for data analytics. If it is a framework, during the time of requirement elicitation phase, it is essential to examine the entire process of the organization. However, end-users will provide requirements by means of reports. During the Designing a Data Warehouse, if you are confined to these reports, the data warehouse will not be able to provide framework capabilities.
Expect users to query Normalized Atomic Data
Most of the users of a data warehouse are business users who do not have experience in writing queries by joining multiple tables. We need to incorporate OLAP cube tools such as SSAS MDM or SSAS Tabular etc when designing a data warehouse.
Fail to conform to Facts and Dimensions
You start with simple data marts which consist of a handful of facts and dimension tables. Over time, you will extend those fact and dimension tables to cover much broader requirements. However, you need to make sure that you don’t duplicate tables especially dimension tables. Though duplication is acceptable at designing a data warehouse for different grains, there is no value of the same data in multiple dimensions. In that situation, there can be a lot of administrative and performance issues.
Conclusion
In this article, we discussed the things that you should avoid when designing a data warehouse. When the design decisions are made, it is important to remember that you are dealing with a large quantity of data with historical values. Further, the data warehouse is a framework for data analytics, not a mere reporting system.

View all posts by Dinesh Asanka
- Testing Type 2 Slowly Changing Dimensions in a Data Warehouse - May 30, 2022
- Incremental Data Extraction for ETL using Database Snapshots - January 10, 2022
- Use Replication to improve the ETL process in SQL Server - November 4, 2021