This article will restore a Transparent Data Encrypted Azure SQL Database into an on-premise SQL Server. Further, we will also create a copy of the Azure database on the same server.
Read more »Rajendra Gupta

Hi! I am Rajendra Gupta, Database Specialist and Architect, helping organizations implement Microsoft SQL Server, Azure, Couchbase, AWS solutions fast and efficiently, fix related issues, and Performance Tuning with over 14 years of experience.
I am the author of the book "DP-300 Administering Relational Database on Microsoft Azure". I published more than 650 technical articles on MSSQLTips, SQLShack, Quest, CodingSight, and SeveralNines.
I am the creator of one of the biggest free online collections of articles on a single topic, with his 50-part series on SQL Server Always On Availability Groups.
Based on my contribution to the SQL Server community, I have been recognized as the prestigious Best Author of the Year continuously in 2019, 2020, and 2021 (2nd Rank) at SQLShack and the MSSQLTIPS champions award in 2020.
Personal Blog: https://www.dbblogger.com
I am always interested in new challenges so if you need consulting help, reach me at rajendra.gupta16@gmail.com
View all posts by Rajendra Gupta
I am the author of the book "DP-300 Administering Relational Database on Microsoft Azure". I published more than 650 technical articles on MSSQLTips, SQLShack, Quest, CodingSight, and SeveralNines.
I am the creator of one of the biggest free online collections of articles on a single topic, with his 50-part series on SQL Server Always On Availability Groups.
Based on my contribution to the SQL Server community, I have been recognized as the prestigious Best Author of the Year continuously in 2019, 2020, and 2021 (2nd Rank) at SQLShack and the MSSQLTIPS champions award in 2020.
Personal Blog: https://www.dbblogger.com
I am always interested in new challenges so if you need consulting help, reach me at rajendra.gupta16@gmail.com
View all posts by Rajendra Gupta
Latest posts by Rajendra Gupta (see all)
- Understanding PostgreSQL SUBSTRING function - September 21, 2024
- How to install PostgreSQL on Ubuntu - July 13, 2023
- How to use the CROSSTAB function in PostgreSQL - February 17, 2023
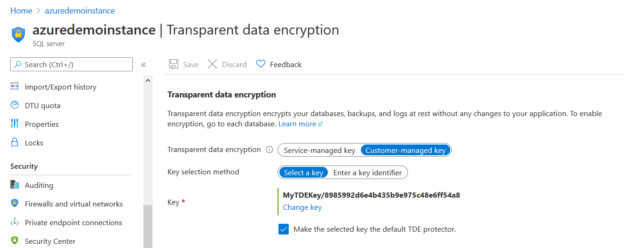
TDE customer-managed keys in Azure SQL Database
June 24, 2021Azure SQL Database is a Platform-as-a-Service (PaaS) solution that offers managed database service. Azure DB provides many features such as automatic database tuning, vulnerability assessment, automated patching, performance tuning, alerts. It provides a 99.995% availability SLA for the Zone redundant database in the business-critical service tier.
Read more »
Query Store Hints in Azure SQL Database
June 22, 2021This article explores the recently announced preview feature of Azure SQL Database – Query Store Hints.
Read more »
Azure Automation: Azure Logic Apps for face recognition and insert its data into Azure SQL Database
June 15, 2021Today, we will implement an Azure Logic App for face recognition and insert its data into an Azure SQL database.
Read more »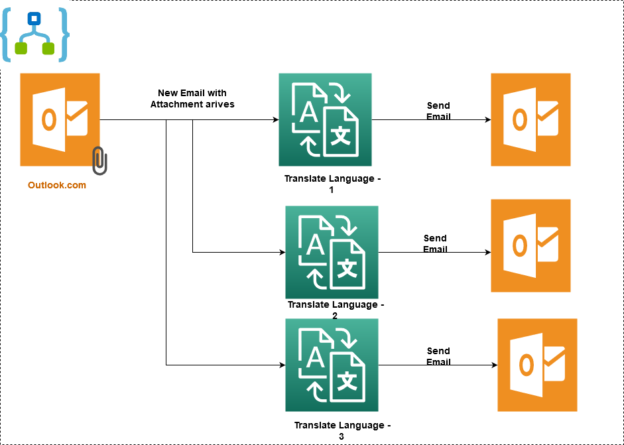
Azure Automation: Translate documents into different languages using Cognitive Services with Azure Logic Apps
June 9, 2021Suppose you write a technical blog in the English language for your website. You have good followers in a country where the primary language is not English. You want to translate the document content in their native language for a wider reach.
Read more »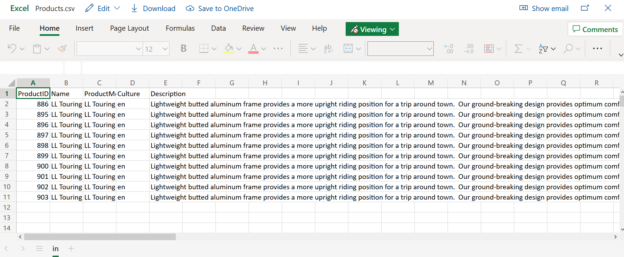
Azure Automation: Export Azure SQL database data to CSV files using Azure Logic Apps
June 1, 2021This article uses Azure automation techniques for sending query results as a CSV file attachment in Azure SQL Database by using Azure logic apps.
Read more »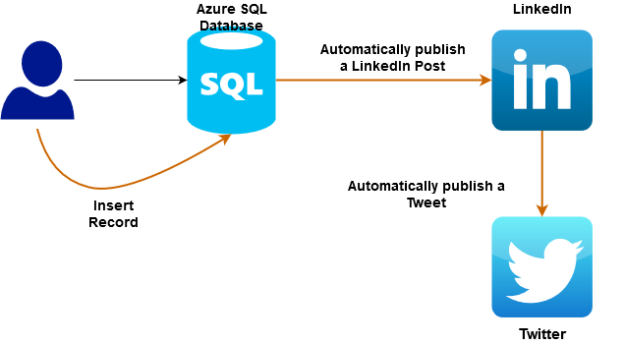
Azure Automation: Publish LinkedIn posts and tweets automatically using Azure Logic Apps
May 25, 2021This article implements Azure Automation logic for automatically publishing a LinkedIn post and Twitter’s Tweet using the simplified Azure Logic App.
Read more »
Azure Automation: Use Azure Logic Apps to import data into Azure SQL Database from Azure Blob Storage
May 17, 2021This article uses Azure Automation techniques to import data into Azure SQL Database from Azure Storage container.
Read more »
Azure Automation: Analyzing Twitter sentiments using Azure Logic Apps
May 14, 2021This article configures Azure Automation for Analyzing Twitter sentiments using Azure Logic Apps and stores them into Azure SQL Database.
Read more »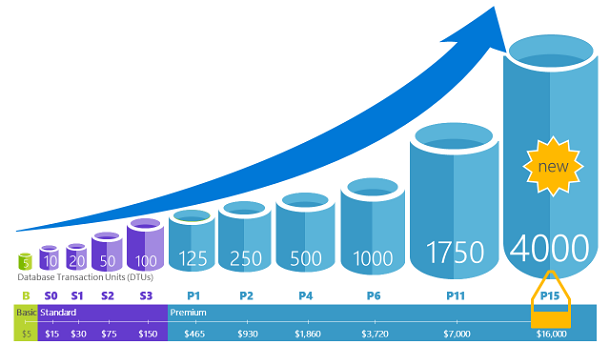
Azure Automation: Auto-scaling Azure SQL database with Azure Logic Apps
May 12, 2021Azure SQL Database supports DTU-based and vCores based purchasing models for deploying your databases in the Azure managed service.
Read more »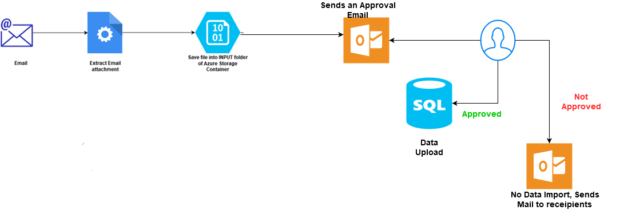
Azure Automation: Building approval-based automated workflows using Azure Logic Apps
May 11, 2021In the Azure Automation article, Azure Automation: Automate data loading from email attachments using Azure Logic Apps, we did the following tasks:
Read more »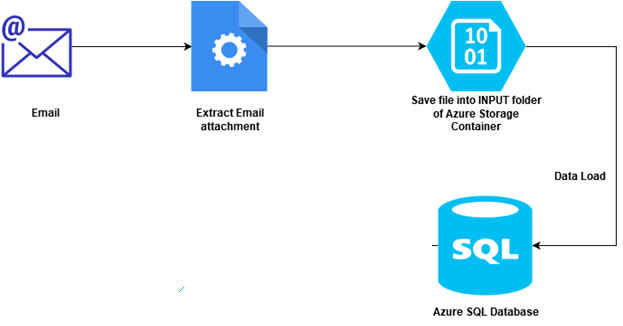
Azure Automation: Automate data loading from email attachments using Azure Logic Apps
May 11, 2021This article will explore Azure automation for automatic data loading into Azure SQL Databases using the Azure Logic App.
Read more »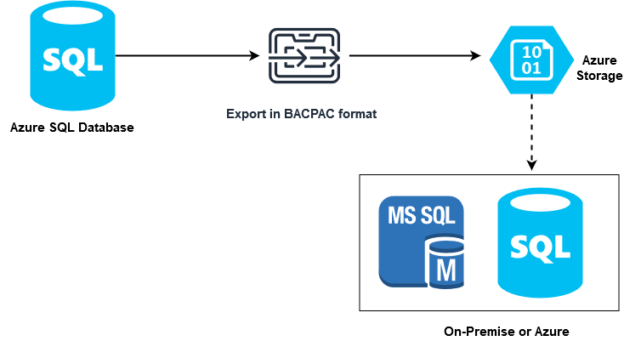
Azure Automation: Export Azure SQL Database to Blob Storage in a BACPAC file
May 5, 2021Azure SQL Database supports exporting schema and data in a compressed format BACPAC. We can store this BACPAC file into an Azure storage account. Later, this BACPAC file can help restore the Azure SQL database, and Azure managed SQL instance or on-premises SQL Server.
Read more »
Azure Automation: Create database copies of Azure SQL Database
April 27, 2021This article will explore Azure automation for creating a new Azure SQL Database copy.
Read more »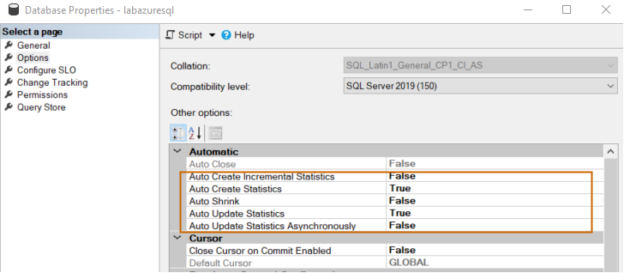
Azure Automation: Automate Azure SQL Database indexes and statistics maintenance
April 27, 2021Azure SQL Database is a PaaS solution for migrating your on-premises databases to the Azure cloud infrastructure. It is a managed service and Azure manages the infrastructure, database availability, backup restore, and compute resources.
Read more »Lift and Shift SSIS packages using Azure Data Factory V2
April 23, 2021This article will explore the process for Lift and Shift SSIS packages to Azure using Azure Data Factory V2.
Read more »
Azure Automation: Automate Pause and Resume of Azure Analysis Services
April 20, 2021This article explores Azure Automation for the change state of Azure Analysis Services.
Read more »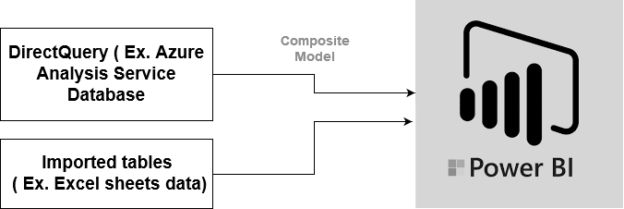
Direct Query Mode in Power BI for Azure Analysis Services
April 19, 2021In this article, we will explore Direct Query Mode in Power BI for Azure Analysis Services.
Read more »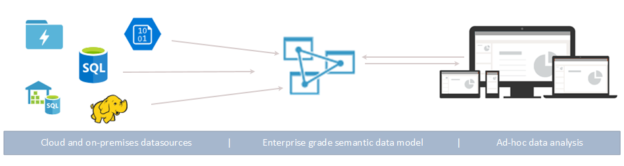
Azure Analysis Services and Power BI Live connections
April 14, 2021In this article, we will deploy Azure Analysis Services and create a live connection in the Power BI.
Read more »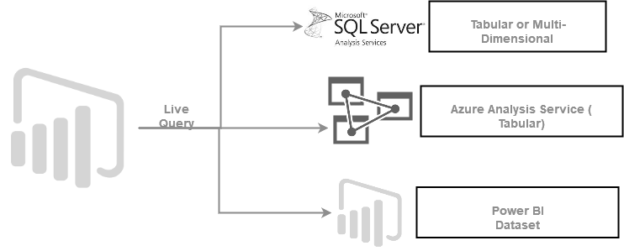
An overview of Power BI data models
April 12, 2021Power BI is a business analytics solution provided by Microsoft. It helps you to create data visualizations from various data sources. We can import data from these data sources, create a data model, and prepares reports, visuals. These data sources are as below:
Read more »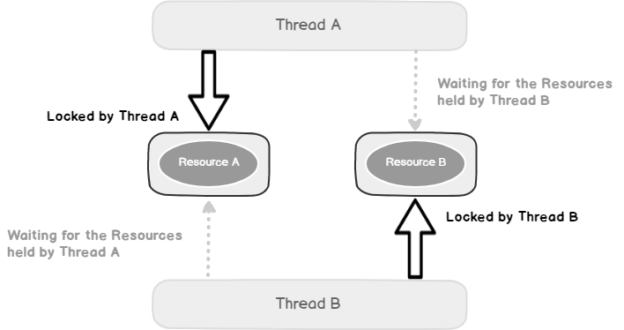
Capturing deadlocks on AWS RDS SQL Server databases
April 7, 2021This article will explore the process to capture deadlock XML and deadlock graphs for AWS RDS SQL Server databases.
Read more »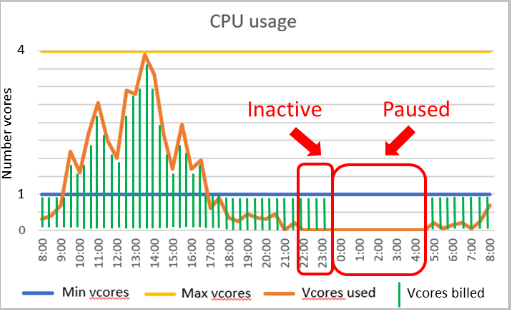
Automatic Pause and Resume of an Azure SQL database
April 2, 2021Azure SQL Database is an Infrastructure-as-a-Service component for migrating your on-premises SQL Server to cloud infrastructure. We always look for performance, cost, and scaling resources while we plan resources in the cloud. Many times, we do not want our databases running 24*7*365. Suppose you have a development or training database. Your developers work during the daytime on the weekdays. If you deploy an Azure SQL Database, you don’t get an option to stop it. You get charged for it whether you use it actively or not.
Read more »
Moving the SSISDB Catalog on a new SQL Server instance
March 30, 2021This article will explore the right way of moving integration services (SSIS) catalog SQL Database to a new instance.
Read more »
Configure long-term backup retention for Azure SQL database
March 25, 2021This article configures a long-term backup retention policy for Azure SQL Database.
Read more »
Create a transactionally consistent copy of Azure SQL database
March 22, 2021In this article, we implement a copy of the Azure SQL database using both Azure Web Portal and Azure CLI.
Read more »