
Introduction
In a typical OLTP environment, we want to maintain an acceptable level of data integrity. The easiest way to do this is through the use of foreign keys, which ensure that the values for a given column will always match that of a primary key in another table.
Over time, as the number of tables, columns, and foreign keys increase, the structure of that database can become unwieldy. A single table could easily link to thirty others, a table could have a parent-child relationship with itself, or a circular relationship could occur between a set of many tables.
A common request that comes up is to somehow report on, or modify a set of data in a given table. In a denormalized OLAP environment, this would be trivially easy, but in our OLTP scenario above, we could be dealing with many relationships, each of which needs to be considered prior to taking action. As DBAs, we are committed to maintaining large amounts of data, but need to ensure that our maintenance doesn’t break the applications that rely on that data.
How do we map out a database in such a way as to ensure that our work considers all relationships? How can we quickly determine every row of data that relates to a given row? That is the adventure we are embarking upon here!
Problem
It is possible to represent the table relationships in a database using an entity-relationship diagram (ERD), which shows each primary key & foreign key for the set of tables we are analyzing. For this example, we will use AdventureWorks, focusing on the Production.Product table and relationships that can affect that table. If we generate a complete ERD for AdventureWorks, we get a somewhat unwieldy result:
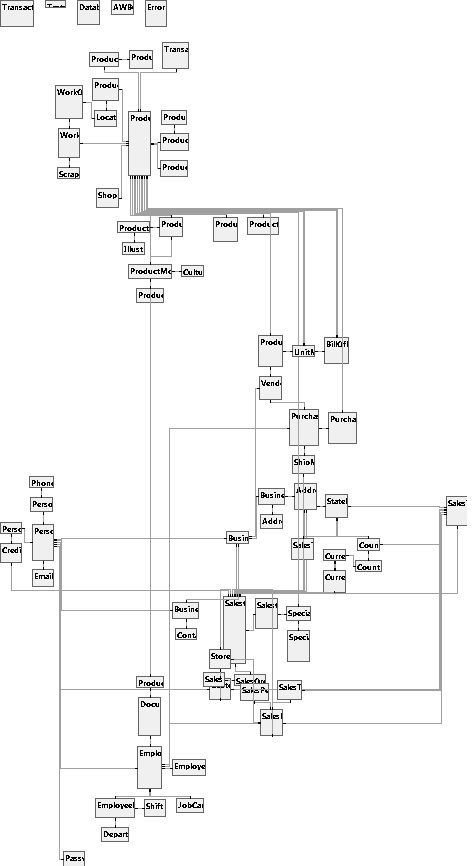
Not terribly pretty, but it’s a good overview that shows the “hot spots” in the database, where many relationships exist, as well as outliers, which have no dependencies defined. One observation that becomes clear is that nearly every table is somehow related. Five tables (at the top) stand alone, but otherwise every table has at least one relationship with another table. Removing those five tables leaves 68 behind, which is small by many standards, but for visualizing relationships, is still rather clunky. Generating an ERD on very large databases can yield what I fondly refer to as “Death Stars”, where there are hundreds or thousands of tables, and the diagram puts them in a huge set of concentric circles:

Whether it is a Spirograph or database is up to the viewer, but as a tool, it is more useful as wall art than as science.
To simplify our problem, let’s take a small segment of AdventureWorks that relates to the Product table:
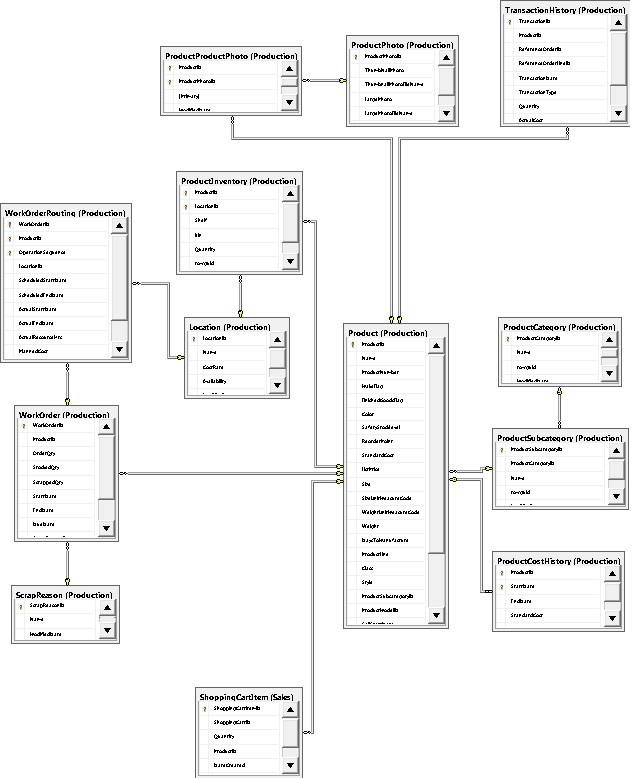
This ERD illustrates 13 tables and their dependencies. If we wanted to delete rows from Production.Product for any products that are silver, we would immediately need to consider all dependencies shown in that diagram. To do this, we could manually write the following queries:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
SELECT COUNT(*) FROM Production.Product WHERE Color = 'Silver' -- 43 rows SELECT COUNT(*) FROM Production.ProductCostHistory -- 45 rows INNER JOIN Production.Product ON Production.Product.ProductID = Production.ProductCostHistory.ProductID WHERE Production.Product.Color = 'Silver' SELECT COUNT(*) FROM Production.WorkOrder -- 6620 rows INNER JOIN Production.Product ON Production.Product.ProductID = Production.WorkOrder.ProductID WHERE Production.Product.Color = 'Silver' SELECT COUNT(*) FROM Production.TransactionHistory -- 10556 rows INNER JOIN Production.Product ON Production.Product.ProductID = Production.TransactionHistory.ProductID WHERE Production.Product.Color = 'Silver' SELECT COUNT(*) FROM Production.ProductProductPhoto -- 43 rows INNER JOIN Production.Product ON Production.Product.ProductID = Production.ProductProductPhoto.ProductID WHERE Production.Product.Color = 'Silver' SELECT COUNT(*) FROM Production.BillOfMaterials -- 400 rows INNER JOIN Production.Product ON Production.Product.ProductID = Production.BillOfMaterials.ProductAssemblyID WHERE Production.Product.Color = 'Silver' SELECT COUNT(*) FROM Production.BillOfMaterials -- 567 rows INNER JOIN Production.Product ON Production.Product.ProductID = Production.BillOfMaterials.ComponentID WHERE Production.Product.Color = 'Silver' SELECT COUNT(*) FROM Production.ProductListPriceHistory -- 45 rows INNER JOIN Production.Product ON Production.Product.ProductID = Production.ProductListPriceHistory.ProductID WHERE Production.Product.Color = 'Silver' SELECT COUNT(*) FROM Production.ProductInventory -- 86 rows INNER JOIN Production.Product ON Production.Product.ProductID = Production.ProductInventory.ProductID WHERE Production.Product.Color = 'Silver' SELECT COUNT(*) FROM Production.WorkOrderRouting -- 9467 rows INNER JOIN Production.WorkOrder ON Production.WorkOrder.WorkOrderID = Production.WorkOrderRouting.WorkOrderID INNER JOIN Production.Product ON Production.Product.ProductID = Production.WorkOrder.ProductID WHERE Production.Product.Color = 'Silver' |
While these queries are helpful, they took a very long time to write. For a larger database, this exercise would take an even longer amount of time and, due to the tedious nature of the task, be very prone to human error. In addition, order is critical—deleting from the wrong table in the hierarchy first could result in foreign key violations. The row counts provided are total rows generated through the join statements, and are not necessarily the counts in any one table. If we are ready to delete the data above, then we can convert those SELECT queries into DELETE statements, run them, and be happy with a job well done:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 |
DELETE [WorkOrderRouting] FROM [Production].[WorkOrderRouting] INNER JOIN [Production].[WorkOrder] ON [Production].[WorkOrder].[WorkOrderID] = [Production].[WorkOrderRouting].[WorkOrderID] INNER JOIN [Production].[Product] ON [Production].[Product].[ProductID] = [Production].[WorkOrder].[ProductID] WHERE (Product.Color = 'Silver') GO DELETE [ProductInventory] FROM [Production].[ProductInventory] INNER JOIN [Production].[Product] ON [Production].[Product].[ProductID] = [Production].[ProductInventory].[ProductID] WHERE (Product.Color = 'Silver') GO DELETE [ProductListPriceHistory] FROM [Production].[ProductListPriceHistory] INNER JOIN [Production].[Product] ON [Production].[Product].[ProductID] = [Production].[ProductListPriceHistory].[ProductID] WHERE (Product.Color = 'Silver') DELETE [BillOfMaterials] FROM [Production].[BillOfMaterials] INNER JOIN [Production].[Product] ON [Production].[Product].[ProductID] = [Production].[BillOfMaterials].[ComponentID] WHERE (Product.Color = 'Silver') DELETE [BillOfMaterials] FROM [Production].[BillOfMaterials] INNER JOIN [Production].[Product] ON [Production].[Product].[ProductID] = [Production].[BillOfMaterials].[ProductAssemblyID] WHERE (Product.Color = 'Silver') GO DELETE [ProductProductPhoto] FROM [Production].[ProductProductPhoto] INNER JOIN [Production].[Product] ON [Production].[Product].[ProductID] = [Production].[ProductProductPhoto].[ProductID] WHERE (Product.Color = 'Silver') GO DELETE [TransactionHistory] FROM [Production].[TransactionHistory] INNER JOIN [Production].[Product] ON [Production].[Product].[ProductID] = [Production].[TransactionHistory].[ProductID] WHERE (Product.Color = 'Silver') GO DELETE [ProductVendor] FROM [Purchasing].[ProductVendor] INNER JOIN [Production].[Product] ON [Production].[Product].[ProductID] = [Purchasing].[ProductVendor].[ProductID] WHERE (Product.Color = 'Silver') GO DELETE [WorkOrder] FROM [Production].[WorkOrder] INNER JOIN [Production].[Product] ON [Production].[Product].[ProductID] = [Production].[WorkOrder].[ProductID] WHERE (Product.Color = 'Silver') GO DELETE [PurchaseOrderDetail] FROM [Purchasing].[PurchaseOrderDetail] INNER JOIN [Production].[Product] ON [Production].[Product].[ProductID] = [Purchasing].[PurchaseOrderDetail].[ProductID] WHERE (Product.Color = 'Silver') GO DELETE [ProductCostHistory] FROM [Production].[ProductCostHistory] INNER JOIN [Production].[Product] ON [Production].[Product].[ProductID] = [Production].[ProductCostHistory].[ProductID] WHERE (Product.Color = 'Silver') GO DELETE FROM [Production].[Product] WHERE Product.Color = 'Silver' |
Unfortunately, the result of running this TSQL is an error:
The DELETE statement conflicted with the REFERENCE constraint “FK_SpecialOfferProduct_Product_ProductID”. The conflict occurred in database “AdventureWorks2012”, table “Sales.SpecialOfferProduct”, column ‘ProductID’.
It turns out there are relationships to tables outside of the Production schema in both Purchasing and Sales. Using the full ERD above, we can add some additional statements to our delete script that will handle them:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 |
DELETE [WorkOrderRouting] FROM [Production].[WorkOrderRouting] INNER JOIN [Production].[WorkOrder] ON [Production].[WorkOrder].[WorkOrderID] = [Production].[WorkOrderRouting].[WorkOrderID] INNER JOIN [Production].[Product] ON [Production].[Product].[ProductID] = [Production].[WorkOrder].[ProductID] WHERE (Product.Color = 'Silver') GO DELETE [SalesOrderDetail] FROM [Sales].[SalesOrderDetail] INNER JOIN [Sales].[SpecialOfferProduct] ON [Sales].[SpecialOfferProduct].[ProductID] = [Sales].[SalesOrderDetail].[ProductID] INNER JOIN [Production].[Product] ON [Production].[Product].[ProductID] = [Sales].[SpecialOfferProduct].[ProductID] WHERE (Product.Color = 'Silver') GO DELETE [SalesOrderDetail] FROM [Sales].[SalesOrderDetail] INNER JOIN [Sales].[SpecialOfferProduct] ON [Sales].[SpecialOfferProduct].[SpecialOfferID] = [Sales].[SalesOrderDetail].[SpecialOfferID] INNER JOIN [Production].[Product] ON [Production].[Product].[ProductID] = [Sales].[SpecialOfferProduct].[ProductID] WHERE (Product.Color = 'Silver') GO DELETE [ProductInventory] FROM [Production].[ProductInventory] INNER JOIN [Production].[Product] ON [Production].[Product].[ProductID] = [Production].[ProductInventory].[ProductID] WHERE (Product.Color = 'Silver') GO DELETE [ProductListPriceHistory] FROM [Production].[ProductListPriceHistory] INNER JOIN [Production].[Product] ON [Production].[Product].[ProductID] = [Production].[ProductListPriceHistory].[ProductID] WHERE (Product.Color = 'Silver') GO DELETE [SpecialOfferProduct] FROM [Sales].[SpecialOfferProduct] INNER JOIN [Production].[Product] ON [Production].[Product].[ProductID] = [Sales].[SpecialOfferProduct].[ProductID] WHERE (Product.Color = 'Silver') GO DELETE [BillOfMaterials] FROM [Production].[BillOfMaterials] INNER JOIN [Production].[Product] ON [Production].[Product].[ProductID] = [Production].[BillOfMaterials].[ComponentID] WHERE (Product.Color = 'Silver') GO DELETE [BillOfMaterials] FROM [Production].[BillOfMaterials] INNER JOIN [Production].[Product] ON [Production].[Product].[ProductID] = [Production].[BillOfMaterials].[ProductAssemblyID] WHERE (Product.Color = 'Silver') GO DELETE [ProductProductPhoto] FROM [Production].[ProductProductPhoto] INNER JOIN [Production].[Product] ON [Production].[Product].[ProductID] = [Production].[ProductProductPhoto].[ProductID] WHERE (Product.Color = 'Silver') GO DELETE [TransactionHistory] FROM [Production].[TransactionHistory] INNER JOIN [Production].[Product] ON [Production].[Product].[ProductID] = [Production].[TransactionHistory].[ProductID] WHERE (Product.Color = 'Silver') GO DELETE [ProductVendor] FROM [Purchasing].[ProductVendor] INNER JOIN [Production].[Product] ON [Production].[Product].[ProductID] = [Purchasing].[ProductVendor].[ProductID] WHERE (Product.Color = 'Silver') GO DELETE [WorkOrder] FROM [Production].[WorkOrder] INNER JOIN [Production].[Product] ON [Production].[Product].[ProductID] = [Production].[WorkOrder].[ProductID] WHERE (Product.Color = 'Silver') GO DELETE [PurchaseOrderDetail] FROM [Purchasing].[PurchaseOrderDetail] INNER JOIN [Production].[Product] ON [Production].[Product].[ProductID] = [Purchasing].[PurchaseOrderDetail].[ProductID] WHERE (Product.Color = 'Silver') GO DELETE [ProductCostHistory] FROM [Production].[ProductCostHistory] INNER JOIN [Production].[Product] ON [Production].[Product].[ProductID] = [Production].[ProductCostHistory].[ProductID] WHERE (Product.Color = 'Silver') GO DELETE FROM [Production].[Product] WHERE Product.Color = 'Silver' |
That executed successfully, but I feel quite exhausted from all the roundabout effort that went into the deletion of 43 rows from a table. Clearly this manual solution will not be scalable in any large database environment. What we need is a tool that can intelligently and quickly map these relationships for us.
Solution
We want to build a stored procedure that will take some inputs for the table we wish to act on, and any criteria we want to attach to it, and return actionable data on the structure of this schema. In an effort to prevent this article from becoming unwieldy, I’ll refrain from a detailed explanation of every bit of SQL, and focus on overall function and utility.
Our first task is to define our stored procedure, build parameters, and gather some basic data about the table we wish to act on (called the “target table” going forward). Deletion will be the sample action as it is the most destructive example that we can use. We will build our solution with 3 basic parameters:
@schema_name: The name of the schema we wish to report on
@table_name: The name of the table we wish to report on (target table).
@where_clause: The filter that we will apply when analyzing our data.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
CREATE PROCEDURE dbo.atp_schema_mapping @schema_name SYSNAME, @table_name SYSNAME, @where_clause VARCHAR(MAX) = '' AS BEGIN SET NOCOUNT ON; DECLARE @sql_command VARCHAR(MAX) = ''; -- Used for many dynamic SQL statements SET @where_clause = ISNULL(LTRIM(RTRIM(@where_clause)), ''); -- Clean up WHERE clause, to simplify future SQL DECLARE @row_counts TABLE -- Temporary table to dump dynamic SQL output into (row_count INT); DECLARE @base_table_row_count INT; -- This will hold the row count of the base entity. SELECT @sql_command = 'SELECT COUNT(*) FROM [' + @schema_name + '].[' + @table_name + ']' + -- Build COUNT statement CASE WHEN @where_clause <> '' -- Add WHERE clause, if provided THEN CHAR(10) + 'WHERE ' + @where_clause ELSE '' END; INSERT INTO @row_counts (row_count) EXEC (@sql_command); SELECT @base_table_row_count = row_count -- Extract count from temporary location. FROM @row_counts; -- If there are no matching rows to the input provided, exit immediately with an error message. IF @base_table_row_count = 0 BEGIN PRINT '-- There are no rows to process based on the input table and where clause. Execution aborted.'; RETURN; END END GO |
For step one, we have also added a row count check. In the event that the filter we apply to the target table results in no rows returned, then we’ll exit immediately and provide an informational message to let the user know that no further work is needed. As a test of this, we can execute the following SQL, using a color that is surely not found in Adventureworks:
|
1 2 3 4 5 6 |
EXEC dbo.atp_schema_mapping @schema_name = 'Production', @table_name = 'Product', @where_clause = 'Product.Color = ''Flurple''' |
The result is exactly as we expected:
There are no rows to process based on the input table and where clause. Execution aborted.
There is no other output or action from the stored proc, so far, but this provides a framework to begin our work.
The first hurdle to overcome is collecting data on our schema and organize it in a meaningful fashion. To process table data effectively, we need to turn an ERD into rows of metadata that describe a specific relationship, as well as how it relates to our target table. A critical part of this task is to emphasize that we are not just interested in relationships between tables. A set of relationships is not enough to completely map all data paths within a database. What we are truly interested in are data paths: Each set of relationships that leads from a given column back to our target table.
A table can be related to another via many different sets of paths, and it is important that we define all of these paths, so as not to miss any important relationships. The following shows a single example of two tables that are related in multiple ways:
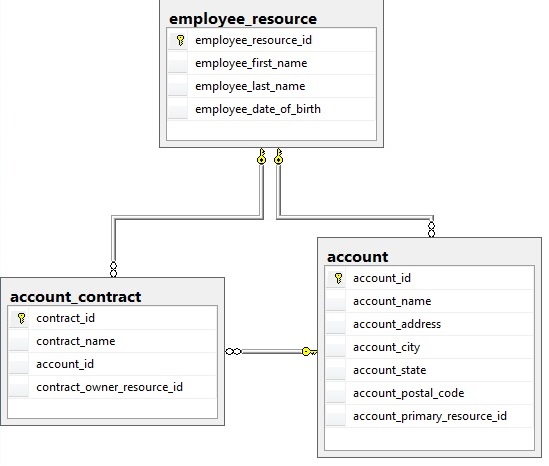
If we wanted to delete from the account table, we would need to examine the following relationships:
account_contract – – – > account (via account_id)
account_contract – – – > employee_resource (via contract_owner_resource_id)
account – – – > account_resource (via account_primary_resource_id)
account_contract – – – > employee_resource (via account_id and account_primary_resource_id)
The last relationship is very important—it illustrates a simple example of how it is possible for two tables to relate through any number of paths in between. It’s even possible for two tables to relate through the same intermediary tables, but using different key columns. Either way, we must consider all of these relationships in our work.
In order to map these relationships, we will need to gather the appropriate schema metadata from a variety of system views and recursively relate that data back to itself as we build a useful set of data with which to move forward on:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 |
-- This table will hold all foreign key relationships DECLARE @foreign_keys TABLE ( foreign_key_id INT NOT NULL IDENTITY(1,1) PRIMARY KEY CLUSTERED, referencing_object_id INT NULL, referencing_schema_name SYSNAME NULL, referencing_table_name SYSNAME NULL, referencing_column_name SYSNAME NULL, primary_key_object_id INT NULL, primary_key_schema_name SYSNAME NULL, primary_key_table_name SYSNAME NULL, primary_key_column_name SYSNAME NULL, level INT NULL, object_id_hierarchy_rank VARCHAR(MAX) NULL, referencing_column_name_rank VARCHAR(MAX) NULL); -- Insert all foreign key relational data into the table variable using a recursive CTE over system tables. WITH fkey (referencing_object_id, referencing_schema_name, referencing_table_name, referencing_column_name, primary_key_object_id, primary_key_schema_name, primary_key_table_name, primary_key_column_name, level, object_id_hierarchy_rank, referencing_column_name_rank) AS ( SELECT parent_table.object_id AS referencing_object_id, parent_schema.name AS referencing_schema_name, parent_table.name AS referencing_table_name, CONVERT(SYSNAME, NULL) AS referencing_column_name, CONVERT(INT, NULL) AS referenced_table_object_id, CONVERT(SYSNAME, NULL) AS referenced_schema_name, CONVERT(SYSNAME, NULL) AS referenced_table_name, CONVERT(SYSNAME, NULL) AS referenced_key_column_name, 0 AS level, CONVERT(VARCHAR(MAX), parent_table.object_id) AS object_id_hierarchy_rank, CAST('' AS VARCHAR(MAX)) AS referencing_column_name_rank FROM sys.objects parent_table INNER JOIN sys.schemas parent_schema ON parent_schema.schema_id = parent_table.schema_id WHERE parent_table.name = @table_name AND parent_schema.name = @schema_name UNION ALL SELECT child_object.object_id AS referencing_object_id, child_schema.name AS referencing_schema_name, child_object.name AS referencing_table_name, referencing_column.name AS referencing_column_name, referenced_table.object_id AS referenced_table_object_id, referenced_schema.name AS referenced_schema_name, referenced_table.name AS referenced_table_name, referenced_key_column.name AS referenced_key_column_name, f.level + 1 AS level, f.object_id_hierarchy_rank + '-' + CONVERT(VARCHAR(MAX), child_object.object_id) AS object_id_hierarchy_rank, f.referencing_column_name_rank + '-' + CAST(referencing_column.name AS VARCHAR(MAX)) AS referencing_column_name_rank FROM sys.foreign_key_columns sfc INNER JOIN sys.objects child_object ON sfc.parent_object_id = child_object.object_id INNER JOIN sys.schemas child_schema ON child_schema.schema_id = child_object.schema_id INNER JOIN sys.columns referencing_column ON referencing_column.object_id = child_object.object_id AND referencing_column.column_id = sfc.parent_column_id INNER JOIN sys.objects referenced_table ON sfc.referenced_object_id = referenced_table.object_id INNER JOIN sys.schemas referenced_schema ON referenced_schema.schema_id = referenced_table.schema_id INNER JOIN sys.columns AS referenced_key_column ON referenced_key_column.object_id = referenced_table.object_id AND referenced_key_column.column_id = sfc.referenced_column_id INNER JOIN fkey f ON f.referencing_object_id = sfc.referenced_object_id WHERE ISNULL(f.primary_key_object_id, 0) <> f.referencing_object_id -- Exclude self-referencing keys AND f.object_id_hierarchy_rank NOT LIKE '%' + CAST(child_object.object_id AS VARCHAR(MAX)) + '%' ) INSERT INTO @foreign_keys ( referencing_object_id, referencing_schema_name, referencing_table_name, referencing_column_name, primary_key_object_id, primary_key_schema_name, primary_key_table_name, primary_key_column_name, level, object_id_hierarchy_rank, referencing_column_name_rank) SELECT DISTINCT referencing_object_id, referencing_schema_name, referencing_table_name, referencing_column_name, primary_key_object_id, primary_key_schema_name, primary_key_table_name, primary_key_column_name, level, object_id_hierarchy_rank, referencing_column_name_rank FROM fkey; UPDATE FKEYS SET referencing_column_name_rank = SUBSTRING(referencing_column_name_rank, 2, LEN(referencing_column_name_rank)) -- Remove extra leading dash leftover from the top-level column, which has no referencing column relationship. FROM @foreign_keys FKEYS SELECT * FROM @foreign_keys; |
The TSQL above builds a set of data, centered on the target table provided (in the anchor section of the CTE), and recursively maps each level of relationships via each table’s foreign keys. The result set includes the following columns:
foreign_key_id: An auto-numbering primary key.
referencing_object_id: The object_id of the referencing table
referencing_schema_name: The name of the referencing schema
referencing_table_name: The name of the referencing table
referencing_column_name: The name of the specific referencing column for the referencing table above
primary_key_object_id: The object_id of the table referenced by the referencing table above
primary_key_schema_name: The schema name of the primary key table.
primary_key_table_name: The table name of the primary key table.
primary_key_column_name: The name of the primary key column referenced by the referencing column.
level: How many steps does this relationship path trace from the target table to the referencing table? This provides us the ability to logically order any operations from most removed to least removed. For delete or update statements, this is crucial.
object_id_hierarchy_rank: A list of each table’s object_id within the relationship tree. The target table is on the left, whereas the referencing table for each relationship is on the right. This will be used when constructing TSQL statements and optimizing unused TSQL.
referencing_column_name_rank: A list of the names of the referencing columns. This will be used later on for optimizing and removing irrelevant statements.
There are 2 WHERE clauses that are worth explaining further:
|
1 2 3 |
AND f.object_id_hierarchy_rank NOT LIKE '%' + CAST(child_object.object_id AS VARCHAR(MAX)) + '%' |
This ensures that we don’t loop around in circles forever. If a relationship exists that is circular (such as our account example earlier), then an unchecked recursive CTE would continue to increment the level and add to the relationship tree until the recursion limit was reached. We want to enumerate each relationship path only once, and this guards against infinite loops and repeated data.
|
1 2 3 |
WHERE ISNULL(f.primary_key_object_id, 0) <> f.referencing_object_id |
There is a single caveat that was explicitly avoided above: self-referencing foreign keys. In an effort to avoid infinite loops, we remove any foreign keys that reference their own table. If the referencing and referenced tables are the same, then we will filter them out of our result set immediately and deal with them separately.
We’ve explicitly excluded relationships from a table to itself, and are now obligated to do something about that. To collect this data, we do not need a recursive CTE. A set of joins between parent & child data will suffice:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 |
DECLARE @self_referencing_keys TABLE ( self_referencing_keys_id INT NOT NULL IDENTITY(1,1), referencing_primary_key_name SYSNAME NULL, referencing_schema_name SYSNAME NULL, referencing_table_name SYSNAME NULL, referencing_column_name SYSNAME NULL, primary_key_schema_name SYSNAME NULL, primary_key_table_name SYSNAME NULL, primary_key_column_name SYSNAME NULL); INSERT INTO @self_referencing_keys ( referencing_primary_key_name, referencing_schema_name, referencing_table_name, referencing_column_name, primary_key_schema_name, primary_key_table_name, primary_key_column_name) SELECT (SELECT COL_NAME(SIC.OBJECT_ID, SIC.column_id) FROM sys.indexes SI INNER JOIN sys.index_columns SIC ON SIC.index_id = SI.index_id AND SIC.object_id = SI.object_id WHERE SI.is_primary_key = 1 AND OBJECT_NAME(SIC.OBJECT_ID) = child_object.name) AS referencing_primary_key_name, child_schema.name AS referencing_schema_name, child_object.name AS referencing_table_name, referencing_column.name AS referencing_column_name, referenced_schema.name AS primary_key_schema_name, referenced_table.name AS primary_key_table_name, referenced_key_column.name AS primary_key_column_name FROM sys.foreign_key_columns sfc INNER JOIN sys.objects child_object ON sfc.parent_object_id = child_object.object_id INNER JOIN sys.schemas child_schema ON child_schema.schema_id = child_object.schema_id INNER JOIN sys.columns referencing_column ON referencing_column.object_id = child_object.object_id AND referencing_column.column_id = sfc.parent_column_id INNER JOIN sys.objects referenced_table ON sfc.referenced_object_id = referenced_table.object_id INNER JOIN sys.schemas referenced_schema ON referenced_schema.schema_id = referenced_table.schema_id INNER JOIN sys.columns AS referenced_key_column ON referenced_key_column.object_id = referenced_table.object_id AND referenced_key_column.column_id = sfc.referenced_column_id WHERE child_object.name = referenced_table.name AND child_object.name IN -- Only consider self-referencing relationships for tables somehow already referenced above, otherwise they are irrelevant. (SELECT referencing_table_name FROM @foreign_keys); |
We can return data from this table (if needed) with one additional query:
|
1 2 3 4 5 6 7 8 |
IF (SELECT COUNT(*) FROM @self_referencing_keys) > 0 BEGIN SELECT * FROM @self_referencing_keys; END |
We now have all of the data needed in order to begin analysis. We have a total of 3 goals to achieve here:
- Get counts of data that fit each relationship.
- If there are zero rows found for any relationships, then we can disregard them for the sake of deleting data. This will greatly speed up execution speed & efficiency on larger databases.
- Generate DELETE statements for the relevant data identified above.
- Collect all relevant information about a single foreign key relationship.
- Build all of the INNER JOINs that relate this foreign key back to the target table via the specific relationship defined in step 1.
- Execute the count TSQL.
- Store the output of the count TSQL in our @foreign_keys table for use later.
- SQL Server Database Metrics - October 2, 2019
- Using SQL Server Database Metrics to Predict Application Problems - September 27, 2019
- SQL Injection: Detection and prevention - August 30, 2019
Collecting row counts will require dynamic SQL in order to query an unknown list of tables and columns. For our example here, I use SELECT COUNT(*) FROM in order to return row counts. If you are working in tables with significant row counts, then you may find this approach to be slow, so please do not run the research portion of this stored procedure in a production environment without some level of caution (using a READ UNCOMMITTED isolation level removes contention, though it won’t speed things up much).
The following TSQL defines some new variables and iterates through each relationship until row counts have been collected for each relationship:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 |
DECLARE @count_sql_command VARCHAR(MAX) = ''; -- Used for dynamic SQL for count calculations DECLARE @row_count INT; -- Temporary holding place for relationship row count DECLARE @object_id_hierarchy_sql VARCHAR(MAX); DECLARE @process_schema_name SYSNAME = ''; DECLARE @process_table_name SYSNAME = ''; DECLARE @referencing_column_name SYSNAME = ''; DECLARE @join_sql VARCHAR(MAX) = ''; DECLARE @object_id_hierarchy_rank VARCHAR(MAX) = ''; DECLARE @referencing_column_name_rank VARCHAR(MAX) = ''; DECLARE @old_schema_name SYSNAME = ''; DECLARE @old_table_name SYSNAME = ''; DECLARE @foreign_key_id INT; DECLARE @has_same_object_id_hierarchy BIT; -- Will be used if this foreign key happens to share a hierarchy with other keys DECLARE @level INT; WHILE EXISTS (SELECT * FROM @foreign_keys WHERE processed = 0 AND level > 0 ) BEGIN SELECT @count_sql_command = ''; SELECT @join_sql = ''; SELECT @old_schema_name = ''; SELECT @old_table_name = ''; CREATE TABLE #inner_join_tables ( id INT NOT NULL IDENTITY(1,1), object_id INT); SELECT TOP 1 @process_schema_name = FKEYS.referencing_schema_name, @process_table_name = FKEYS.referencing_table_name, @object_id_hierarchy_rank = FKEYS.object_id_hierarchy_rank, @referencing_column_name_rank = FKEYS.referencing_column_name_rank, @foreign_key_id = FKEYS.foreign_key_id, @referencing_column_name = FKEYS.referencing_column_name, @has_same_object_id_hierarchy = CASE WHEN (SELECT COUNT(*) FROM @foreign_keys FKEYS2 WHERE FKEYS2.object_id_hierarchy_rank = FKEYS.object_id_hierarchy_rank) > 1 THEN 1 ELSE 0 END, @level = FKEYS.level FROM @foreign_keys FKEYS WHERE FKEYS.processed = 0 AND FKEYS.level > 0 ORDER BY FKEYS.level ASC; SELECT @object_id_hierarchy_sql ='SELECT ' + REPLACE (@object_id_hierarchy_rank, '-', ' UNION ALL SELECT '); INSERT INTO #inner_join_tables EXEC(@object_id_hierarchy_sql); SET @count_sql_command = 'SELECT COUNT(*) FROM [' + @process_schema_name + '].[' + @process_table_name + ']' + CHAR(10); SELECT @join_sql = @join_sql + CASE WHEN (@old_table_name <> FKEYS.primary_key_table_name OR @old_schema_name <> FKEYS.primary_key_schema_name) THEN 'INNER JOIN [' + FKEYS.primary_key_schema_name + '].[' + FKEYS.primary_key_table_name + '] ' + CHAR(10) + ' ON ' + ' [' + FKEYS.primary_key_schema_name + '].[' + FKEYS.primary_key_table_name + '].[' + FKEYS.primary_key_column_name + '] = [' + FKEYS.referencing_schema_name + '].[' + FKEYS.referencing_table_name + '].[' + FKEYS.referencing_column_name + ']' + CHAR(10) ELSE '' END , @old_table_name = CASE WHEN (@old_table_name <> FKEYS.primary_key_table_name OR @old_schema_name <> FKEYS.primary_key_schema_name) THEN FKEYS.primary_key_table_name ELSE @old_table_name END , @old_schema_name = CASE WHEN (@old_table_name <> FKEYS.primary_key_table_name OR @old_schema_name <> FKEYS.primary_key_schema_name) THEN FKEYS.primary_key_schema_name ELSE @old_schema_name END FROM @foreign_keys FKEYS INNER JOIN #inner_join_tables join_details ON FKEYS.referencing_object_id = join_details.object_id WHERE CHARINDEX(FKEYS.object_id_hierarchy_rank + '-', @object_id_hierarchy_rank + '-') <> 0 -- Do not allow cyclical joins through the same table we are originating from AND FKEYS.level > 0 AND ((@has_same_object_id_hierarchy = 0) OR (@has_same_object_id_hierarchy = 1 AND FKEYS.referencing_column_name = @referencing_column_name) OR (@has_same_object_id_hierarchy = 1 AND @level > FKEYS.level)) ORDER BY join_details.ID DESC; SELECT @count_sql_command = @count_sql_command + @join_sql; IF @where_clause <> '' BEGIN SELECT @count_sql_command = @count_sql_command + ' WHERE (' + @where_clause + ')'; END INSERT INTO @row_counts (row_count) EXEC (@count_sql_command); SELECT @row_count = row_count FROM @row_counts; UPDATE FKEYS SET processed = 1, row_count = @row_count, join_condition_sql = @join_sql FROM @foreign_keys FKEYS WHERE FKEYS.foreign_key_id = @foreign_key_id; DELETE FROM @row_counts; DROP TABLE #inner_join_tables END |
3 new columns have been added to our @foreign_keys table:
processed: A bit used to flag a relationship once it has been analyzed.
row_count: The row count that results from our work above.
join_condition_sql: The sequence of INNER JOIN statements generated above is cached here so that we do not need to perform all of this work again in the future.
The basic process followed is to:
Conclusion (Until Part 2)
We’ve built a framework for traversing a hierarchy of foreign keys, and are well on our way towards our goal of effective schema research. In Part 2, we’ll apply some optimization to our stored procedure in order to speed up execution on larger, more complex databases. We’ll then put all the pieces together and demo the result of all of this work. Thanks for reading, and I hope you’re enjoying this adventure so far!

In his free time, Ed enjoys video games, sci-fi & fantasy, traveling, and being as big of a geek as his friends will tolerate.
View all posts by Ed Pollack