
Description
We often have a need to view object definitions in SQL Server, whether they be tables, triggers, or foreign keys. The built in tools are great for an object here and there, but are very cumbersome if you’re looking to generate create statements for a large number of objects.
We will be introducing (and reintroducing) many different system views that provide valuable information about objects within SQL Server. This will allow us to understand how to locate and use information about our data and then be able to perform extremely useful tasks, such as creating copies of our schema, validating correctness, or generating schema for testing purposes.
Background and Purpose
Being able to quickly display the CREATE statement for an object can be extremely useful. Not only does this allow us to review our database schema, but it allows us to use that information to build out copies of some or all of those structures. Why would we ever want to do this? There are many good reasons, some of which I’ll list here:
- Quickly view the definition of a single object.
- Automated Schema Validation
- Generate a creation script, to be used to build those objects elsewhere.
- Use the creation scripts from multiple databases in order to compare/contrast objects.
- View all objects within a table in a single script.
- View all or some objects in a database based on customized input.
- Generate creation scripts for use in source control.
SQL Server Management Studio allows you to right-click on any object that is viewable from the database tree and choose to generate a create statement from it, like this:
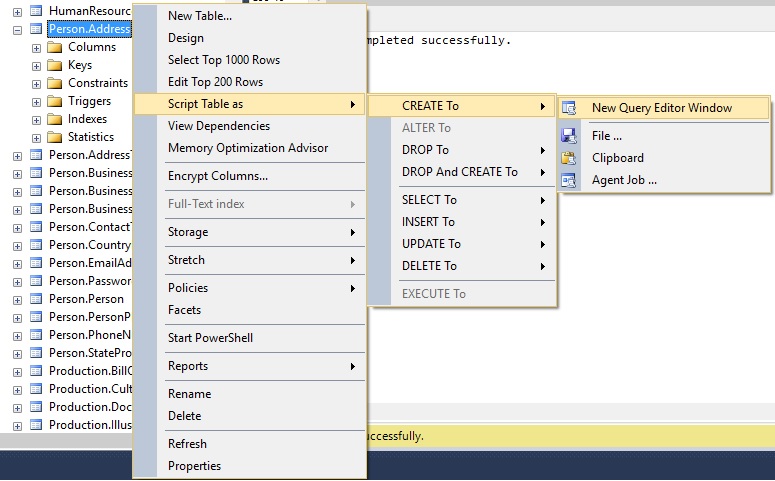
The resulting TSQL is as follows:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 |
USE [AdventureWorks2014] GO /****** Object: Table [Person].[Address] Script Date: 5/8/2016 3:48:12 PM ******/ SET ANSI_NULLS ON GO SET QUOTED_IDENTIFIER ON GO CREATE TABLE [Person].[Address]( [AddressID] [int] IDENTITY(1,1) NOT FOR REPLICATION NOT NULL, [AddressLine1] [nvarchar](60) NOT NULL, [AddressLine2] [nvarchar](60) NULL, [City] [nvarchar](30) NOT NULL, [StateProvinceID] [int] NOT NULL, [PostalCode] [nvarchar](15) NOT NULL, [SpatialLocation] [geography] NULL, [rowguid] [uniqueidentifier] ROWGUIDCOL NOT NULL, [ModifiedDate] [datetime] NOT NULL, CONSTRAINT [PK_Address_AddressID] PRIMARY KEY CLUSTERED ( [AddressID] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY] TEXTIMAGE_ON [PRIMARY] GO ALTER TABLE [Person].[Address] ADD CONSTRAINT [DF_Address_rowguid] DEFAULT (newid()) FOR [rowguid] GO ALTER TABLE [Person].[Address] ADD CONSTRAINT [DF_Address_ModifiedDate] DEFAULT (getdate()) FOR [ModifiedDate] GO ALTER TABLE [Person].[Address] WITH CHECK ADD CONSTRAINT [FK_Address_StateProvince_StateProvinceID] FOREIGN KEY([StateProvinceID]) REFERENCES [Person].[StateProvince] ([StateProvinceID]) GO ALTER TABLE [Person].[Address] CHECK CONSTRAINT [FK_Address_StateProvince_StateProvinceID] GO EXEC sys.sp_addextendedproperty @name=N'MS_Description', @value=N'Primary key for Address records.' , @level0type=N'SCHEMA',@level0name=N'Person', @level1type=N'TABLE',@level1name=N'Address', @level2type=N'COLUMN',@level2name=N'AddressID' GO EXEC sys.sp_addextendedproperty @name=N'MS_Description', @value=N'First street address line.' , @level0type=N'SCHEMA',@level0name=N'Person', @level1type=N'TABLE',@level1name=N'Address', @level2type=N'COLUMN',@level2name=N'AddressLine1' GO EXEC sys.sp_addextendedproperty @name=N'MS_Description', @value=N'Second street address line.' , @level0type=N'SCHEMA',@level0name=N'Person', @level1type=N'TABLE',@level1name=N'Address', @level2type=N'COLUMN',@level2name=N'AddressLine2' GO EXEC sys.sp_addextendedproperty @name=N'MS_Description', @value=N'Name of the city.' , @level0type=N'SCHEMA',@level0name=N'Person', @level1type=N'TABLE',@level1name=N'Address', @level2type=N'COLUMN',@level2name=N'City' GO EXEC sys.sp_addextendedproperty @name=N'MS_Description', @value=N'Unique identification number for the state or province. Foreign key to StateProvince table.' , @level0type=N'SCHEMA',@level0name=N'Person', @level1type=N'TABLE',@level1name=N'Address', @level2type=N'COLUMN',@level2name=N'StateProvinceID' GO EXEC sys.sp_addextendedproperty @name=N'MS_Description', @value=N'Postal code for the street address.' , @level0type=N'SCHEMA',@level0name=N'Person', @level1type=N'TABLE',@level1name=N'Address', @level2type=N'COLUMN',@level2name=N'PostalCode' GO EXEC sys.sp_addextendedproperty @name=N'MS_Description', @value=N'Latitude and longitude of this address.' , @level0type=N'SCHEMA',@level0name=N'Person', @level1type=N'TABLE',@level1name=N'Address', @level2type=N'COLUMN',@level2name=N'SpatialLocation' GO EXEC sys.sp_addextendedproperty @name=N'MS_Description', @value=N'ROWGUIDCOL number uniquely identifying the record. Used to support a merge replication sample.' , @level0type=N'SCHEMA',@level0name=N'Person', @level1type=N'TABLE',@level1name=N'Address', @level2type=N'COLUMN',@level2name=N'rowguid' GO EXEC sys.sp_addextendedproperty @name=N'MS_Description', @value=N'Default constraint value of NEWID()' , @level0type=N'SCHEMA',@level0name=N'Person', @level1type=N'TABLE',@level1name=N'Address', @level2type=N'CONSTRAINT',@level2name=N'DF_Address_rowguid' GO EXEC sys.sp_addextendedproperty @name=N'MS_Description', @value=N'Date and time the record was last updated.' , @level0type=N'SCHEMA',@level0name=N'Person', @level1type=N'TABLE',@level1name=N'Address', @level2type=N'COLUMN',@level2name=N'ModifiedDate' GO EXEC sys.sp_addextendedproperty @name=N'MS_Description', @value=N'Default constraint value of GETDATE()' , @level0type=N'SCHEMA',@level0name=N'Person', @level1type=N'TABLE',@level1name=N'Address', @level2type=N'CONSTRAINT',@level2name=N'DF_Address_ModifiedDate' GO EXEC sys.sp_addextendedproperty @name=N'MS_Description', @value=N'Street address information for customers, employees, and vendors.' , @level0type=N'SCHEMA',@level0name=N'Person', @level1type=N'TABLE',@level1name=N'Address' GO EXEC sys.sp_addextendedproperty @name=N'MS_Description', @value=N'Primary key (clustered) constraint' , @level0type=N'SCHEMA',@level0name=N'Person', @level1type=N'TABLE',@level1name=N'Address', @level2type=N'CONSTRAINT',@level2name=N'PK_Address_AddressID' GO EXEC sys.sp_addextendedproperty @name=N'MS_Description', @value=N'Foreign key constraint referencing StateProvince.StateProvinceID.' , @level0type=N'SCHEMA',@level0name=N'Person', @level1type=N'TABLE',@level1name=N'Address', @level2type=N'CONSTRAINT',@level2name=N'FK_Address_StateProvince_StateProvinceID' GO |
Wow…that is quite a bit of output for a single table. If all we needed was some information about this table, and we didn’t mind the extra output, then this would generally be adequate. If we were looking for schema creation scripts for an entire schema, database, or some other large segment of objects, then this approach would become cumbersome. Right-clicking a hundred times is not my idea of fun, nor is it something that can be easily automated.
Some of the output can be customized. For example, if I wanted to turn off the scripting of extended properties, I could do so via the SSMS options as follows:
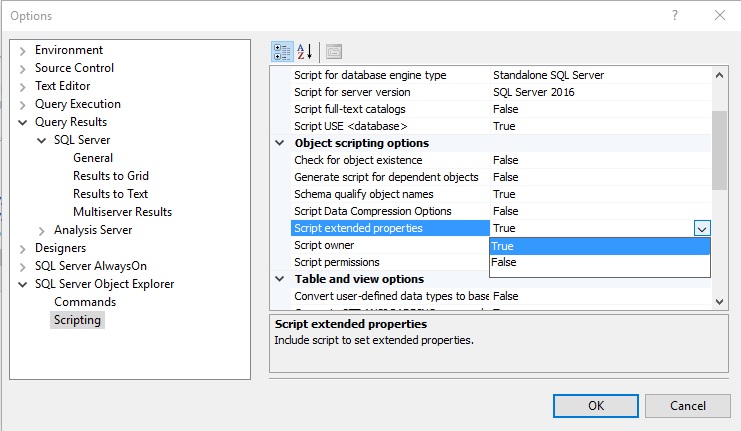
While this menu allows for quite a bit of customization of scripting output, the idea of having to return to this menu whenever I would like to change what I am outputting does seem a bit slow. While clicking through menus is easy, it’s slow and manual, both attributes I don’t generally like to incorporate into my workday 🙂
I’m always looking for ways to automate and speed up clunky or slow processes—especially those that rely on any significant element of manual labor. Typically, the more we are doing by hand as part of routine processes, the greater the chance something will go wrong. We’re human, and while I consider myself an expert in right-clicking, if I had to do that a hundred times every Monday in order to validate some portion of schema, it’s unclear whether I would make a mistake or lose my mind first.
Either way, I’d like to propose an alternative to all of these possibilities. Using data collected from system views, we can do all of this ourselves. Once we have sufficiently researched and gathered data from system views, we can create a stored procedure using those collection processes and automate everything into a stored procedure call with a handful of parameters.
What follows is an introduction to these views, how to use them in order to gather useful information about our database and the objects within.
Using System Metadata to Understand our Database
SQL Server provides a wide variety of system views, each of which provides a vast array of information about objects within SQL Server. These allow us to learn about table attributes, system settings, or view what sorts of schema exist in any database.
This analysis will focus on the primary structures that make up any database and that house our data: schemas, tables, constraints, indexes, and triggers. We’ll also throw in extended properties in order to illustrate our ability to learn about some of the less used (but potentially handy) components within SQL Server.
Schemas & Tables
Schemas and tables are easy to understand. From within a database, we can view a list of schemas like this:
|
1 2 3 4 5 |
SELECT * FROM sys.schemas; |
Running this query lists all schemas within our database. Schemas are useful for organizing database objects and/or applying more granular security to different types of data. When run on AdventureWorks, the results of the above query are:
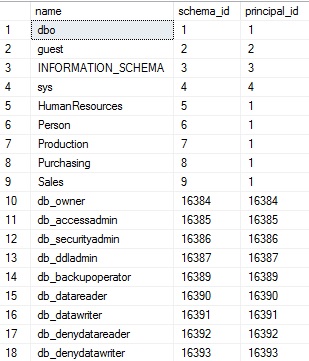
The results are simply a list of schema names within the database. The view contains the schema name, its ID, and the ID of its owner. Database roles appear in the list as well. While their inclusion may seem confusing, eliminating them is easy when we join this view to other views of interest. This view contains all entities that are capable of owning others from the context of database schemas. Some of the schemas above are familiar, such as dbo (the default schema in SQL Server), and the AdventureWorks-specific ones, such as Sales, Purchasing, or HumanResources.
Tables represent our primary storage mechanism and are therefore very important to us. We can view lots of information about them as follows:
|
1 2 3 4 5 6 |
SELECT * FROM sys.tables WHERE tables.is_ms_shipped = 0; |
Adding the check on is_ms_shipped will filter out any system tables. If you’d like the full list of all tables, including system objects, feel free to comment out or omit this filter. The results are as follows:

There are quite a few columns there, including another 2.5 pages worth that are off of the screen to the right! They include different bits of metadata that will be useful under a variety of circumstances. For the sake of our work here, we’ll simply stick to collecting table & schema names for those that are not system tables. We can join our two views above in order to list schemas and tables together:
|
1 2 3 4 5 6 7 8 9 10 |
SELECT schemas.name AS SchemaName, tables.name AS TableName FROM sys.schemas INNER JOIN sys.tables ON schemas.schema_id = tables.schema_id WHERE tables.is_ms_shipped = 0 ORDER BY schemas.name, tables.name; |
Schema_id can be used in order to join these views together and connect schemas to tables:
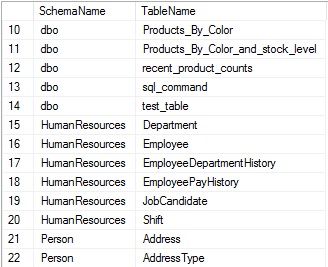
Adding aliases to each column proves useful, since the names of each are “name”, which is not a terribly descriptive way to differentiate between schema and table names. Later on in this article, as we return information about many other types of objects, aliasing them with friendly names will greatly improve readability and the ability to understand the results quickly & easily. Ordering by schema and table names also allows us to more easily browse through the results.
Columns
Columns contain each attribute of a table. Understanding them is imperative to understanding the contents of a table and the types of data that we store there. The following query adds sys.columns to our existing query, which provides additional information about each column, the table they belong to, and the schema the table belongs to:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
SELECT schemas.name AS Schema_Name, tables.name AS Table_Name, columns.name AS Column_Name, ROW_NUMBER() OVER (PARTITION BY schemas.name, tables.name ORDER BY columns.column_id ASC) AS Ordinal_Position, columns.max_length AS Column_Length, columns.precision AS Column_Precision, columns.scale AS Column_Scale, columns.collation_name AS Column_Collation, columns.is_nullable AS Is_Nullable, columns.is_identity AS Is_Identity, columns.is_computed AS Is_Computed, columns.is_sparse AS Is_Sparse FROM sys.schemas INNER JOIN sys.tables ON schemas.schema_id = tables.schema_id INNER JOIN sys.columns ON tables.object_id = columns.object_id; |
Columns are joined to tables using the object_id of the table, which is referenced by any columns contained within. The query above returns much more than column names, including details about each column that are useful when figuring out what kind of data each contains. The results begin to paint a clearer picture of our data:
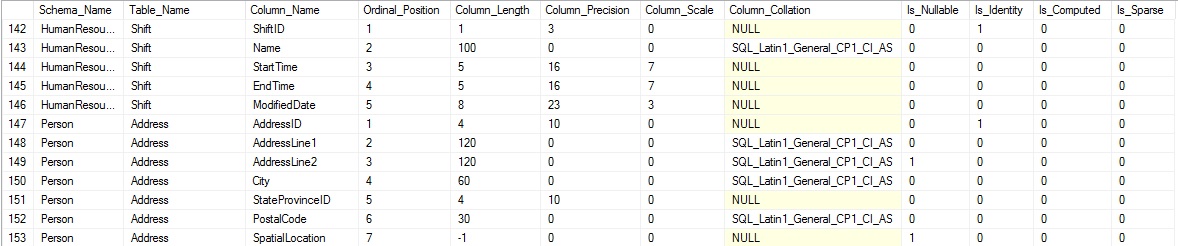
The ordinal position tells us the column order, which is useful when inserting into a table, or determining the logical order for data. Other columns provide additional information, such as the column length, nullability, identity status, and more!
Data Types
This is a great start, but we can learn more. Sys.types tells us more about the data type for each column, and can be joined directly to our previous query using user_type_id. The resulting type, when combined with length, precision, and scale, tell us exactly about a column’s data type and how it is defined:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
SELECT schemas.name AS Schema_Name, tables.name AS Table_Name, columns.name AS Column_Name, UPPER(types.name) AS Column_Data_Type, columns.max_length AS Column_Length, columns.precision AS Column_Precision, columns.scale AS Column_Scale FROM sys.schemas INNER JOIN sys.tables ON schemas.schema_id = tables.schema_id INNER JOIN sys.columns ON tables.object_id = columns.object_id INNER JOIN sys.types ON columns.user_type_id = types.user_type_id; |
To prevent our results from getting too cluttered, I’ve removed some of the columns previously discussed:
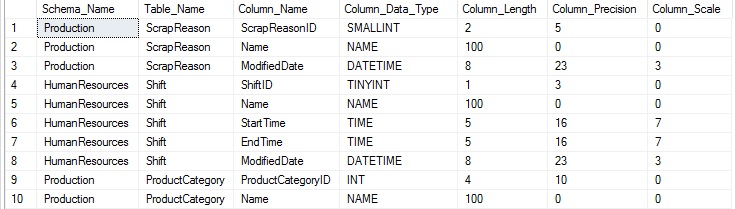
This additional information provides us with a familiar type name, such as DATETIME or INT, which may include customized user data types, such as NAME. We now have a basic understanding of what is in a table, and can now delve further into additional attributes.
Identity Column Details
One of the attributes previously identified in sys.columns was is_identity, which told us if a column was an identity or not. If it is, we also want to know the seed and increment of the column, which tell us how that identity will behave. This can be accomplished by joining sys.columns to sys.identity_columns:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
SELECT schemas.name AS Schema_Name, tables.name AS Table_Name, columns.name AS Column_Name, UPPER(types.name) AS Column_Data_Type, CAST(identity_columns.seed_value AS BIGINT) AS Identity_Seed, CAST(identity_columns.increment_value AS BIGINT) AS Identity_Increment FROM sys.schemas INNER JOIN sys.tables ON schemas.schema_id = tables.schema_id INNER JOIN sys.columns ON tables.object_id = columns.object_id INNER JOIN sys.types ON columns.user_type_id = types.user_type_id LEFT JOIN sys.identity_columns ON columns.object_id = identity_columns.object_id AND columns.column_id = identity_columns.column_id; |
Note that the join to sys.identity_columns requires the use of both object_id, which indicates the table it belongs to, and also column_id, which specifies the unique ID of the column within that table. In order to most easily and accurately reference any column uniquely, we must use both object_id and column_id. The results of the above query show the additional information added to the end of the result set:
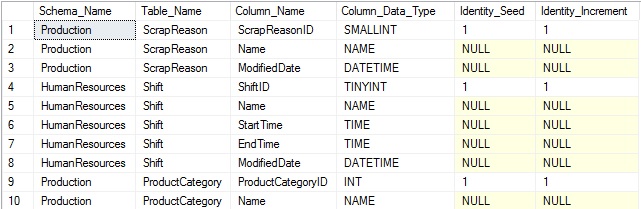
The results aren’t terribly exciting. IDENTITY(1,1) is the most common definition used for an identity column, but we’ve gained additional knowledge that will prove useful later on.
Default Constraints
A column can have at most a single default constraint associated with it. If one is defined, knowing its name and value are helpful in understanding the behavior of the column. A default often indicates a business rule or data need to ensure the column is not NULL, or is at least always populated with some important catchall value. We can gather this information from sys.default_constraints like this:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
SELECT schemas.name AS Schema_Name, tables.name AS Table_Name, columns.name AS Column_Name, UPPER(types.name) AS Column_Data_Type, default_constraints.name AS Default_Constraint_Name, UPPER(default_constraints.definition) AS Default_Constraint_Definition FROM sys.schemas INNER JOIN sys.tables ON schemas.schema_id = tables.schema_id INNER JOIN sys.columns ON tables.object_id = columns.object_id INNER JOIN sys.types ON columns.user_type_id = types.user_type_id LEFT JOIN sys.default_constraints ON schemas.schema_id = default_constraints.schema_id AND columns.object_id = default_constraints.parent_object_id AND columns.column_id = default_constraints.parent_column_id; |
Note that while this new view is joined on a schema, table, and column, the join on schema is unnecessary we are already are joining that view via sys.tables. Regardless, it is included for both documentation purposes and completeness. The results of the query show all columns, but if a default is defined, that information is also provided:
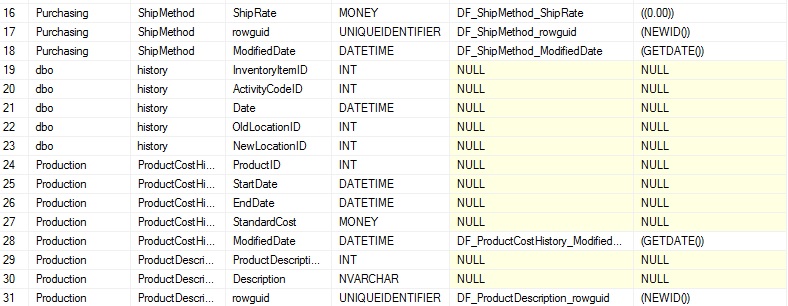
We can note a variety of defaults that take values of the current date, zero, and a new GUID unique identifier, though many other types can exist with whatever values you choose to assign. NULL indicates that a column has no default assigned to it. If we chose to join to sys.default_constraints using an INNER JOIN, then we would filter out all of the rows without defaults, leaving behind only the set of columns with default values defined.
Computed Columns
Similar to default constraints, a column may only have a single computed definition associated with it. A computed column cannot be assigned values, and instead is automatically updated based on whatever definition is created for it. Information on this can be found in sys.computed_columns and joined back to sys.columns using object_id and column_id:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
SELECT schemas.name AS Schema_Name, tables.name AS Table_Name, columns.name AS Column_Name, UPPER(types.name) AS Column_Data_Type, UPPER(computed_columns.definition) AS Computed_Column_Definition FROM sys.schemas INNER JOIN sys.tables ON schemas.schema_id = tables.schema_id INNER JOIN sys.columns ON tables.object_id = columns.object_id INNER JOIN sys.types ON columns.user_type_id = types.user_type_id LEFT JOIN sys.computed_columns ON columns.object_id = computed_columns.object_id AND columns.column_id = computed_columns.column_id; |
This new view inherits all of the columns in sys.columns, adding a few additional pieces of information. Of these, we will focus on the definition, which tells us in TSQL how that column is populated:
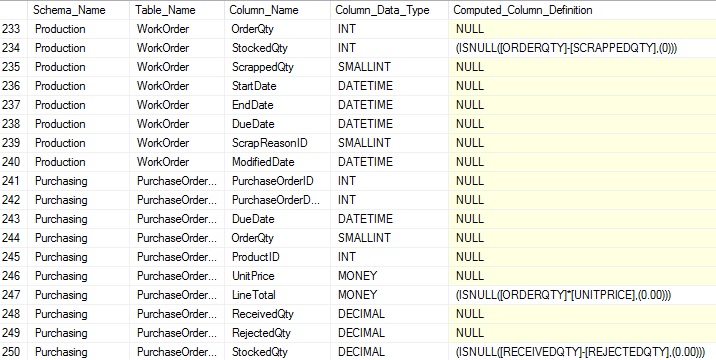
Since sys.computed_columns contains all of the information in sys.columns, it is not necessary to include sys.columns when also querying it if all we care about are columns with computed values defined on them. If we want to include all columns with the computed definition being optional, then the LEFT JOIN between them is required. Any column with no row in sys.computed_columns will result in a NULL in the above query, indicating that it does not have a computed column definition.
Indexes & Primary Key Definitions
A table can only have one primary key associated with it, but this definition is important enough that we want to always capture it, regardless of what columns it is on, or if it is also a clustered index or not. Details about primary keys, as well as details on other indexes, can be found in sys.indexes. This view also holds data pertaining to other indexes on the table. Therefore, we can collect info on all indexes, including primary keys, in a single operation:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 |
WITH CTE_INDEX_COLUMNS AS ( SELECT INDEX_DATA.name AS Index_Name, SCHEMA_DATA.name AS Schema_Name, TABLE_DATA.name AS Table_Name, INDEX_DATA.is_unique, INDEX_DATA.has_filter, INDEX_DATA.filter_definition, INDEX_DATA.type_desc AS Index_Type, STUFF(( SELECT ', ' + columns.name + CASE WHEN index_columns.is_descending_key = 1 THEN ' DESC' ELSE ' ASC' END FROM sys.tables INNER JOIN sys.indexes ON tables.object_id = indexes.object_id INNER JOIN sys.index_columns ON indexes.object_id = index_columns.object_id AND indexes.index_id = index_columns.index_id INNER JOIN sys.columns ON tables.object_id = columns.object_id AND index_columns.column_id = columns.column_id WHERE INDEX_DATA.object_id = indexes.object_id AND INDEX_DATA.index_id = indexes.index_id AND index_columns.is_included_column = 0 ORDER BY index_columns.key_ordinal FOR XML PATH('')), 1, 2, '') AS Index_Column_List, STUFF(( SELECT ', ' + columns.name FROM sys.tables INNER JOIN sys.indexes ON tables.object_id = indexes.object_id INNER JOIN sys.index_columns ON indexes.object_id = index_columns.object_id AND indexes.index_id = index_columns.index_id INNER JOIN sys.columns ON tables.object_id = columns.object_id AND index_columns.column_id = columns.column_id WHERE INDEX_DATA.object_id = indexes.object_id AND INDEX_DATA.index_id = indexes.index_id AND index_columns.is_included_column = 1 ORDER BY index_columns.key_ordinal FOR XML PATH('')), 1, 2, '') AS Include_Column_List, Is_Primary_Key FROM sys.indexes INDEX_DATA INNER JOIN sys.tables TABLE_DATA ON TABLE_DATA.object_id = INDEX_DATA.object_id INNER JOIN sys.schemas SCHEMA_DATA ON TABLE_DATA.schema_id = SCHEMA_DATA.schema_id) SELECT Index_Name, Schema_Name, Table_Name, is_unique, has_filter, filter_definition, Index_Type, Index_Column_List, ISNULL(Include_Column_List, '') AS Include_Column_List, Is_Primary_Key FROM CTE_INDEX_COLUMNS WHERE CTE_INDEX_COLUMNS.Index_Type <> 'HEAP'; |
This query collects basic index data, such as whether it is clustered, filtered, or a primary key. It also uses XML to pull the index column details into a comma-separated list, for easy use later on. Collecting all of this data at once is efficient and convenient, and avoids the need to return for column lists, or to check any properties of an index later on.
While the query above appears complex, if we remove the XML necessary to parse the column list, the resulting query would only be a simple SELECT from sys.indexes, sys.tables, and sys.schemas. While we could do this initially, and then add the column lists later on, collecting all of this data right now will simplify our TSQL and improve performance as we won’t need to perform additional schema searches and joins to that data once this is complete.
The results of the above query look like this:

We omit HEAP from the results as they are not needed for explicit documentation of tables as they are automatically implied in the heap’s definition. We get a fairly wide result set back, but it provides us everything we need to understand an index and its purpose and usage.
Foreign Keys
Foreign keys also represent column lists in one table that reference columns in a target table. We can view basic information on a foreign key using the system view sys.foreign_keys:
|
1 2 3 4 5 6 7 8 9 10 11 |
SELECT foreign_keys.name AS Foreign_Key_Name, schemas.name AS Foreign_Key_Schema_Name, tables.name AS Foreign_Key_Table_Name FROM sys.foreign_keys INNER JOIN sys.tables ON tables.object_id = foreign_keys.parent_object_id INNER JOIN sys.schemas ON schemas.schema_id = tables.schema_id; |
This query returns a list of foreign keys and the source/target tables referenced by it:
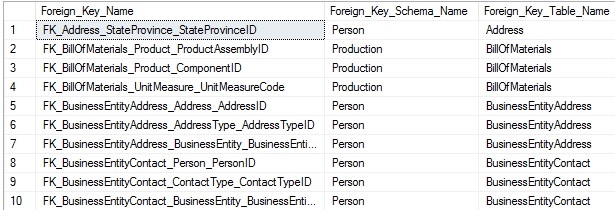
This is straight-forward, but we also want to collect the column lists from source and target tables in order to correctly include them in our data. A foreign key is often a relationship between a single column in one table and its corresponding column in another table, but could exist between groups of columns. As a result, we must write our TSQL to be able to handle either scenario. For now, let’s look at a list of columns in which a foreign key is defined by a row per column in the result set:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
SELECT foreign_keys.name AS Foreign_Key_Name, FOREIGN_KEY_TABLE.name AS Foreign_Key_Table_Name, FOREIGN_KEY_COLUMN.name AS Foreign_Key_Column_Name, REFERENCED_TABLE.name AS Referenced_Table_Name, REFERENECD_COLUMN.name AS Referenced_Column_Name FROM sys.foreign_key_columns INNER JOIN sys.foreign_keys ON foreign_keys.object_id = foreign_key_columns.constraint_object_id INNER JOIN sys.tables FOREIGN_KEY_TABLE ON foreign_key_columns.parent_object_id = FOREIGN_KEY_TABLE.object_id INNER JOIN sys.columns as FOREIGN_KEY_COLUMN ON foreign_key_columns.parent_object_id = FOREIGN_KEY_COLUMN.object_id AND foreign_key_columns.parent_column_id = FOREIGN_KEY_COLUMN.column_id INNER JOIN sys.columns REFERENECD_COLUMN ON foreign_key_columns.referenced_object_id = REFERENECD_COLUMN.object_id AND foreign_key_columns.referenced_column_id = REFERENECD_COLUMN.column_id INNER JOIN sys.tables REFERENCED_TABLE ON REFERENCED_TABLE.object_id = foreign_key_columns.referenced_object_id ORDER BY FOREIGN_KEY_TABLE.name, foreign_key_columns.constraint_column_id; |
Sys.foreign_key_columns tells us the column relationships. From there, we need to join sys.tables and sys.columns twice: Once for the parent table and another for the foreign key table. Combining this information allows us to understand what columns reference and are referenced by any foreign key. If a foreign key has multiple columns participating in it, then it will be represented as multiple rows in the result set:
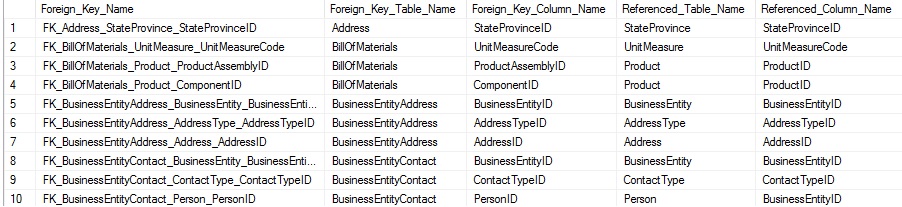
Since we need to worry about two sets of data, collecting it takes a bit more work, but much of it is a duplication of concepts that we have already discussed previously.
Check Constraints
Check constraints are relatively simple to collect information on. Since they are stored with their entire definitions intact, there is no need to query column metadata in order to construct them. Sys.check_constraints can be queried in order to view info on check constraints:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
SELECT schemas.name AS Schema_Name, tables.name AS Table_Name, check_constraints.name AS Check_Constraint_Name, check_constraints.is_not_trusted AS With_Nocheck, check_constraints.definition AS Check_Constraint_Definition FROM sys.check_constraints INNER JOIN sys.tables ON tables.object_id = check_constraints.parent_object_id INNER JOIN sys.schemas ON tables.schema_id = schemas.schema_id; |
Selecting the is_not_trusted column allows us to validate if the constraint was created with NOCHECK or not. The definition contains the exact constraint details as they were entered when it was created. The results are easy to read and understand:
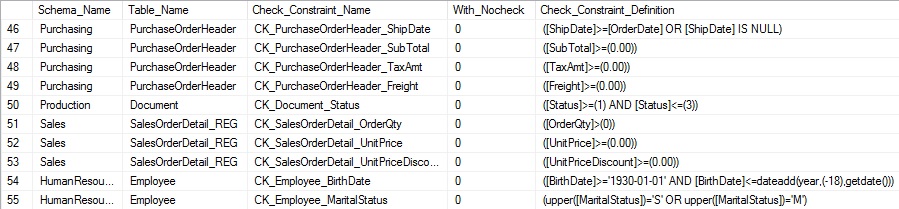
The definition itself may be complex, but our efforts to collect this information are the same, regardless of how intricate the check constraint it.
Triggers
Triggers are stored in a very similar manner to check constraints. The only difference is that their definition is included in sys.sql_modules, whereas the trigger name and object information are stored in sys.triggers. Despite there being two tables involved, we can collect data on them in the same manner as with check constraints:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
SELECT schemas.name AS Schema_Name, tables.name AS Table_Name, sql_modules.definition AS Trigger_Definition FROM sys.triggers INNER JOIN sys.sql_modules ON triggers.object_id = sql_modules.object_id INNER JOIN sys.tables ON triggers.parent_id = tables.object_id INNER JOIN sys.schemas ON schemas.schema_id = tables.schema_id; |
Note that while we join to sys.triggers, we do not return any columns from that view. That is because the trigger definition provides all details of a trigger that would be found in a CREATE TRIGGER statement. Sys.sql_modules contains details about a variety of objects within SQL Server, such as stored procedures, triggers, and functions. Definitions within this view are all provided in their entirety, including the CREATE statement. As a result, there is no need to query for additional metadata, such as if the trigger is INSTEAD OF or AFTER, or if it is on UPDATE, DELETE, or INSERT. The results of the above query are as follows:
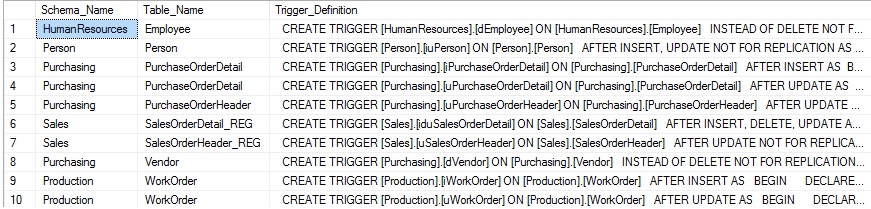
The results are far more simple than we would have expected! The entire definition is returned in a single column, which makes our work quite easy!
Extended Properties
Extended properties are a bit odd in terms of definition and usage. They can be linked to many different objects in SQL Server, such as tables, columns, or constraints. As a result, we need to not only collect their definition, but also the object they relate to. This is a feature that not everyone uses, but is a good example of how even the more oddball parts of SQL Server can be documented if necessary.
Sys.extended_properties contains all of the basic information about an extended property. The major_id and minor_id within the view provide us with information on what object the property references. Since we do not know precisely what type of object any extended property may reference up front, we need to LEFT JOIN all possible targets in order to collect a complete result set:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
SELECT Child.type_desc AS Object_Type, extended_properties.name AS Extended_Property_Name, CAST(extended_properties.value AS NVARCHAR(MAX)) AS Extended_Property_Value, schemas.name AS Schema_Name, Child.name AS Object_Name, Parent.name AS Parent_Object_Name, columns.name AS Parent_Column_Name, indexes.name AS Index_Name FROM sys.extended_properties INNER JOIN sys.objects Child ON extended_properties.major_id = Child.object_id INNER JOIN sys.schemas ON schemas.schema_id = Child.schema_id LEFT JOIN sys.objects Parent ON Parent.object_id = Child.parent_object_id LEFT JOIN sys.columns ON Child.object_id = columns.object_id AND extended_properties.minor_id = columns.column_id AND extended_properties.class_desc = 'OBJECT_OR_COLUMN' AND extended_properties.minor_id <> 0 LEFT JOIN sys.indexes ON Child.object_id = indexes.object_id AND extended_properties.minor_id = indexes.index_id AND extended_properties.class_desc = 'INDEX' WHERE Child.type_desc IN ('CHECK_CONSTRAINT', 'DEFAULT_CONSTRAINT', 'FOREIGN_KEY_CONSTRAINT', 'PRIMARY_KEY_CONSTRAINT', 'SQL_TRIGGER', 'USER_TABLE') ORDER BY Child.type_desc ASC; |
In this query, sys.extended_properties forms the base table. Sys.objects and sys.schemas are connected using an INNER JOIN, as their metadata will apply to all properties, regardless of type. From here, the remaining joins allow us to gather additional information about the object referenced in sys.objects. The WHERE clause limits the targets that we are interested in to the types of objects that we have discussed thus far (constraints, triggers, and columns).
The results of the above query will look like this:

The results tell us the name of the extended property, the type of object it references, information about that object, and the text stored in the extended property itself. Microsoft wasn’t terribly creative and named all extended properties “MS_Description”. You can name yours whatever you want, though, such as in this dinosaur table that I’ve created:
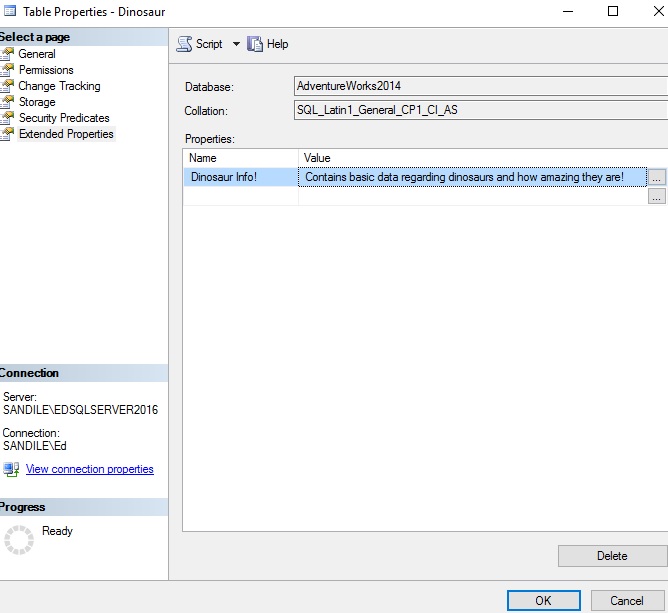
Conclusion
System views provide a wealth of information about our data, how it is stored, and the constraints that we place on it. Using these views, we can quickly gather information about objects that are important to us, such as indexes or foreign keys. With this information, we can reconstruct our schema in a format that will assist in schema duplication, development and QA, and schema comparison.
In our next article, Creating the perfect schema documentation script, we will take everything we have discussed here and combine it into a script that will greatly improve our ability to document and understand a database and its structure.
References and Further Reading
Some of the system views discussed here were also introduced in a previous 2-part article about searching SQL Server. If desired, we could combine these scripts such that the search script also returned the definition, as well. This could be a very efficient (and fun) way to find objects and their definition based on a keyword search:
Searching SQL Server made easy – Searching catalog views
Searching SQL Server made easy – Building the perfect search script
Options are documented for the built-in SQL Server scripting here:
Generate SQL Server Scripts Wizard (Choose Script Options Page)
Some basic instructions on this process can be found here:
Generate Scripts (SQL Server Management Studio)
Lastly, information on catalog views, which provide the basis for this article, can be found here:
Catalog Views (Transact-SQL)

In his free time, Ed enjoys video games, sci-fi & fantasy, traveling, and being as big of a geek as his friends will tolerate.
View all posts by Ed Pollack
- SQL Server Database Metrics - October 2, 2019
- Using SQL Server Database Metrics to Predict Application Problems - September 27, 2019
- SQL Injection: Detection and prevention - August 30, 2019