
Description
Converting a delimited string into a dataset or transforming it into useful data can be an extremely useful tool when working with complex inputs or user-provided data. There are many methods available to accomplish this task; here we will discuss many of them, comparing performance, accuracy, and availability!
Introduction
While we try to ensure that the queries we write are set-based, and run as efficiently as possible, there are many scenarios when delimited strings can be a more efficient way to manage parameters or lists. Sometimes alternatives, such as temp tables, table-valued parameters, or other set-based approaches simply aren’t available. Regardless of reasons, there is a frequent need to convert a delimited string to and from a tabular structure.
Our goal is to examine many different approaches towards this problem. We’ll dive into each method, discuss how and why they work, and then compare and contrast performance for both small and large volumes of data. The results should aid you when trying to work through problems involving delimited data.
As a convention, this article will use comma separated values in all demos, but commas can be replaced with any other delimiter or set of delimiting characters. This convention allows for consistency and is the most common way in which list data is spliced. We will create functions that will be used to manage the creation, or concatenation of data into delimited strings. This allows for portability and reuse of code when any of these methods are implemented in your database environments.
Creating Delimited Data
The simpler use case for delimited strings is the need to create them. As a method of data output, either to a file or an application, there can be benefits in crunching data into a list prior to sending it along its way. For starters, we can take a variable number of columns or rows and turn them into a variable of known size or shape. This is a convenience for any stored procedure that can have a highly variable set of outputs. It can be even more useful when outputting data to a file for use in a data feed or log.
There are a variety of ways to generate delimited strings from data within tables. We’ll start with the scariest option available: The Iterative Approach. This is where we cue the Halloween sound effects and spooky music.
The Iterative Approach
In terms of simplicity, iterating through a table row-by-row is very easy to script, easy to understand, and simple to modify. For anyone not too familiar with SQL query performance, it’s an easy trap to fall into for a variety of reasons:
SQL Server is optimized for set-based queries. Iterative approaches require repetitive table access, which can be extremely slow and expensive.
Iterative approaches are very fast for small row sets, leading us to the common mistake of accepting small-scale development data sets as indicative of large-scale production performance.
Debugging and gauging performance can be difficult when a loop is repeating many, many times. Ie: in what iteration was it when something misbehaved, created bad data, or broke?
The performance of a single iteration may be better than a set-based approach, but after some quantity of iterations, the sum of query costs will exceed that of getting everything in a single query.
Consider the following example of a cursor-based approach that builds a list of sales order ID numbers from a fairly selective query:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
DECLARE @Sales_Order_ID INT; DECLARE @Sales_Order_Id_List VARCHAR(MAX) = ''; DECLARE Sales_Order_Cursor CURSOR FOR SELECT SalesOrderID FROM Sales.SalesOrderHeader WHERE Status = 5 AND OrderDate BETWEEN '1/1/2014' AND '2/1/2014' AND TotalDue > 140000; OPEN Sales_Order_Cursor; FETCH NEXT FROM Sales_Order_Cursor INTO @Sales_Order_ID; WHILE @@FETCH_STATUS = 0 BEGIN SELECT @Sales_Order_Id_List = @Sales_Order_Id_List + CAST(@Sales_Order_ID AS VARCHAR(MAX)) + ','; FETCH NEXT FROM Sales_Order_Cursor INTO @Sales_Order_ID; END SELECT @Sales_Order_Id_List = LEFT(@Sales_Order_Id_List, LEN(@Sales_Order_Id_List) - 1); CLOSE Sales_Order_Cursor; DEALLOCATE Sales_Order_Cursor; SELECT @Sales_Order_Id_List AS Sales_Order_Id_List; |
The above TSQL will declare a cursor that will be used to iterate through all sales order headers with a specific status, order date range, and total amount due. The cursor is then open and iterated through using a WHILE loop. At the end, we remove the trailing comma from our string-building and clean up the cursor object. The results are displayed as follows:

We can see that the comma-separated list was generated correctly, and our ten IDs were returned as we wanted. Execution only took a few seconds, but that in of itself should be a warning sign: Why did a result set of ten rows against a not-terribly-large table take more than a few milliseconds? Let’s take a look at the STATISTICS IO metrics, as well as the execution plan for this script:

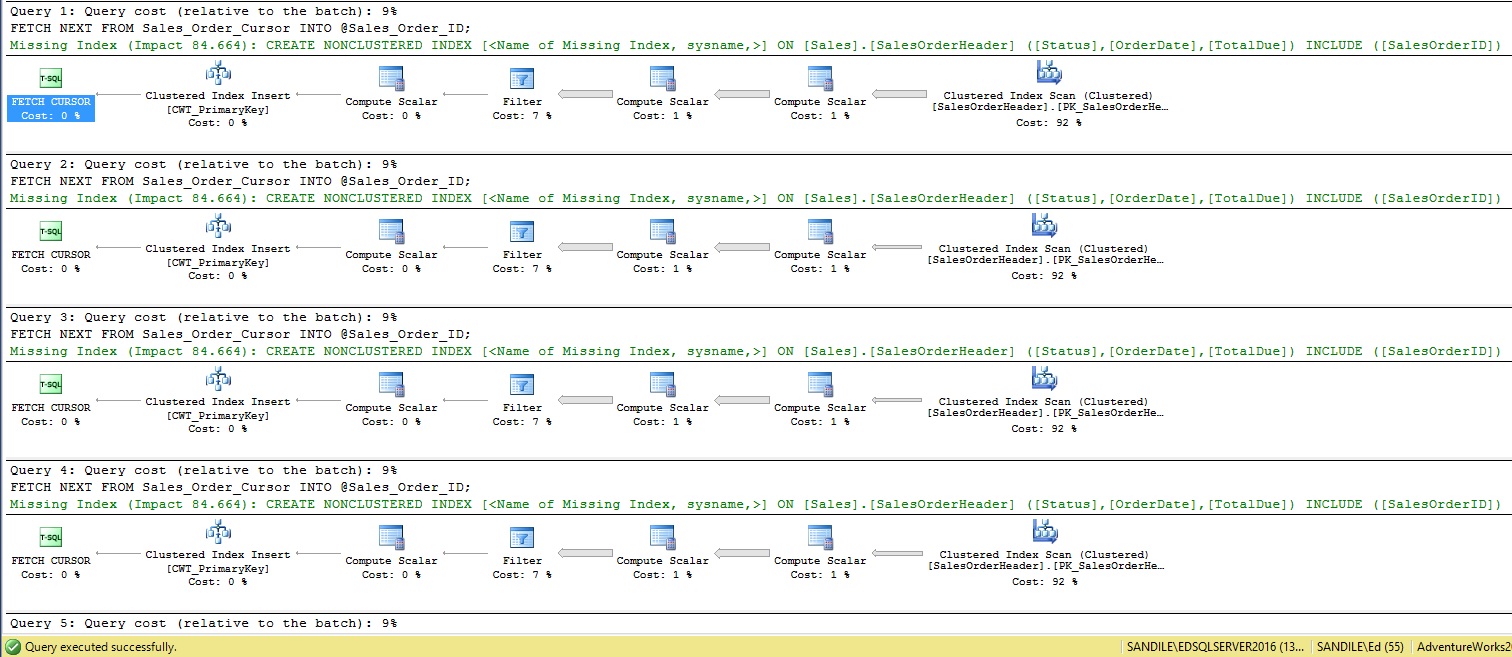
The execution plan is cut off, but you can be assured that there are six more similar plans below the ones pictured here. These metrics are misleading as each loop doesn’t seem too bad, right? Just 9% of the subtree cost or a few hundred reads doesn’t seem too wild, but add up all of these costs and it becomes clear that this won’t scale. What if we had thousands of rows to iterate through? For 5,000 rows, we would be looking at about 147,995,000 reads! Not to mention a very, very long execution plan that is certain to make Management Studio crawl as it renders five thousand execution plans.
Alternatively, we could cache all of the data in a temp table first, and then pull it row-by-row. This would result in significantly fewer reads on the underlying sales data, outperforming cursors by a mile, but would still involve iterating through the temp table over and over. For the scenario of 5,000 rows, we’d still have an inefficient slog through a smaller data set, rather than crawling through lots of data. Regardless of method, it’s still navigating quicksand either way, with varying amounts of quicksand.
We can quickly illustrate this change as follows:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
DECLARE @Sales_Order_Id_List VARCHAR(MAX) = ''; DECLARE @Row_Count SMALLINT; DECLARE @Current_Row_ID SMALLINT = 1; CREATE TABLE #SalesOrderIDs (Row_ID SMALLINT NOT NULL IDENTITY(1,1) CONSTRAINT PK_SalesOrderIDs_Temp PRIMARY KEY CLUSTERED, SalesOrderID INT NOT NULL); INSERT INTO #SalesOrderIDs (SalesOrderID) SELECT SalesOrderID FROM Sales.SalesOrderHeader WHERE Status = 5 AND OrderDate BETWEEN '1/1/2014' AND '2/1/2014' AND TotalDue > 140000; SELECT @Row_Count = @@ROWCOUNT; WHILE @Current_Row_ID <= @Row_Count BEGIN SELECT @Sales_Order_Id_List = @Sales_Order_Id_List + CAST(SalesOrderID AS VARCHAR(MAX)) + ',' FROM #SalesOrderIDs WHERE Row_ID = @Current_Row_ID; SELECT @Current_Row_ID = @Current_Row_ID + 1; END SELECT @Sales_Order_Id_List = LEFT(@Sales_Order_Id_List, LEN(@Sales_Order_Id_List) - 1); SELECT @Sales_Order_Id_List AS Sales_Order_Id_List; DROP TABLE #SalesOrderIDs; |
The resulting performance is better in that we only touch SalesOrderHeader once, but then hammer the temp table over and over. STATISTICS IO reveals the following:

This is a bit better than before, but still ugly. The execution plan also looks better, but still far too many operations to be efficient:

An iteration is universally a bad approach here, and one that will not scale well past the first few iterations. If you are building a delimited list, it is worth taking the time to avoid iteration and consider any other method to build a string. Nearly anything is more efficient than this and certainly less scary!
XML String-Building
We can make some slick use of XML in order to build a string on-the-fly from the data retrieved in any query. While XML tends to be a CPU-intensive operation, this method allows us to gather the needed data for our delimited list without the need to loop through it over and over. One query, one execution plan, one set of reads. This is much easier to manage than what has been presented above. The syntax is a bit unusual, but will be explained below:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
DECLARE @Sales_Order_Id_List VARCHAR(MAX) = ''; SELECT @Sales_Order_Id_List = STUFF((SELECT ',' + CAST(SalesOrderID AS VARCHAR(MAX)) FROM Sales.SalesOrderHeader WHERE Status = 5 AND OrderDate BETWEEN '1/1/2014' AND '2/1/2014' AND TotalDue > 140000 FOR XML PATH(''), TYPE).value('.', 'VARCHAR(MAX)'), 1, 1, ''); SELECT @Sales_Order_Id_List AS Sales_Order_Id_List; |
In this script, we start with the list of SalesOrderID values as provided by the SELECT statement embedded in the middle of the query. From there, we add the FOR XML PATH(‘’) clause to the end of the query, just like this:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
DECLARE @Sales_Order_Id_List VARCHAR(MAX) = ''; SELECT @Sales_Order_Id_List = (SELECT ',' + CAST(SalesOrderID AS VARCHAR(MAX)) FROM Sales.SalesOrderHeader WHERE Status = 5 AND OrderDate BETWEEN '1/1/2014' AND '2/1/2014' AND TotalDue > 140000 FOR XML PATH('')); SELECT @Sales_Order_Id_List AS Sales_Order_Id_List; |
The result of this query is almost there—we get a comma-separated list, but one with two flaws:

The obvious problem is the extra comma at the start of the string. The less obvious problem is that the data type of the output is indeterminate and based upon the various components of the SELECT statement. To resolve the data type, we add the TYPE option to the XML statement. STUFF is used to surreptitiously omit the comma. The leading comma can also be removed using RIGHT, as follows:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
DECLARE @Sales_Order_Id_List VARCHAR(MAX) = ''; SELECT @Sales_Order_Id_List = (SELECT ',' + CAST(SalesOrderID AS VARCHAR(MAX)) FROM Sales.SalesOrderHeader WHERE Status = 5 AND OrderDate BETWEEN '1/1/2014' AND '2/1/2014' AND TotalDue > 140000 FOR XML PATH(''), TYPE).value('.', 'VARCHAR(MAX)'); SELECT @Sales_Order_Id_List = RIGHT(@Sales_Order_Id_List, LEN(@Sales_Order_Id_List) - 1); SELECT @Sales_Order_Id_List AS Sales_Order_Id_List; |
This is a bit easier to digest at least. So how does this XML-infused syntax perform? We benefit greatly from doing everything in a single TSQL statement, and the resulting STATISTICS IO data and execution plan are as follows:


Well, that execution plan is a bit hard to read! Much of it revolves around the need to generate XML and then parse it, resulting in the desired comma-delimited list. While not terribly pretty, we are also done without the need to loop through an ID list or step through a cursor. Our reads are as low as they will get without adding any indexes to SalesOrderHeader to cover this query.
XML is a slick way to quickly generate a delimited list. It’s efficient on IO, but will typically result in high subtree costs and high CPU utilization. This is an improvement over iteration, but we can do better than this.
Set-Based String Building
There exists a better option for building strings (regardless of how they are delimited or structured) that provides the best of both worlds: Low CPU consumption and low disk IO. A string can be built in a single operation by taking a string and building it out of columns, variables, and any static text you need to add. The syntax looks like this:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
DECLARE @Sales_Order_Id_List VARCHAR(MAX) = ''; SELECT @Sales_Order_Id_List = @Sales_Order_Id_List + CAST(SalesOrderID AS VARCHAR(MAX)) + ',' FROM Sales.SalesOrderHeader WHERE Status = 5 AND OrderDate BETWEEN '1/1/2014' AND '2/1/2014' AND TotalDue > 140000 SELECT @Sales_Order_Id_List = LEFT(@Sales_Order_Id_List, LEN(@Sales_Order_Id_List) - 1); SELECT @Sales_Order_Id_List; |
The start of this process is to start with a string and set it equal to some starting value. An empty string is used here, but anything could be inserted at the start of the string as a header, title, or starting point. We then SELECT the string equal to itself plus our tabular data plus any other string data we wish to add to it. The results are the same as our previous queries:
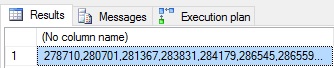
The SELECT statement is identical to what we would run if we were not building a string at all, except that we assign everything back to the list string declared above. Using this syntax, we can retrieve data by reading the table only as much as is needed to satisfy our query, and then build the string at the low cost of a COMPUTE SCALAR operator, which is typically SQL Server performing basic operations. In other words, no disk IO costs associated with it, and very minimal query cost/CPU/memory overhead.
As we can see, the execution plan and STATISTICS IO both are simpler and come out as an all-around win in terms of performance:


The resulting execution plan is almost as simple as if we did not have any string building involved, and there is no need for worktables or other temporary objects to manage our operations.
This string-building syntax is fun to play with and remarkably simple and performant. Whenever you need to build a string from any sort of tabular data, consider this approach. The same technique can be used for building backup statements, assembling index or other maintenance scripts, or building dynamic SQL scripts for future execution. It’s versatile and efficient, and therefore being familiar with it will benefit any database professional.
Parsing Delimited Data
The flip-side of what we demonstrated above is parsing and analyzing a delimited string. There exist many methods for pulling apart a comma-separated list, each of which has benefits and disadvantages to them. We’ll now look at a variety of methods and compare speed, resource consumption, and effectiveness.
To help illustrate performance, we’ll use a larger comma-delimited string in our demonstrations. This will exaggerate and emphasize the benefits or pitfalls of the performance that we glean from execution plans, IO stats, duration, and query cost. The methods above had some fairly obvious results, but what we experiment with below may be less obvious, and require larger lists to validate. The following query (very similar to above, but more inclusive) will be used to generate a comma-delimited list for us to parse:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
DECLARE @Sales_Order_Id_List VARCHAR(MAX) = ''; SELECT @Sales_Order_Id_List = @Sales_Order_Id_List + CAST(SalesOrderID AS VARCHAR(MAX)) + ',' FROM Sales.SalesOrderHeader WHERE Status = 5 AND OrderDate BETWEEN '1/1/2014' AND '2/1/2014' AND TotalDue > 50000 SELECT @Sales_Order_Id_List = LEFT(@Sales_Order_Id_List, LEN(@Sales_Order_Id_List) - 1); SELECT @Sales_Order_Id_List; |
This will yield 693 IDs in a list, which should provide a decent indicator of performance on a larger result set.
The Iterative Method
Once again, iteration is a method we can employ to take apart a delimited string. Our work above should already leave us skeptical as to its performance, but look around the SQL Server blogs and professional sites and you will see iteration used very often. It is easy to iterate through a string a deconstruct it, but we once again will need to evaluate
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
CREATE TABLE #Sales_Order_Id_Results (Sales_Order_Id INT NOT NULL); DECLARE @Sales_Order_Id_Current INT; WHILE @Sales_Order_Id_List LIKE '%,%' BEGIN SELECT @Sales_Order_Id_Current = LEFT(@Sales_Order_Id_List, CHARINDEX(',', @Sales_Order_Id_List) - 1); SELECT @Sales_Order_Id_List = RIGHT(@Sales_Order_Id_List, LEN(@Sales_Order_Id_List) - CHARINDEX(',', @Sales_Order_Id_List)); INSERT INTO #Sales_Order_Id_Results (Sales_Order_Id) SELECT @Sales_Order_Id_Current END INSERT INTO #Sales_Order_Id_Results (Sales_Order_Id) SELECT @Sales_Order_Id_List SELECT * FROM #Sales_Order_Id_Results; DROP TABLE #Sales_Order_Id_Results; |
This query takes the string and pulls out each ID from the left, one at a time, and then inserting it into the temp table we created at the top. The final insert grabs the last remaining ID that was left out of the loop. It takes quite a long time to run as it needs to loop 693 times in order to retrieve each value and add it to the temporary table. Our performance metrics show the repetitive nature of our work here:
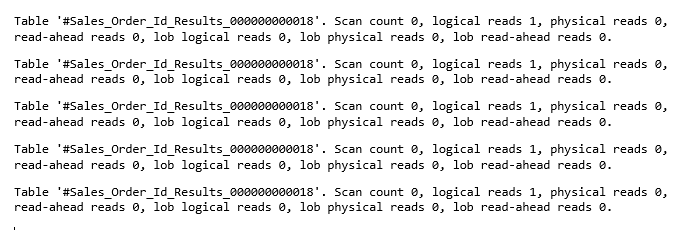
This shows the first 5 of 693 iterations. Each loop may only require a single read in order to insert a new value to the temp table, but repeating that hundreds of times is time consuming. The execution plan is similarly repetitive:

0% per loop is misleading as it’s only 1/693th of the total execution plan. Subtree costs, memory usage, CPU, cached plan size, etc…all are tiny, but when multiplied by 693, they become a bit more substantial:
693 Logical Reads
6.672 Query cost
6KB Data Written
10s Runtime (clean cache)
1s Runtime (subsequent executions)
An iterative approach has a linear runtime, that is for each ID we add to our list, the overall runtime and performance increases by whatever the costs are for a single iteration. This makes the results predictable, but inefficient.
XML
We can make use of XML again in order to convert a delimited string into XML and then output the parsed XML into our temp table. The benefits and drawbacks of using XML as described earlier all apply here. XML is relatively fast and convenient but makes for a messy execution plan and a bit more memory and CPU consumption along the way (as parsing XML isn’t free).
The basic method here is to convert the comma-separated list into XML, replacing commas with delimiting XML tags. Next, we parse the XML for each of the values delimited by those tags. From this point, the results go into our temp table and we are done. The TSQL to accomplish this is as follows:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
DECLARE @Sales_Order_idlist VARCHAR(MAX) = ''; SELECT @Sales_Order_idlist = @Sales_Order_idlist + CAST(SalesOrderID AS VARCHAR(MAX)) + ',' FROM Sales.SalesOrderHeader WHERE Status = 5 AND OrderDate BETWEEN '1/1/2014' AND '2/1/2014' AND TotalDue > 50000 SELECT @Sales_Order_idlist = LEFT(@Sales_Order_idlist, LEN(@Sales_Order_idlist) - 1); CREATE TABLE #Sales_Order_Id_Results (Sales_Order_Id INT NOT NULL); DECLARE @Sales_Order_idlist_XML XML = CONVERT(XML, '<Id>' + REPLACE(@Sales_Order_idlist, ',', '</Id><Id>') + '</Id>'); INSERT INTO #Sales_Order_Id_Results (Sales_Order_Id) SELECT Id.value('.', 'INT') AS Sales_Order_Id FROM @Sales_Order_idlist_XML.nodes('/Id') Sales_Order_idlist_XML(Id); SELECT * FROM #Sales_Order_Id_Results; DROP TABLE #Sales_Order_Id_Results; |
The results of this query are the same as the iterative method, and will be identical to those of any demos we do here:
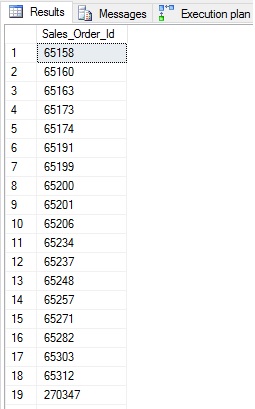
No surprises here, we get a list of 693 IDs that had been stored in the CSV we created earlier.
The performance metrics are as follows:


IO is about the same as earlier. Instead of paying that cost one-at-a-time, we do it all at once in order to load everything into the temporary table. The execution plan is more complex, but there is only one of them, which is quite nice!
696 Logical Reads
136.831 Query cost
6KB Data Written
1s Runtime (clean cache)
100ms Runtime (subsequent executions)
This is a big improvement. Let’s continue and review other methods of string-splitting.
STRING_SPLIT
Included in SQL Server 2016 is a long-requested function that will do all the work for you, and it’s called SPLIT_STRING(). The syntax is as simple as it gets, and will get us the desired results quickly:
|
1 2 3 4 5 6 7 8 9 10 11 |
CREATE TABLE #Sales_Order_Id_Results (Sales_Order_Id INT NOT NULL); INSERT INTO #Sales_Order_Id_Results (Sales_Order_Id) SELECT * FROM STRING_SPLIT(@Sales_Order_idlist, ','); SELECT * FROM #Sales_Order_Id_Results; DROP TABLE #Sales_Order_Id_Results; |
This is certainly the easiest way to split up a delimited list. How does performance look?


1396 Logical Reads
0.0233 Query cost
6KB Data Written
0.8s Runtime (clean cache)
90ms Runtime (subsequent executions)
Microsoft’s built-in function provides a solution that is convenient and appears to perform well. It isn’t faster than XML, but it clearly was written in a way that provides an easy-to-optimize execution plan. Logical reads are higher, as well. While we cannot look under the covers and see exactly how Microsoft implemented this function, we at least have the convenience of a function to split strings that are shipped with SQL Server. Note that the separator passed into this function must be of size 1. In other words, you cannot use STRING_SPLIT with a multi-character delimiter, such as ‘”,”’.
We can easily take any of our string-splitting algorithms and encapsulate them in a function, for convenience. This allows us to compare performance side-by-side for all of our techniques and compare performance. This also allows us to compare our solutions to STRING_SPLIT. I’ll include these metrics later in this article.
OPENJSON
Here is another new alternative that is available to us in SQL Server 2016. Our abuse of JSON parsing is similar to our use of XML parsing to get the desired results earlier. The syntax is a bit simpler, though there are requirements on how we delimit the text in that we must put each string in quotes prior to delimiting them. The entire set must be in square brackets.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
SELECT @Sales_Order_idlist = '["' + REPLACE(@Sales_Order_idlist, ',', '","') + '"]'; CREATE TABLE #Sales_Order_Id_Results (Sales_Order_Id INT NOT NULL); INSERT INTO #Sales_Order_Id_Results (Sales_Order_Id) SELECT value FROM OPENJSON(@Sales_Order_idlist) SELECT * FROM #Sales_Order_Id_Results; DROP TABLE #Sales_Order_Id_Results; |
Our first SELECT formats our string to conform to the expected syntax that OPENJSON expects. From there, our use of this operator is similar to how we used STRING_SPLIT to parse our delimited list. Since the output table contains 3 columns (key, value, and type), we do need to specify the value column name when pulling data from the output.
How does performance look for this unusual approach?


2088 Logical Reads
0.0233 Query cost
6KB Data Written
1s Runtime (clean cache)
40ms Runtime (subsequent executions)
This method of list-parsing took more reads than our last few methods, but the query cost is the same as if it were any other SQL Server function, and the runtime on all subsequent runs was the fastest yet (as low as 22ms, and as high as 50ms). It will be interesting to see how this scales from small lists to larger lists, and if it is a sneaky way to parse lists, or if there are hidden downsides that we will discover later on.
Recursive CTE
Recursion can be used to do a pseudo-set-based parse of a delimited list. We are limited by SQL Server’s recursion limit of 32,767, though I do sincerely hope that we don’t need to parse any lists longer than that!
In order to build our recursive solution, we begin by creating an anchor SELECT statement that pulls the location of the first delimiter in the TSQL, as well as a placeholder for the starting position. To make this TSQL a bit more reusable, I’ve included a @Delimiter variable, instead of hard-coding a comma.
The second portion of the CTE returns the starting position of the next element in the list and the end of that element. An additional WHERE clause removes edge cases that would result in infinite recursion, namely the first and last elements in the list, which we only want/need to process a single time.
The following TSQL illustrates this implementation:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
CREATE TABLE #Sales_Order_Id_Results (Sales_Order_Id INT NOT NULL); IF @Sales_Order_idlist LIKE '%' + @Delimiter + '%' BEGIN WITH CTE_CSV_SPLIT AS ( SELECT CAST(1 AS INT) AS Data_Element_Start_Position, CAST(CHARINDEX(@Delimiter, @Sales_Order_idlist) - 1 AS INT) AS Data_Element_End_Position UNION ALL SELECT CAST(CTE_CSV_SPLIT.Data_Element_End_Position AS INT) + LEN(@Delimiter), CASE WHEN CAST(CHARINDEX(@Delimiter, @Sales_Order_idlist, CTE_CSV_SPLIT.Data_Element_End_Position + LEN(@Delimiter) + 1) AS INT) <> 0 THEN CAST(CHARINDEX(@Delimiter, @Sales_Order_idlist, CTE_CSV_SPLIT.Data_Element_End_Position + LEN(@Delimiter) + 1) AS INT) ELSE CAST(LEN(@Sales_Order_idlist) AS INT) END AS Data_Element_End_Position FROM CTE_CSV_SPLIT WHERE (CTE_CSV_SPLIT.Data_Element_Start_Position > 0 AND CTE_CSV_SPLIT.Data_Element_End_Position > 0 AND CTE_CSV_SPLIT.Data_Element_End_Position < LEN(@Sales_Order_idlist))) INSERT INTO #Sales_Order_Id_Results (Sales_Order_Id) SELECT REPLACE(SUBSTRING(@Sales_Order_idlist, Data_Element_Start_Position, Data_Element_End_Position - Data_Element_Start_Position + LEN(@Delimiter)), @Delimiter, '') AS Column_Data FROM CTE_CSV_SPLIT OPTION (MAXRECURSION 32767); END ELSE BEGIN INSERT INTO #Sales_Order_Id_Results (Sales_Order_Id) SELECT @Sales_Order_idlist AS Column_Data; END SELECT * FROM #Sales_Order_Id_Results; DROP TABLE #Sales_Order_Id_Results; |
This is definitely a more complex query, which leads us to ask if recursion is an efficient way to parse a delimited list. The following are the metrics for this approach for our current example list:

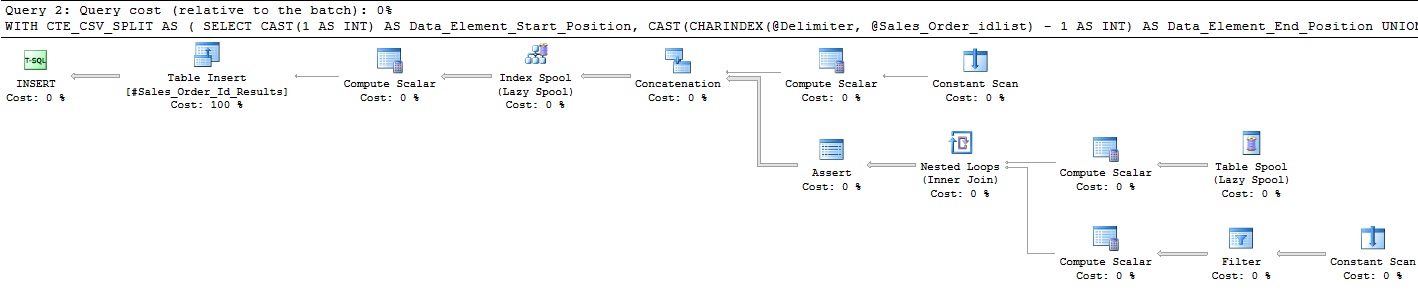
4853 Logical Reads
0.01002 Query cost
6KB Data Written
800ms Runtime (clean cache)
30ms Runtime (subsequent executions)
These are interesting metrics. More reads are necessary to support the worktable required by the recursive CTE, but all other metrics look to be an improvement. In addition to having a surprisingly low query cost, the runtime was very fast when compared to our previous parsing methods. I’d guess the execution plan is low-cost as there are only a small number of ways to optimize it when compared to other queries. Regardless of this academic guess, we have (so far) a winner for the most performant option.
At the end of this study, we’ll provide performance metrics for each method of string parsing for a variety of data sizes, which will help determine if some methods are superior for shorter or longer delimited lists, different data types, or more complex delimiters.
Tally Table
In a somewhat similar fashion to the recursive CTE, we can mimic a set-based list-parsing algorithm by joining against a tally table. The begin this exercise in TSQL insanity, let’s create a tally table containing an ordered set of numbers. To make an easy comparison, we’ll make the number of rows equal to the maximum recursion allowed by a recursive CTE:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
CREATE TABLE dbo.Tally ( Tally_Number INT); GO SET STATISTICS IO OFF; SET STATISTICS TIME OFF; GO DECLARE @count INT = 1; WHILE @count <= 32767 BEGIN INSERT INTO dbo.Tally (Tally_Number) SELECT @count; SELECT @count = @count + 1; END GO SET STATISTICS IO ON; SET STATISTICS TIME ON; |
This populates 32767 rows into Tally, which will serve as the pseudo-anchor for our next CTE solution:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
CREATE TABLE #Sales_Order_Id_Results (Sales_Order_Id INT NOT NULL); SELECT @Sales_Order_idlist = LEFT(@Sales_Order_idlist, LEN(@Sales_Order_idlist) - 1); DECLARE @List_Length INT = DATALENGTH(@Sales_Order_idlist); WITH CTE_TALLY AS ( SELECT TOP (@List_Length) ROW_NUMBER() OVER (ORDER BY (SELECT 1)) AS Tally_Number FROM dbo.Tally), CTE_STARTING_POINT AS ( SELECT 1 AS Tally_Start UNION ALL SELECT Tally.Tally_Number + 1 AS Tally_Start FROM dbo.Tally WHERE SUBSTRING(@Sales_Order_idlist, Tally.Tally_Number, LEN(@Delimiter)) = @Delimiter), CTE_ENDING_POINT AS ( SELECT CTE_STARTING_POINT.Tally_Start, CHARINDEX(@Delimiter, @Sales_Order_idlist, CTE_STARTING_POINT.Tally_Start) - CTE_STARTING_POINT.Tally_Start AS Element_Length, CASE WHEN CHARINDEX(@Delimiter, @Sales_Order_idlist, CTE_STARTING_POINT.Tally_Start) IS NULL THEN 0 ELSE CHARINDEX(@Delimiter, @Sales_Order_idlist, CTE_STARTING_POINT.Tally_Start) END - ISNULL(CTE_STARTING_POINT.Tally_Start, 0) AS Tally_End FROM CTE_STARTING_POINT) INSERT INTO #Sales_Order_Id_Results (Sales_Order_Id) SELECT CASE WHEN Element_Length > 0 THEN SUBSTRING(@Sales_Order_idlist, CTE_ENDING_POINT.Tally_Start, CTE_ENDING_POINT.Element_Length) ELSE SUBSTRING(@Sales_Order_idlist, CTE_ENDING_POINT.Tally_Start, @List_Length - CTE_ENDING_POINT.Tally_Start + 1) END AS Sales_Order_Id FROM CTE_ENDING_POINT; SELECT * FROM #Sales_Order_Id_Results; DROP TABLE #Sales_Order_Id_Results; |
This set of CTEs performs the following actions:
Builds a CTE with numbers from the tally table, counting only up to the total data length of our list.
Build a CTE set of starting points that indicate where each list element starts.
Build a CTE set of ending points that indicate where each list element ends and the length of each.
Perform arithmetic on those numbers to determine the contents of each list element.
The CASE statement near the end handles the single edge case for the last element in the list, which would otherwise return a negative number for the end position. Since we know the length of the overall list, there’s no need for this calculation anyway.
Here are the performance metrics for this awkward approach to delimited list-splitting:

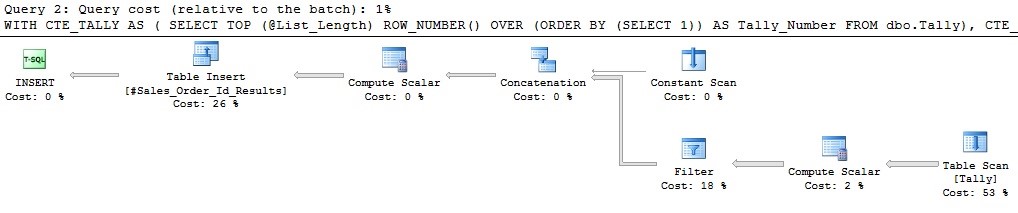
The bulk of reads on this operation comes from the scan on Tally. The execution plan is surprisingly simple for TSQL that appears even more complex than the recursive CTE. How do the remaining metrics stack up?
58 Logical Reads
0.13915 Query cost
6KB Data Written
1s Runtime (clean cache)
40ms Runtime (subsequent executions)
While the query cost is evaluated as higher, all other metrics look quite good. The runtime is not better than recursion in this case but is very close to being as fast. The bulk of speed of this operation comes from the fact that everything can be evaluated in-memory. The only logical reads necessary are to the tally table, after which SQL Server can crunch the remaining arithmetic quickly and efficiently as any computer is able to.
Performance Comparison
In an effort to provide more in-depth performance analysis, I’ve rerun the tests from above on a variety of list lengths and combinations of data types. The following are the tests performed:
List of 10 elements, single-character delimiter. List is VARCHAR(100).
List of 10 elements, single-character delimiter. List is VARCHAR(MAX).
List of 500 elements, single-character delimiter. List is VARCHAR(5000).
List of 500 elements, single-character delimiter. List is VARCHAR(MAX).
List of 10000 elements, single-character delimiter. List is VARCHAR(MAX).
List of 10 elements, 3-character delimiter. List is VARCHAR(100).
List of 10 elements, 3-character delimiter. List is VARCHAR(MAX).
List of 500 elements, 3-character delimiter. List is VARCHAR(5000).
List of 500 elements, 3-character delimiter. List is VARCHAR(MAX).
List of 10000 elements, 3-character delimiter. List is VARCHAR(MAX).
The results are attached in an Excel document, including reads, query cost, and average runtime (no cache clear). Note that execution plans were turned off when testing duration, in order to prevent their display from interfering with timing. Duration is calculated as an average of 10 trials after the first (ensuring the cache is no longer empty). Lastly, the temporary table was omitted for all methods where it wasn’t needed, to prevent IO noise writing to it. The only one that requires it is the iteration, as it’s necessary to write to the temp table on each iteration in order to save results.
The numbers reveal that the use of XML, JSON, and STRING_SPLIT consistently outperform other methods. Oftentimes, the metrics for STRING_SPLIT are almost identical to the JSON approach, including the query cost. While the innards of STRING_SPLIT are not exposed to the end user, this leads me to believe that some string-parsing method such as this was used as the basis for building SQL Server’s newest string function. The execution plan is nearly identical as well.
There are times where CTEs perform well but under a variety of conditions, such as when a VARCHAR(MAX) is used, or when the delimiter becomes larger than 1 character, performance falls behind other methods. As noted earlier, if you would like to use a delimiter longer than 1 character, STRING_SPLIT will not be of help. As such, trials with 3-character delimiters were not run for this function.
Duration is ultimately the true test for me here, and I weighted it heavily in my judgment. If I can parse a list in 10ms versus 100ms, then a few extra reads or bits of CPU/memory use is of little concern to me. It is worth noting that there is some significance to methods that require no disk IO. CTE methods require worktables, which reside in TempDB and equate to disk IO when needed. XML, JSON, and STRING_SPLIT occur in memory and therefore require no interaction with TempDB.
As expected, the iterative method of string parsing is the ugliest, requiring IO to build a table, and plenty of time to crawl through the string. This latency is most pronounced when a longer list is parsed.
Conclusion
There are many ways to build and parse delimited lists. While some are more or less creative than others, there are some definitive winners when it comes to performance. STRING_SPLIT performs quite well—kudos to Microsoft for adding this useful function and tuning it adequately. JSON and XML parsing, though, also perform adequately—sometimes better than STRING_SPLIT. Since the query cost & CPU consumption of XML are consistently less than the other 2 methods mentioned here, I’d recommend either JSON or STRING_SPLIT over the others. If a delimiter longer than 1 character is required, then STRING_SPLIT is eliminated as longer delimiters are not allowed for the separator parameter. The built-in nature of STRING_SPLIT is handy but leaves absolutely no room for customization.
There are other ways to parse lists that are not presented here. If you have one and believe it can outperform everything here, let me know and I’ll run it through a variety of tests to see where it falls.
References and Further Reading
Many of these methods I’ve been playing with for years, while others are brand new in SQL Server 2016. Some have been explored in other blogs or Microsoft documentation, and for any that have seen attention elsewhere, I’ve made it a point to get creative and find newer, simpler, or more performant ways to manage them. Here are some references for the built-in functions used:
Documentation on OPENJSON:
Information on XML, both for parsing and list building:
Documentation on the new STRING_SPLIT function:
- STRING_SPLIT (Transact-SQL)
- Dynamic SQL: Applications, Performance, and Security
Also, my book, Dynamic SQL: Applications, Performance, and Security has a chapter that delves into list-building and provides significantly more detail and script options than was presented here:

In his free time, Ed enjoys video games, sci-fi & fantasy, traveling, and being as big of a geek as his friends will tolerate.
View all posts by Ed Pollack
- SQL Server Database Metrics - October 2, 2019
- Using SQL Server Database Metrics to Predict Application Problems - September 27, 2019
- SQL Injection: Detection and prevention - August 30, 2019