Description
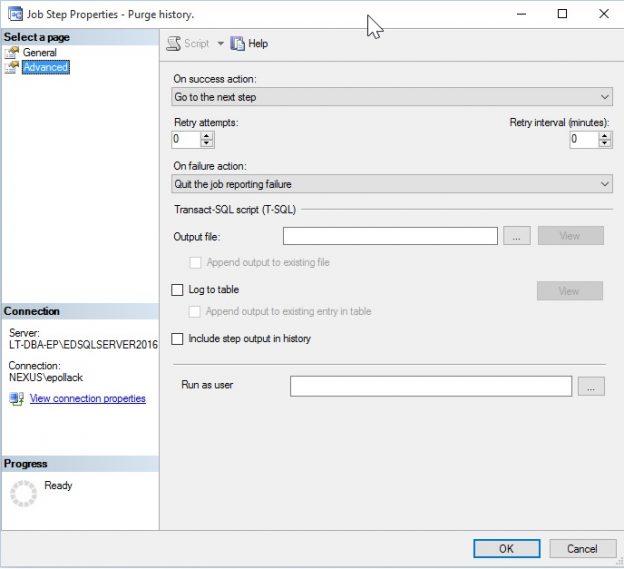
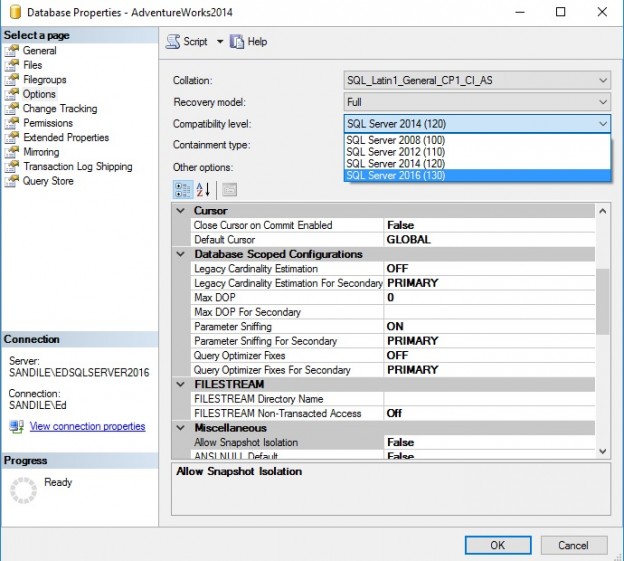
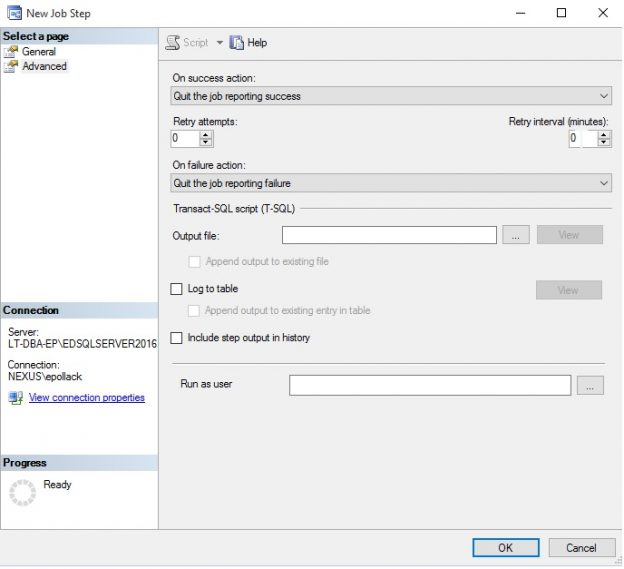
Once collected, job performance metrics can be used for a variety of reporting needs, from locating jobs that are not performing well to finding optimal release windows, scheduling maintenance, or trending over time. These techniques allow us to maintain insight into parts of SQL Server that are often not monitored enough and prevent job-related emergencies before they become emergencies.
Read more »