

In this article, I am going to explain how we can create a dynamic pivot table in SQL Server. Pivot tables are a piece of summarized information that is generated from a large underlying dataset. It is generally used to report on specific dimensions from the vast datasets. Essentially, the user can convert rows into columns. This gives the users the ability to transpose columns from a SQL Server table easily and create reports as per the requirements.
Some pivot tables are also created to help in data analysis, mainly for slicing and dicing with the data and generate analytical queries after all. If you see the figure below, you’ll have some idea how a pivot table is created from a table.

Figure 1 – Pivot Table Example
If you see the figure above, you can see that there are two tables. The table on the left is the actual table that contains the original records. The table on the right is a pivot table that is generated by converting the rows from the original table into columns. Basically, a pivot table will contain three specific areas, mainly – rows, columns, and values. In the above illustration, the rows are taken from the Student column, the columns are taken from the Subject, and the values are created by aggregating the Marks column.
Creating a sample data
Now that we have some idea about how a pivot table works let us go ahead and try our hands-on. You can execute the script below to create sample data, and we will try to implement the above illustration here.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
CREATE TABLE Grades( [Student] VARCHAR(50), [Subject] VARCHAR(50), [Marks] INT ) GO INSERT INTO Grades VALUES ('Jacob','Mathematics',100), ('Jacob','Science',95), ('Jacob','Geography',90), ('Amilee','Mathematics',90), ('Amilee','Science',90), ('Amilee','Geography',100) GO |
Let us try to select the data from the table that we just created as below.
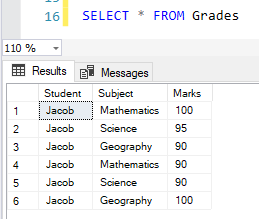
Figure 2 – Sample Dataset for Pivot Table
Applying the PIVOT Operator
Now that we have our data ready, we can go ahead and create the pivot table in SQL Server. Considering the same illustration as above, we will keep the Student column as rows and take the Subject for the columns. Also, another important point to note here is that while writing the query for the pivot table in SQL Server, we need to provide a distinct list of column values that we would like to visualize in the pivot table. For this script, we can see that we have three distinct subjects available in the original dataset, so we must provide these three in the list while creating the pivot table.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
SELECT * FROM ( SELECT [Student], [Subject], [Marks] FROM Grades ) StudentResults PIVOT ( SUM([Marks]) FOR [Subject] IN ( [Mathematics], [Science], [Geography] ) ) AS PivotTable |
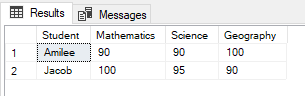
Figure 3 – Applying the PIVOT Operator
As you can see in the figure above, the pivot table has been created and we have converted the rows for Subjects into distinct columns.
Now let us try to break the above script and understand how it works. If you see the script, clearly, we can divide it into two separate sections – the first part in which we select data from the original table as it is and in the second part, we define how the pivot table should be created. In the script, we also mention some specific keywords like SUM, FOR and IN, which are meant for use by the PIVOT operator only. Let’s quickly talk about these keywords.
The SUM operator
In the script, I have used the SUM operator, which will essentially aggregate the values from the Marks column so that it can be used in the pivot table. It is mandatory for the pivot operator to use an aggregated column that it can display for the values sections.
The FOR keyword
The FOR keyword is a special keyword used for the pivot table in SQL Server scripts. This operator tells the pivot operator on which column do we need to apply the pivot function. Basically, the column which is to be converted from rows into columns.
The IN keyword
The IN keyword, as already explained above, lists all the distinct values from the pivot column that we want to add to the pivot table column list. For this example, since we have only three distinct values for the Subject column, we provide all the three in the list for the IN keyword.
The only limitation in this process is that we need to provide hardcoded values for the columns that we need to select from the pivot table. For instance, if a new subject value is inserted into the table, the pivot table won’t be able to display the new value as a column because it is not defined in the list for the IN operator. Let us go ahead and insert a few records into the table for a different subject – “History“.
|
1 2 3 4 |
INSERT INTO Grades VALUES ('Jacob','History',80), ('Amilee','History',90) GO |
Let us execute the query for displaying the pivot table as we did previously.
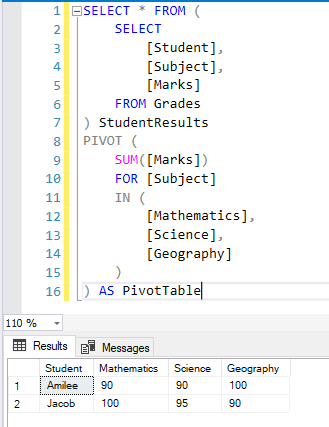
Figure 4 – Running the PIVOT Query
As you can see, the new subject that we just inserted into the table is not available in the PIVOT table. This is because we did not mention the new column in the IN list of the PIVOT operator. This is one of the limitations of the PIVOT table in SQL. Each time we want to include a new column in the PIVOT, we would need to go and modify the underlying code.
Another scenario would be like if the requirements change and now, we need to pivot students instead of the subjects, even in such a case, we would need to modify the entire query. In order to avoid this, we can create something dynamic in which we can configure the columns on which we would need the PIVOT table. Let’s go ahead and understand how to make a dynamic stored procedure that will return a PIVOT table in SQL.
Building a Dynamic Stored Procedure for PIVOT Tables
Let’s encapsulate the entire PIVOT script in a stored procedure. This stored procedure will have the configurable options in which we should be able to customize our requirements just by altering some parameterized values. The script for the dynamic PIVOT table in SQL is below.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
CREATE PROCEDURE dbo.DynamicPivotTableInSql @ColumnToPivot NVARCHAR(255), @ListToPivot NVARCHAR(255) AS BEGIN DECLARE @SqlStatement NVARCHAR(MAX) SET @SqlStatement = N' SELECT * FROM ( SELECT [Student], [Subject], [Marks] FROM Grades ) StudentResults PIVOT ( SUM([Marks]) FOR ['+@ColumnToPivot+'] IN ( '+@ListToPivot+' ) ) AS PivotTable '; EXEC(@SqlStatement) END |
As you can see in the script above, I have two parameterized variables. The details of these two parameters are as follows.
- @ColumnToPivot – This parameter accepts the name of the column in the base table on which the pivot table is going to be applied. For the current scenario, it will be the “Subject” column because we would like to pivot the base table and display all the subjects in the columns
- @ListToPivot – This parameter accepts the list of values that we want to visualize as a column in the pivot table in SQL
Executing the Dynamic Stored Procedure
Now that our dynamic stored procedure is ready let us go ahead and execute it. Let us replicate the first scenario where we visualized all the three subjects – Mathematics, Science and Geography in the pivot table in SQL. Execute the script as below.
|
1 2 3 |
EXEC dbo.DynamicPivotTableInSql N'Subject' ,N'[Mathematics],[Science],[Geography]' |
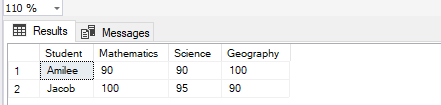
Figure 5 – Executing Dynamic Stored Procedure
As you can see, we have now provided the name of the column “Subject” as the first parameter and the list of pivot columns as the second column.
Suppose, now we would also like to include the marks for the column “History” in this pivot table, the only thing that you should do is to add the name of the column in the second parameter and execute the stored procedure.
|
1 2 3 |
EXEC dbo.DynamicPivotTableInSql N'Subject' ,N'[Mathematics],[Science],[Geography],[History]' |
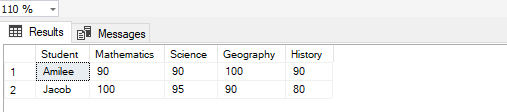
Figure 6 – Executing Dynamic Stored Procedure Modified
As easy as that, you can add as many columns you’d like to add to the list and the pivot table will be displayed accordingly.
Let us now consider another scenario where you need to display the name of the students on the columns and the subjects on the rows—just a vice versa scenario of what we have been doing all along. The solution is also simple, as you might have expected. We will just modify the values in both the parameters such that the first parameter indicates the column “Student” and the second parameter will contain the list of students that you want along with the columns. The stored procedure is as follows.
|
1 2 3 |
EXEC dbo.DynamicPivotTableInSql N'Student' ,N'[Amilee],[Jacob]' |
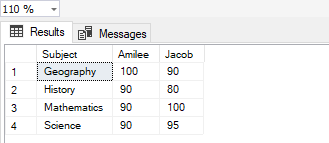
Figure 7 – Dynamic Stored Procedure
As you can see in the image above, the pivot table in SQL is dynamically modified without having to modify the underlying code behind.
Conclusion
In this article, I have explained what a pivot table in SQL is and how to create one. I have also demonstrated a simple scenario in which you can implement pivot tables. Finally, I have also shown how to parameterize the pivot table script such that the values table structure can be easily altered without having to modify the underlying code.

He is a prolific author, with over 100 articles published on various technical blogs, including his own blog, and a frequent contributor to different technical forums.
In his leisure time, he enjoys amateur photography mostly street imagery and still life. Some glimpses of his work can be found on Instagram. You can also find him on LinkedIn
View all posts by Aveek Das
- Getting started with PostgreSQL on Docker - August 12, 2022
- Getting started with Spatial Data in PostgreSQL - January 13, 2022
- An overview of Power BI Incremental Refresh - December 6, 2021