
Summary
There is a multitude of database metrics that we can collect and use to help us understand database and server resource consumption, as well as overall usage.
This data can include hardware statistics, such as measures of CPU or memory consumed over time. We can also examine database metadata, including row counts, waits, and deadlocks.
At face value, this information can be useful in capacity planning and alerting when a server is low on resources. Our goal in this article an in Using Database Metrics to Predict Application Problems article will be to collect a handful of useful database metrics and then demonstrate how we can use them to benefit app development, troubleshooting, and bug hunting!
What Database Metrics Do We Monitor?
There is a multitude of database metrics we can monitor that will provide insight into how our server and data are being managed. Some are more useful than others and for different applications, some metrics may be more applicable than others.
Row Counts
For any data-driven application, row counts are likely one of the easiest and most effective database metrics to follow. They provide direct insight into the volume of data associated with an entity and can easily be trended over time.
For example, consider a table that tracks sales metrics where we typically see about 10k rows per day (each of which corresponds to a specific product sale). If we happen to notice one day that there are only 100 new rows in the table, or perhaps 10 million, we would have cause to investigate. Maybe it’s possible that a holiday or major data import project occurred, but excluding those special circumstances, we would move forward under the assumption that something is wrong and requires our attention.
In general, we can quantify a liberal range of values as to what normal and abnormal are. If determining absolute row counts is challenging, we can operate on percentages and say that any data growth over or under a range of percentages is abnormal. We can also choose to do both and cover both scenarios: High/low point-in-time data creation and high/low rates of increase over time.
Row counts only help us track insertions and deletions, though, and do not provide insight into updates or reads. If there is a process that is updating far more rows than necessary, then row counts will do little to help, unless we happen to audit these operations. Similarly, an app that is reading data inefficiently will not impact row counts via excessive SELECT statements.
Database File IO
Measuring IO metrics against database files provides a unique insight into how much data is being written and read by any given data file. This allows us to separate between activity against data and log files, as well as between different data files in a database that happens to have multiple data files.
This metric can help us pinpoint the general problem, though it will not tell us a specific table or code to investigate. This is still beneficial, though, as we can greatly narrow down a problem over time. In addition, this can help us measure overall database disk activity and trend it over time. By knowing these numbers, we can predict future data throughput and ensure that our hardware, storage, and network infrastructure can handle it in the future as the application grows.
Transaction Log Backup Size
We can also measure database change over time via the transaction logs. For any database in the FULL (or bulk-logged) recovery mode, all logged changes will result in log growth that is roughly proportional to the amount of change incurred.
If a database has log backup files taken hourly that are roughly 1GB in size, then we know that a transaction log backup size of 1TB would be anomalous and worth investigating.
This provides us another monitoring angle as we can analyze database metrics about database backups either via SQL Server metadata or via the files on disk. If transaction log backups are unusually high or low, then we know that database write activity is unusually high or low. This may correspond to a planned maintenance event and be expected, but it may also be the result of a runaway process, broken component, or some other problem that needs investigation.
Blocking/Waits
When queries take a long time to execute, either because they are slow or because they are waiting for other processes to complete, we may identify an app problem that requires attention.
Waits can be easily snapshotted and monitored at any point in time and repeated regularly. We can then look for long-running waits that exceed what we believe to be normal or crunch our data to trend over time any processes that get significantly slower and require attention.
Alternatively, wait stats can provide a useful research mechanism when an issue is identified via other means and further investigation is required. Wait stats can be associated with SPID, query text, execution plan XML, and more, allowing us to collect quite a bit of detail on what became slow and why.
Tracking Database Metrics
The remainder of this article will focus on details: How do we collect and track these metrics? The goal will be to keep the queries simple and applicable to the largest audience possible so that the most value can be gained from them.
Row Counts
There are multiple ways to collect row counts, and the method you choose should be based on data size and how accurate you need the data to be. The simplest way to get a row count from a table is as follows:
|
1 2 3 |
SELECT COUNT(*) FROM sales.SalesOrderDetail; |
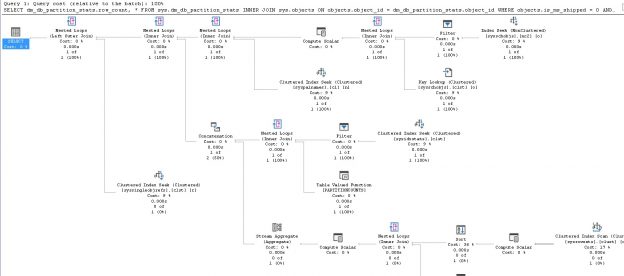
This method is quick & dirty, but requires an index scan of the clustered index to execute. This can be slow and resource-intensive for a large table. While the results are guaranteed to be accurate and return an exact row count, executing a COUNT against a table with millions or billions of rows will be painful and not worth the effort. The following shows the IO stats and execution plan for this operation:

This clearly is not scalable for any large data set and we should steer clear of using COUNT(*) unless we can apply a very limiting WHERE clause against it.
Another way to collect row count metrics is to query the view sys.sm_db_partition_stats:
|
1 2 3 4 5 6 7 8 9 |
SELECT dm_db_partition_stats.row_count FROM sys.dm_db_partition_stats INNER JOIN sys.objects ON objects.object_id = dm_db_partition_stats.object_id WHERE objects.is_ms_shipped = 0 AND objects.type_desc = 'USER_TABLE' AND objects.name = 'SalesOrderDetail' AND dm_db_partition_stats.index_id IN (0,1); |
This is a far more efficient method of collecting row counts. Besides, the view contains a variety of other useful database metrics, such as page counts, reserved vs. used pages, and in-row vs. overflow data. It is critical to note that these data points are approximations based on data in memory from underlying system tables. If you require precise row counts, do not use this view! For our purposes, though, we will often be looking for an order of magnitude of growth. For example, the difference between 1,000,000 rows and 999,975 is trivial for measuring overall growth metrics.
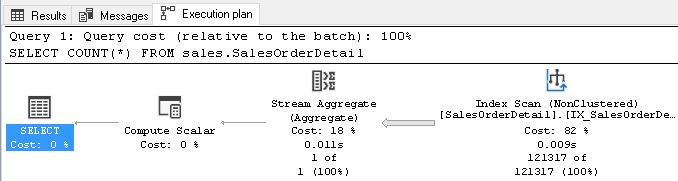
Here is the IO stats and execution plan for the above query:
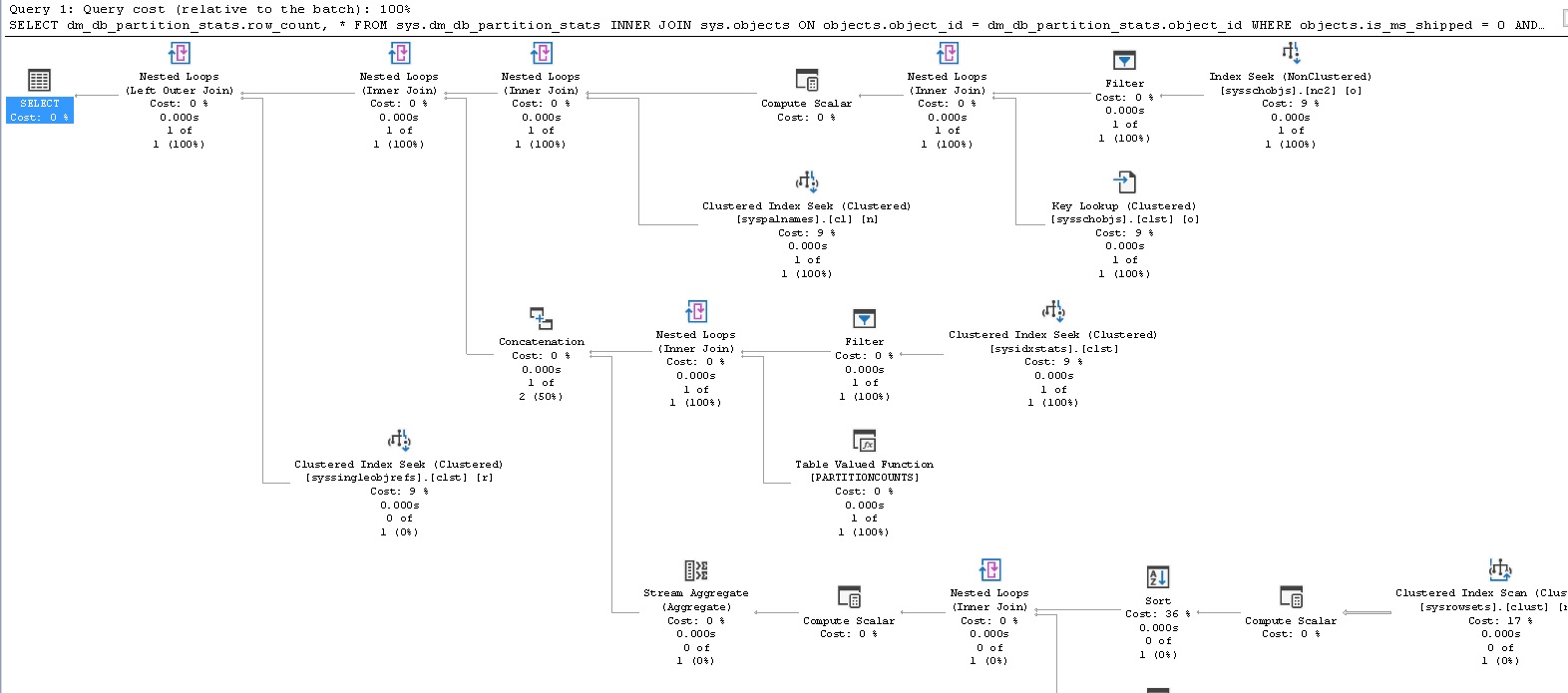
We can see that while the execution plan is far more complex, we need only read smaller system tables to get the data we need. As a result, reads are a fraction of what they were previously. More importantly, as our table grows, performance will not get worse! Using this system view also provides the bonus of being able to quickly save all row counts to a database metrics table directly from this query, without the need to iterate through tables using a loop or dynamic SQL:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
SELECT schemas.name AS SchemaName, objects.name AS TableName, CASE WHEN dm_db_partition_stats.index_id = 1 THEN 'Clustered Index' ELSE 'Heap' END AS TableType, dm_db_partition_stats.row_count FROM sys.dm_db_partition_stats INNER JOIN sys.objects ON objects.object_id = dm_db_partition_stats.object_id INNER JOIN sys.schemas ON schemas.schema_id = objects.schema_id WHERE objects.is_ms_shipped = 0 AND objects.type_desc = 'USER_TABLE' AND dm_db_partition_stats.index_id IN (0,1); |
This query returns row counts for all tables in a database, along with the schema name, table name, and whether it is a heap or not.
Another way to get row counts can be to rely on timestamps within the table. If there is a create time or last modified time column that is indexed, we can query against it on a regular basis, getting a count of rows since the last time we checked. This is a great way to get an accurate count without having to read an entire table repeated.
The function APPROX_COUNT_DISTINCT can also be a useful tool as it can pull a distinct count of values for a column much faster than COUNT. This function is also an approximation, and is guaranteed to return a count that is at least 97% accurate. We can observe its accuracy by placing it in a query alongside COUNT:
|
1 2 3 4 |
SELECT COUNT(DISTINCT SalesOrderDetailID) AS actual_count, APPROX_COUNT_DISTINCT(SalesOrderDetailID) AS approximate_count FROM sales.salesorderdetail; |
The results show counts that are more than close enough for our purposes:
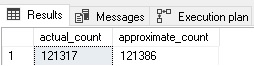
Lastly, if a table has any sort of auditing, tracking, or logging against it, then we can interrogate the log for details, rather than the table itself. If you are already going to the trouble of auditing a table’s activity, then there is no downside to leveraging that data for our own metrics-gathering purposes.
Once we have row counts collected and available over a period of time, we can compare past values to present values and measure metrics of note, such as:
- Has a table grown by more than 10% in the past N days?
- Has a table grown by more than 2% for more than N days straight?
- Has a table not grown at all in more than N days?
- Has a table shrunk by more than 10%?
- Is a table’s row count approaching the maximum allowed by its primary key data type?
These and many more questions can be answered by collecting row count metrics and then automating a script against them daily that inspects recent data for any changes that are significant enough to alert on.
Database File IO
Knowing how much data is being written to each database file can help isolate and quantify the overall database write activity. It can also be used to pinpoint a specific database or file where the activity is significantly higher than normal.
File IO is tracked in the dynamic management view sys.dm_io_virtual_file_stats. This handy view provides database metrics for the number of reads and writes against a database file, as well as a variety of other useful details. One important note: This view is reset when SQL Server restarts! As a result, this data must be captured regularly and saved in order for it to be meaningful. Collecting this data hourly is a typical application of it, though more or less frequent polling may be desirable in different applications. All database metrics stored in this view are cumulative and tell us the total reads or total writes since the SQL Server service last started.
To gather this data, we can query the view and join it to sys.master_files, which provides details about the file itself, and sys.databases to get the name of the database that the file belongs to.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
SELECT databases.name AS DatabaseName, master_files.name AS DatabaseFileName, master_files.type_desc AS FileType, master_files.physical_name, dm_io_virtual_file_stats.num_of_reads, dm_io_virtual_file_stats.num_of_bytes_read, dm_io_virtual_file_stats.num_of_writes, dm_io_virtual_file_stats.num_of_bytes_written, dm_io_virtual_file_stats.size_on_disk_bytes FROM sys.master_files INNER JOIN sys.dm_io_virtual_file_stats(NULL, NULL) ON master_files.database_id = dm_io_virtual_file_stats.database_id INNER JOIN sys.databases ON databases.database_id = master_files.database_id AND master_files.file_id = dm_io_virtual_file_stats.file_id; |
The results of this query are as follows:
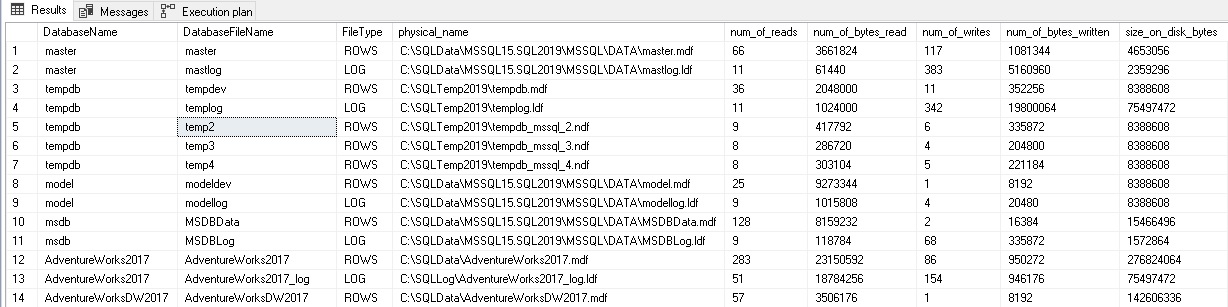
This tells us the database, file, and how much data has been written and read against each file. If we run the query again, the numbers will have increased by however much additional IO activity has taken place since our initial run:
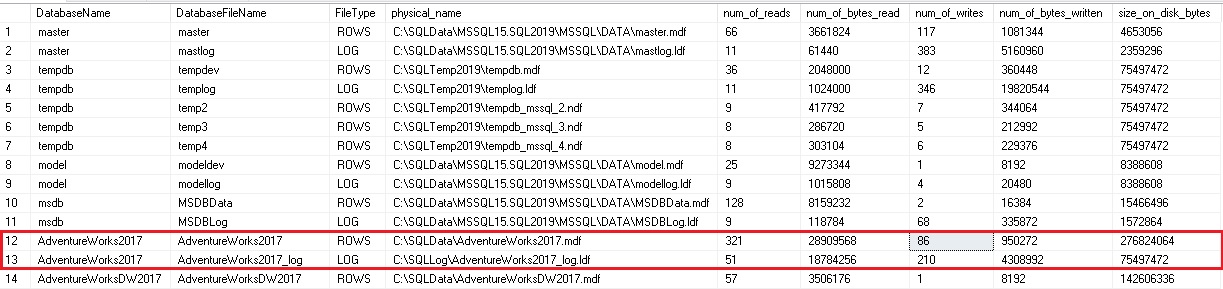
Note that numbers have gone up in AdventureWorks2017, as well as the master database. Since this query pulls data for all databases and files on a SQL Server, we can collect it quite quickly and easily, with little impact on the server via this operation.
Once we have IO file stats, we can answer questions like these:
- Are there more reads or writes against a database than we would expect?
- Are the reads or writes significantly high for a file given its size?
- Have reads or writes increased dramatically over time?
- Are reads or writes far higher at a specific time of the day? If so, can we correlate those database metrics to a job, app, or process that may be causing it?
- Is the total IO approaching the limits of the storage system?
These questions (and more) allow us to get ahead of potential IO-related problems, isolate them, and investigate further. We can determine what database or file is overconsuming storage bandwidth and use the timing of the data to track down what process is responsible for excessive resource consumption. Similarly, excessively low usage can also be indicative of an application problem where actions are not taking place, but should be.
Transaction Log Backup Size
Whenever a write operation completes, the details of that operation are logged by the transaction log. Checkpoints are issued periodically that commit that data to the physical transaction log from memory. When a transaction log backup is taken, all data in the transaction log will be committed to the database files and all transactions prior to the backup removed from the log.
The result of this process is that the transaction log backups will be sized to roughly reflect the amount of database activity that generated them. A small transaction log backup is indicative of less database activity than a large backup. There are a variety of outliers and exceptions to this guideline, such as minimally logged transactions, but those exceptions have little bearing on our conversation here.
We have two options available for measuring transaction log backup sizes:
- Track backup sizes using Powershell or tool/service that collects and records file sizes
- Use data in MSDB to track backup file sizes
For our purposes, the second option is more convenient as it uses built-in SQL Server features and is therefore readily accessible and free. It is limited by our retention policy for MSDB backup data. A SQL server should always have a retention policy that cleans up data older than N days from MSDB’s logs to ensure that the database does not get bloated over time. That being said, it’s unlikely that a server will retain less than a day of data. We can pull this backup history data and join it to some of the data we have already worked with to paint a clear picture of backup activity:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
SELECT backupset.database_name, CAST(8.0 * master_files.size/1024.0 AS DECIMAL(18, 0)) AS database_file_size_in_MB, CAST(backupset.backup_size/1024.0/1024.0 AS DECIMAL(18, 2)) AS BackupSizeMB, CAST(backupset.compressed_backup_size/1024.0/1024.0 AS DECIMAL(18, 2)) AS CompressedSizeMB, backupset.backup_start_date AS BackupStartDate, backupset.backup_finish_date AS BackupEndDate, CAST(backupset.backup_finish_date - backupset.backup_start_date AS TIME) AS AmtTimeToBkup, backupmediafamily.physical_device_name AS BackupDeviceName FROM msdb.dbo.backupset INNER JOIN msdb.dbo.backupmediafamily ON backupset.media_set_id = backupmediafamily.media_set_id INNER JOIN sys.databases ON databases.name = backupset.database_name INNER JOIN sys.master_files ON master_files.database_id = databases.database_id AND master_files.type_desc = 'ROWS' WHERE backupset.type = 'L'; |
On my local server, this query returns 3 results, indicating that 3 transaction log backups have been taken since the last MSDB cleanup occurred:

By adding in the database size, we can better measure how large or small the transaction log backup really is. If we save and trend this data over time, then we can better understand how backup sizes change as app activity varies. In the example data above, none of the backups appear to be too large. If a transaction log backup for AdventureWorksDW2017 was 5GB, though, I’d be concerned as this is almost 5000 times larger than the database itself. For a log backup to be so large would indicate significantly more data changed than exists in the database. This can be true if the database contains a significant amount of rolling log data, but for most standard OLTP/OLAP tables, a log backup that is that much larger than the data would be unusual.
The analytics that we can run based on transaction log backup sizes are similar to, and help justify what we see in IO file stats data. If writes are high and the transaction log increased significantly in size during a given time, then we have a good reason to dig further and find out what is causing so much IO, and is it normal?
One example of a common cause of this can be no-op churn. An app regularly updates data when changes are detected by a stored procedure or process, but accidentally always updates the data, regardless of whether a change has occurred or not. Updating a column and setting it equal to its existing value will result in transaction log growth, as odd as it may sound. This is important as a no-op update is still a transaction and its execution needs to be recorded in the transaction log for completeness’ sake, even if the resulting data is the same as its initial values.
Saving and monitoring transaction log backup sizes can help catch app issues that stem from writing too much data, whether it be because of flawed code or inefficient TSQL.
Blocking/Waits
Additional database metrics that can be especially helpful when researching performance or app problems are blocking and waits. Knowing when queries are running slow or have become slower with time is a great way to locate with a high level of certainty the TSQL that may be responsible for any number of performance or app-related problems. Many tools also do this work, as well. If you happen to use a third-party tool to track waits, blocking, and other poorly performing queries, then you need only attach monitoring to that tool and you are done! The following query will return all waits on a SQL Server, with the only filter to remove system processes from the results:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
SELECT @@SERVERNAME AS server_name, GETDATE() AS local_time, dm_exec_requests.session_id, dm_exec_requests.blocking_session_id, databases.name AS database_name, dm_exec_requests.wait_time, dm_exec_requests.wait_resource, dm_exec_requests.wait_type, dm_exec_sessions.host_name, dm_exec_sessions.program_name, dm_exec_sessions.login_name, dm_exec_requests.command, CASE WHEN dm_exec_sql_text.text LIKE '%CREATE PROCEDURE%' THEN '/* PROC: */ ' + SUBSTRING(dm_exec_sql_text.text, CHARINDEX('CREATE PROCEDURE ', dm_exec_sql_text.text) + 17, 60) + ' ... ' ELSE SUBSTRING(dm_exec_sql_text.text, 1, 60) + ' ...' END AS Begin_SQL, CASE WHEN dm_exec_sql_text.text LIKE '%CREATE PROCEDURE%' THEN '/* PROC - SEE SOURCE CODE */' ELSE RTRIM(dm_exec_sql_text.text) END AS Script_Text, SUBSTRING(dm_exec_sql_text.text, (dm_exec_requests.statement_start_offset/2) + 1, ((CASE dm_exec_requests.statement_end_offset WHEN -1 THEN DATALENGTH(dm_exec_sql_text.text) ELSE dm_exec_requests.statement_end_offset END - dm_exec_requests.statement_start_offset)/2) + 1) AS Wait_SQL, CONVERT(VARCHAR(MAX), Query_Hash, 1) AS Query_Hash, CASE WHEN dm_exec_sql_text.text IS NULL THEN NULL ELSE CHECKSUM(dm_exec_sql_text.text) END AS Checksum_Text_Hash FROM master.sys.dm_exec_requests INNER JOIN master.sys.dm_exec_sessions ON dm_exec_requests.session_id = dm_exec_sessions.session_id OUTER APPLY master.sys.dm_exec_sql_text(dm_exec_requests.sql_handle) INNER JOIN sys.databases ON databases.database_id = dm_exec_requests.database_id WHERE dm_exec_sessions.is_user_process = 1 -- Only check user processes |
This query essentially pulls and organizes data on all current requests, joining them to their originating sessions, the SQL text for the request, and the databases the query is running against. For my local server, I can observe two rows in the result set. One is my current session and the other some queries I am executing against my baseball stats database:
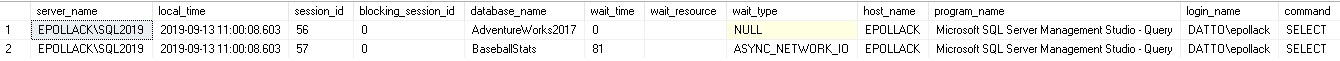
A ton of data is returned, so much so that I had to cut off the results here. Included are metrics about the TSQL that is waiting, what is blocking it (if anything), the person running the query, the wait type, and much more! On a busy server, this list could become very long. As such, we’d benefit from adding some filters:
- Dm_exec_requests.wait_time: We probably only care about waits that are greater than a certain time. Maybe 1 second, 10 seconds, a minute, or more. That value depends on your server and the type of queries that run on it
- Dm_exec_requests.status: Filtering out status = ‘background’ probably makes sense here to remove any internal processes that you likely are not interested in
- Databases.name: You may only care about certain databases or wish to remove system databases. Filter this column to remove master, model, msdb, and tempdb, which are likely databases you are not interested in tracking
- Dm_exec_requests.last_wait_type: Filter to remove wait types that you either are not interested in or already track via other means
- Dm_exec_requests.command: This can be filtered to remove backups or other processes that you might not be interested in
This data can get large, so you’ll want to consider a few options to ensure that it does not become too big:
- Save only N days of data. Odds are wait stats older than a few weeks or months are not of much use to you anymore. If they are, consider offloading them to an archive table
- Compress any tables that these database metrics are stored in. There is a ton of text included and it will compress quite nicely
- Truncate SQL text. If seeing the first 1000 characters of a TSQL statement is enough to figure out where it is coming from, then you can truncate SQL text within this query to 1000 characters and eliminate the possibility that an extra-ugly query will regurgitate some 50,000 character SQL text
- If you are only interested in a specific application or user, you can filter on it via the columns host_name or login_name in dm_exec_sessions. This can help remove noise from the results so that only what we need to see for a given application is saved. Alternatively, we could save everything and create views to help filter the data per application for us, if needed. That won’t save any space, but it would be convenient
Waits data is what can ultimately tell us the culprit when faced with an app performance problem. More importantly, we can proactively monitor this data and alert on any wait time that is too high (based on the standards or baselines for your application). This may allow you to identify latency that has yet to manifest as a bug or outage. Once identified, it can be fixed without the need for an emergency, which will make any operations team smile!
Conclusion
A variety of database metrics and ideas were provided in this article. This is only the beginning, though! Depending on your application and database environments, you may have many other data points to add in. If you use AlwaysOn availability groups or replication, then tracking latency between primary and secondary servers would be very important in alerting on excessive latency. Once discovered, that latency could be traced to wait stats, IO, or other metrics that allow you to find the offending process.
Once we are tracking these database metrics, we can monitor, alert, trend, and crunch them to gain further insights. In the second part of this article, we will take what we have learned and apply it to answer more complex problems and make predictions that traditionally are not made using them!

In his free time, Ed enjoys video games, sci-fi & fantasy, traveling, and being as big of a geek as his friends will tolerate.
View all posts by Ed Pollack
- SQL Server Database Metrics - October 2, 2019
- Using SQL Server Database Metrics to Predict Application Problems - September 27, 2019
- SQL Injection: Detection and prevention - August 30, 2019